Se me pidió que escribiera este artículo con una gran cantidad de materiales sobre análisis estático, que cada vez me llaman más la atención. En primer lugar, este es el
blog PVS-studio , que se está promocionando activamente en Habré con la ayuda de revisiones de errores encontradas por su herramienta en proyectos de código abierto. Recientemente, PVS-studio implementó el
soporte para Java , y, por supuesto, los desarrolladores de IntelliJ IDEA, cuyo analizador incorporado es probablemente el más avanzado para Java en la actualidad,
no pudieron mantenerse alejados .
Al leer tales comentarios, existe la sensación de que estamos hablando de un elixir mágico: haga clic en el botón, y aquí está: una lista de defectos ante sus ojos. Parece que a medida que los analizadores mejoren, se encontrarán más y más errores automáticamente, y los productos escaneados por estos robots mejorarán cada vez más, sin ningún esfuerzo de nuestra parte.
Pero no hay elixires mágicos. Me gustaría hablar sobre algo que generalmente no se menciona en publicaciones como "estas son las cosas que nuestro robot puede encontrar": lo que los analizadores no pueden hacer, cuál es su papel real y su lugar en el proceso de entrega de software, y cómo implementarlos correctamente.
 Ratchet (fuente: Wikipedia ).
Ratchet (fuente: Wikipedia ).Lo que los analizadores estáticos nunca pueden
¿Qué es, desde un punto de vista práctico, el análisis del código fuente? Enviamos algunas fuentes a la entrada, y en la salida en poco tiempo (mucho más corto que la ejecución de la prueba) obtenemos información sobre nuestro sistema. La limitación fundamental y matemáticamente insuperable es que solo podemos obtener una clase de información bastante estrecha de esta manera.
El ejemplo más famoso de un problema que no se puede resolver con la ayuda del análisis estático es
el problema de apagado : este es un teorema que demuestra que es imposible desarrollar un algoritmo general que determinaría mediante el código fuente de un programa si se repetirá o finalizará en un tiempo finito. Una extensión de este teorema es
el teorema de Rice, que establece que para cualquier propiedad no trivial de funciones computables, determinar si un programa arbitrario calcula una función con esta propiedad es un problema algorítmicamente insoluble. Por ejemplo, es imposible escribir un analizador que determine mediante cualquier código fuente si el programa que se analiza es una implementación de un algoritmo que calcula, por ejemplo, la cuadratura de un número entero.
Por lo tanto, la funcionalidad de los analizadores estáticos tiene limitaciones insuperables. En todos los casos, el analizador estático nunca podrá detectar cosas como, por ejemplo, la aparición de una "excepción de puntero nulo" en lenguajes anulables, o en todos los casos determinará la aparición de un "atributo no encontrado" en lenguajes escritos dinámicamente. Todo lo que puede hacer el analizador estático más avanzado es resaltar casos particulares, cuyo número entre todos los posibles problemas con su código fuente es, sin exagerar, una caída en el cubo.
El análisis estático no es una búsqueda de errores
La conclusión se deduce de lo anterior: el análisis estático no es un medio para reducir el número de defectos en un programa. Me aventuraré a afirmar: cuando se aplica por primera vez a su proyecto, encontrará lugares "ocupados" en el código, pero lo más probable es que no encuentre ningún defecto que afecte la calidad de su programa.
Los ejemplos de defectos encontrados automáticamente por los analizadores son impresionantes, pero no debemos olvidar que estos ejemplos se encontraron escaneando un gran conjunto de bases de código grandes. Por el mismo principio, los crackers con la capacidad de enumerar algunas contraseñas simples en una gran cantidad de cuentas finalmente encuentran aquellas cuentas que tienen una contraseña simple.
¿Esto significa que no es necesario aplicar el análisis estático? Por supuesto que no! Y exactamente por la misma razón por la que vale la pena verificar cada contraseña nueva para llegar a la lista de paradas de contraseñas "simples".
El análisis estático es más que buscar errores
De hecho, las tareas prácticamente resueltas por el análisis son mucho más amplias. De hecho, en general, el análisis estático es cualquier verificación de las fuentes realizada antes de su lanzamiento. Aquí hay algunas cosas que puede hacer:
- Verificación del estilo de codificación en el sentido amplio de la palabra. Esto incluye verificar el formato y buscar el uso de corchetes vacíos / adicionales, establecer valores de umbral para métricas como el número de líneas / complejidad ciclomática del método, etc., todo lo que potencialmente hace que el código sea difícil de leer y mantener. En Java, dicha herramienta es Checkstyle, en Python - flake8. Los programas de esta clase generalmente se llaman linters.
