Mi nombre es Vladislav, participo en el desarrollo de
Tarantool - DBMS y servidor de aplicaciones en una botella. Y hoy les contaré cómo implementamos el escalado horizontal en Tarantool usando el módulo
VShard .
Primero, una pequeña teoría.
Hay dos tipos de escalado: horizontal y vertical. Horizontal se divide en dos tipos: replicación y fragmentación. La replicación se usa para escalar la computación, el fragmentación se usa para escalar datos.
Sharding se divide en dos tipos: sharding por rangos y sharding por hashes.
Al fragmentar con rangos, calculamos alguna clave de fragmento de cada registro en el clúster. Estas teclas de fragmentos se proyectan en una línea recta, que se divide en rangos que agregamos a diferentes nodos físicos.
El fragmentado con hash es más simple: de cada registro en el clúster consideramos una función hash, agregamos las entradas con el mismo valor de la función hash a un nodo físico.
Hablaré sobre el escalado horizontal usando el hash sharding.
Implementación previa
El primer módulo de escala horizontal que tuvimos fue el
fragmento de Tarantool . Este es un particionamiento muy simple por hashes, que considera la clave de fragmento de la clave primaria de todas las entradas en el clúster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Pero luego surgió una tarea que Tarantool Shard no pudo manejar por tres razones fundamentales.
Primero,
se requería la
localidad de los datos relacionados lógicamente . Cuando tenemos datos que están conectados lógicamente, siempre queremos almacenarlos en el mismo nodo físico, sin importar cómo cambie la topología del clúster o se realice el equilibrio. Y el fragmento de Tarantool no garantiza esto. Considera el hash solo por las claves primarias y, al reequilibrar, incluso los registros con el mismo hash se pueden dividir durante algún tiempo; la transferencia no es atómica.
El problema de la falta de localidad de los datos nos lo impidió más. Daré un ejemplo. Hay un banco en el que el cliente abrió una cuenta. Los datos de la cuenta y del cliente siempre deben almacenarse físicamente juntos para que puedan leerse en una solicitud, intercambiarse en una transacción, por ejemplo, al transferir dinero desde una cuenta. Si usa un fragmento clásico con el fragmento de Tarantool, los valores de las funciones de fragmento serán diferentes para las cuentas y los clientes. Los datos pueden estar en diferentes nodos físicos. Esto complica enormemente tanto la lectura como el trabajo transaccional con dicho cliente.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
En el ejemplo anterior, los campos de
id no pueden coincidir fácilmente con cuentas y clientes. Están conectados a través del campo de cuenta
customer_id y
customer_id id . El mismo campo de
id rompería la unicidad de la clave principal de la cuenta. Y de otra manera, Shard no puede fragmentarse.
El siguiente problema es el
lento reajuste . Este es el problema clásico de todos los fragmentos en hashes. La conclusión es que cuando cambiamos la composición de un clúster, generalmente cambiamos la función de fragmento, porque generalmente depende de la cantidad de nodos. Y cuando la función cambia, debe revisar todas las entradas del clúster y volver a calcular la función de fragmento. Quizás transfiera algunas notas. Y mientras los estamos transfiriendo, no sabemos si los datos que necesita la próxima solicitud entrante ya se han transferido, tal vez ahora estén en proceso de transferencia. Por lo tanto, durante la reorganización, es necesario que cada lectura solicite dos funciones de fragmento: la antigua y la nueva. Las solicitudes se están volviendo dos veces más lentas, y para nosotros fue inaceptable.
Otra característica de Tarantool Shard fue que cuando algunos nodos en los conjuntos de réplicas fallan, muestra
poca accesibilidad de lectura .
