Programme de reconnaissance d'images d'auto-apprentissage Disney Research
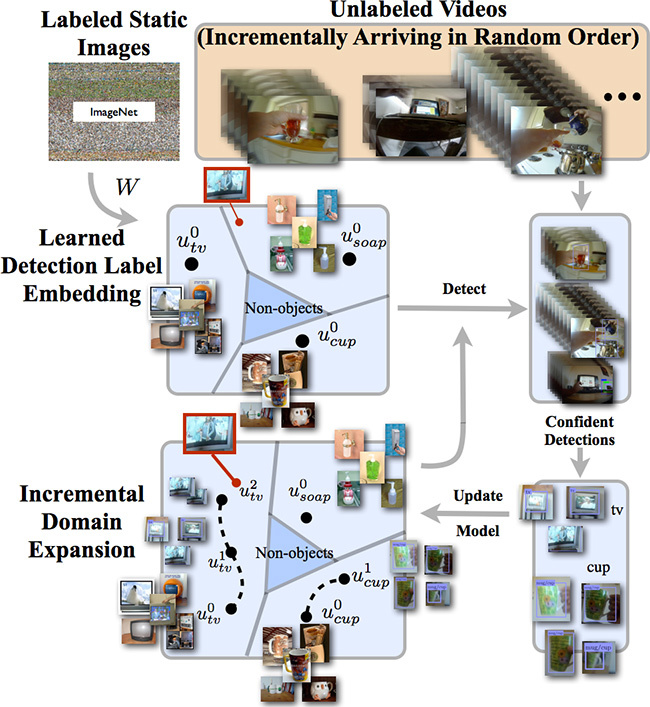 Une équipe de chercheurs de la division Pittsburgh de Disney Research a développé un système de vision par ordinateur qui utilise certains principes de la vision humaine ( pdf ). En particulier, il contient des algorithmes d'auto-apprentissage et est capable d'améliorer la reconnaissance d'objets au fil du temps.Comme la plupart des autres systèmes de vision par ordinateur, le développement de Disney Research construit un modèle conceptuel pour chaque objet, qu'il s'agisse d'un avion ou d'un distributeur de savon. Dans ce cas, un algorithme entraîné est utilisé qui analyse un grand nombre de photographies d'un objet donné.Une caractéristique distinctive de l'algorithme de Disney Research est qu'il utilise ensuite ce modèle pour reconnaître des objets dans la vidéo, tout en extrayant simultanément de nouvelles informations sur ces objets et en complétant le modèle prévu à l'origine. Cela vous permet de reconnaître des objets dans une plage plus large, même s'ils sont différents de ceux des échantillons rencontrés précédemment.Les illustrations (cliquables) montrent le résultat de la reconnaissance des formes. Dans la rangée supérieure se trouvent des images de test de la base de données ImageNet, qui ont été utilisées pour former le modèle d'origine. Dans la rangée du bas se trouvent des exemples de reconnaissance correcte des objets par le programme IDE-LME. Les chercheurs notent que les objets reconnus sur les photographies diffèrent considérablement en apparence de ceux utilisés pour entraîner le système. «Le processus [d'auto-apprentissage] se poursuit, potentiellement indéfiniment, tout au long de la vie du système de reconnaissance», explique Leonid Sigal, chercheur principal à Disney Research Pittsburgh. «Il s'agit d'un système d'auto-apprentissage qui évolue en permanence grâce à l'acquisition incontrôlée d'expérience, constituant un modèle du monde de plus en plus complet et complexe.»
Une équipe de chercheurs de la division Pittsburgh de Disney Research a développé un système de vision par ordinateur qui utilise certains principes de la vision humaine ( pdf ). En particulier, il contient des algorithmes d'auto-apprentissage et est capable d'améliorer la reconnaissance d'objets au fil du temps.Comme la plupart des autres systèmes de vision par ordinateur, le développement de Disney Research construit un modèle conceptuel pour chaque objet, qu'il s'agisse d'un avion ou d'un distributeur de savon. Dans ce cas, un algorithme entraîné est utilisé qui analyse un grand nombre de photographies d'un objet donné.Une caractéristique distinctive de l'algorithme de Disney Research est qu'il utilise ensuite ce modèle pour reconnaître des objets dans la vidéo, tout en extrayant simultanément de nouvelles informations sur ces objets et en complétant le modèle prévu à l'origine. Cela vous permet de reconnaître des objets dans une plage plus large, même s'ils sont différents de ceux des échantillons rencontrés précédemment.Les illustrations (cliquables) montrent le résultat de la reconnaissance des formes. Dans la rangée supérieure se trouvent des images de test de la base de données ImageNet, qui ont été utilisées pour former le modèle d'origine. Dans la rangée du bas se trouvent des exemples de reconnaissance correcte des objets par le programme IDE-LME. Les chercheurs notent que les objets reconnus sur les photographies diffèrent considérablement en apparence de ceux utilisés pour entraîner le système. «Le processus [d'auto-apprentissage] se poursuit, potentiellement indéfiniment, tout au long de la vie du système de reconnaissance», explique Leonid Sigal, chercheur principal à Disney Research Pittsburgh. «Il s'agit d'un système d'auto-apprentissage qui évolue en permanence grâce à l'acquisition incontrôlée d'expérience, constituant un modèle du monde de plus en plus complet et complexe.»
 Le modèle conceptuel de chaque objet s'élargit et s'affine progressivement à mesure que le système rencontre de nouvelles informations. Théoriquement, une telle méthode peut conduire au fait qu'en agissant sans supervision, le système attribuera à l'objet des caractéristiques qui lui sont inhabituelles, ce qui entraînera des erreurs de reconnaissance. Mais les auteurs du programme disent qu'un tel problème n'a pas encore été remarqué.En plus de Sigal, les auteurs des travaux scientifiques incluent Alina Kuznetsova, Bodo Rosenhahn de l'Université de Wilhelm Leibniz (Hanovre, Allemagne) et l'ancien employé de Disney Sen Hwan Yu (qui travaille maintenant à l'Institut national des sciences) et la technologie à Ulsan (Corée du Sud).La présentation des travaux scientifiques a eu lieu lors de la conférence de l'IEEE sur la vision par ordinateur et la reconnaissance des formes à Boston (7-12 juin 2015).
Le modèle conceptuel de chaque objet s'élargit et s'affine progressivement à mesure que le système rencontre de nouvelles informations. Théoriquement, une telle méthode peut conduire au fait qu'en agissant sans supervision, le système attribuera à l'objet des caractéristiques qui lui sont inhabituelles, ce qui entraînera des erreurs de reconnaissance. Mais les auteurs du programme disent qu'un tel problème n'a pas encore été remarqué.En plus de Sigal, les auteurs des travaux scientifiques incluent Alina Kuznetsova, Bodo Rosenhahn de l'Université de Wilhelm Leibniz (Hanovre, Allemagne) et l'ancien employé de Disney Sen Hwan Yu (qui travaille maintenant à l'Institut national des sciences) et la technologie à Ulsan (Corée du Sud).La présentation des travaux scientifiques a eu lieu lors de la conférence de l'IEEE sur la vision par ordinateur et la reconnaissance des formes à Boston (7-12 juin 2015).Source: https://habr.com/ru/post/fr380363/
All Articles