- No solo se puede analizar el código ejecutable. Los archivos de recursos como JSON, YAML, XML, .properties pueden (y deberían!) Verificar automáticamente su validez. Después de todo, es mejor descubrir que debido a algunas citas no emparejadas, la estructura JSON se viola en la etapa inicial de la verificación automática de solicitud de extracción que cuando se ejecutan pruebas o en tiempo de ejecución. Las herramientas relevantes están disponibles: por ejemplo, YAMLlint , JSONLint .
- La compilación (o análisis de lenguajes de programación dinámica) también es una forma de análisis estático. Como regla general, los compiladores pueden emitir advertencias que señalan problemas con la calidad del código fuente, y no deben ignorarse.
- A veces, la compilación no es solo compilación de código ejecutable. Por ejemplo, si tiene documentación en el formato AsciiDoctor , al momento de convertirla en HTML / PDF, el controlador AsciiDoctor ( complemento Maven ) puede dar advertencias, por ejemplo, sobre enlaces internos rotos. Y esta es una buena razón para no aceptar la solicitud de extracción con cambios en la documentación.
- La corrección ortográfica también es una forma de análisis estático. La utilidad aspell puede verificar la ortografía no solo en la documentación, sino también en los códigos fuente de los programas (comentarios y literales) en varios lenguajes de programación, incluidos C / C ++, Java y Python. ¡Un error ortográfico en la interfaz de usuario o la documentación también es un defecto!
- Las pruebas de configuración (para lo que es, vea este y este informe), aunque se ejecutan en un entorno de tiempo de ejecución para pruebas unitarias como pytest, de hecho también son una especie de análisis estático, porque no ejecutan códigos fuente durante su ejecución .
Como puede ver, la búsqueda de errores en esta lista tiene el papel menos importante, y todo lo demás está disponible mediante el uso de herramientas gratuitas de código abierto.
¿Cuál de estos tipos de análisis estático debe usarse en su proyecto? Por supuesto, todo, cuanto más, ¡mejor! Lo principal es implementarlo correctamente, lo que se discutirá más a fondo.
Tubería de entrega como filtro de etapas múltiples y análisis estático como su primera cascada
La metáfora clásica para la integración continua es la canalización a través de la cual fluyen los cambios, desde cambiar el código fuente hasta ser entregados a producción. La secuencia estándar de pasos en esta tubería es la siguiente:
- análisis estático
- compilación
- pruebas unitarias
- pruebas de integración
- Pruebas de IU
- control manual
Los cambios rechazados en la enésima etapa del transportador no se transfieren a la etapa N + 1.
¿Por qué es así y no de otra manera? En la parte de prueba de la tubería, los evaluadores reconocen la conocida pirámide de prueba.
 Prueba de pirámide. Fuente: artículo de Martin Fowler.
Prueba de pirámide. Fuente: artículo de Martin Fowler.En la parte inferior de esta pirámide hay pruebas que son más fáciles de escribir, que son más rápidas de ejecutar y no tienen tendencia a falsos positivos. Por lo tanto, debería haber más, deberían cubrir más código y ejecutarse primero. En la parte superior de la pirámide, todo es al revés, por lo que el número de pruebas de integración y UI debe reducirse al mínimo requerido. La persona en esta cadena es el recurso más costoso, lento y poco confiable, por lo que está al final y hace el trabajo solo si los pasos anteriores no revelaron ningún defecto. Sin embargo, de acuerdo con los mismos principios, ¡un transportador está construido en partes que no están directamente relacionadas con las pruebas!
Me gustaría ofrecer una analogía en forma de un sistema de filtración de agua de múltiples etapas. Se suministra agua sucia (cambios con defectos) a la entrada, a la salida debemos obtener agua limpia, en la que se elimina toda contaminación indeseable.
 Filtro multietapa. Fuente: Wikimedia Commons
Filtro multietapa. Fuente: Wikimedia CommonsComo sabe, los filtros de limpieza están diseñados para que cada cascada posterior pueda filtrar una fracción cada vez más pequeña de contaminantes. Al mismo tiempo, las cascadas más gruesas tienen un mayor rendimiento y un menor costo. En nuestra analogía, esto significa que las compuertas de calidad de entrada tienen mayor velocidad, requieren menos esfuerzo para comenzar y son ellas mismas sin pretensiones en su trabajo, y es en esta secuencia que se construyen. El papel del análisis estático, que, como ahora entendemos, es capaz de eliminar solo los defectos más graves, es el papel de la rejilla de "trampa de suciedad" al comienzo de la cascada de filtros.
El análisis estático por sí solo no mejora la calidad del producto final, así como un recolector de lodo no produce agua potable. Sin embargo, en general, junto con otros elementos del transportador, su importancia es obvia. Aunque en el filtro multietapa las etapas de salida son potencialmente capaces de atrapar todo igual que las de entrada, está claro qué consecuencias tendrá el intento de hacer con etapas finas sin etapas de entrada.
