Prometheus 2.6.0 optimizó la carga de WAL, lo que acelera el proceso de inicio.
El objetivo no oficial de desarrollar Prometheus 2.x TSDB es acelerar el lanzamiento para que no demore más de un minuto. En los últimos meses, ha habido informes de que el proceso está tardando un poco más, y si Prometheus se reinicia por algún motivo, entonces esto ya es un problema. Casi todo este tiempo, se carga el WAL (grabación de pregrabación), que incluye muestras de las últimas horas que aún no se han comprimido en un bloque. A fines de octubre, finalmente logré resolverlo; el resultado es PR # 440 , que reduce el tiempo de CPU en 6.5 veces y el tiempo de cálculo en 4 veces. Veamos cómo hice estas mejoras.

Primero, se necesita una configuración de prueba. Creé un pequeño programa Go que genera TSDB con WAL con mil millones de muestras dispersas en 10,000 series de tiempo. Luego abrí este TSDB y miré cuánto tiempo tardó en usar la utilidad de time (no una estructura incorporada, ya que no incluye estadísticas de memoria), y también creé un perfil de CPU usando el paquete de tiempo de ejecución / pprof :
f, err := os.Create("cpu.prof") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile()
El perfil de la CPU no nos permite determinar directamente el tiempo de cálculo que nos interesa, sin embargo, existe una correlación significativa. Como resultado, en mi computadora de escritorio (procesador i7-3770 con 16 GB de RAM y unidades de estado sólido), la descarga tardó aproximadamente 4 minutos y un poco menos de 6 GB de RAM en su punto máximo:
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k 23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
Esto no es un zumbido, así que go tool pprof cpu.prof el perfil usando la go tool pprof cpu.prof y veamos cuánto tiempo llevará el proceso si usa el comando top .

Aquí flat es la cantidad de tiempo dedicado a una función determinada, y cum es el tiempo dedicado a esta función y a todas las funciones que llama. También puede ser útil ver estos datos en un gráfico para tener una idea de la pregunta. Prefiero usar el comando web para esto, pero hay otras opciones, incluidos los archivos svg, png y pdf.
Se puede ver que aproximadamente un tercio de nuestra CPU se gasta en agregar muestras a la base de datos interna, aproximadamente dos tercios en el procesamiento de WAL en general y un cuarto en limpiar la memoria ( runtime.scanobject ). Veamos el código para el primero de estos procesos usando list memSeries.*append :
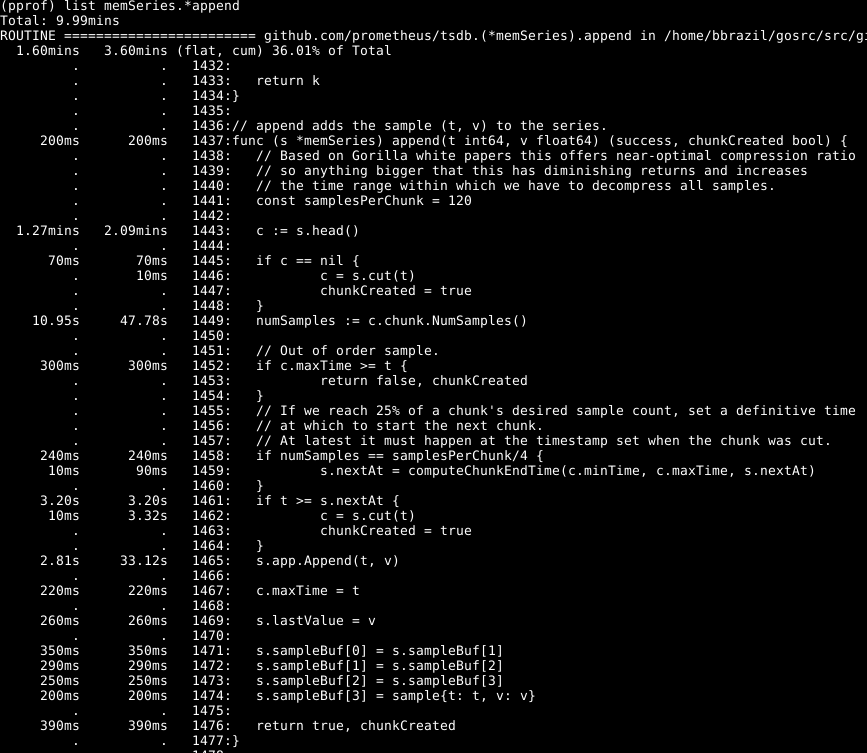
Lo siguiente es sorprendente aquí: se dedica más de la mitad del tiempo a obtener el dato principal de la serie en la línea 1443. Además, no se dedica poco tiempo a establecer el número de muestras en este dato en la línea 1449. El tiempo necesario para completar la línea 1465 - esperado, ya que este es el núcleo de la acción de esta función. En consecuencia, esperaba que la operación tomara la mayor parte del tiempo.
