Fantastic Dizzy es un juego de plataformas y rompecabezas creado en 1991 por Codemasters. Ella es parte de la
serie Dizzy . A pesar de que la serie Dizzy sigue siendo popular y crea juegos de aficionados (
Dizzy Age ), parece que nadie estuvo involucrado en el desarrollo inverso de los juegos originales.
Escribí algunas herramientas simples para extraer, ver y empaquetar los recursos del juego original. Herramientas publicadas en
GitHub .
Desempaquetar EXE
El archivo binario PCDIZZY.EXE está empaquetado en el formato Microsoft
EXEPack . Aunque hay muchas herramientas de Linux que pueden descomprimir dichos ejecutables, ninguno de ellos parece admitir la versión utilizada para Fantastic Dizzy. Por lo tanto, para descomprimir el archivo ejecutable, utilicé la versión DOS de
UNP . Después de desempaquetar el archivo ejecutable, se puede descargar a la IDA. Convenientemente, la versión desempaquetada del archivo binario aún funcionaba bien, por lo que podría depurarse usando el depurador DOSBox.
Archivos de datos
Hay dos archivos de datos en el juego: DIZZY.NDX y DIZZY.RES. Las extensiones, así como los tamaños de archivo, nos dan una pista sobre lo que pueden contener. El archivo NDX tiene aproximadamente 8 KB y el archivo RES tiene aproximadamente 800 KB. Dado que el juego está escrito en C, podemos buscar llamadas abiertas en la IDA para ver dónde se abren los archivos de datos. En los juegos de DOS escritos en ensamblador, para esto debe buscar instrucciones int 21h (para abrir el archivo ah = 3d). El binario Dizzy contiene una función de contenedor alrededor de fopen que le permite especificar el nombre principal y la extensión del archivo. Nos lleva al siguiente bloque de código:
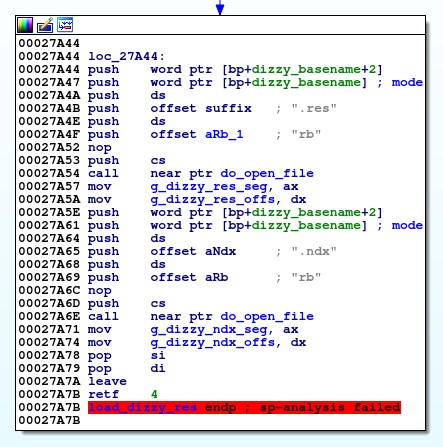
Carga los archivos DIZZY.RES y DIZZY.NDX, y también guarda punteros de archivo en variables globales. Al realizar ingeniería inversa en los binarios de DOS, surge un problema molesto: los registros que contienen son de 16 bits, pero los punteros en algunos casos pueden ser de 32 bits. Aquí los punteros FILE * tienen un tamaño de 32 bits y se devuelven de do_open_file a ax: dx. Tenga en cuenta que las cadenas también son punteros de 32 bits, y dizzy_basename se pasa a la función de llamada en la pila (y este autoanálisis IDA confuso, se consideró un argumento de modo para fopen).
Al buscar las ocurrencias de g_dizzy_res / ndx en xrefs, puede encontrar dónde se leen los archivos. En este punto, el depurador de DOSBox es útil porque hay una alta probabilidad de muchas operaciones de lectura de archivos al azar, y usar un IDA para determinar las compensaciones de lectura sería un proceso bastante monótono.
Aquí se puede encontrar una buena guía para construir y usar el depurador DOSBox.
Cuando se usa el IDA y el depurador DOSBox juntos, se hace evidente que el archivo NDX se usa como un índice para el archivo RES. Cada entrada en el archivo NDX toma 16 bytes; almacena el identificador de fragmento, su tamaño y desplazamiento en el archivo RES. Al observar cómo se leen los datos RES, puede ver que el byte de marca se verifica primero en el archivo NDX. Si no se establece el bit 0x80, los datos se leen directamente desde el archivo RES; de lo contrario, se ejecuta una ruta de código más compleja. El indicador está configurado para la mayoría de los fragmentos, por lo que con un alto grado de probabilidad podemos suponer que denota algún tipo de compresión utilizada para estos fragmentos.
