A principios de 2018, comenzamos activamente el proceso de digitalización de la producción y los procesos en la empresa. En el sector petroquímico, esto no es solo una tendencia de moda, sino un nuevo paso evolutivo hacia el aumento de la eficiencia y la competitividad. Teniendo en cuenta los detalles del negocio, que, sin ninguna digitalización, muestra buenos resultados económicos, los digitalizadores se enfrentan a una tarea difícil: cambiar los procesos establecidos en la empresa es una tarea bastante laboriosa.
Nuestra digitalización comenzó con la creación de dos centros y sus correspondientes bloques funcionales.
Esta es la "Función de tecnología digital", que incluye todas las áreas de productos: digitalización de procesos, IIoT y análisis avanzado, así como un centro de gestión de datos que se ha convertido en un área independiente.

Y solo la tarea principal de la oficina de datos es implementar completamente la cultura de la toma de decisiones basada en datos (sí, sí, decisión basada en datos), así como, en principio, racionalizar todo lo relacionado con el trabajo con datos: análisis, procesamiento , almacenamiento e informes. La peculiaridad es que todas nuestras herramientas digitales tendrán que usar no solo activamente sus propios datos, es decir, aquellos que generan ellos mismos (por ejemplo, desvíos móviles o sensores IIoT), sino también datos externos, con una clara comprensión de dónde y por qué son necesarios. para usar
Mi nombre es Artyom Danilov, soy el jefe del departamento de Infraestructura y Tecnología en SIBUR, en esta publicación les contaré cómo y sobre qué construimos un gran sistema de procesamiento y almacenamiento de datos para todo SIBUR. Para empezar, solo hablaremos sobre la arquitectura de nivel superior y cómo puede formar parte de nuestro equipo.
Estas son las áreas que incluyen el trabajo en una oficina de datos:
1. Trabajar con datosLos chicos que participan activamente en el inventario y la catalogación de nuestros datos trabajan aquí. Entienden qué necesidades tiene una función en particular, pueden determinar qué tipo de análisis puede ser necesario, qué métricas deben monitorearse para tomar decisiones y cómo se utilizan los datos en un área comercial en particular.
2. BI y visualización de datosLa dirección está estrechamente relacionada con la primera y le permite visualizar los resultados del trabajo de los muchachos del primer equipo.
3. Dirección del control de calidad de los datos.Aquí se introducen herramientas de control de calidad de datos y se implementa toda la metodología de dicho control. En otras palabras, los chicos de aquí implementan software, escriben varias verificaciones y pruebas, entienden cómo se realizan las verificaciones cruzadas entre los diferentes sistemas, observan las funciones de los empleados responsables de la calidad de los datos y también establecen una metodología común.
4. Gestión de NSISomos una gran empresa Tenemos muchos tipos diferentes de directorios, y contratistas, y materiales, y un directorio de empresas ... En general, créanme, hay directorios más que suficientes.
Cuando una empresa compra activamente algo para sus actividades, generalmente tiene procesos especiales para completar estos directorios. De lo contrario, el caos alcanzará un nivel tal que será imposible trabajar desde la palabra "completamente". También tenemos dicho sistema (MDM).
Aquí están los problemas. Supongamos que, en una de las divisiones regionales, de las cuales tenemos mucho, los empleados se sientan e ingresan datos en el sistema. Contribuya a mano, con todas las consecuencias derivadas de este método. Es decir, necesitan ingresar datos, verificar que todo llegó al sistema en la forma correcta, sin duplicados. Al mismo tiempo, algunas cosas, en el caso de completar algunos detalles y campos obligatorios, debe buscar y buscar en Google de forma independiente. Por ejemplo, tiene un TIN de la empresa y necesita otra información: verifica los servicios especiales y el registro.
Todos estos datos, por supuesto, ya están en algún lugar, por lo que sería correcto simplemente extraerlos automáticamente.
Anteriormente, la empresa, en principio, no tenía una posición única, un equipo claro que lo hiciera. Hubo muchas divisiones dispersas que ingresaron datos manualmente. Pero, por lo general, es difícil que tales estructuras formulen exactamente qué y dónde exactamente en el proceso de trabajar con datos debe cambiarse para que todo sea perfecto. Por lo tanto, estamos revisando el formato y la estructura de gestión del NSI.
5. Implementación del almacén de datos (nodo de datos)Esto es exactamente lo que comenzamos a hacer en esta área.
Definamos de inmediato los términos; de lo contrario, las frases que utilizo pueden cruzarse con otros conceptos. En términos generales, nodo de datos = lago de datos + almacén de datos. Un poco más adelante revelaré esto con más detalle.
