Con la difusión y el desarrollo de las redes neuronales, existe una creciente necesidad de usarlas en dispositivos integrados, de baja potencia, robots y drones. El dispositivo Neural Compute Stick junto con el marco Intel OpenVINO nos permite resolver este problema asumiendo los pesados cálculos de las redes neuronales. Gracias a esto, puede lanzar fácilmente un clasificador o detector de red neuronal en un dispositivo de baja potencia como el Raspberry Pi en tiempo casi real, sin aumentar en gran medida el consumo de energía. En esta publicación, le mostraré cómo usar el marco OpenVINO (en C ++) y el Neural Compute Stick para lanzar un sistema simple de detección de rostros en la Raspberry Pi.
Como de costumbre, todo el código está disponible en
GitHub .

Un poco sobre Neural Compute Stick y OpenVINO
En el verano de 2017, Intel lanzó el dispositivo
Neural Compute Stick (NCS), diseñado para ejecutar redes neuronales en dispositivos de baja potencia, y después de un par de meses se pudo comprar y probar, lo cual hice. NCS es un pequeño módulo informático con una carcasa de color azul (que también actúa como un radiador), conectado al dispositivo principal a través de USB. En el interior, entre otras cosas, se encuentra la Intel Myriad
VPU , que es esencialmente un procesador paralelo de 12 núcleos, enfocado para operaciones que a menudo ocurren en redes neuronales. NCS no es adecuado para entrenar redes neuronales, pero la inferencia en redes neuronales ya entrenadas es comparable en velocidad a la de la GPU. Todos los cálculos en NCS se realizan en números flotantes de 16 bits, lo que le permite aumentar la velocidad. NCS requiere solo 1 vatio de potencia para funcionar, es decir, a 5 V, se consume una corriente de hasta 200 mA en el conector USB; esto es incluso menos que la cámara para la Raspberry Pi (250 mA).

Para trabajar con el primer NCS, se utilizó el
Neural Compute SDK (NCSDK): incluye herramientas para compilar redes neuronales en formatos
Caffe y
TensorFlow en formato NCS, herramientas para medir su rendimiento, así como Python y C ++ API para inferencia.
Luego se lanzó una nueva versión del marco NCS:
NCSDK2 . La API ha cambiado bastante y, aunque algunos cambios me parecieron extraños, hubo algunas innovaciones útiles. En particular, se agregó la conversión automática de flotante de 32 bits a flotante de 16 bits a C ++ (antes, las muletas tenían que insertarse en forma de código de Numpy). También aparecieron colas de imágenes y sus resultados de procesamiento.
En mayo de 2018, Intel lanzó
OpenVINO (anteriormente llamado Intel Computer Vision SDK). Este marco está diseñado para lanzar redes neuronales de manera eficiente en varios dispositivos: procesadores Intel y tarjetas gráficas,
FPGA , así como el Neural Compute Stick.
En noviembre de 2018, se lanzó una nueva versión del acelerador:
Neural Compute Stick 2 . La potencia informática del dispositivo se ha incrementado: en la descripción en el sitio prometen una aceleración de hasta 8 veces, sin embargo, no pude probar la nueva versión del dispositivo. La aceleración se logra al aumentar el número de núcleos de 12 a 16, así como al agregar nuevos dispositivos informáticos optimizados para redes neuronales. Es cierto que no encontré información sobre el consumo de energía de la información.
La segunda versión de NCS ya es incompatible con NCSDK o NCSDK2: OpenVINO, que es capaz de trabajar con muchos otros dispositivos además de ambas versiones de NCS, pasó su autoridad. OpenVINO tiene una gran funcionalidad e incluye los siguientes componentes:
- Model Optimizer: secuencia de comandos Python que le permite convertir redes neuronales de marcos de aprendizaje profundo populares al formato universal OpenVINO. La lista de marcos compatibles: Caffe , TensorFlow , MXNET , Kaldi (marco de reconocimiento de voz), ONNX (formato abierto para representar redes neuronales).
