En nuestra era, las máquinas han logrado con éxito una precisión del 99% en la comprensión y definición de características y objetos en las imágenes. Nos enfrentamos a esto todos los días, por ejemplo: reconocimiento facial en la cámara del teléfono inteligente, la capacidad de buscar fotos en Google, escanear texto de un código de barras o libros a una buena velocidad, etc. Tal eficiencia de la máquina fue posible gracias a un tipo especial de red neuronal llamada neuronal convolucional la red Si eres un entusiasta del aprendizaje profundo, es probable que hayas escuchado al respecto y podrías desarrollar varios clasificadores de imágenes. Los marcos modernos de aprendizaje profundo como Tensorflow y PyTorch simplifican el aprendizaje automático de imágenes. Sin embargo, la pregunta sigue siendo: ¿cómo pasan los datos a través de las capas de la red neuronal y cómo la computadora aprende de ellos? Para obtener una vista clara desde cero, nos sumergimos en una convolución, visualizando la imagen de cada capa.

Redes neuronales convolucionales
Antes de comenzar a estudiar redes neuronales convolucionales (SNA), debe aprender a trabajar con redes neuronales. Las redes neuronales imitan el cerebro humano para resolver problemas complejos y buscar patrones en los datos. En los últimos años, han reemplazado muchos algoritmos de aprendizaje automático y visión por computadora. El modelo básico de una red neuronal consiste en neuronas organizadas en capas. Cada red neuronal tiene una capa de entrada y salida y se le agregan varias capas ocultas dependiendo de la complejidad del problema. Al transmitir datos a través de capas, las neuronas se entrenan y reconocen los signos. Esta representación de una red neuronal se llama modelo. Después de entrenar el modelo, le pedimos a la red que haga pronósticos basados en datos de prueba.
El SNS es un tipo especial de red neuronal que funciona bien con imágenes. Ian Lekun los propuso en 1998, donde reconocieron el número presente en la imagen de entrada. SNA también se utiliza para reconocimiento de voz, segmentación de imágenes y procesamiento de texto. Antes de la creación de redes neuronales convolucionales, se utilizaron perceptrones multicapa en la construcción de clasificadores de imágenes. La clasificación de imágenes se refiere a la tarea de extraer clases de una imagen ráster multicanal (color, blanco y negro). Los perceptrones multicapa tardan mucho tiempo en buscar información en las imágenes, ya que cada entrada debe estar asociada con cada neurona en la siguiente capa. El SNA los rodeó usando un concepto llamado conectividad local. Esto significa que conectaremos cada neurona solo a la región de entrada local. Esto minimiza el número de parámetros, permitiendo que varias partes de la red se especialicen en atributos de alto nivel, como la textura o el patrón repetitivo. Confundido? Comparemos cómo se transmiten las imágenes a través de perceptrones multicapa (MP) y redes neuronales convolucionales.