Nueva solución
Para resolver los tres problemas descritos, creamos
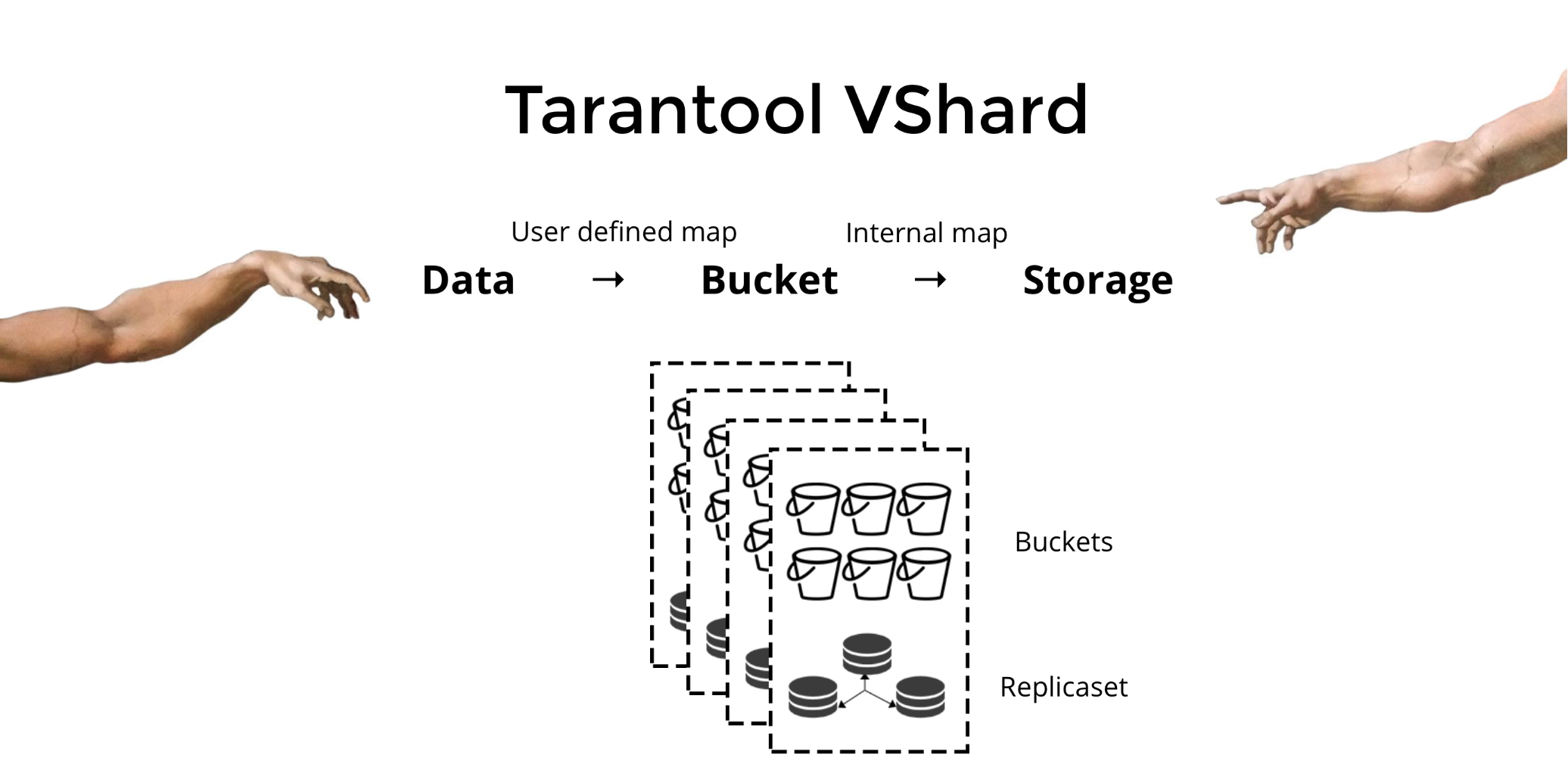
Tarantool VShard . Su diferencia clave es que el nivel de almacenamiento de datos está virtualizado: los almacenamientos virtuales aparecieron sobre los físicos, y los registros se distribuyen entre ellos. Estos almacenamientos se llaman bucket'ami. El usuario no necesita pensar en qué y en qué nodo físico se encuentra. Bucket es una unidad de datos indivisible atómica, como en la fragmentación clásica de una tupla. VShard siempre almacena el depósito completo en un nodo físico y, durante la reorganización, transfiere todos los datos de un depósito atómicamente. Debido a esto, se proporciona la localidad. Solo necesitamos poner los datos en un cubo, y siempre podemos estar seguros de que estos datos estarán junto con cualquier cambio en el clúster.