- Motor de inferencia: API C ++ y Python para inferencia de red neuronal, abstraída de un dispositivo de inferencia específico. El código API se verá casi idéntico para CPU, GPU, FPGA y NCS.
- Un conjunto de complementos para diferentes dispositivos. Los complementos son bibliotecas dinámicas que se cargan explícitamente en el código del programa principal. Estamos más interesados en el complemento para NCS.
- Un conjunto de modelos pre-entrenados en el formato universal OpenVINO (la lista completa está aquí ). Una impresionante colección de redes neuronales de alta calidad: detectores de rostros, peatones, objetos; reconocimiento de la orientación de caras, puntos especiales de caras, posturas humanas; super resolución; y otros Vale la pena señalar que no todos ellos son compatibles con NCS / FPGA / GPU.
- Descargador de modelos: otro script que simplifica la descarga de modelos en formato OpenVINO a través de la red (aunque puede hacerlo fácilmente sin él).
- Biblioteca de visión por computadora OpenCV optimizada para hardware Intel.
- Biblioteca de visión por computadora OpenVX .
- Intel Compute Library para redes neuronales profundas .
- Intel Math Kernel Library para redes neuronales profundas .
- Una herramienta para optimizar redes neuronales para FPGA (opcional).
- Documentación y programas de muestra.
En mis artículos anteriores, hablé sobre cómo ejecutar el detector facial YOLO en el NCS
(primer artículo) , así como sobre cómo entrenar su detector facial SSD y ejecutarlo en el Raspberry Pi y el NCS
(segundo artículo) . En estos artículos, usé NCSDK y NCSDK2. En este artículo, le diré cómo hacer algo similar, pero usando OpenVINO, haré una pequeña comparación de los dos detectores faciales diferentes y dos marcos para lanzarlos, y señalaré algunas trampas. Escribo en C ++, porque creo que de esta manera puedes lograr un mejor rendimiento, lo que será importante en el caso de Raspberry Pi.
Instalar OpenVINO
No es la tarea más difícil, aunque hay sutilezas. Al momento de escribir esto, OpenVINO solo es compatible con Ubuntu 16.04 LTS, CentOS 7.4 y Windows 10. Tengo Ubuntu 18 y necesito
pequeñas muletas para instalarlo. También quería comparar OpenVINO con NCSDK2, cuya instalación también tiene problemas: en particular, ajusta sus versiones de Caffe y TensorFlow y puede romper ligeramente la configuración del entorno. Al final, decidí seguir un camino simple e instalar ambos marcos en una máquina virtual con Ubuntu 16 (uso
VirtualBox ).
Vale la pena señalar que para conectar con éxito NCS a una máquina virtual, debe instalar complementos invitados VirtualBox y habilitar la compatibilidad con USB 3.0. También agregué un filtro universal para dispositivos USB, como resultado de lo cual el NCS se conectó sin problemas (aunque la cámara web todavía tiene que estar conectada en la configuración de la máquina virtual). Para instalar y compilar OpenVINO, debe tener una cuenta Intel, elegir una opción de marco (con o sin soporte FPGA) y seguir las
instrucciones . NCSDK es aún más simple: arranca
desde GitHub (no olvide seleccionar la rama ncsdk2 para la nueva versión del marco), después de lo cual debe
make install .
El único problema que encontré al ejecutar NCSDK2 en una máquina virtual es un error de la siguiente forma:
E: [ 0] dispatcherEventReceive:236 dispatcherEventReceive() Read failed -1 E: [ 0] eventReader:254 Failed to receive event, the device may have reset
Ocurre al final de la ejecución correcta del programa y (parece) no afecta nada. Aparentemente, este es un
pequeño error relacionado con VM (esto no debería estar en Raspberry).