Eche un vistazo al elemento memSeries.head : calcula una pieza de datos que se devuelve cada vez. El fragmento de datos cambia solo después de cada 120 adiciones y, por lo tanto, podemos guardar el fragmento de encabezado actual en la estructura de datos de la serie . Esto ocupa parte de la RAM (a la que volveré más adelante ), pero ahorra una cantidad significativa de CPU. Y en general, también acelera Prometheus.
Entonces echemos un vistazo a Head.processWALSamples :
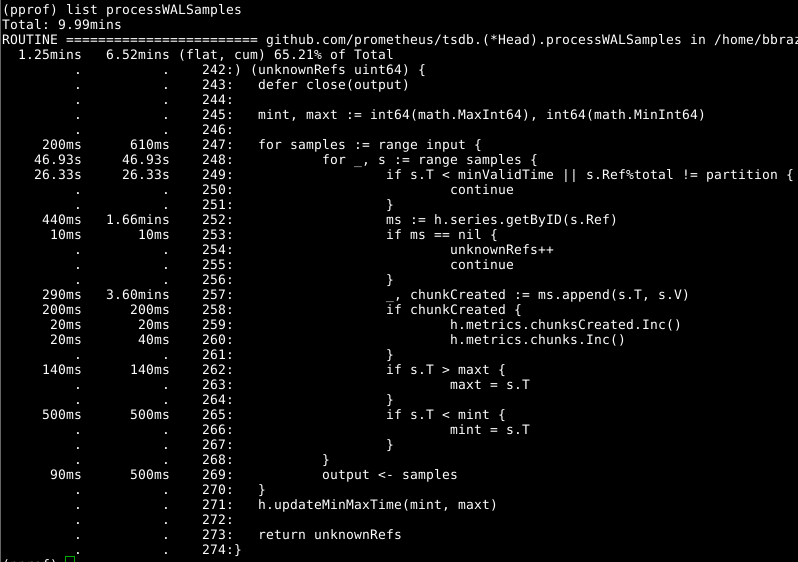
Este complemento ya se ha optimizado anteriormente, así que mira el siguiente culpable obvio, getByID en la línea 252:
(código)
Parece que hay algún tipo de conflicto de bloqueo, y se pierde tiempo haciendo una búsqueda de mapa de dos niveles. La memoria caché para cada identificador reduce significativamente este indicador.
Vale la pena Head.processWALSamples segundo vistazo a Head.processWALSamples , y le sorprende la cantidad de tiempo que pasó en la línea 249. Volvamos un poco a la pregunta de cómo funciona la carga de WAL: se crea Head.processWALSamples Head.processWALSamples para cada CPU disponible, además de otro para leer y decodificando WAL desde el disco. Las filas están segmentadas por estas gorutinas, por lo que la concurrencia puede ser una ventaja. El método de implementación es el siguiente: todas las muestras se envían a la primera gorutina, que procesa los elementos que necesita. Luego envía todas las muestras a la segunda gorutina, que procesa los elementos que necesita, y así sucesivamente, hasta que la última gorutina, Head.processWALSamples todos los datos a la gorutina de control.