¿Cómo puedo poner datos en un cubo? En el esquema que presentamos anteriormente para el cliente del banco, agregaremos el
bucket id del
bucket id a las tablas de acuerdo con el nuevo campo. Si los datos vinculados son los mismos, los registros estarán en el mismo depósito. La ventaja es que podemos almacenar estos registros con la misma
bucket id en diferentes espacios, e incluso en diferentes motores. La
bucket id proporciona independientemente de cómo se almacenen estos registros.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
¿Por qué estamos tan ansiosos por esto? Si tenemos fragmentos clásicos, entonces los datos pueden colarse en todos los almacenamientos físicos que solo tenemos. En el ejemplo con el banco, al solicitar todas las cuentas de un cliente, deberá recurrir a todos los nodos. Resulta la dificultad de leer O (N), donde N es el número de tiendas físicas. Muy lento
Gracias a bucket'am y la localidad por
bucket id siempre podemos leer datos de un nodo en una solicitud, independientemente del tamaño del clúster.

Debe calcular la
bucket id del
bucket id y asignar los mismos valores usted mismo. Para algunos, esto es una ventaja, para alguien una desventaja. Considero que es una ventaja que pueda elegir la función para calcular la
bucket id del
bucket id usted mismo.
¿Cuál es la diferencia clave entre los fragmentos clásicos y los fragmentos virtuales con el cubo?
En el primer caso, cuando cambiamos la composición del clúster, tenemos dos estados: el actual (antiguo) y el nuevo, en el que debemos ir. En el proceso de transición, no solo necesita transferir los datos, sino también recalcular las funciones hash para todos los registros. Esto es muy inconveniente, porque en cualquier momento no sabemos qué datos ya se han transferido y cuáles no. Además, esto no es confiable ni atómico, ya que para la transferencia atómica de un conjunto de registros con el mismo valor de la función hash, es necesario almacenar persistentemente el estado de transferencia en caso de que sea necesaria la recuperación. Hay conflictos, errores, debe reiniciar el procedimiento muchas veces.
El fragmentación virtual es mucho más simple. No tenemos dos estados seleccionados del clúster, solo tenemos el estado del depósito. El grupo se vuelve más maniobrable, gradualmente se mueve de un estado a otro. Y ahora hay más de dos estados. Gracias a una transición sin problemas, puede cambiar el saldo sobre la marcha, eliminar el almacenamiento recién agregado. Es decir, la capacidad de control del equilibrio aumenta considerablemente, se vuelve granular.
Uso
Digamos que elegimos una función para la
bucket id y vertimos tantos datos en el clúster que no había más espacio. Ahora queremos agregar nodos y que los datos se trasladen a ellos mismos. En VShard, esto se hace de la siguiente manera. Primero, inicie nuevos nodos y Tarantools en ellos, y luego actualice la configuración de VShard. Describe todos los miembros del clúster, todas las réplicas, conjuntos de réplicas, maestros, URI asignados y mucho más.
VShard.storage.cfg nuevos nodos a la configuración, y usando la función
VShard.storage.cfg , la usamos en todos los nodos del clúster.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Como recordará, en los fragmentos clásicos con un cambio en el número de nodos, la función de fragmentos también cambia. En VShard esto no sucede, tenemos un número fijo de almacenamientos virtuales: bucket'ov. Esta es la constante que selecciona al iniciar el clúster. Puede parecer que debido a esto, la escalabilidad es limitada, pero en realidad no. Puede elegir una gran cantidad de bucket'ov, decenas y cientos de miles. Lo principal es que debe haber al menos dos órdenes de magnitud más que el número máximo de conjuntos de réplicas que tendrá en el clúster.