La instalación en Raspberry Pi es significativamente diferente. Primero, asegúrese de tener Raspbian Stretch instalado: ambos marcos solo funcionan oficialmente en este sistema operativo. NCSDK2 debe
compilarse en modo solo API , de lo contrario, intentará instalar Caffe y TensorFlow, lo que es poco probable que complazca a su Raspberry. En el caso de OpenVINO, hay una
versión ya
ensamblada para Raspberry , que solo necesita desempaquetar y configurar las variables de entorno. En esta versión solo hay C ++ y Python API, así como la biblioteca OpenCV, todas las demás herramientas no están disponibles. Esto significa que para ambos marcos, los modelos deben convertirse por adelantado en una máquina con Ubuntu. Mi
demostración de detección de rostros funciona tanto en Raspberry como en el escritorio, por lo que acabo de agregar los archivos de red neuronal convertidos a mi repositorio de GitHub para facilitar la sincronización con Raspberry. Tengo un Raspberry Pi 2 modelo B, pero debería despegar con otros modelos.
Hay otra sutileza con respecto a la interacción de la Raspberry Pi y el Neural Compute Stick: si en el caso de una computadora portátil es suficiente con meter el NCS en el puerto USB 3.0 más cercano, entonces para Raspberry tendrá que encontrar un cable USB, de lo contrario NSC bloqueará los tres conectores USB restantes con su cuerpo. También vale la pena recordar que Raspberry tiene todas las versiones de USB 2.0, por lo que la tasa de inferencia será menor debido a retrasos en la comunicación (una comparación detallada será más adelante). Pero si desea conectar dos o más NCS a Raspberry, lo más probable es que tenga que encontrar un concentrador USB con alimentación adicional.
¿Cómo se ve el código OpenVINO?
Bastante voluminoso. Hay muchas acciones diferentes que hacer, comenzando con la carga del complemento y terminando con la inferencia misma; es por eso que escribí una clase de envoltura para el detector. El código completo se puede ver en GitHub, pero aquí solo enumero los puntos principales. Comencemos en orden:
Las definiciones de todas las funciones que necesitamos están en el archivo
inference_engine.hpp en el espacio de nombres
InferenceEngine .
#include <inference_engine.hpp> using namespace InferenceEngine;
Las siguientes variables serán necesarias todo el tiempo. necesitamos
inputName y
outputName para abordar la entrada y salida de la red neuronal. En términos generales, una red neuronal puede tener muchas entradas y salidas, pero en nuestros detectores habrá una a la vez. La variable
net es la red misma, la
request es un puntero a la última solicitud de inferencia,
inputBlob es un puntero a la matriz de datos de entrada de la red neuronal. Las variables restantes hablan por sí mismas.
string inputName; string outputName; ExecutableNetwork net; InferRequest::Ptr request; Blob::Ptr inputBlob;
Ahora descargue el complemento necesario: necesitamos el responsable de NCS y NCS2, se puede obtener con el nombre "MYRIAD". Permítame recordarle que en el contexto de OpenVINO, un complemento es solo una biblioteca dinámica que se conecta por solicitud explícita. El parámetro de la función
PluginDispatcher es una lista de directorios en los que buscar complementos. Si configura las variables de entorno de acuerdo con las instrucciones, una línea vacía será suficiente. Como referencia, los complementos están en
[OpenVINO_install_dir]/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64/ InferencePlugin plugin = PluginDispatcher({""}).getPluginByDevice("MYRIAD");
Ahora cree un objeto para cargar la red neuronal, considere su descripción y configure el tamaño del lote (el número de imágenes procesadas simultáneamente). Una red neuronal en el formato OpenVINO está definida por dos archivos: un .xml con una descripción de la estructura y un .bin con pesos. Si bien utilizaremos detectores listos para usar de OpenVINO, luego crearemos el nuestro. Aquí
std::string filename es el nombre del archivo sin la extensión. También debe tener en cuenta que el NCS solo admite un tamaño de lote de 1.
