Génération de musique classique à l'aide d'un réseau de neurones récurrent
De nos jours, les réseaux neuronaux entraînés font des choses incroyables, mais les expériences dans ce domaine continuent de découvrir quelque chose de nouveau. Par exemple, le programmeur Daniel Johnson a publié les résultats de ses expériences sur l'utilisation des réseaux de neurones pour générer de la musique classique.Malheureusement, vous ne pouvez pas intégrer un fichier audio sur GT, vous devez donc donner un lien direct pour écouter l'un des résultats: http://hexahedria.com/files/nnet_music_2.mp3 .Comment a-t-il fait?Daniel Johnson dit qu'il s'est concentré sur la propriété de l'invariance. La plupart des réseaux de neurones existants pour la génération de musique sont invariants dans le temps, mais pas invariants. Par conséquent, la transposition d'une seule étape entraînera un résultat complètement différent. Pour la plupart des autres applications, cette approche fonctionne bien, mais pas en musique. Ici, je voudrais parvenir à l'harmonie des harmonies.Daniel n'a trouvé qu'un seul type de réseaux de neurones populaires où il y a invariance dans plusieurs directions: ce sont des réseaux de neurones convolutifs pour la reconnaissance d'images.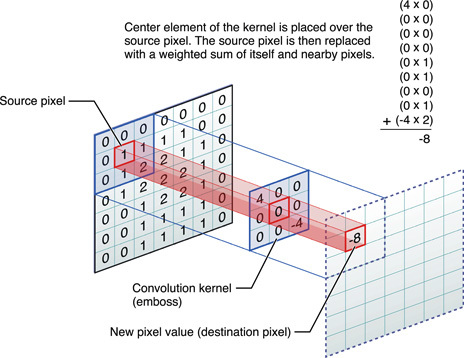 L'auteur a adapté le modèle convolutionnel, en ajoutant un réseau neuronal récurrent pour chaque pixel avec sa propre mémoire et en remplaçant les pixels par des notes. Ainsi, il a reçu un système invariant dans le temps et dans les notes.
L'auteur a adapté le modèle convolutionnel, en ajoutant un réseau neuronal récurrent pour chaque pixel avec sa propre mémoire et en remplaçant les pixels par des notes. Ainsi, il a reçu un système invariant dans le temps et dans les notes.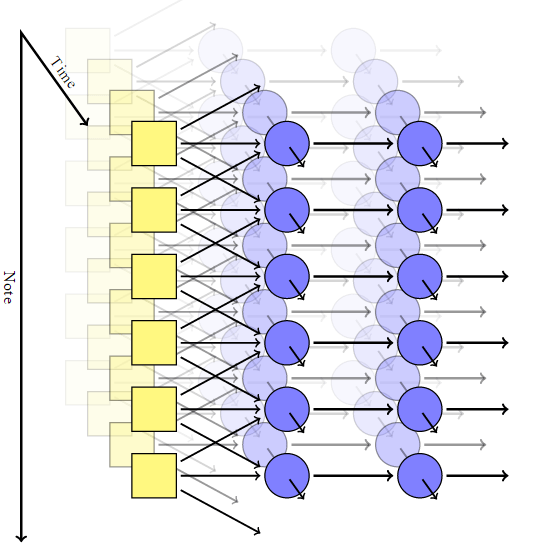 Mais dans un tel réseau il n'y a pas de mécanisme pour obtenir des accords harmonieux: à la sortie, chaque note est complètement indépendante des autres.Pour obtenir une combinaison de notes, Johnson a utilisé un modèle comme RNN-RBM, où une partie du réseau neuronal est responsable du temps et l'autre partie des accords consonantiques. Pour contourner les limites de la GAR, il a proposé l'introduction de deux axes: pour le temps et pour les notes (et un pseudo-axe pour la direction des calculs).