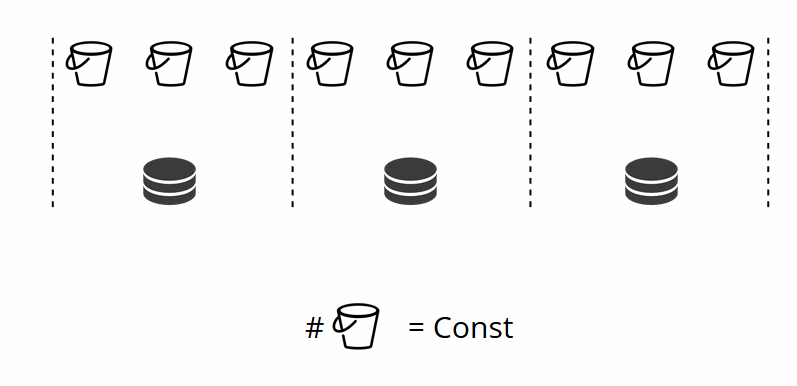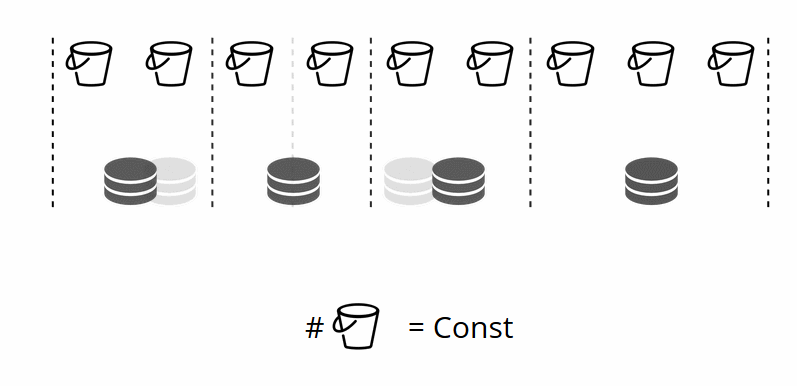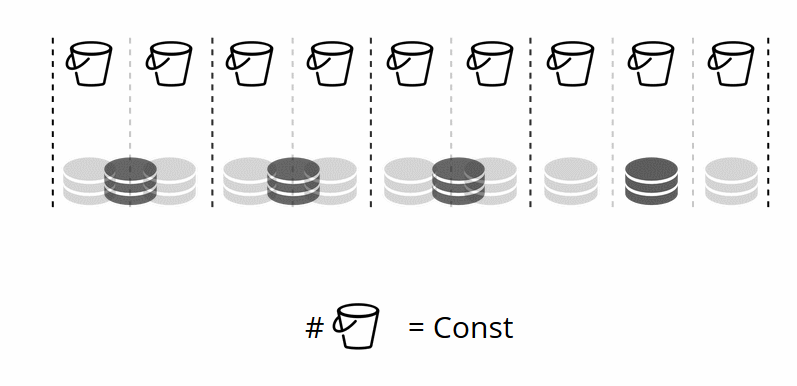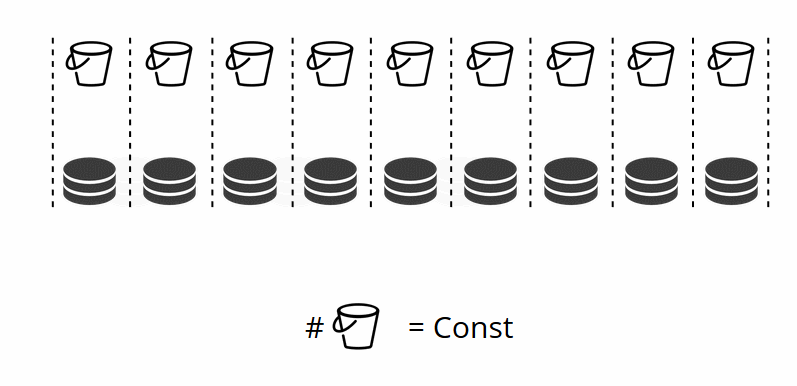
Dado que el número de almacenamientos virtuales no cambia, y la función de fragmento depende solo de este valor, podemos agregar tantos almacenamientos físicos como sea necesario sin volver a contar la función de fragmento.
¿Cómo se distribuyen los paquetes entre las tiendas físicas por su cuenta? Cuando se llama a VShard.storage.cfg en uno de los nodos, se activa el proceso de reequilibrio. Este es un proceso analítico que calcula el equilibrio perfecto en un clúster. Acude a todos los nodos físicos, pregunta quién tiene cuántos bucket'ov y construye rutas para su movimiento con el fin de promediar la distribución. El reequilibrador envía rutas a almacenes llenos de gente, y comienzan a enviar baldes. Después de un tiempo, el grupo se equilibra.
Pero en proyectos reales, el concepto de equilibrio perfecto puede ser diferente. Por ejemplo, quiero almacenar menos datos en un conjunto de réplicas que en el otro, porque hay menos espacio en el disco duro. VShard piensa que todo está bien equilibrado y, de hecho, mi almacenamiento está a punto de desbordarse. Hemos proporcionado un mecanismo para ajustar las reglas de equilibrio utilizando pesos. Cada conjunto de réplicas y repositorio se pueden ponderar. Cuando el equilibrador decide a quién enviar cuántos bucket'ov, tiene en cuenta la
relación de todos los pares de pesas.