CNNNetReader netReader; netReader.ReadNetwork(filename+".xml"); netReader.ReadWeights(filename+".bin"); netReader.getNetwork().setBatchSize(1);
Entonces sucede lo siguiente:
- Para ingresar a la red neuronal, establezca el tipo de datos en char sin firmar de 8 bits. Esto significa que podemos ingresar la imagen en el formato en que proviene de la cámara, e InferenceEngine se encargará de la conversión (NCS realiza cálculos en formato flotante de 16 bits). Esto se acelerará un poco en la Raspberry Pi; según tengo entendido, la conversión se realiza en el NCS, por lo que hay menos retrasos en la transferencia de datos a través de USB.
- Obtenemos los nombres de entrada y salida, para que luego podamos acceder a ellos.
- Obtenemos la descripción de las salidas (este es un mapa del nombre de la salida a un puntero a un bloque de datos). Obtenemos un puntero al bloque de datos de la primera salida (única).
- Obtenemos su tamaño: 1 x 1 x número máximo de detecciones x longitud de la descripción de la detección (7). Sobre el formato de la descripción de detecciones - más adelante.
- Establezca el formato de salida en flotante de 32 bits. Nuevamente, la conversión de flotante de 16 bits se encarga de InferenceEngine.
Ahora el punto más importante: cargamos la red neuronal en el complemento (es decir, en NCS). Aparentemente, la compilación al formato deseado está sobre la marcha. Si el programa falla en esta función, la red neuronal probablemente no sea adecuada para este dispositivo.
net = plugin.LoadNetwork(netReader.getNetwork(), {});
Y finalmente, haremos una inferencia de prueba y obtendremos los tamaños de entrada (tal vez esto se puede hacer de manera más elegante). Primero, abrimos una solicitud de inferencia, luego de ella obtenemos un enlace al bloque de datos de entrada, y ya le solicitamos el tamaño.
Intentemos subir una imagen a NCS. De la misma manera, creamos una solicitud de inferencia, obtenemos un puntero a un bloque de datos, y desde allí obtenemos un puntero a la matriz en sí. A continuación, simplemente copie los datos de nuestra imagen (aquí ya está reducida al tamaño deseado). Vale la pena señalar que en
cv::Mat y
inputBlob mediciones se almacenan en diferente orden (en OpenCV, el índice del canal cambia más rápido que todos, en OpenVINO es más lento que todos), por lo que memcpy es indispensable. Entonces comenzamos la inferencia asincrónica.
¿Por qué asíncrono? Esto optimizará la asignación de recursos. Si bien el NCS considera la red neuronal, puede procesar el siguiente marco, lo que conducirá a una aceleración notable en la Raspberry Pi.
cv::Mat data; ...
Si conoce bien las redes neuronales, es posible que tenga una pregunta sobre en qué punto escalamos los valores de los píxeles de entrada de la red neuronal (por ejemplo, lo llevamos al rango
) El hecho es que en los modelos OpenVINO esta transformación ya está incluida en la descripción de la red neuronal, y cuando usamos nuestro detector haremos algo similar. Y dado que tanto la conversión a flotante como la escala de entradas son realizadas por OpenVINO, solo necesitamos cambiar el tamaño de la imagen.
Ahora (después de hacer un trabajo útil) completaremos la solicitud de inferencia. El programa está bloqueado hasta que lleguen los resultados de la ejecución. Obtenemos un puntero al resultado.
float * output; ncsCode = request->Wait(IInferRequest::WaitMode::RESULT_READY); output = request->GetBlob(outputName)->buffer().as<float*>();
Ahora es el momento de pensar en qué formato el NCS devuelve el resultado del detector. Vale la pena señalar que el formato es ligeramente diferente de lo que era cuando se usa NCSDK. En términos generales, la salida del detector es de cuatro dimensiones y tiene una dimensión (1 x 1 x número máximo de detecciones x 7), podemos suponer que se trata de una matriz de tamaño (
maxNumDetectedFaces x 7).