Comparación de MP y SNA
El número total de entradas en la capa de entrada para el perceptrón multicapa será 784, ya que la imagen de entrada tiene un tamaño de 28x28 = 784 (se considera el conjunto de datos MNIST). La red debe poder predecir el número en la imagen de entrada, lo que significa que la salida puede pertenecer a cualquiera de las siguientes clases en el rango de 0 a 9. En la capa de salida, devolvemos estimaciones de clase, digamos si esta entrada es la imagen con el número "3", entonces, en la capa de salida, la neurona correspondiente "3" tiene un valor más alto en comparación con otras neuronas. Nuevamente surge la pregunta: "¿Cuántas capas ocultas necesitamos y cuántas neuronas deberían estar en cada una?" Por ejemplo, tome el siguiente código MP:
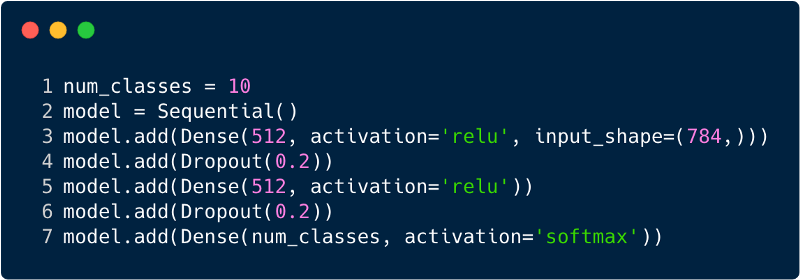
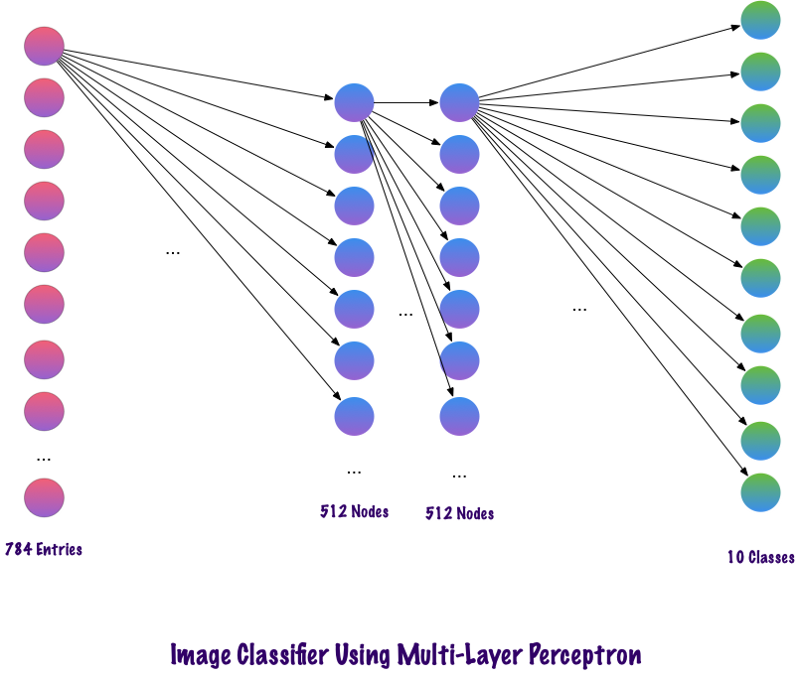
El código anterior se implementa utilizando un marco llamado Keras. La primera capa oculta tiene 512 neuronas que están conectadas a la capa de entrada de 784 neuronas. La siguiente capa oculta: la capa de exclusión, que resuelve el problema del reciclaje. 0.2 significa que hay un 20% de posibilidades de no tener en cuenta las neuronas de la capa oculta anterior. Nuevamente agregamos una segunda capa oculta con el mismo número de neuronas que en la primera capa oculta (512), y luego otra capa exclusiva. Finalmente, terminando este conjunto de capas con una capa de salida que consta de 10 clases. La clase que más importa será el número predicho por el modelo. Así es como se ve una red multicapa después de identificar todas las capas. Uno de los inconvenientes del perceptrón multinivel es que está completamente conectado, lo que requiere mucho tiempo y espacio.