Por ejemplo, una tienda tiene un peso de 100 y la otra tiene 200. Luego, la primera almacenará dos veces menos bucket'ov que la segunda. Tenga en cuenta que estoy hablando específicamente sobre la
relación de pesos. Los significados absolutos no tienen efecto. Puede elegir pesos basados en una distribución de clúster del 100%: una tienda tiene el 30%, otra tiene el 70%. Puede tomar la capacidad de almacenamiento en gigabytes como base, o puede medir pesos en la cantidad de bucket'ov. Lo principal es observar la actitud que necesita.
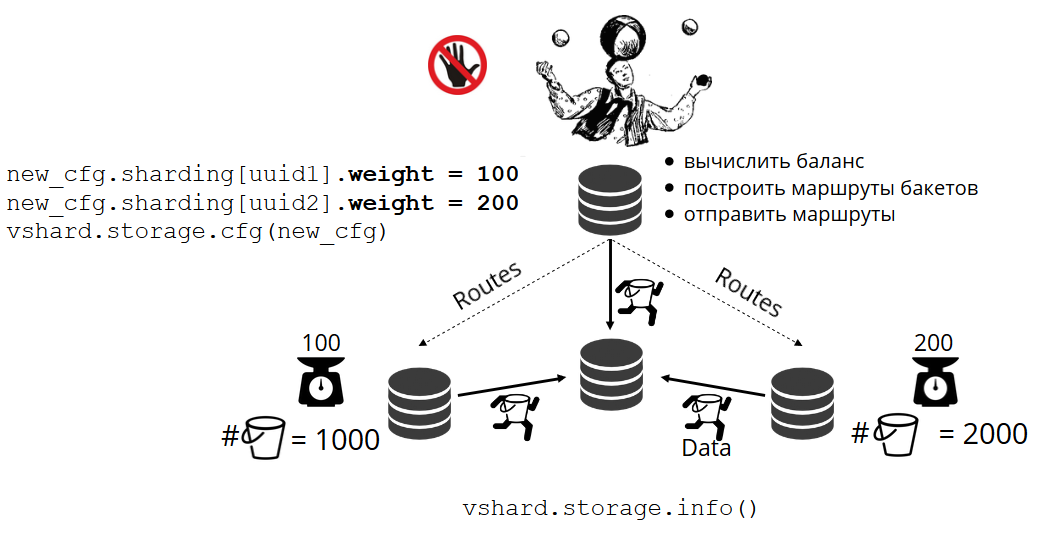
Tal sistema tiene un efecto secundario interesante: si asigna un peso cero a alguna tienda, entonces el equilibrador ordenará a la tienda que distribuya todos sus cubos. Después de eso, puede eliminar todo el conjunto de réplicas de la configuración.
Transferencia de cubo atómico
Tenemos un depósito, acepta algún tipo de solicitud de lectura y escritura, y luego el equilibrador solicita transferirlo a otro almacenamiento. Bucket deja de aceptar solicitudes de grabación, de lo contrario podrán actualizarlo durante la transferencia, luego tendrán tiempo para actualizar la actualización portátil, luego la actualización de la actualización portátil, y así hasta el infinito. Por lo tanto, el registro está bloqueado y aún puede leer desde el bucket. Comienza la transferencia de trozos a un nuevo lugar. Una vez completada la transferencia, el depósito volverá a comenzar a aceptar solicitudes. En el lugar anterior, también sigue mintiendo, pero ya se ha marcado como basura y, posteriormente, el recolector de basura lo eliminará trozo por trozo.
Cada depósito está asociado con metadatos que se almacenan físicamente en el disco. Todos los pasos anteriores se guardan en el disco, y pase lo que pase con el repositorio, el estado del depósito se restaurará automáticamente.
Puedes tener preguntas:
- ¿Qué pasará con esas solicitudes que funcionaron con el depósito cuando comenzaron a portarlo?
Hay dos tipos de enlaces en los metadatos de cada depósito: lectura y escritura. Cuando el usuario realiza una solicitud al depósito, indica cómo trabajará con él, solo lectura o lectura escritura. Para cada solicitud, se incrementa el contador de referencia correspondiente.