El objetivo del "recolector de suciedad" es evitar que las cascadas posteriores capturen defectos muy graves. Por ejemplo, al menos, la persona que realiza la revisión del código no debe distraerse con código formateado incorrectamente y la violación de los estándares de codificación establecidos (como paréntesis o ramas adicionales que están demasiado anidados). Los errores como NPE deben detectarse mediante pruebas unitarias, pero si incluso antes de la prueba el analizador nos dice que el error inevitablemente sucederá, esto acelerará significativamente su corrección.
Creo que ahora está claro por qué el análisis estático no mejora la calidad del producto, si se aplica esporádicamente, y debe usarse continuamente para detectar cambios con defectos graves. La pregunta es si el uso de un analizador estático mejorará la calidad de su producto, es más o menos equivalente a la pregunta "¿mejorarán las cualidades de bebida del agua tomada de un depósito sucio si se pasa a través de un colador?"
Implementación en un proyecto heredado
Una pregunta práctica importante: ¿cómo integrar el análisis estático en el proceso de integración continua como una "puerta de calidad"? En el caso de las pruebas automáticas, todo es obvio: hay un conjunto de pruebas, la caída de cualquiera de ellas es razón suficiente para creer que el conjunto no pasó la puerta de calidad. Un intento de establecer la puerta de la misma manera en función de los resultados del análisis estático falla: hay demasiadas advertencias de análisis en el código heredado, no desea ignorarlas por completo, pero es imposible detener la entrega del producto solo porque contiene advertencias del analizador.
Cuando se aplica por primera vez, el analizador genera una gran cantidad de advertencias en cualquier proyecto, la gran mayoría de los cuales no están relacionados con el correcto funcionamiento del producto. Es imposible corregir todos estos comentarios a la vez, y muchos no son necesarios. Al final, sabemos que nuestro producto en su conjunto funciona, ¡y antes de la introducción del análisis estático!
Como resultado, muchos se limitan al uso episódico del análisis estático, o lo usan solo en el modo informativo, cuando el informe del analizador simplemente se emite durante el ensamblaje. Esto es equivalente a la ausencia de cualquier análisis, porque si ya tenemos muchas advertencias, la aparición de otra (arbitrariamente grave) al cambiar el código pasa desapercibida.
Se conocen los siguientes métodos para administrar puertas de calidad:
- Establecer un límite en el número total de advertencias o el número de advertencias dividido por el número de líneas de código. Esto funciona mal, ya que tal puerta omite libremente los cambios con nuevos defectos hasta que se excede su límite.
- Arreglando, en cierto momento, todas las advertencias antiguas en el código como ignoradas, y negándose a construir cuando ocurren nuevas advertencias. Esta funcionalidad es proporcionada por PVS-studio y algunos recursos en línea, por ejemplo, Codacy. No pasé a trabajar en PVS-studio, ya que por mi experiencia con Codacy, su principal problema es que determinar qué es "viejo" y qué es "nuevo" es un algoritmo bastante complicado y no siempre funciona, especialmente si los archivos están muy modificados o renombrados. En mi memoria, Codacy podría omitir nuevas advertencias en la solicitud de extracción y, al mismo tiempo, no omitir la solicitud de extracción debido a advertencias no relacionadas con cambios en el código de este RP.
- En mi opinión, la solución más efectiva se describe en el libro Entrega continua "trinquete" ("trinquete"). La idea principal es que la propiedad de cada versión es la cantidad de advertencias del análisis estático, y solo se permiten aquellos cambios que no aumenten la cantidad total de advertencias.
Trinquete
Funciona de esta manera:
- En la etapa inicial, el número de advertencias en el código encontrado por los analizadores se registra en los metadatos sobre el lanzamiento. Por lo tanto, al compilar la rama principal, no solo se escribe "versión 7.0.2", sino también "versión 7.0.2, que contiene 100500 advertencias de Checkstyle" en su administrador de repositorios. Si utiliza un administrador de repositorio avanzado (como Artifactory), guardar esos metadatos sobre su lanzamiento es fácil.
- Ahora, cada solicitud de extracción durante el ensamblaje compara el número de advertencias recibidas con el número de la versión actual. Si PR lleva a un aumento en este número, entonces el código no pasa la puerta de calidad para el análisis estático. Si el número de advertencias disminuye o no cambia, entonces pasa.
- En la próxima versión, el número contado de advertencias se reescribirá en los metadatos de la versión.
Poco a poco, pero de manera constante (como con el trinquete), el número de advertencias tenderá a cero. Por supuesto, el sistema puede ser engañado introduciendo una nueva advertencia, pero corrigiendo la de otra persona. Esto es normal, porque a larga distancia da el resultado: las advertencias generalmente se corrigen, no individualmente, sino inmediatamente por un grupo de cierto tipo, y todas las advertencias eliminadas fácilmente se eliminan rápidamente.