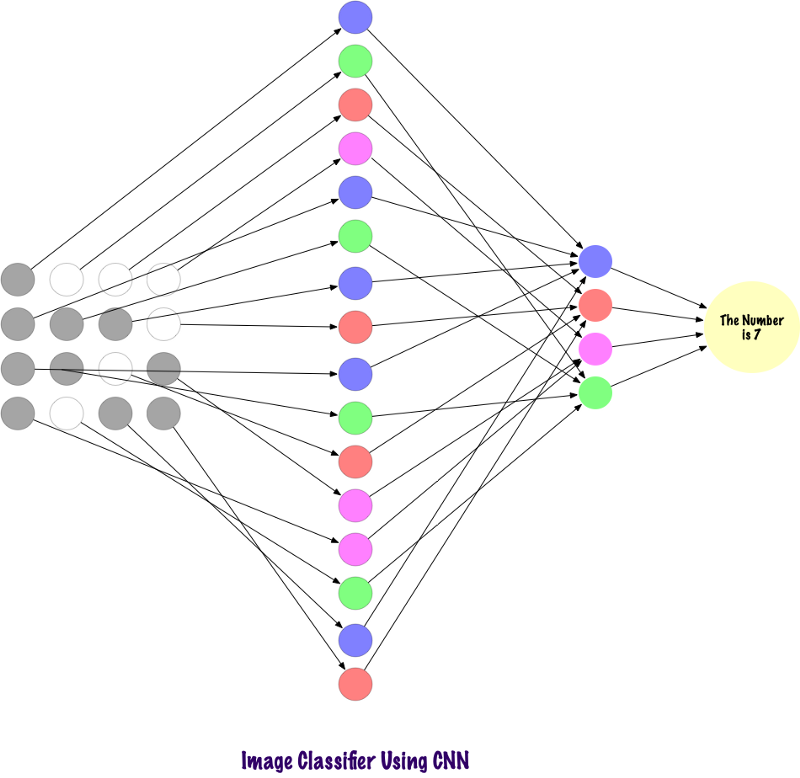
Los convolts no usan capas completamente unidas. Utilizan capas dispersas, que toman matrices como entrada, lo que les da una ventaja sobre MP. En MP, cada nodo es responsable de comprender la imagen completa. En el SCN, dividimos la imagen en áreas (pequeñas áreas locales de píxeles). La capa de salida combina los datos recibidos de cada nodo oculto para encontrar patrones. A continuación se muestra una imagen de cómo están conectadas las capas.
Ahora veamos cómo el SCN encuentra información en las fotografías. Antes de eso, debemos entender cómo se extraen los signos. En el SCN, utilizamos diferentes capas, cada capa conserva los signos de la imagen, por ejemplo, tiene en cuenta la imagen del perro, cuando la red necesita clasificar al perro, debe identificar todos los signos, como ojos, orejas, lengua, piernas, etc. Estas señales se rompen y se reconocen en los niveles de la red local mediante filtros y núcleos.
¿Cómo miran las computadoras una imagen?
Una persona que mira una imagen y comprende su significado suena muy razonable. Digamos que caminas y observas los muchos paisajes que te rodean. ¿Cómo entendemos la naturaleza en este caso? Tomamos imágenes del entorno utilizando nuestro órgano sensorial principal: el ojo, y luego lo enviamos a la retina. Todo parece bastante interesante, ¿verdad? Ahora imaginemos que una computadora hace lo mismo. En las computadoras, las imágenes se interpretan usando un conjunto de valores de píxeles que van de 0 a 255. La computadora observa estos valores de píxeles y los comprende. A primera vista, no conoce objetos y colores. Simplemente reconoce los valores de píxeles, y la imagen es equivalente a un conjunto de valores de píxeles para la computadora. Más tarde, al analizar los valores de píxeles, gradualmente aprende si la imagen es gris o de color. Las imágenes en escala de grises tienen solo un canal, ya que cada píxel representa la intensidad de un color. 0 significa negro y 255 significa blanco, las otras variantes de blanco y negro, es decir, gris, se encuentran entre ellas.
Las imágenes en color tienen tres canales, rojo, verde y azul. Representan la intensidad de 3 colores (matriz tridimensional), y cuando los valores cambian simultáneamente, esto da un gran conjunto de colores, ¡realmente una paleta de colores! Después de eso, la computadora reconoce las curvas y contornos de los objetos en la imagen. Todo esto puede estudiarse en la red neuronal convolucional. Para esto, utilizaremos PyTorch para cargar un conjunto de datos y aplicar filtros a las imágenes. El siguiente es un fragmento de código.
Ahora veamos cómo se alimenta una sola imagen en una red neuronal.
img = np.squeeze(images[7]) fig = plt.figure(figsize = (12,12)) ax = fig.add_subplot(111) ax.imshow(img, cmap='gray') width, height = img.shape thresh = img.max()/2.5 for x in range(width): for y in range(height): val = round(img[x][y],2) if img[x][y] !=0 else 0 ax.annotate(str(val), xy=(y,x), color='white' if img[x][y]<thresh else 'black')

Así es como el número "3" se divide en píxeles. Del conjunto de dígitos escritos a mano, se selecciona "3" al azar, en el que se muestran los valores de píxeles. Aquí ToTensor () normaliza los valores de píxeles reales (0–255) y los limita a un rango de 0 a 1. ¿Por qué es esto? Porque facilita los cálculos en las secciones posteriores, ya sea para interpretar imágenes o para encontrar patrones comunes que existen en ellas.