Arquitectura
En primer lugar, tratamos de averiguar con qué tipo de datos trabajar, qué sistemas hay, qué sensores. Entendimos lo que sería la transmisión de datos (esto es lo que las propias empresas generan de todos sus equipos, esto es IIoT, etc.) y sistemas clásicos, diferentes CRM, ERP y similares.
Nos dimos cuenta de que los datos en los sistemas actuales no serán lo suficientemente directos como para ser muy grandes en volumen, pero con la introducción de herramientas digitales y IIoT habrá muchos de ellos. Y también habrá datos muy heterogéneos de los sistemas de contabilidad clásicos. Por lo tanto, se les ocurrió la arquitectura de dicho plan.

Más detalles sobre los bloques.
Almacenamiento
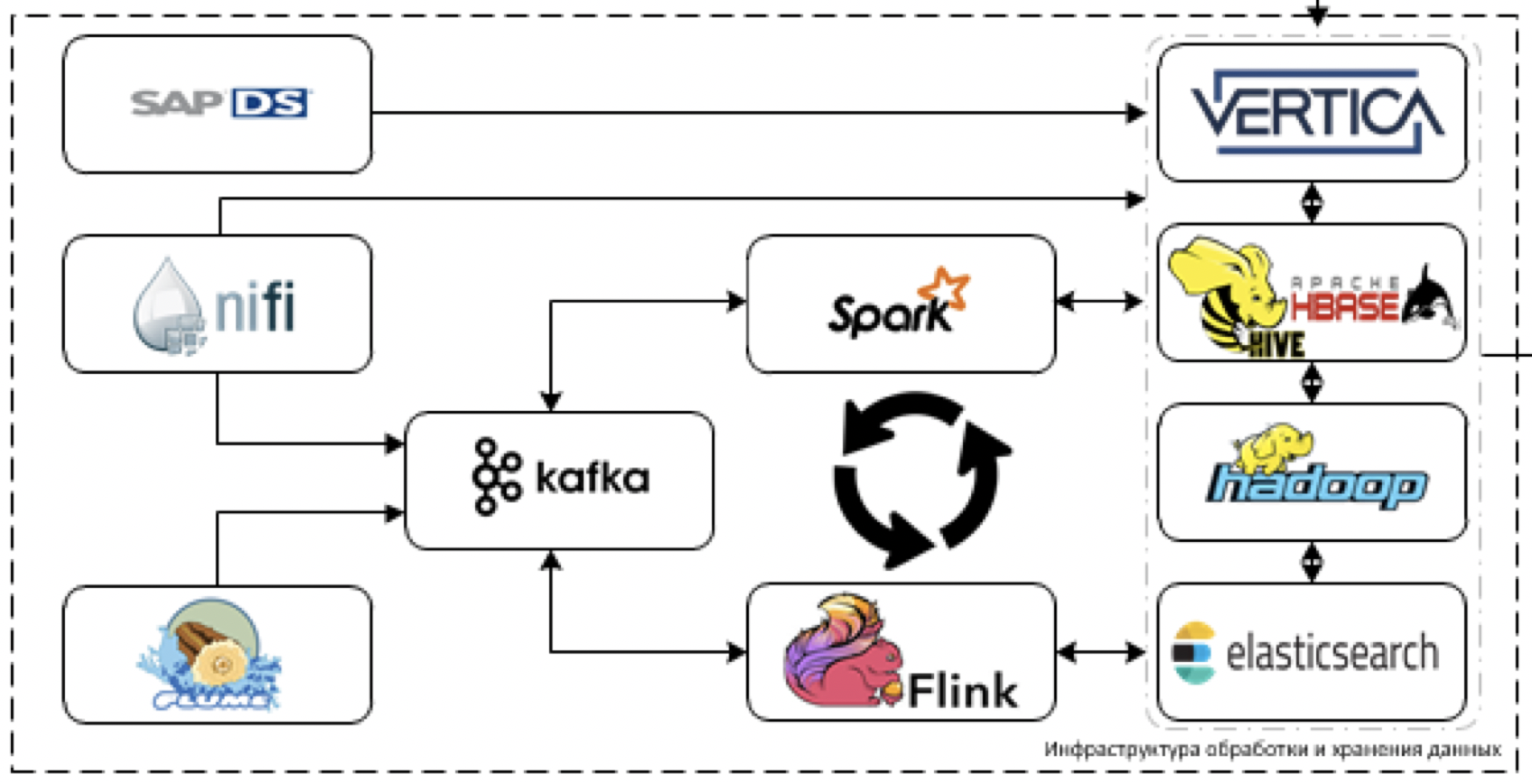
Este es el núcleo central de nuestra plataforma. Lo que se utiliza para procesar y almacenar datos. El desafío es descargar datos de más de 60 sistemas diferentes cuando comienzan a entregarlos. Es decir, generalmente hay todos los datos que pueden ser útiles para tomar algunas decisiones.