El parámetro
maxNumDetectedFaces se establece en la descripción de la red neuronal, y es fácil cambiarlo, por ejemplo, en la descripción .prototxt de la red en formato Caffe. Anteriormente lo obtuvimos del objeto que representa el detector. Este parámetro está relacionado con los detalles de la clase de detectores
SSD (Single Shot Detector) , que incluye todos los detectores NCS compatibles. Un SSD siempre considera el mismo (y muy grande) número de cuadros delimitadores para cada imagen, y después de filtrar las detecciones con una baja calificación de confianza y eliminar los marcos superpuestos utilizando la supresión no máxima, generalmente dejan el mejor 100-200. Esto es precisamente de lo que es responsable el parámetro.
Los siete valores en la descripción de una detección son los siguientes:
- el número de imagen en el lote en el que se detecta el objeto (en nuestro caso, debería ser cero);
- clase de objeto (0 - fondo, a partir de 1 - otras clases, solo se devuelven detecciones con una clase positiva);
- confianza en presencia de detección (en el rango );
- Coordenada x normalizada de la esquina superior izquierda del cuadro delimitador (en el rango );
- de manera similar - coordenada y;
- ancho del cuadro delimitador normalizado (en el rango );
- igualmente - altura;
Código para extraer cuadros delimitadores de la salida del detector void get_detection_boxes(const float* predictions, int numPred, int w, int h, float thresh, std::vector<float>& probs, std::vector<cv::Rect>& boxes) { float score = 0; float cls = 0; float id = 0;
aprendemos
numPred del detector en sí, y
w,h - tamaños de imagen para visualización.
Ahora sobre cómo se ve el esquema general de inferencia en tiempo real. Primero inicializamos la red neuronal y la cámara, iniciamos
cv::Mat para cuadros en bruto y uno más para cuadros reducidos al tamaño deseado. Llenamos nuestros cuadros con ceros; esto agregará confianza de que en un solo inicio la red neuronal no encontrará nada. Luego comenzamos el ciclo de inferencia:
- Cargamos la trama actual en la red neuronal mediante una solicitud asincrónica: NCS ya ha comenzado a funcionar, y en este momento tenemos la oportunidad de hacer que el procesador principal funcione de manera útil.
- Mostramos todas las detecciones anteriores en el cuadro anterior, dibujamos un cuadro (si es necesario).
- Obtenemos un nuevo marco de la cámara, lo comprimimos al tamaño deseado. Para Raspberry, recomiendo usar el algoritmo de cambio de tamaño más simple: en OpenCV, esta es la interpolación de vecinos más cercanos. Esto no afectará la calidad del rendimiento del detector, pero puede agregar un poco de velocidad. También reflejo el marco para una fácil visualización (opcional).
- Ahora es el momento de obtener el resultado con NCS completando la solicitud de inferencia. El programa se bloqueará hasta que se reciba el resultado.
- Procesamos nuevas detecciones, seleccionamos fotogramas.
- El resto: trabajar pulsaciones de teclas, contar cuadros, etc.
Cómo compilarlo
En los ejemplos de InferenceEngine, no me gustaron los voluminosos archivos CMake, y decidí reescribir todo de manera compacta en mi Makefile:
g++ $(RPI_ARCH) \ -I/usr/include -I. \ -I$(OPENVINO_PATH)/deployment_tools/inference_engine/include \ -I$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/include \ -L/usr/lib/x86_64-linux-gnu \ -L/usr/local/lib \ -L$(OPENVINO_PATH)/deployment_tools/inference_engine/lib/ubuntu_16.04/intel64 \ -L$(OPENVINO_PATH_RPI)/deployment_tools/inference_engine/lib/raspbian_9/armv7l \ vino.cpp wrapper/vino_wrapper.cpp \ -o demo -std=c++11 \ `pkg-config opencv --cflags --libs` \ -ldl -linference_engine $(RPI_LIBS)
Este equipo trabajará tanto en Ubuntu como en Raspbian, gracias a un par de trucos. Las rutas para buscar encabezados y bibliotecas dinámicas que he indicado tanto para Raspberry como para la máquina Ubuntu. De las bibliotecas, además de OpenCV, también debe conectar
libinference_engine y
libdl , una biblioteca para vincular dinámicamente otras bibliotecas, es necesaria para cargar el complemento. Al mismo tiempo,
libmyriadPlugin no necesita ser especificado. Entre otras cosas, para Raspberry también conecto la biblioteca
Raspicam para trabajar con la cámara (esto es
$(RPI_LIBS) ). También tuve que usar el estándar C ++ 11.