Crea tu propio filtro
Los filtros, como su nombre lo indica, filtran la información. En el caso de las redes neuronales convolucionales, cuando se trabaja con imágenes, se filtra la información sobre los píxeles. ¿Por qué deberíamos filtrar? Recuerde que una computadora debe pasar por un proceso de aprendizaje para comprender las imágenes, muy similar a cómo lo hace un niño. ¡En este caso, sin embargo, no necesitaremos muchos años! En resumen, aprende desde cero y luego avanza hacia el todo.
Por lo tanto, la red debe conocer inicialmente todas las partes gruesas de la imagen, es decir, los bordes, contornos y otros elementos de bajo nivel. Una vez que se descubren, se allana el camino para los síntomas complejos. Para llegar a ellos, primero debemos extraer los atributos de bajo nivel, luego el medio y luego los de nivel superior. Los filtros son una forma de extraer la información que el usuario necesita, y no solo la transferencia de datos a ciegas, por lo que la computadora no comprende la estructuración de las imágenes. Al principio, las funciones de bajo nivel se pueden extraer en función de un filtro específico. El filtro aquí también es un conjunto de valores de píxeles, similar a una imagen. Se puede entender como los pesos que conectan las capas en la red neuronal convolucional. Estos pesos o filtros se multiplican por los valores de entrada para producir imágenes intermedias que representan la comprensión de la imagen por parte de la computadora. Luego se multiplican por algunos filtros más para expandir la vista. Luego detecta los órganos visibles de una persona (siempre que haya una persona presente en la imagen). Más tarde, con la inclusión de varios filtros más y varias capas, la computadora exclama: “¡Oh, sí! Este es un hombre ".
Si hablamos de filtros, entonces tenemos muchas opciones. Es posible que desee desenfocar la imagen, luego aplicar un filtro de desenfoque, si necesita agregar nitidez, entonces un filtro de nitidez vendrá al rescate, etc.
Veamos algunos fragmentos de código para comprender la funcionalidad de los filtros.

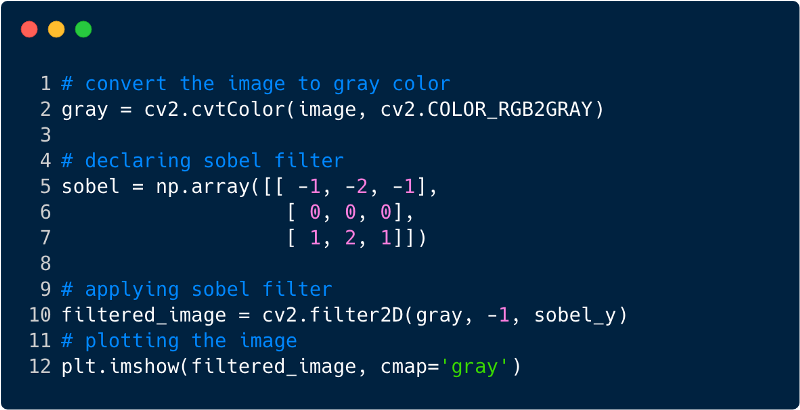

Así es como se ve la imagen después de aplicar el filtro, en este caso utilizamos el filtro Sobel.