¿Por qué necesito un contador de referencia para leer las solicitudes? Digamos que el depósito se transfiere silenciosamente, y aquí viene el recolector de basura y quiere eliminar este depósito. Él ve que el recuento de enlaces es mayor que cero, por lo que no puede eliminarlo. Y cuando se procesen las solicitudes, el recolector de basura podrá completar su trabajo.
El contador de referencia para las solicitudes de escritura asegura que el depósito ni siquiera comienza a transferirse mientras al menos una solicitud de escritura está trabajando con él. Pero las solicitudes de escritura pueden venir constantemente, y luego el depósito nunca se transferirá. El hecho es que si el equilibrador ha expresado su deseo de transferirlo, las nuevas solicitudes de grabación comenzarán a bloquearse y el sistema actual esperará a que se complete el tiempo de espera. Si las solicitudes no se completan en el tiempo asignado, el sistema nuevamente comenzará a aceptar nuevas solicitudes de escritura, posponiendo la transferencia del depósito por un tiempo. Por lo tanto, el equilibrador realizará los intentos de transferencia hasta que uno tenga éxito.
VShard tiene una API bucket_ref de bajo nivel en caso de que tenga pocas características de alto nivel. Si realmente quiere hacer algo usted mismo, solo acceda a esta API desde el código. - ¿Es posible no bloquear registros en absoluto?
Es imposible Si el depósito contiene datos críticos que necesitan acceso de escritura constante, tendrá que bloquear su transferencia por completo. Para esto hay una función bucket_pin , que une firmemente el depósito al conjunto de réplica actual, evitando su transferencia. En este caso, el bucket'y vecino podrá moverse sin restricciones.

Hay una herramienta aún más poderosa que bucket_pin : bloqueo de conjunto de réplicas. Ya no se hace en código, sino a través de la configuración. El bloqueo prohíbe el movimiento de cualquier bucket'ov de esta réplica set'a y la recepción de nuevos. En consecuencia, todos los datos estarán constantemente disponibles para la grabación.

VShard.router
VShard consta de dos submódulos: VShard.storage y VShard.router. Se pueden crear y escalar independientemente incluso en una instancia. Al acceder al clúster, no sabemos dónde se encuentra el depósito, y VShard.router lo buscará por
bucket id para nosotros.
Veamos un ejemplo de cómo se ve esto. Regresamos al clúster bancario y a las cuentas de los clientes. Quiero poder extraer todas las cuentas de un cliente particular del clúster. Para hacer esto, escribo la función habitual para la búsqueda local:
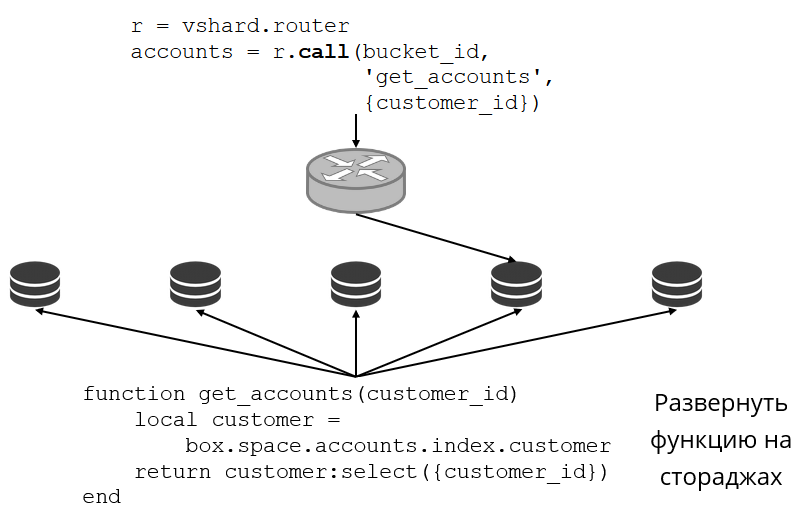
Ella busca todas las cuentas de clientes por su identificación. Ahora necesito decidir cuál de los repositorios llamará a esta función. Para hacer esto, calculo la
bucket id del
bucket id partir de la identificación del cliente en mi solicitud y le pido a VShard.router que me llame a tal función en el almacenamiento donde vive el depósito con la
bucket id resultante. Hay una tabla de enrutamiento en el submódulo, en la que se especifica la ubicación del depósito en el conjunto de réplicas. Y VShard.router representa mi solicitud.
