Google entend mieux, la recherche est plus facile
Google a annoncé avoir finalisé son système de recherche vocale afin d'améliorer la reconnaissance du discours de l'utilisateur dans les endroits bruyants. Il a toujours été l'un des meilleurs systèmes de reconnaissance vocale, il est particulièrement pratique lors de la recherche à l'aide de smartphones. Maintenant, la fonction de recherche vocale est devenue encore plus développée que jamais. Le blog Google Research décrit les améliorations qui ont été apportées au système mis à jour.Depuis 2012, le géant de la recherche a abandonné l'utilisation de la méthode des mélanges gaussiens (MGS) il y a trente ans dans la reconnaissance vocale. Les nouveaux systèmes ont commencé à utiliser des réseaux de neurones profonds ( Deep Neural Networks ). STS peut mieux reconnaître les sons émis par l'utilisateur à un certain moment, ce qui augmente considérablement la précision de la reconnaissance.
Il a toujours été l'un des meilleurs systèmes de reconnaissance vocale, il est particulièrement pratique lors de la recherche à l'aide de smartphones. Maintenant, la fonction de recherche vocale est devenue encore plus développée que jamais. Le blog Google Research décrit les améliorations qui ont été apportées au système mis à jour.Depuis 2012, le géant de la recherche a abandonné l'utilisation de la méthode des mélanges gaussiens (MGS) il y a trente ans dans la reconnaissance vocale. Les nouveaux systèmes ont commencé à utiliser des réseaux de neurones profonds ( Deep Neural Networks ). STS peut mieux reconnaître les sons émis par l'utilisateur à un certain moment, ce qui augmente considérablement la précision de la reconnaissance.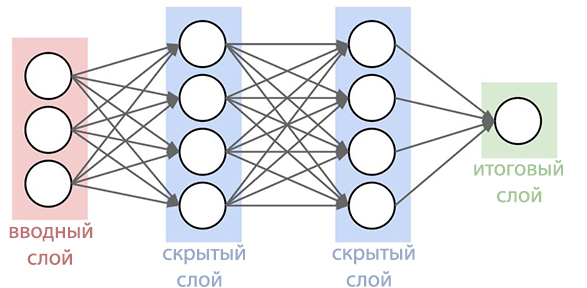 Maintenant, les experts de Google ont annoncé qu'ils étaient parvenus à créer un réseau neuronal plus avancé de modèles acoustiques qui utilisent une classification temporelle connexionniste et des algorithmes d' apprentissage discriminatoires . Ces modèles représentent une extension spéciale des réseaux de neurones périodiques qui sont plus précis, en particulier dans les environnements bruyants, et incroyablement rapides!Dans la reconnaissance vocale traditionnelle, le formulaire vocal que l'utilisateur a rempli a été divisé en trames (segments) consécutives de 10 millisecondes. Chaque image a subi une analyse de fréquence et le vecteur résultant avec les caractéristiques a été passé à travers des modèles acoustiques, tels que GNS, qui donnent des probabilités pour toutes les correspondances sonores. Le modèle de Markov caché (SMM) permet de démêler des détails inconnus à partir de ceux déjà obtenus, ce qui permet d'introduire une sorte de structuration de cette séquence de distributions de probabilité. Ce modèle est en outre combiné avec d'autres sources de connaissances, comme le modèle de prononciation, qui relie des séquences de sons à certains mots de la langue sélectionnée et le modèle de langue, qui à son tour exprime à quel point le mot fait référence à la langue sélectionnée.Le module de reconnaissance réconcilie ensuite toutes ces informations afin de déterminer la phrase que l'utilisateur fait. Si l'utilisateur dit, par exemple, le mot "musée" (mju: 'zɪəm est une forme phonétique), alors il peut être difficile de déterminer quand le son "j" se termine et le son "u" commence. Cependant, en vérité, le déterminant ne se soucie pas quand cette transition se produit. La seule chose qui le dérange, c'est précisément les sons qui ont été prononcés.Le nouveau modèle acoustique amélioré est basé sur les réseaux neuronaux périodiques (PNS). Dans la topologie du PNS, il existe des boucles de rétroaction qui vous permettent de simuler la dépendance temporelle. Lorsque l'utilisateur prononce / U / dans l'exemple précédent, l'appareil d'articulation de la personne passe en douceur du son / J / au son / M / tout d'abord. Essayez de prononcer le mot «musée», pour les personnes qui parlent couramment l'anglais, ce ne sera pas difficile et le mot se prononcera facilement d'un seul souffle, PNS est capable de saisir ce moment.