Redes neuronales convolucionales
Hasta ahora, hemos visto cómo se utilizan los filtros para extraer características de las imágenes. Ahora, para completar toda la red neuronal convolucional, necesitamos conocer todas las capas que usamos para diseñarla. Las capas utilizadas en el SCN,
- Capa convolucional
- Capa de agrupación
- Capa completamente unida
Con las tres capas, el clasificador de imagen convolucional se ve así:
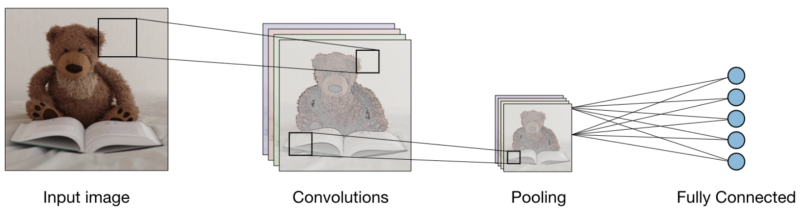
Ahora veamos qué hace cada capa.
La capa convolucional (CONV) usa filtros que realizan operaciones de convolución escaneando la imagen de entrada. Sus hiperparámetros incluyen un tamaño de filtro, que puede ser 2x2, 3x3, 4x4, 5x5 (pero no limitado a esto) y el paso S. El resultado O se denomina mapa de características o mapa de activación en el que todas las características se calculan utilizando capas y filtros de entrada. A continuación se muestra una imagen de la generación de mapas de características al aplicar convolución,
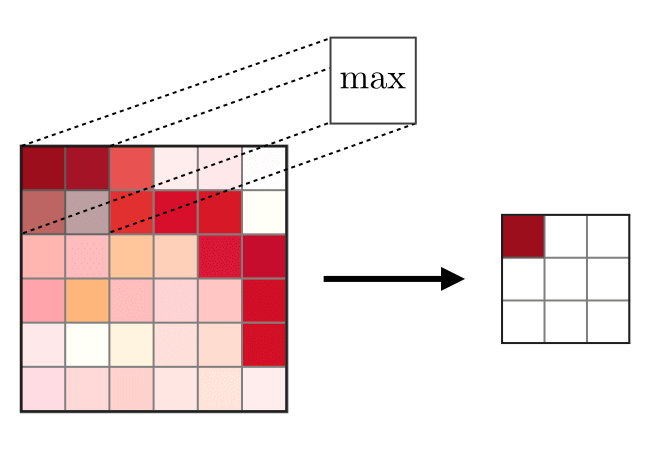
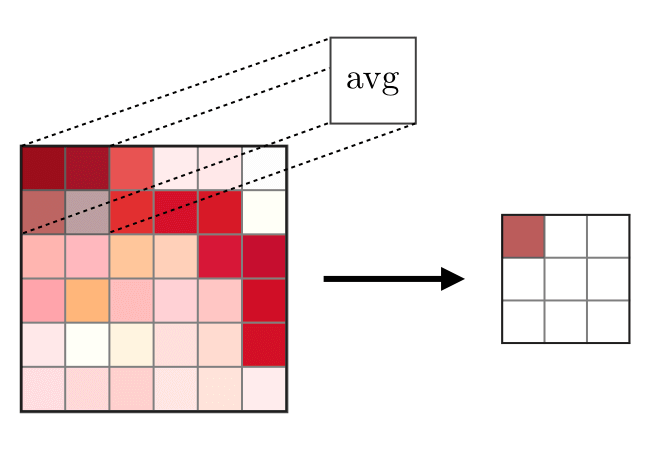
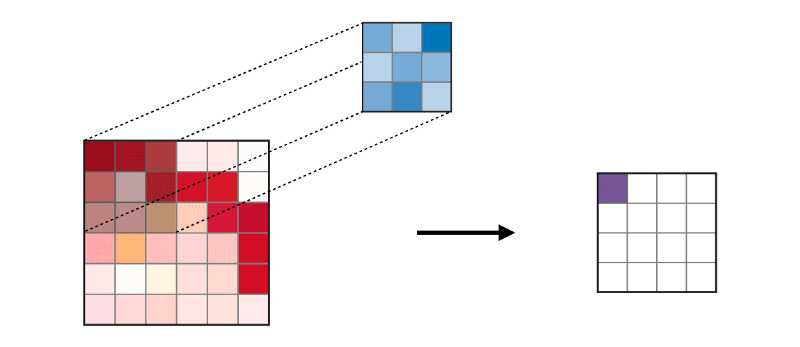 La capa de fusión (POOL) se
La capa de fusión (POOL) se usa para compactar las características que generalmente se usan después de la capa de convolución. Hay dos tipos de operaciones de unión: esta es la unión máxima y media, donde se toman los valores máximo y promedio de las características, respectivamente. La siguiente es la operación de operaciones de fusión,
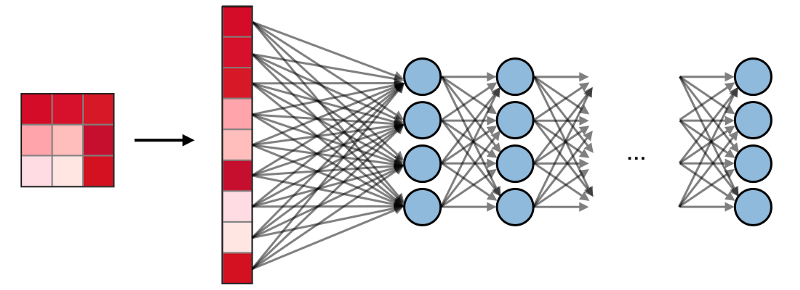
 Las capas completamente conectadas (FC)
Las capas completamente conectadas (FC) funcionan con una entrada plana, donde cada entrada está conectada a todas las neuronas. Por lo general, se usan al final de la red para conectar capas ocultas a la capa de salida, lo que ayuda a optimizar los puntajes de la clase.
Visualización de SNA en PyTorch
