Entonces, el 4 de enero, a las 7:15, después de haberme limpiado los ojos del sueño, encuentro un paquete de un mensaje en el grupo Telegram del servidor Zabbix de que la carga de la CPU en uno de los servidores de virtualización aumentó:
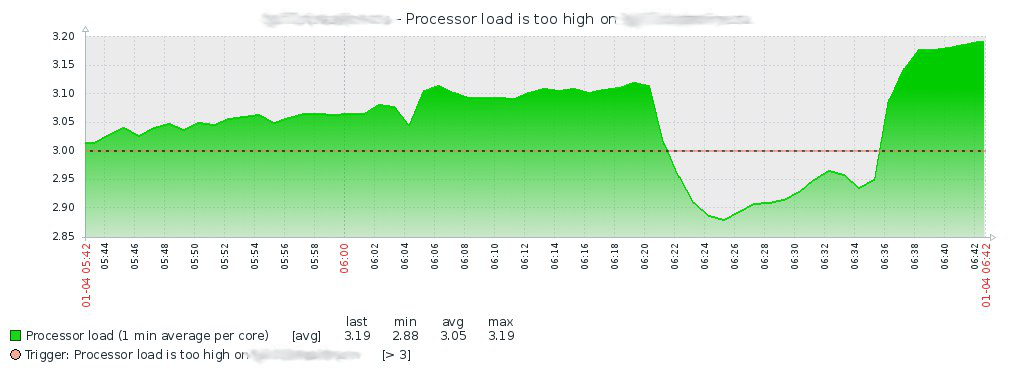
Después de mirar la historia en Zabbix, me subo al servidor y miro en dmesg, donde encuentro lo siguiente:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
Estoy subiendo al almacenamiento donde está mirando el adaptador QLogic FC, veo que el 1 de enero a las 19:54 una de las unidades en el almacenamiento fue puesta fuera de servicio, la unidad de repuesto fue recogida y la recuperación finalizó el 2 de enero a las 9:11:

Pensé: tal vez algo vino del repositorio o del interruptor FC, lo que causó que el controlador se enfureciera con el adaptador QLogic.
Creó una tarea en el rastreador, reinició el servidor, todo funcionó de nuevo como debería, a primera vista.
Sobre esto, pospuso otras acciones hasta el final de las vacaciones de Año Nuevo.
Con el comienzo de la semana laboral el 9 de enero, comenzó a resolver la causa del fracaso.
Desde el mensaje:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
no demasiado informativo, subió a la fuente del controlador.
A juzgar por el código del controlador, se emite un mensaje cuando el controlador se descarga debido a un error en el PCI (linux / drivers / scsi / qla2xxx / qla_os.c (kernel v4.15)):
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n");
Empecé a cavar más, me metí en BMC, miro en el registro de eventos:
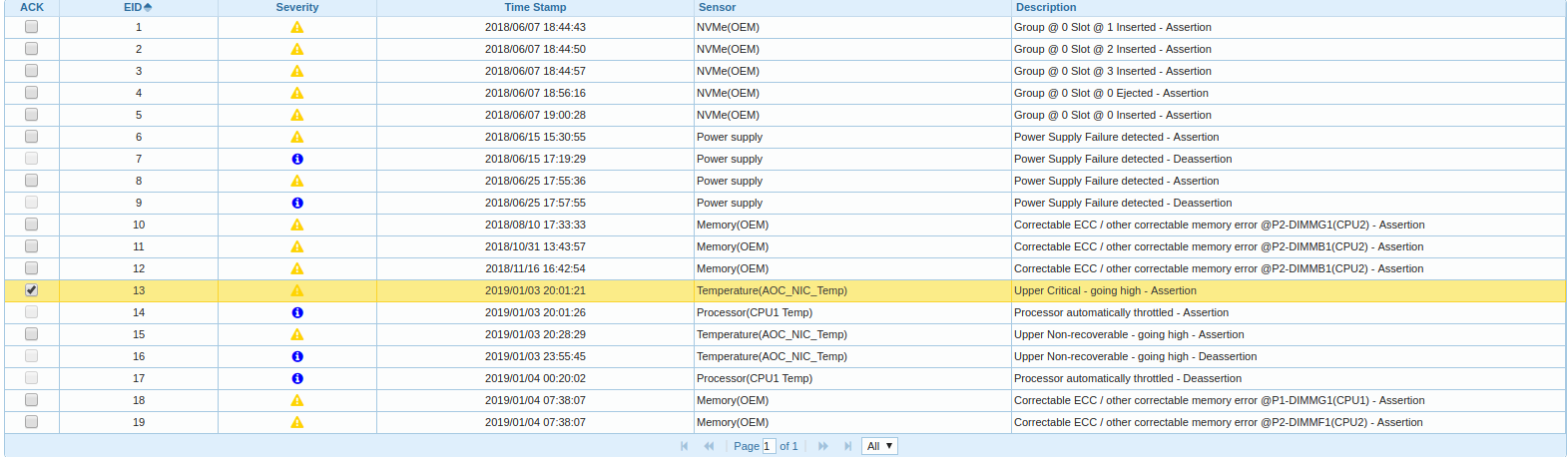
Resulta que uno de los dos nodos de CPU en la plataforma se está calentando y acelerando, y el tiempo del mensaje sobre la descarga del controlador del adaptador FC se correlaciona con el tiempo de inicio de la aceleración.