Compresión
La ruta de compresión comienza leyendo desde la base del fragmento RES dos palabras de 32 bits que indican los tamaños inicial y final, y luego se llama a la función de descompresión. En 1991, la codificación de longitud de ejecución simple (RLE) y la compresión de diccionario fueron populares, como varios algoritmos Liv-Zempel. El comienzo del ciclo de desempaquetado se ve así:
Los tokens para desempaquetar se obtienen usando la función get_next_token, que lee la siguiente parte de los datos de origen en ax: dx con un cambio por cl. El registro cl se usa como la posición del cambio de bit, volviendo a cero después de llegar a ocho. Al comienzo del ciclo, se lee el token y se comprueba el bit inferior. Si se establece la bandera, entonces el código es simple:
Simplemente guarda el byte actual, recibe el siguiente token y continúa trabajando. Si se borra la bandera, se selecciona una ruta de código más larga, que termina con la instrucción rep movsb. Esto indica que se usa algún tipo de diccionario en la compresión.
El algoritmo de compresión es interesante por varias razones. En primer lugar, utiliza codificación de longitud de bits variable. El valor absoluto se codifica como 1 indicador y un valor de datos de 8 bits. Curiosamente, el flujo de bits está codificado como little endian. Esto complica un poco el análisis de descompresión al observar el archivo RES en un editor hexadecimal. Por ejemplo, si los primeros tres bytes de un fragmento están codificados como valores absolutos, los datos se ordenan de la siguiente manera:
: AAAAAAAA BBBBBBBB CCCCCCCC DDDDDDDD 1: 6543210F 7 2: 543210F 76 3: 43210F 765
Además, el desempacador puede omitir el byte al leer, si el contador cl vuelve a cero al recibir el siguiente token. No sé si esto es optimización, o un error, o un truco creado por el desarrollador del juego para solucionar el problema con mis herramientas.
Si se borra el indicador, el desempacador realiza la copia de la parte inicial de los datos desempaquetados. En este caso, los siguientes bits codifican la longitud y el desplazamiento desde el cual copiar. El desplazamiento está codificado en 10 o 13 bits, y la opción deseada indica la bandera. Esto parece una elección muy extraña, porque complica un poco el código y, en el mejor de los casos, solo guarda 2 bits.
Codificar la duración de la serie parece un poco extraño. El desempacador lee los bits hasta que alcanza el bit cero. Entonces, el número de bits utilizados para codificar la longitud es dos más el número de bits distintos de cero. Por ejemplo, al codificar una longitud de 58 (0x3a), el flujo de bits se ve así:
11110 111010
La codificación requiere 11 bits. Las longitudes pequeñas están mejor codificadas porque la longitud mínima de bits es 2. Copiar longitudes de hasta 3 requiere solo 3 bits para codificar, hasta 7 requiere 5 bits, y así sucesivamente. No estoy seguro si este tipo de codificación es una técnica común.
El depurador DOSBox también es muy útil para reconstruir el algoritmo de descompresión. Si no sabe cómo deberían ser los datos descomprimidos, es difícil entender si el desempacador funciona correctamente. Usando el depurador, puede recorrer todo el algoritmo de descompresión y guardar un volcado de memoria desempaquetada para comparar.
Otra característica útil es la bandera en el archivo NDX, que indica que el recurso está comprimido. Dado que el juego original admite recursos desempaquetados, podemos reempaquetar el archivo RES sin la necesidad de un algoritmo de compresión. Modificar y volver a empaquetar fragmentos con el lanzamiento posterior del juego es una buena forma de probar nuestras suposiciones sobre los formatos de datos.