Ahora que tenemos la ideología completa de construir el SNA, implementemos el SNA usando el marco PyTorch de Facebook.
Paso 1 : descargue la imagen de entrada que se enviará a través de la red. (Aquí lo hacemos con Numpy y OpenCV)
import cv2 import matplotlib.pyplot as plt %matplotlib inline img_path = 'dog.jpg' bgr_img = cv2.imread(img_path) gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
 Paso 2
Paso 2 : Procesar filtros
Visualicemos los filtros para comprender mejor cuáles utilizaremos,
import numpy as np filter_vals = np.array([ [-1, -1, 1, 1], [-1, -1, 1, 1], [-1, -1, 1, 1], [-1, -1, 1, 1] ]) print('Filter shape: ', filter_vals.shape)
 Paso 3
Paso 3 : determinar el SCN
Este SNA tiene una capa convolucional y una capa de agrupación con una función máxima, y los pesos se inicializan utilizando los filtros que se muestran arriba,
import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self, weight): super(Net, self).__init__()
Net( (conv): Conv2d(1, 4, kernel_size=(4, 4), stride=(1, 1), bias=False) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) )
Paso 4 : Procesar filtros
Un vistazo rápido a los filtros utilizados,
def viz_layer(layer, n_filters= 4): fig = plt.figure(figsize=(20, 20)) for i in range(n_filters): ax = fig.add_subplot(1, n_filters, i+1) ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray') ax.set_title('Output %s' % str(i+1)) fig = plt.figure(figsize=(12, 6)) fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05) for i in range(4): ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[]) ax.imshow(filters[i], cmap='gray') ax.set_title('Filter %s' % str(i+1)) gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1)
Filtros:
 Paso 5
Paso 5 : Resultados filtrados por capa
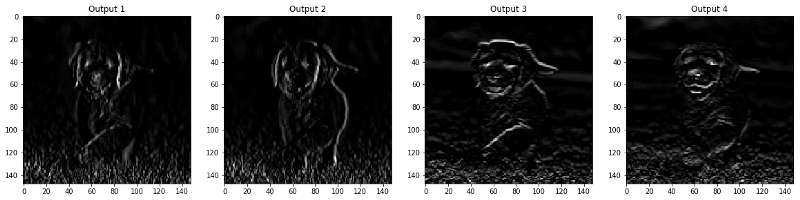
Las imágenes que aparecen en la capa CONV y POOL se muestran a continuación.
viz_layer(activated_layer) viz_layer(pooled_layer)
Capas convolucionales

Capas de agrupación
 Fuente
Fuente