Aquí vale la pena hacer un comentario de que la plataforma del servidor que tenemos aquí es https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm con dos EPYC 7601 para cada nodo:
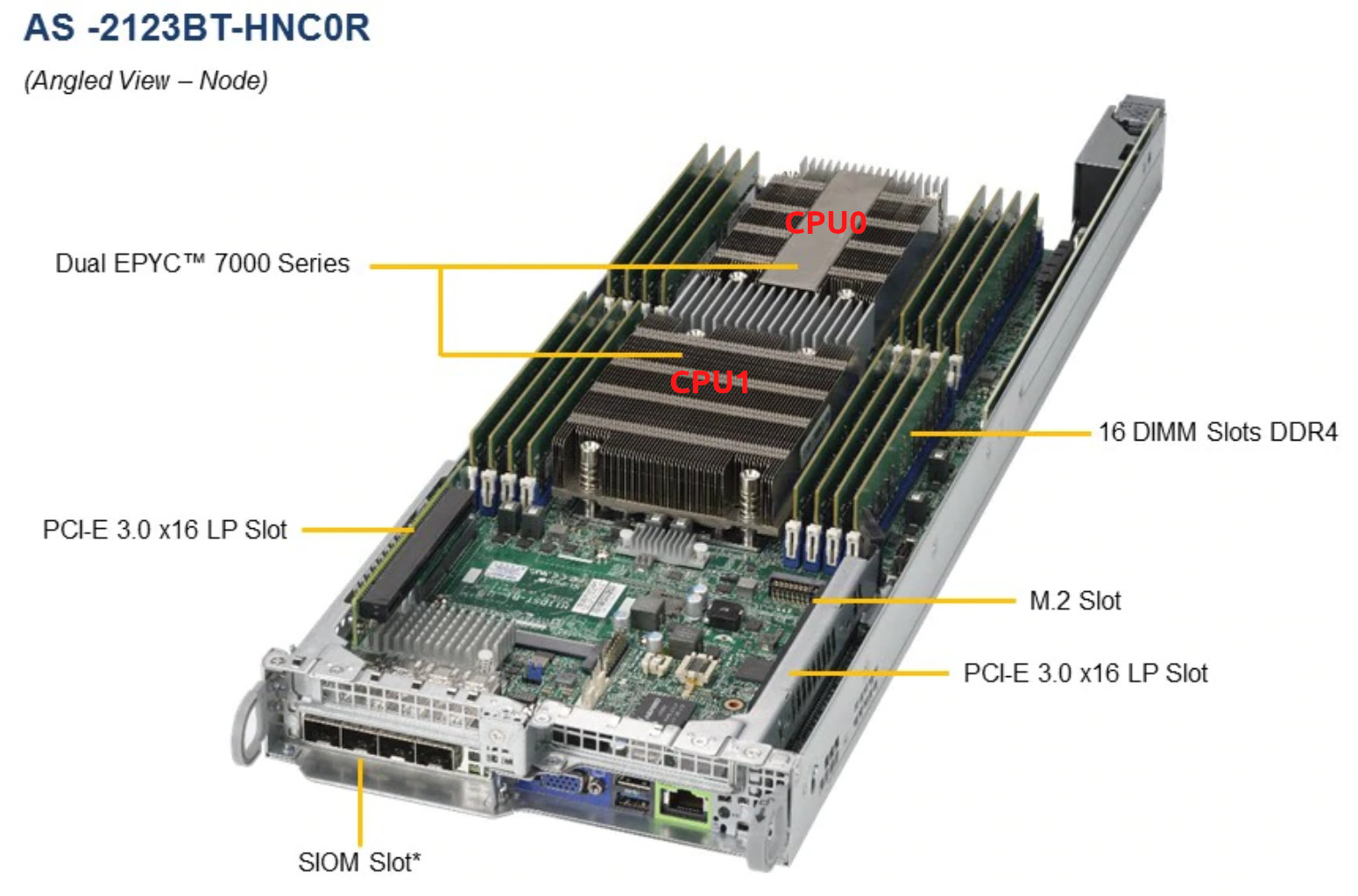
Lo moví al centro de datos, eliminé el nodo del servidor, cambié la pasta térmica, lo pegué, pero todavía se calienta.