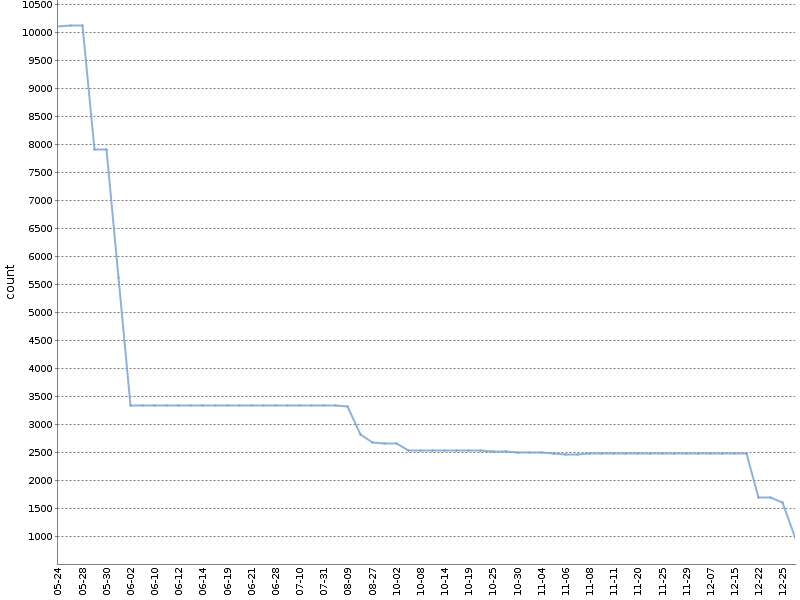
Este gráfico muestra el número total de advertencias de Checkstyle durante medio año de trabajo de este tipo en
uno de nuestros proyectos OpenSource . ¡El número de advertencias ha disminuido en un orden de magnitud, y esto sucedió naturalmente, en paralelo con el desarrollo del producto!
Utilizo una versión modificada de este método, contando por separado las advertencias desglosadas por módulos de proyecto y herramientas de análisis, el archivo YAML generado con metadatos de ensamblaje se ve así:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
En cualquier sistema CI avanzado, se puede implementar “trinquete” para cualquier herramienta de análisis estático, sin depender de complementos y herramientas de terceros. Cada uno de los analizadores produce su informe en un texto simple o formato XML, que es fácil de analizar. Queda por registrar solo la lógica necesaria en el script de CI. Puede ver cómo se implementa esto en nuestros proyectos de código abierto basados en Jenkins y Artifactory
aquí o
aquí . Ambos ejemplos dependen de la biblioteca
ratchetlib : el método
countWarnings() cuenta las etiquetas xml en los archivos generados por Checkstyle y Spotbugs, y
compareWarningMaps() implementa el mismo trinquete, arrojando un error cuando aumenta el número de advertencias en cualquiera de las categorías.
Una implementación interesante del trinquete es posible para analizar la ortografía de comentarios, textos literales y documentación usando aspell. Como sabe, al revisar la ortografía, no todas las palabras desconocidas para el diccionario estándar son incorrectas; se pueden agregar al diccionario del usuario. Si hace que un diccionario personalizado forme parte del código fuente de un proyecto, la compuerta de calidad ortográfica se puede formular de la siguiente manera: ejecutar aspell con un diccionario estándar y personalizado
no debería encontrar ningún error ortográfico.
Sobre la importancia de arreglar la versión del analizador
En conclusión, debe tenerse en cuenta lo siguiente: no importa cómo integre el análisis en su canal de entrega, la versión del analizador debe ser fija. Si permite que el analizador se actualice espontáneamente, al ensamblar la siguiente solicitud de extracción, pueden aparecer nuevos defectos que no están relacionados con el cambio del código, pero están conectados con el hecho de que el nuevo analizador simplemente puede encontrar más defectos, y esto interrumpirá el proceso de recibir solicitudes de extracción . La actualización del analizador debe ser una acción consciente. Sin embargo, la fijación estricta de la versión de cada componente del ensamblaje es generalmente un requisito necesario y un tema para una conversación separada.
Conclusiones
- El análisis estático no encontrará errores y no mejorará la calidad de su producto como resultado de una sola aplicación. El uso constante en el proceso de entrega proporciona un efecto positivo en la calidad.
- La búsqueda de errores no es la tarea principal de análisis, la gran mayoría de las funciones útiles están disponibles en las herramientas de código abierto.
- Implemente puertas de calidad basadas en los resultados del análisis estático en la primera etapa de la tubería de entrega, utilizando trinquete para el código heredado.
Referencias
- Entrega continua
- A. Kudryavtsev: Análisis de programas: cómo entender que eres un buen programador para informar sobre diferentes métodos de análisis de código (¡no solo estático!)