Mientras tanto, los complementos se distribuyen a través de los núcleos, que es lo que necesita, y se realizan muchas tareas duplicadas en cada gorutin, que debe procesar todas las muestras y calcular el módulo. De hecho, cuantos más núcleos, más trabajo se duplica. Realicé cambios para segmentar los datos en la gourutina del controlador, de modo que cada gorutina de Head.processWALSamples ahora solo obtenga las muestras que necesita . En mi computadora, 8 ejecutando gorutin, el tiempo de cálculo se ahorró un poco, pero el volumen de la CPU fue decente. Para las computadoras con una gran cantidad de núcleos, los beneficios deberían ser más sustanciales.
Y nuevamente volvemos a la pregunta: hora de borrar la memoria. No podemos (generalmente) determinar esto a través de perfiles de CPU. En su lugar, preste atención a los perfiles de memoria dinámica para encontrar los elementos que se destacan. Esto requiere un poco de expansión de código al final del programa:
runtime.GC() hf, err := os.Create("heap.prof") if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(hf)
La limpieza formal de la memoria está asociada con cierta información en la memoria dinámica, cuya recolección y limpieza se lleva a cabo solo durante la limpieza de la memoria.
Nuevamente usamos la misma herramienta, pero especificamos la etiqueta -alloc_space , ya que estamos interesados en todas las operaciones de asignación de memoria, y no solo en las operaciones que usan memoria en un momento particular; por lo tanto, ejecute go tool pprof -alloc_space heap.prof . Si nos fijamos en el distribuidor superior, el culpable es obvio:
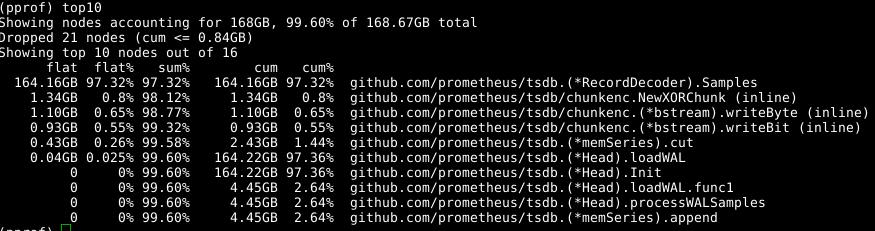
Echa un vistazo al código:
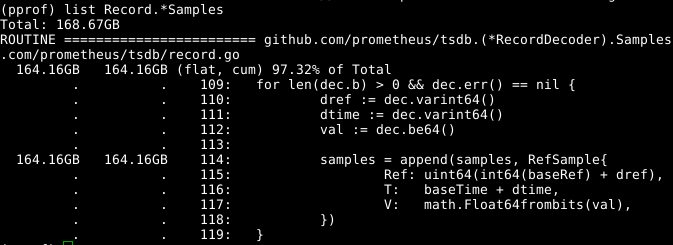
La matriz de samples extensible parece ser un problema. Si pudiéramos reutilizar la matriz al mismo tiempo que RecordDecoder.Samples a RecordDecoder.Samples , esto ahorraría una cantidad significativa de memoria. Resulta que el código fue compuesto de esta manera, pero un pequeño error de codificación condujo al hecho de que no funcionó. Si lo arregla , la memoria se borra en 8 segundos de la CPU en lugar de 151 segundos.
Los resultados generales son bastante tangibles:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k 23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
No solo hemos reducido el tiempo de cálculo en 4 veces, y el tiempo de la CPU, en 6,5 veces, sino que también la cantidad de memoria ocupada se reduce en más de 2 GB.
Parece que todo es simple, pero el truco es el siguiente: rebusqué decentemente en la base del código y analicé todo como si fuera en retrospectiva. Al estudiar el código, llegué a un callejón sin NumSamples varias veces, por ejemplo, al eliminar una llamada NumSamples , leer y decodificar en subprocesos separados, así como de varias maneras para segmentar processWALSamples . Estoy casi seguro de que al regular la cantidad de gorutinas, se puede lograr más, pero para esto las pruebas deben realizarse en máquinas más potentes que las mías, para que haya más núcleos. Logré mi objetivo: la productividad aumentó, y me di cuenta de que era mejor no hacer que el registro del programa fuera demasiado grande, y por lo tanto decidí detenerme allí.