Niveles
Fantastic Dizzy es un juego con un mundo abierto. Los niveles son áreas con desplazamiento vertical u horizontal. El jugador se mueve entre niveles, llegando al final del nivel o entrando y saliendo de edificios. Aunque las referencias a los fragmentos en el archivo RES se hacen a través de identificadores (ID) de 16 bits, el archivo binario del juego en realidad contiene una tabla de nombres de niveles coincidentes con identificadores de fragmentos. Cada nivel consta de varios fragmentos: un título, una o más capas, un mosaico y una paleta. Aquí hay poca redundancia, porque algunos niveles usan la misma paleta y mosaico, pero no reutilizan los mismos fragmentos, por lo que el archivo RES contiene muchos recursos duplicados.
Las capas codifican mosaicos para un nivel. Para diferentes partes del mundo o para capas de fondo, puede usar capas adicionales. Por ejemplo, en el nivel de tree1.stg, hay ocho capas para diferentes partes de las copas de los árboles y una capa de fondo común. Sin embargo, los niveles submarinos se dividen en sea1.stg y sea2.stg, cada uno de los cuales tiene una capa de primer plano y una capa de fondo.
Las capas de fondo son fondos de ancho fijo sin desplazamiento, por ejemplo, un bosque en una parte de un juego con copas de árboles. Los mosaicos de primer plano y de fondo, que se encuentran delante y detrás del personaje, están codificados en la misma capa que los mosaicos sobre los que puedes caminar. Por ejemplo, la captura de pantalla muestra el nivel desde la parte superior de los árboles desde el comienzo del juego:
Nivel de copa de árbolEs la séptima capa de tree1.stg:
Séptimo nivel de capa tree1.stgVale la pena señalar que el jugador puede pasar frente a la cabaña, pero detrás de dos árboles. Toda la información de mosaico está contenida en una matriz de mapa de mosaico ubicada en una capa. Los mosaicos en los fragmentos de la capa están codificados en dos bytes, y los 9 bits inferiores se utilizan para el índice de mosaico. No entendí completamente los bits superiores, pero al menos contienen información sobre el desplazamiento de la paleta para el mosaico y, probablemente, información sobre colisiones.
Como niveles en el juego, también se almacenan escenas, retratos de personajes y una pantalla de control de inventario. Parece que esta técnica es estándar para los juegos de DOS, probablemente porque minimiza la cantidad de código necesario.
"Nivel" de gestión de inventarioSprites
El formato de sprite no es particularmente interesante. Cada sprite es un mapa de bits con un byte por píxel, pero con solo 16 colores por sprite. El uso de un número limitado de colores era una técnica común en la era del VGA de 256 colores, porque para los sprites era fácil realizar un cambio de paleta o usarlos en niveles con otras paletas; Además, ahorró el espacio asignado a los sprites.
Los sprites tienen diferentes tamaños, por lo que un fragmento separado contiene información sobre el tamaño del sprite y sus desplazamientos en x e y. Los sprites se agrupan en conjuntos, pero la agrupación parece bastante arbitraria. Por ejemplo, un conjunto de sprites contiene gráficos de protector de pantalla, objetos de inventario, así como algunos personajes que no son jugadores. Esto hace que la visualización de conjuntos de sprites sea un poco complicada porque la paleta no es la misma para todos los sprites.
Sprites del personaje del jugador¿Qué más queda?
Queda por hacer ingeniería inversa algunas cosas más. Principalmente me interesan los formatos de archivos de datos, pero hay algunos aspectos que no entiendo:
- ¿Dónde están las ubicaciones de los objetos (llaves, frutas, etc.). Parece que no están escritos en fragmentos de nivel. Quizás estén almacenados en el archivo binario del juego, porque el jugador puede recoger un objeto en un nivel y lanzarlo en otro.
- Cómo funcionan las colisiones de nivel. Un jugador puede caminar delante o detrás de algunas baldosas, y los pisos pueden ser planos o inclinados.
- Cómo están conectados los niveles. Esta información se puede almacenar en el binario del juego.
- El desplazamiento de la paleta para los mosaicos en los niveles no es del todo correcto. Algunos mosaicos muestran colores incorrectos.
- Cada conjunto de sprites tiene tres fragmentos: encabezado, tabla y datos. Los fragmentos con una tabla y datos son claros para mí, pero en el encabezado se incluye cierta información sobre los sprites, por ejemplo, el desplazamiento de x e y. No entendí su formato por completo.