Notamos que el flujo de aire en una parte del servidor no es tan fuerte como en la otra. Después de haber cargado ligeramente todos los nodos con stress-ng, se hizo evidente que los procesadores de nodos en el lado derecho de la plataforma no explotan correctamente y la temperatura de la segunda CPU en dos nodos alcanza rápidamente un nivel crítico.
Después de intentar cambiar los parámetros de soplado en BMC, resultó que no tenían ningún efecto:
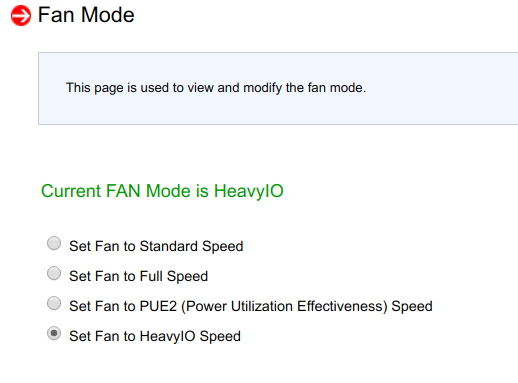
Reiniciar BMC tampoco tuvo efecto.
Después de mirar las lecturas del sensor, vi que en un nodo de 53 sensores, solo se detectan 4 y en el otro nodo solo 6:
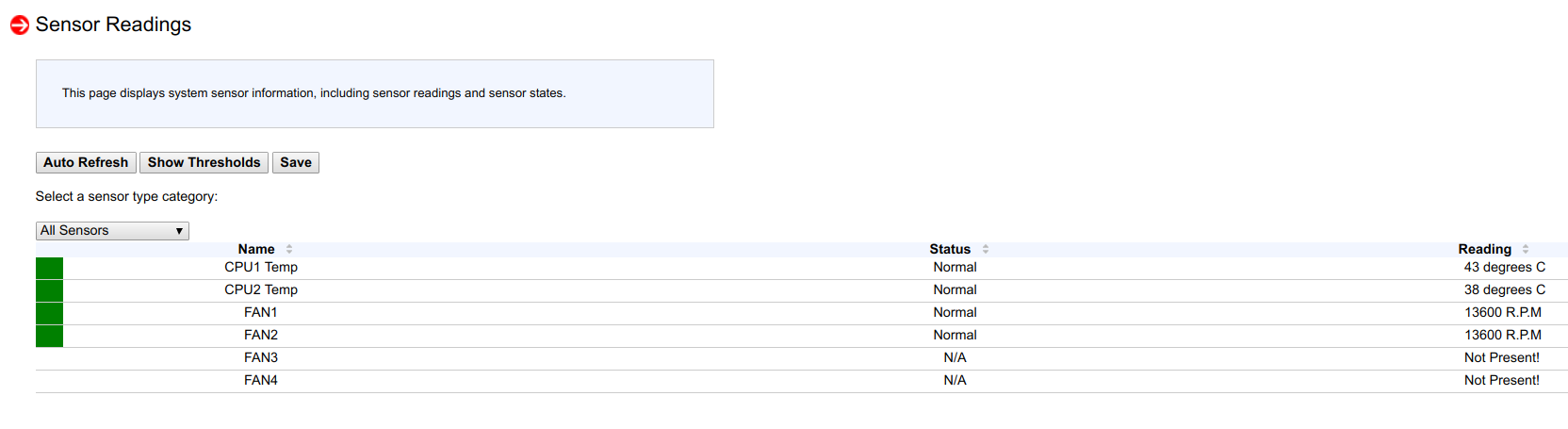
Y luego, recordé que al actualizar una nueva versión del BIOS y un nuevo BMC en los nodos hace un mes o dos, en dos nodos no restablecí la configuración del BMC a los parámetros de fábrica (para verificar un caso particular de ajuste).
Después de restablecer el BMC a los parámetros de fábrica, se detectaron nuevamente los 53 sensores, el control de velocidad del ventilador volvió a funcionar y los procesadores dejaron de calentarse.
El hecho de que la causa de la descarga del controlador QLogic sea el sobrecalentamiento del procesador no es exacto, pero no encontré otras correlaciones cercanas.
Conclusiones:
- después del firmware BMC, incluso si todo funciona bien a primera vista, vale la pena restablecer la configuración de fábrica;
- Por supuesto, los mensajes de error de temperatura y núcleo deben ser monitoreados y esto es natural en los planes, pero no todos a la vez.