Por supuesto, puede suceder que en este momento la reorganización comenzó y el cubo comenzó a moverse. El enrutador en segundo plano actualiza gradualmente la tabla en fragmentos grandes: consulta los repositorios para sus tablas de depósito actuales.
Incluso puede suceder que recurramos al depósito que se acaba de mover, y el enrutador aún no ha logrado actualizar su tabla de enrutamiento. Luego, recurrirá al antiguo repositorio y le indicará al enrutador dónde buscar el depósito o simplemente responderá que no tiene los datos necesarios. Luego, el enrutador recorrerá todos los almacenes en busca del cubo deseado. Y todo esto es transparente para nosotros, ni siquiera notaremos una falla en la tabla de enrutamiento.
Leer inestabilidad
Recordemos qué problemas tuvimos inicialmente:
- No hubo localidad de datos. Decidimos agregando bucket'ov.
- Volver a cargar disminuyó la velocidad y ralentizó todo. Implementado la transferencia de datos atómicos bucket'ami, se deshizo del recuento de funciones de fragmentos.
- Lectura inestable.
VShard.router resuelve el último problema utilizando el subsistema de conmutación por error de lectura automática.
El enrutador hace ping periódicamente al almacenamiento especificado en la configuración. Y luego algunos de ellos dejaron de hacer ping. El enrutador tiene una conexión de respaldo en caliente para cada réplica, y si la actual deja de responder, irá a otra. La solicitud de lectura se procesará normalmente, porque podemos leer en réplicas (pero no escribir). Podemos establecer la prioridad de las réplicas mediante las cuales el enrutador debe seleccionar la conmutación por error para las lecturas. Hacemos esto con la zonificación.
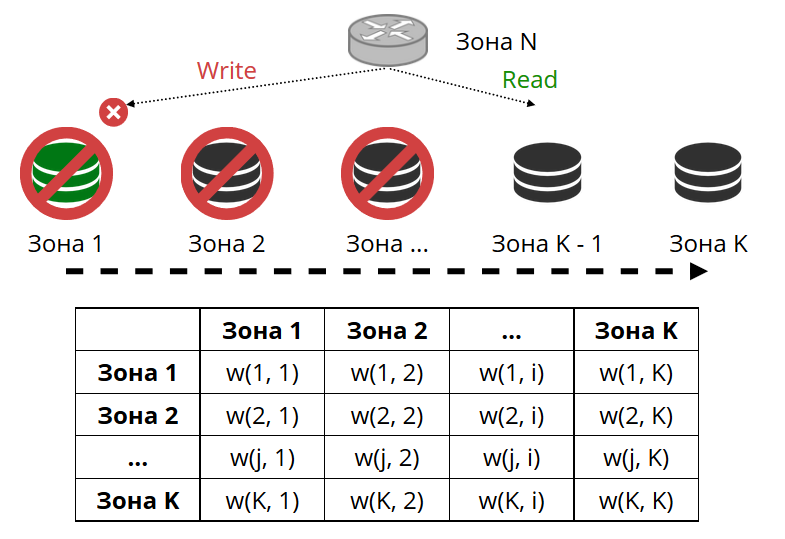
Asignamos un número de zona a cada réplica y cada enrutador y establecemos una tabla en la que indicamos la distancia entre cada par de zonas. Cuando el enrutador decide dónde enviar una solicitud de lectura, seleccionará una réplica en la zona más cercana a la suya.