Por separado, vale la pena señalar que al compilar en Raspberry, se necesita la
-march=armv7-a (esto es
$(RPI_ARCH) ). Si no lo especifica, el programa se compilará, pero se bloqueará con un segfault silencioso. También puede agregar optimizaciones usando
-O3 , esto agregará velocidad.
¿Qué son los detectores?
NCS solo admite detectores SSD Caffe de la caja, aunque con un par de trucos sucios logré ejecutar
YOLO desde el formato Darknet en él.
Single Shot Detector (SSD) es una arquitectura popular entre las redes neuronales livianas, y con la ayuda de diferentes codificadores (o redes troncales) puede variar con bastante flexibilidad la relación de velocidad y calidad.
Experimentaré con diferentes detectores faciales:
- YOLO, tomado de aquí , convertido primero al formato Caffe, luego al formato NCS (solo con NCSDK). Imagen 448 x 448.
- Mi detector Mobilenet + SSD, sobre el entrenamiento del que hablé en una publicación anterior . Todavía tengo una versión recortada de este detector, que solo ve caras pequeñas, y al mismo tiempo un poco más rápido. Comprobaré la versión completa de mi detector tanto en NCSDK como en OpenVINO. Imagen 300 x 300.
- Detector de detección de rostros-adas-0001 de OpenVINO: MobileNet + SSD. Imagen 384 x 672.
- Detector OpenVINO de detección de rostros-retail-0004: SqueezeNet + SSD liviano. Imagen 300 x 300.
Para los detectores de OpenVINO, no hay escalas ni en el formato Caffe ni en el formato NCSDK, por lo que solo puedo iniciarlos en OpenVINO.
Transforme su detector en formato OpenVINO
Tengo dos archivos en formato Caffe: .prototxt con una descripción de la red y .caffemodel con pesos. Necesito obtener dos archivos de ellos en el formato OpenVINO: .xml y .bin con una descripción y pesos, respectivamente. Para hacer esto, use el script mo.py de OpenVINO (también conocido como Model Optimizer):
mo.py \ --framework caffe \ --input_proto models/face/ssd-face.prototxt \ --input_model models/face/ssd-face.caffemodel \ --output_dir models/face \ --model_name ssd-vino-custom \ --mean_values [127.5,127.5,127.5] \ --scale_values [127.5,127.5,127.5] \ --data_type FP16
output_dir especifica el directorio en el que se crearán los archivos nuevos,
model_name es el nombre de los archivos nuevos sin extensión,
data_type (FP16/FP32) es el tipo de equilibrio en la red neuronal (NCS solo admite FP16). Los
mean_values, scale_values establecen el promedio y la escala para preprocesar las imágenes antes de que se inicien en la red neuronal. La conversión específica se ve así:
En este caso, los valores se convierten del rango
en rango
. En general, este script tiene muchos parámetros, algunos de los cuales son específicos de marcos individuales, le recomiendo que consulte el manual del script.
La distribución OpenVINO para Raspberry no tiene modelos listos, pero son bastante fáciles de descargar.