Maintenant, les experts de Google ont annoncé qu'ils étaient parvenus à créer un réseau neuronal plus avancé de modèles acoustiques qui utilisent une classification temporelle connexionniste et des algorithmes d' apprentissage discriminatoires . Ces modèles représentent une extension spéciale des réseaux de neurones périodiques qui sont plus précis, en particulier dans les environnements bruyants, et incroyablement rapides!Dans la reconnaissance vocale traditionnelle, le formulaire vocal que l'utilisateur a rempli a été divisé en trames (segments) consécutives de 10 millisecondes. Chaque image a subi une analyse de fréquence et le vecteur résultant avec les caractéristiques a été passé à travers des modèles acoustiques, tels que GNS, qui donnent des probabilités pour toutes les correspondances sonores. Le modèle de Markov caché (SMM) permet de démêler des détails inconnus à partir de ceux déjà obtenus, ce qui permet d'introduire une sorte de structuration de cette séquence de distributions de probabilité. Ce modèle est en outre combiné avec d'autres sources de connaissances, comme le modèle de prononciation, qui relie des séquences de sons à certains mots de la langue sélectionnée et le modèle de langue, qui à son tour exprime à quel point le mot fait référence à la langue sélectionnée.Le module de reconnaissance réconcilie ensuite toutes ces informations afin de déterminer la phrase que l'utilisateur fait. Si l'utilisateur dit, par exemple, le mot "musée" (mju: 'zɪəm est une forme phonétique), alors il peut être difficile de déterminer quand le son "j" se termine et le son "u" commence. Cependant, en vérité, le déterminant ne se soucie pas quand cette transition se produit. La seule chose qui le dérange, c'est précisément les sons qui ont été prononcés.Le nouveau modèle acoustique amélioré est basé sur les réseaux neuronaux périodiques (PNS). Dans la topologie du PNS, il existe des boucles de rétroaction qui vous permettent de simuler la dépendance temporelle. Lorsque l'utilisateur prononce / U / dans l'exemple précédent, l'appareil d'articulation de la personne passe en douceur du son / J / au son / M / tout d'abord. Essayez de prononcer le mot «musée», pour les personnes qui parlent couramment l'anglais, ce ne sera pas difficile et le mot se prononcera facilement d'un seul souffle, PNS est capable de saisir ce moment.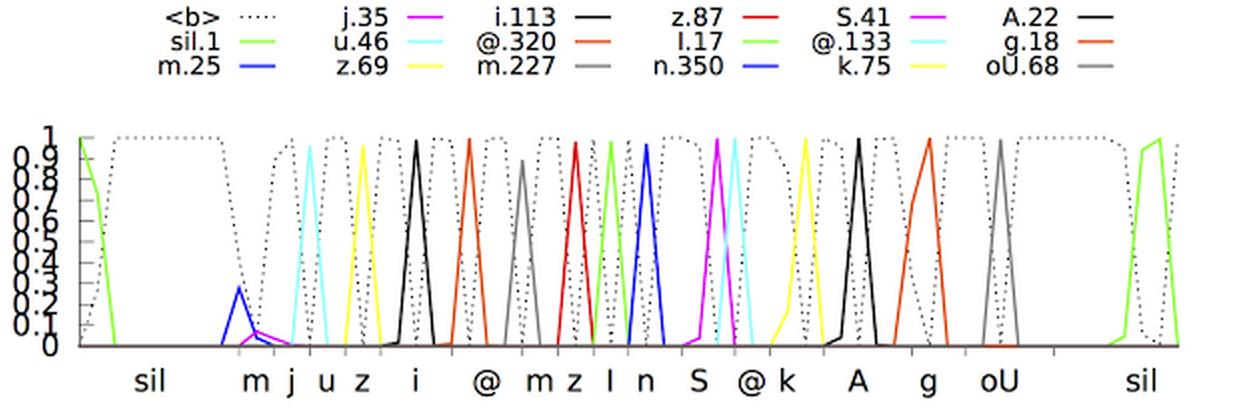 Un type de réseaux neuronaux périodiques dans ce système est une mémoire à long terme, qui, à l'aide de cellules de mémoire et d'un mécanisme de déclenchement complexe, se souvient mieux des informations que les autres PNS. Le déclenchement est une méthode d'allocation d'un certain intervalle de temps pour augmenter la probabilité de détecter des signaux utiles dans un contexte d'interférence. L'adoption de tels modèles a déjà considérablement amélioré la qualité de la reconnaissance vocale.L'étape suivante consistait à apprendre au modèle acoustique à reconnaître les phonèmes (sons) dans la parole prononcée sans faire de prédiction pour chaque trame. Les modèles avec la classification temporelle associative préparent un graphique avec une séquence de pointes qui affichent la séquence de sons dans le signal reçu. Ils peuvent le faire jusqu'à ce que la séquence soit interrompue.En fait, le système de reconnaissance vocale de Google peut désormais examiner le contexte dans lequel le mot a été prononcé, en s'éloignant des bruits de fond.