Comencemos con la extracción y el procesamiento de datos. Para estos fines, planeamos usar la herramienta NiFi ETL para la transmisión y la transmisión de datos en paquetes, así como herramientas de procesamiento de transmisión: Flume para la recepción y decodificación de datos iniciales, Kafka para el almacenamiento en búfer, Flink y Spark Streaming como las principales herramientas de procesamiento de flujo de datos.
Más difícil de trabajar con sistemas de pila SAP. Debe recuperar datos de SAP utilizando una herramienta ETL separada: SAP Data Services.
Como herramientas de almacenamiento, planeamos utilizar la plataforma Cloudera Hadoop (HDFS, HBASE, Hive, Impala), el DBMS analítico Vertica y, para casos individuales, elástico de búsqueda.
Básicamente, utilizamos la pila más avanzada. Sí, puedes intentar arrojarnos tomates y burlarte de lo que llamamos la pila más moderna, pero de hecho, lo es.
No estamos limitados al desarrollo heredado, pero no podemos usar la vanguardia en una solución industrial debido a la orientación empresarial explícita de nuestra plataforma. Por lo tanto, tal vez no arrastremos a Horton, sino que nos limitemos a Clouder, siempre que sea posible, definitivamente estamos tratando de arrastrar una herramienta más nueva.

SAS Data Quality se usa para controlar la calidad de los datos, y Airflow se usa para administrar toda esta bondad. Monitoreamos toda la plataforma a través de la pila ELK. Planeamos hacer la visualización en su mayor parte en Tableau, algunos informes completamente estáticos en SAP BO.
Ya entendemos que parte de las tareas no se pueden realizar a través de soluciones de BI estándar, ya que se requiere una visualización muy sofisticada en tiempo real con muchos controles de cartón. Por lo tanto, escribiremos nuestro propio marco de visualización, que podría integrarse en productos digitales en desarrollo.
Sobre la plataforma digital
Si mira un poco más ampliamente, ahora nuestros colegas de la función de tecnología digital están construyendo una única plataforma digital, cuya tarea es desarrollar rápidamente nuestras propias aplicaciones.
El lago de datos es uno de los elementos de esta plataforma.
Como parte de esta actividad, entendemos que necesitaremos implementar una interfaz conveniente para acceder a los datos analíticos. Por lo tanto, planeamos implementar la API de datos y el modelo de objetos de producción para un acceso más conveniente a los datos de producción.
¿Qué más hacemos y a quién necesitamos?
Además de almacenar y procesar datos, todo el aprendizaje automático, así como el marco IIoT, funcionarán en nuestra plataforma. El lago actuará como una fuente de datos para la capacitación y los modelos de trabajo, y como una capacidad para los modelos de trabajo. Ya está listo un marco ML que funcionará en la parte superior de la plataforma.

En este momento tengo un equipo, un par de arquitectos y 6 desarrolladores, por lo que estamos buscando activamente nuevas personas (necesito
arquitectos e
ingenieros de datos ) que nos ayuden con el desarrollo de la plataforma. No tiene que hurgar en el legado (el legado está aquí solo a la entrada de los sistemas), la pila es nueva.
Ahí es donde estarán las sutilezas: en las integraciones. Conectar lo viejo con lo nuevo, para que funcione bien y resuelva problemas, es un desafío. Además, será necesario inventar, entrenar y colgar un montón de métricas diferentes.
La recopilación de datos se realiza desde todos los sistemas principales: 1C, SAP y un montón de todo lo demás. Según los datos recopilados aquí, se crearán todos los análisis, todas las predicciones, todos los informes digitales.
En resumen, queremos que los datos funcionen realmente bien. Por ejemplo, marketing y ventas: tienen personas que recopilan todas las estadísticas a mano. Es decir, se sientan y desde 5 sistemas diferentes bombean datos dispares en diferentes formatos, los descargan de 5 programas diferentes y luego descargan todo esto en Excel. Luego resumen la información en tablas unificadas de Excel, de alguna manera intentan hacer la visualización.
En general, el carro lleva todo este tiempo. Queremos resolver tales problemas con nuestra plataforma. Y en las siguientes publicaciones le diremos en detalle cómo conectamos los elementos y configuramos el funcionamiento correcto del sistema.
Por cierto, además de
arquitectos e
ingenieros de datos en este equipo, estaremos encantados de ver: