Versión rusa
Imaginemos que está desarrollando un dispositivo de software y hardware. El dispositivo consiste en un sistema operativo personalizado, servidores exclusivos, mucha lógica empresarial, como resultado, tiene que usar hardware real. Si libera un dispositivo roto, sus usuarios no estarán contentos. ¿Cómo hacer versiones estables?
Me gustaría compartir mi historia de cómo lo tratamos.
Prueba de concepto
Si no conoce un objetivo, será realmente difícil superar la tarea. La primera variante de despliegue se parecía a bash :
make dist for i in abc ; do scp ./result.tar.gz $i:~/ ssh $i "tar -zxvf result.tar.gz" ssh $i "make -C ~/resutl install" done
El script se simplificó solo para mostrar la idea principal: no había CI / CD. Nuestro flujo fue:
- Construido en host de desarrollador.
- Implementado para probar el entorno para una demostración.
En la etapa actual, al saber cómo se aprovisionó, todos los errores conocidos eran magia sucia dentro de las mentes de los desarrolladores. Fue un problema real para nosotros debido al crecimiento del equipo.
Solo hazlo
Habíamos usado TeamCity para nuestros proyectos y gitlab no había sido popular, por lo que decidimos usar TeamCity. Creamos manualmente una VM. Estábamos ejecutando pruebas dentro de la VM.
Hubo algunos pasos en el flujo de compilación:
- Instale algunas utilidades dentro del entorno preparado manualmente.
- Comprueba que funciona.
- Si está bien, publique RPM.
- Actualice la puesta en escena a la nueva versión.
make install && ./libs/run_all_tests.sh make dist make srpm rpmbuild -ba SPECS/xxx-base.spec make publish
Recibimos un resultado temporal:
- Algo ejecutable estaba en la rama maestra.
- Funcionó en alguna parte.
- Podríamos detectar algunos problemas casuales.
¿Sientes el olor?
- Hubo un infierno de dependencia con los RPM.
- Todos tenían su propio entorno de desarrollo de mascotas.
- Las pruebas se estaban ejecutando dentro del entorno desconocido.
- Había tres entidades completamente ilimitadas: compilación del sistema operativo, provisión de instalaciones y pruebas.
Reduce la magia sucia
Cambiamos los flujos y el proceso:
- Creamos el metapaquete RPM y eliminamos el infierno de dependencias.
- Creamos una plantilla de VM de desarrollo a través de vagabundo.
- Movimos los guiones de bash a ansible.
- Por un lado, creamos un marco de pruebas de integración, pero por otro lado, usamos serverpec .
Como resultado de la etapa actual que recibimos:
- Todo nuestro entorno de desarrollo era idéntico.
- El código de la aplicación y la lógica de provisión se sincronizaron con cada una.
- Aceleramos el proceso de incorporación de nuevos desarrolladores.
Por un lado, una construcción fue realmente lenta (aproximadamente 30-60 minutos), pero por otro lado fue lo suficientemente buena y atrapó con éxito la gran mayoría de los problemas antes del control de calidad manual. Sin embargo, enfrentamos nuevos problemas diferentes, es decir, luego actualizamos el kernel o luego revertimos un paquete.
Mejorarlo
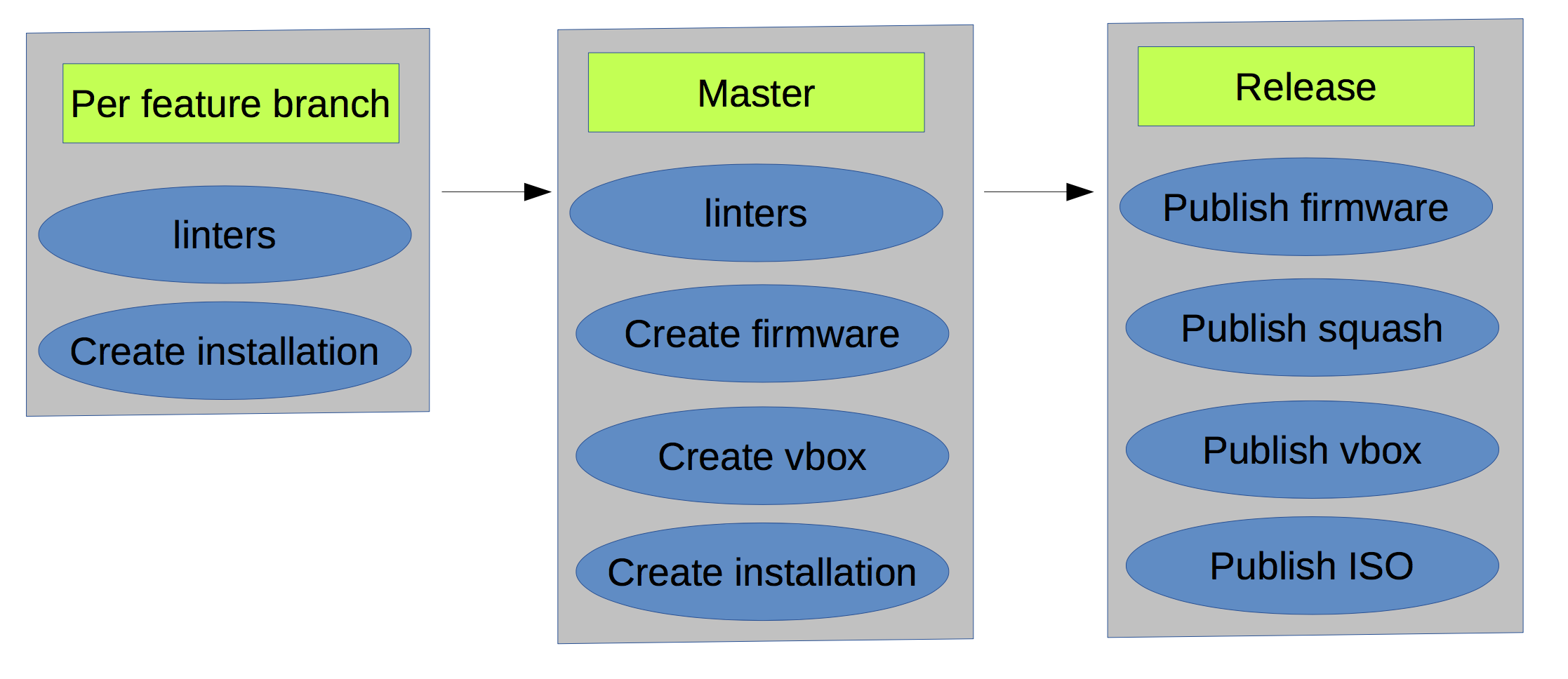
Resolvimos muchos problemas diferentes:
- Las pruebas de integración funcionaron cada vez más lento porque la plantilla de máquina virtual de desarrollo era anterior a los RPM reales. Estábamos reconstruyendo la plantilla manualmente, luego decidimos automatizarla:
- Crea un VMDK automáticamente.
- Adjunte el VMDK a una VM.
- Empaque la VM y cárguela en s3.
- En caso de una fusión, no fue posible obtener el estado de compilación, como resultado, pasamos a gitlab.
- Solíamos hacer un lanzamiento manual todas las semanas, lo automatizamos.
- Versión de incremento automático.
- Genere notas de lanzamiento basadas en problemas cerrados.
- Actualización de registro de cambios.
- Crear solicitudes de fusión.
- Crea un nuevo hito.
- Pasamos algunos pasos a Docker (pelusa, ejecutamos algunas pruebas, enviamos mensajes, compilamos documentos, etc.).
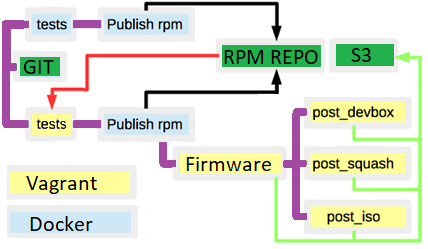
Como resultado en el esquema de la etapa actual se veía así:

- Había muchos repositorios RPM / DEB para paquetes.
- Había s3 como almacén de artefactos.
- Si ejecutaste una compilación dos veces para la misma rama, recibirías un resultado diferente, porque las dependencias del metapaquete no estaban codificadas.
- Había límites no visibles (líneas de color rojo) a través de las construcciones.
Sin embargo, pudimos producir versiones cada semana y mejorar la velocidad de desarrollo.
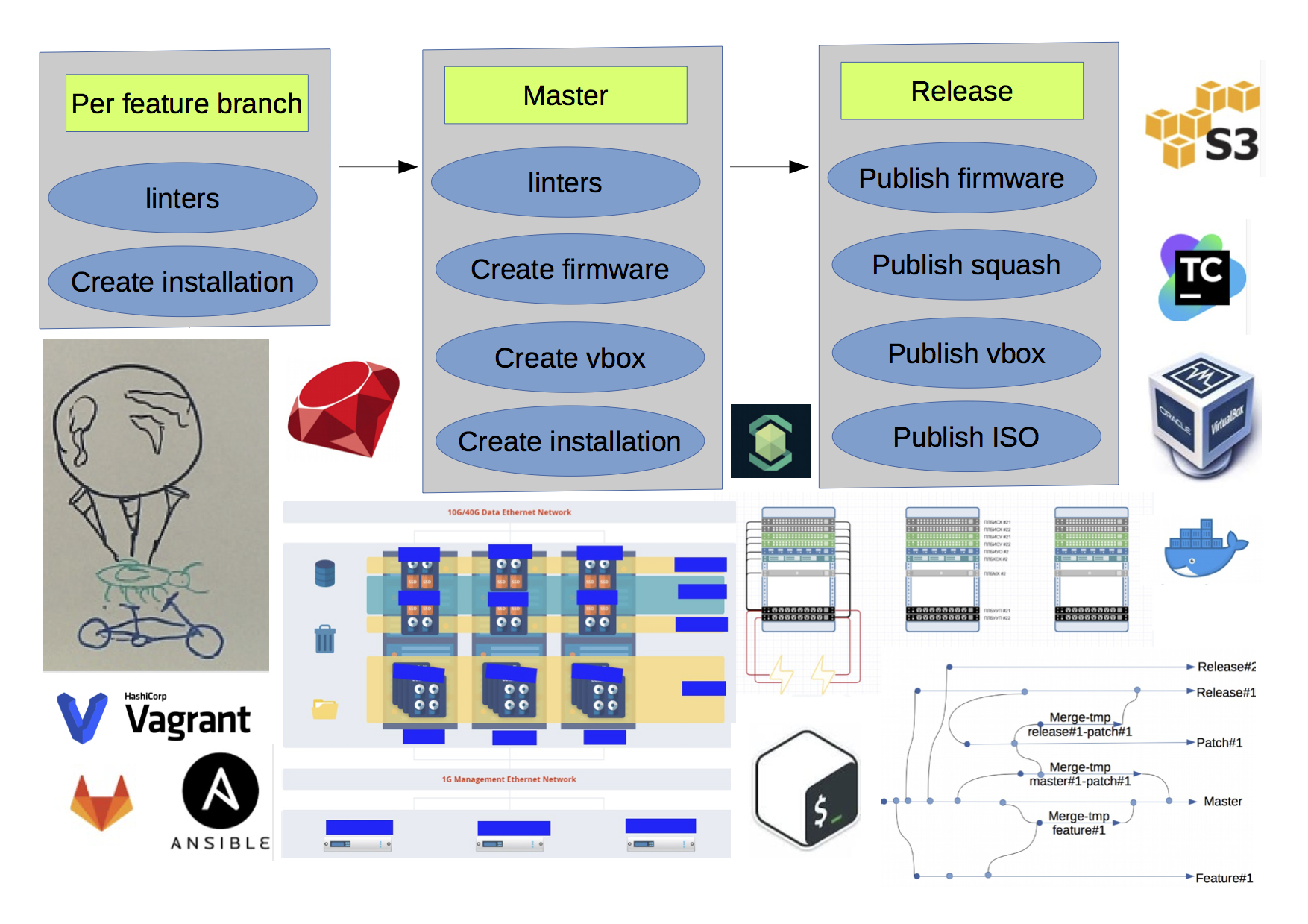
Conclusión
El resultado no fue ideal, pero un viaje de mil li comienza con un solo paso ©.
PD es crosspost