Un type de réseaux neuronaux périodiques dans ce système est une mémoire à long terme, qui, à l'aide de cellules de mémoire et d'un mécanisme de déclenchement complexe, se souvient mieux des informations que les autres PNS. Le déclenchement est une méthode d'allocation d'un certain intervalle de temps pour augmenter la probabilité de détecter des signaux utiles dans un contexte d'interférence. L'adoption de tels modèles a déjà considérablement amélioré la qualité de la reconnaissance vocale.L'étape suivante consistait à apprendre au modèle acoustique à reconnaître les phonèmes (sons) dans la parole prononcée sans faire de prédiction pour chaque trame. Les modèles avec la classification temporelle associative préparent un graphique avec une séquence de pointes qui affichent la séquence de sons dans le signal reçu. Ils peuvent le faire jusqu'à ce que la séquence soit interrompue.En fait, le système de reconnaissance vocale de Google peut désormais examiner le contexte dans lequel le mot a été prononcé, en s'éloignant des bruits de fond. Une question complètement différente: comment rendre tout accessible et pratique en temps réel? Après un grand nombre d'itérations, les programmeurs Google ont réussi à créer des modèles de streaming à flux unique qui traitent les signaux entrants avec des blocs plus grands que les blocs des modèles acoustiques standard, mais en même temps, ils effectuent moins de calculs réels. La réduction du nombre d'opérations de calcul accélère considérablement le processus de reconnaissance. De plus, le bruit artificiel et la réverbération (réduction artificielle des sons) ont été ajoutés au programme de formation du système pour rendre le système de reconnaissance plus résistant au bruit étranger. Dans la vidéo ci-dessous, vous pouvez regarder le système apprendre la phrase.Néanmoins, un autre problème restait à résoudre: le système produit moins de prévisions, mais en même temps elles sont retardées d'environ 300 millisecondes. En produisant le résultat après l'achèvement complet de la phrase, le niveau de reconnaissance a augmenté, mais en même temps, des retards supplémentaires ont été créés pour les utilisateurs, ce qui est totalement inacceptable pour les spécialistes de Goolge. Pour résoudre le problème, le système a été formé pour analyser et produire le résultat pour chaque phrase avant qu'elle ne soit terminée. Cela a rendu le processus de reconnaissance plus synchronisé avec le taux de prononciation normal d'une personne. L'utilisateur n'est plus obligé d'attendre que le programme affiche sa propre version de la phrase parlée.De nouveaux modèles acoustiques sont déjà utilisés pour la recherche vocale et les commandes dans l'application Google(sur Android et iOS) et pour la dictée sur les appareils Android. Les nouveaux modèles ont commencé à nécessiter moins de ressources, sont devenus plus résistants au bruit ambiant et ont pu produire des résultats beaucoup plus rapidement que leurs prédécesseurs. Cela rend la recherche vocale plus agréable pour l'utilisateur.
Une question complètement différente: comment rendre tout accessible et pratique en temps réel? Après un grand nombre d'itérations, les programmeurs Google ont réussi à créer des modèles de streaming à flux unique qui traitent les signaux entrants avec des blocs plus grands que les blocs des modèles acoustiques standard, mais en même temps, ils effectuent moins de calculs réels. La réduction du nombre d'opérations de calcul accélère considérablement le processus de reconnaissance. De plus, le bruit artificiel et la réverbération (réduction artificielle des sons) ont été ajoutés au programme de formation du système pour rendre le système de reconnaissance plus résistant au bruit étranger. Dans la vidéo ci-dessous, vous pouvez regarder le système apprendre la phrase.Néanmoins, un autre problème restait à résoudre: le système produit moins de prévisions, mais en même temps elles sont retardées d'environ 300 millisecondes. En produisant le résultat après l'achèvement complet de la phrase, le niveau de reconnaissance a augmenté, mais en même temps, des retards supplémentaires ont été créés pour les utilisateurs, ce qui est totalement inacceptable pour les spécialistes de Goolge. Pour résoudre le problème, le système a été formé pour analyser et produire le résultat pour chaque phrase avant qu'elle ne soit terminée. Cela a rendu le processus de reconnaissance plus synchronisé avec le taux de prononciation normal d'une personne. L'utilisateur n'est plus obligé d'attendre que le programme affiche sa propre version de la phrase parlée.De nouveaux modèles acoustiques sont déjà utilisés pour la recherche vocale et les commandes dans l'application Google(sur Android et iOS) et pour la dictée sur les appareils Android. Les nouveaux modèles ont commencé à nécessiter moins de ressources, sont devenus plus résistants au bruit ambiant et ont pu produire des résultats beaucoup plus rapidement que leurs prédécesseurs. Cela rend la recherche vocale plus agréable pour l'utilisateur. Source: https://habr.com/ru/post/fr384747/
All Articles