Mais dans un tel réseau il n'y a pas de mécanisme pour obtenir des accords harmonieux: à la sortie, chaque note est complètement indépendante des autres.Pour obtenir une combinaison de notes, Johnson a utilisé un modèle comme RNN-RBM, où une partie du réseau neuronal est responsable du temps et l'autre partie des accords consonantiques. Pour contourner les limites de la GAR, il a proposé l'introduction de deux axes: pour le temps et pour les notes (et un pseudo-axe pour la direction des calculs).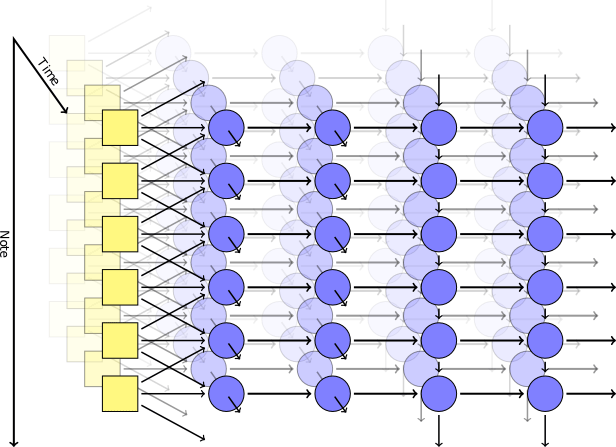 Utilisation de la bibliothèque Theanol'auteur a généré un réseau neuronal selon son modèle. La première couche avec l'axe du temps a pris les paramètres suivants à l'entrée: position, hauteur, valeur des notes environnantes, contexte précédent, rythme. Ensuite, des blocs auto-générateurs basés sur la mémoire à court terme (LSTM) ont été déclenchés: dans l'un, les connexions récurrentes sont dirigées le long de l'axe du temps, dans l'autre le long de l'axe des notes. Après le dernier bloc LSTM, il existe une simple couche non récurrente pour l'émission du résultat final, elle a deux valeurs de sortie: la probabilité de jouer pour une note particulière et la probabilité d'articulation (c'est-à-dire la probabilité que la note se combine avec une autre).Au cours de la formation, nous avons utilisé un ensemble de courts fragments musicaux sélectionnés au hasard dans la collection MIDI de Piano Classical Midi Page. Ensuite, nous avons joué un peu avec les logarithmes afin que le paramètre d'entropie croisée dans la sortie ne soit au moins pas trop bas. Pour garantir la spécialisation des couches, nous avons utilisé une technique telle que le décrochage , quand à chaque étape de la formation la moitié des nœuds cachés ont été accidentellement exclus.Le modèle pratique comprenait deux couches cachées dans le temps, chacune de 300 nœuds, et deux couches le long de l'axe des notes, pour 100 et 50 nœuds, respectivement. La formation a été menée sur la machine virtuelle g2.2xlarge dans le cloud Amazon Web Services.
Utilisation de la bibliothèque Theanol'auteur a généré un réseau neuronal selon son modèle. La première couche avec l'axe du temps a pris les paramètres suivants à l'entrée: position, hauteur, valeur des notes environnantes, contexte précédent, rythme. Ensuite, des blocs auto-générateurs basés sur la mémoire à court terme (LSTM) ont été déclenchés: dans l'un, les connexions récurrentes sont dirigées le long de l'axe du temps, dans l'autre le long de l'axe des notes. Après le dernier bloc LSTM, il existe une simple couche non récurrente pour l'émission du résultat final, elle a deux valeurs de sortie: la probabilité de jouer pour une note particulière et la probabilité d'articulation (c'est-à-dire la probabilité que la note se combine avec une autre).Au cours de la formation, nous avons utilisé un ensemble de courts fragments musicaux sélectionnés au hasard dans la collection MIDI de Piano Classical Midi Page. Ensuite, nous avons joué un peu avec les logarithmes afin que le paramètre d'entropie croisée dans la sortie ne soit au moins pas trop bas. Pour garantir la spécialisation des couches, nous avons utilisé une technique telle que le décrochage , quand à chaque étape de la formation la moitié des nœuds cachés ont été accidentellement exclus.Le modèle pratique comprenait deux couches cachées dans le temps, chacune de 300 nœuds, et deux couches le long de l'axe des notes, pour 100 et 50 nœuds, respectivement. La formation a été menée sur la machine virtuelle g2.2xlarge dans le cloud Amazon Web Services.résultats
Le code source du programme est publié sur Github . Source: https://habr.com/ru/post/fr382711/
All Articles