Por ejemplo, así. wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.xml \ -O ./models/face/vino.xml; \ wget --no-check-certificate \ https://download.01.org/openvinotoolkit/2018_R4/open_model_zoo/face-detection-retail-0004/FP16/face-detection-retail-0004.bin \ -O ./models/face/vino.bin
Comparación de detectores y marcos
Utilicé tres opciones de comparación: 1) Máquina virtual NCS + con Ubuntu 16.04, procesador Core i7, conector USB 3.0; 2) NCS + La misma máquina, conector USB 3.0 + cable USB 2.0 (habrá más demoras en el intercambio con el dispositivo); 3) NCS + Raspberry Pi 2 modelo B, Raspbian Stretch, conector USB 2.0 + cable USB 2.0.
Comencé mi detector con OpenVINO y NCSDK2, detectores de OpenVINO solo con su marco nativo, YOLO solo con NCSDK2 (lo más probable, también se puede ejecutar en OpenVINO).
La tabla FPS para diferentes detectores se ve así (los números son aproximados):
| Modelo | USB 3.0 | USB 2.0 | Raspberry pi |
|---|
| SSD personalizado con NCSDK2 | 10,8 | 9.3 | 7.2 |
| SSD longrange personalizado con NCSDK2 | 11,8 | 10,0 | 7.3 |
| YOLO v2 con NCSDK2 | 5.3 | 4.6 | 3.6 |
| SSD personalizado con OpenVINO | 10,6 | 9,9 | 7,9 |
| OpenVINO detección de rostros-retail-0004 | 15,6 | 14,2 | 9.3 |
| OpenVINO detección de rostros-adas-0001 | 5.8 | 5.5 | 3.9 |
Nota: el rendimiento se midió para todo el programa de demostración, incluido el procesamiento y la visualización de fotogramas.YOLO fue el más lento e inestable de todos. Muy a menudo omite la detección y no puede funcionar con marcos iluminados.
El detector que entrené funciona dos veces más rápido, es más resistente a la distorsión en los cuadros e incluso detecta rostros pequeños. Sin embargo, a veces omite la detección y a veces detecta falsos. Si le cortas las últimas capas, se volverá un poco más rápido, pero dejará de ver caras grandes. El mismo detector lanzado a través de OpenVINO se vuelve un poco más rápido cuando se usa USB 2.0, la calidad no cambia visualmente.
Los detectores OpenVINO, por supuesto, son muy superiores tanto a YOLO como a mi detector. (Ni siquiera comenzaría a entrenar mi detector si OpenVINO existiera en su forma actual en ese momento). El modelo retail-0004 es significativamente más rápido y, al mismo tiempo, prácticamente no pierde la cara, pero logré engañarlo un poco (aunque la confianza en estas detecciones es baja):
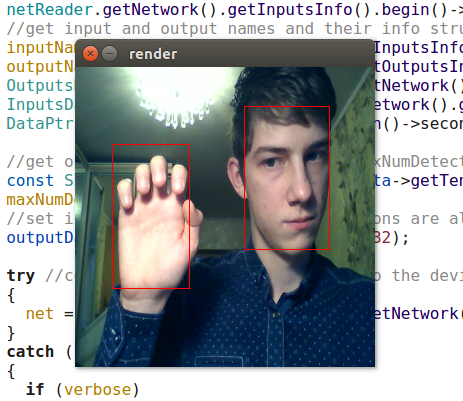 Ataque competitivo de inteligencia natural sobre artificial
Ataque competitivo de inteligencia natural sobre artificialEl detector adas-0001 es mucho más lento, pero funciona con imágenes grandes y debería ser más preciso. No noté la diferencia, pero revisé cuadros bastante simples.
Conclusión
En general, es muy bueno que en un dispositivo de baja potencia como el Raspberry Pi pueda usar redes neuronales, e incluso en tiempo casi real. OpenVINO proporciona una funcionalidad muy extensa para la inferencia de redes neuronales en muchos dispositivos diferentes, mucho más amplio de lo que describí en el artículo.
Creo que Neural Compute Stick y OpenVINO serán muy útiles en mi investigación robótica.