Cómo se ve en la configuración:
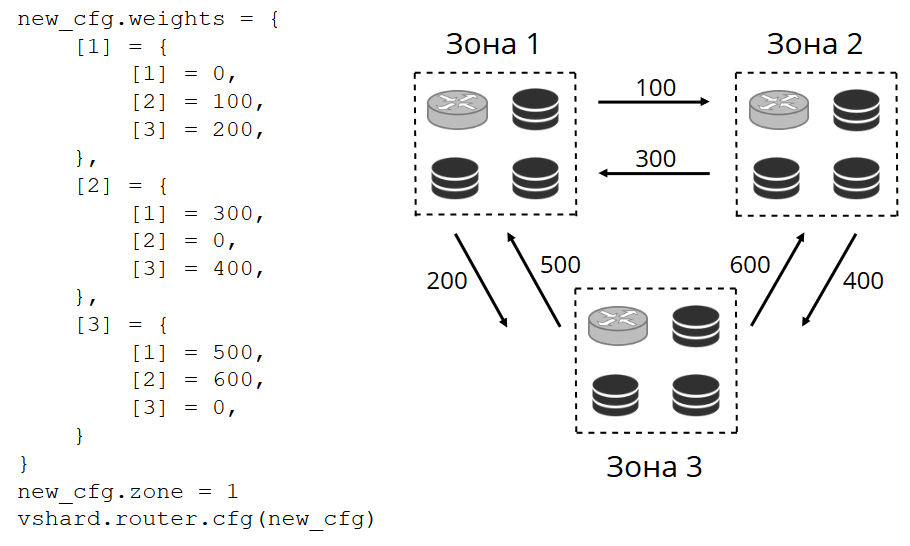
En el caso general, puede hacer referencia a una réplica arbitraria, pero si el clúster es grande y complejo, muy distribuido, la zonificación es muy útil. Los diferentes racks de servidores pueden ser zonas, para no cargar la red con tráfico. O pueden ser puntos geográficamente distantes entre sí.
La zonificación también ayuda a variar el rendimiento de la réplica. Por ejemplo, en cada conjunto de réplicas tenemos una réplica de respaldo, que no debe aceptar solicitudes, sino solo almacenar una copia de los datos. Luego lo hacemos en la zona, que estará muy lejos de todos los enrutadores de la tabla, y recurrirán a él en el caso más extremo.
Grabación de inestabilidad
Dado que estamos hablando de la conmutación por error de lectura, ¿qué pasa con la conmutación por error de escritura al cambiar el asistente? Aquí, VShard no es tan optimista: la elección de un nuevo maestro no se implementa en él, tendrá que hacerlo usted mismo. Cuando de alguna manera lo seleccionamos, es necesario que esta instancia ahora se haga cargo de la autoridad del maestro. Actualizamos la configuración especificando
master = false para el antiguo maestro y
master = true para el nuevo, aplíquelo a través de VShard.storage.cfg y enróllelo en el almacenamiento. Entonces todo sucede automáticamente. El viejo maestro deja de aceptar solicitudes de escritura y comienza a sincronizarse con el nuevo, porque puede haber datos que ya se han aplicado en el viejo maestro, pero el nuevo aún no ha llegado. Después de eso, el nuevo maestro ingresa al rol y comienza a aceptar solicitudes, y el viejo maestro se convierte en una réplica. Así es como funciona la conmutación por error de escritura en VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
¿Cómo ahora seguir toda esta variedad de eventos?
En el caso general, dos manejadores son suficientes:
VShard.storage.info y
VShard.router.info .
VShard.storage.info muestra información en varias secciones.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
El primero es la sección de replicación. Se muestra el estado del conjunto de réplicas al que aplicó esta función: qué retraso de replicación tiene, con quién tiene conexiones y con quién no está disponible, quién está disponible y qué no está disponible, qué asistente está configurado para qué, etc.
En la sección Bucket, puede ver en tiempo real cuántos bucket'ov se están moviendo actualmente al conjunto de réplica actual, cuántos lo están dejando, cuántos están trabajando actualmente en él, cuántos están marcados como basura, cuántos están conectados.
La sección Alerta es una mezcla de todos los problemas que VShard pudo determinar de forma independiente: el maestro no está configurado, el nivel de redundancia es insuficiente, el maestro está allí y todas las réplicas han fallado, etc.
Y la última sección es una luz que se ilumina en rojo cuando las cosas se ponen realmente mal. Es un número de cero a tres, cuanto más peor.
VShard.router.info tiene las mismas secciones, pero significan un poco diferente.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
La primera sección es la replicación. , : , replica set' , , , replica set' bucket' , .
Bucket bucket', ; bucket' ; , replica set'.
Alert, , , failover, bucket'.
, .
VShard?
— bucket'.
int32_max ? bucket' — 30 16 . bucket', . bucket', bucket'. , .
— -
bucket id . , - , bucket — . , bucket' , VShard bucket'. -, bucket' bucket, -. .
Resumen
Vshard :
- ;
- ;
- ;
- read failover;
- bucket'.
VShard . - . —
. , . .
—
lock-free bucket' . , bucket' . , .
—
. : - , , ? .