IoT et hackathon Azure Machine Learning: comment nous avons réalisé le projet hors compétition
 Il n'y a pas si longtemps, un autre hackathon Microsoft a eu lieu . Cette fois, il était dédié à l'apprentissage automatique . Le sujet est cependant très pertinent et prometteur, pour moi plutôt vague. Au début du hackathon, je n'avais qu'une idée générale de ce que c'était, pourquoi c'était nécessaire, et j'ai vu les résultats des modèles formés à quelques reprises. Après avoir appris que l'annonce promettait de nombreux experts pour aider les débutants, j'ai décidé de combiner affaires et plaisir et d'essayer d'utiliser l'apprentissage automatique lorsque je travaillais avec une sorte de solution IoT . Ensuite, je vais vous dire ce qui en est sorti.Je suis depuis longtemps engagé dans les systèmes de sécurité du périmètre, basée sur l'analyse des vibrations de la clôture, de sorte qu'une fois l'idée de travailler avec accéléromètre. L'idée était simple: apprendre au système à distinguer les vibrations de plusieurs téléphones, sur la base des données de l'accéléromètre. Des expériences similaires ont déjà été menées avec succès par mes collègues, je ne doute donc pas que cela soit possible.Au départ, je voulais tout faire sur le Raspberry Pi 2 et Windows IoT . Une planche spéciale a été préparée (sur la photo ci-dessous) avec des accéléromètres numériques et analogiques, mais je n'ai pas réussi à l'essayer en pratique, ayant décidé de tout faire sur un hackathon. Au cas où, j'ai également capturé notre capteur , qui vous permet également d'apprendre des données «brutes» sur les fluctuations.
Il n'y a pas si longtemps, un autre hackathon Microsoft a eu lieu . Cette fois, il était dédié à l'apprentissage automatique . Le sujet est cependant très pertinent et prometteur, pour moi plutôt vague. Au début du hackathon, je n'avais qu'une idée générale de ce que c'était, pourquoi c'était nécessaire, et j'ai vu les résultats des modèles formés à quelques reprises. Après avoir appris que l'annonce promettait de nombreux experts pour aider les débutants, j'ai décidé de combiner affaires et plaisir et d'essayer d'utiliser l'apprentissage automatique lorsque je travaillais avec une sorte de solution IoT . Ensuite, je vais vous dire ce qui en est sorti.Je suis depuis longtemps engagé dans les systèmes de sécurité du périmètre, basée sur l'analyse des vibrations de la clôture, de sorte qu'une fois l'idée de travailler avec accéléromètre. L'idée était simple: apprendre au système à distinguer les vibrations de plusieurs téléphones, sur la base des données de l'accéléromètre. Des expériences similaires ont déjà été menées avec succès par mes collègues, je ne doute donc pas que cela soit possible.Au départ, je voulais tout faire sur le Raspberry Pi 2 et Windows IoT . Une planche spéciale a été préparée (sur la photo ci-dessous) avec des accéléromètres numériques et analogiques, mais je n'ai pas réussi à l'essayer en pratique, ayant décidé de tout faire sur un hackathon. Au cas où, j'ai également capturé notre capteur , qui vous permet également d'apprendre des données «brutes» sur les fluctuations. Lors du hackathon, tous les participants ont été invités à se diviser en équipes et à résoudre l'un des 3 problèmes à l'aide de données pré-préparées. Ma tâche s'est avérée «hors compétition», mais l'équipe s'est réunie assez rapidement:
Lors du hackathon, tous les participants ont été invités à se diviser en équipes et à résoudre l'un des 3 problèmes à l'aide de données pré-préparées. Ma tâche s'est avérée «hors compétition», mais l'équipe s'est réunie assez rapidement: aucun de nous n'avait d'expérience avec Azure Machine Learning, il y avait donc beaucoup à faire! Merci à mes collègues, parmi lesquels se trouvait psfinaki , pour leurs efforts!Il a été décidé de diviser en 3 directions:
aucun de nous n'avait d'expérience avec Azure Machine Learning, il y avait donc beaucoup à faire! Merci à mes collègues, parmi lesquels se trouvait psfinaki , pour leurs efforts!Il a été décidé de diviser en 3 directions:- préparation des données pour l'analyse
- télécharger des données dans le cloud
- travailler avec Azure Machine Learning
La préparation des données consistait à les récupérer à l'accéléromètre, puis à les présenter sous une forme téléchargeable sur le cloud. Le téléchargement vers le cloud a été planifié via le hub d'événements . Eh bien, vous deviez comprendre comment utiliser ces données dans Azure Machine Learning.Des problèmes ont commencé sur les trois points. Il a fallu beaucoup de temps pour configurer Windows IoT sur Raspberry. Elle n'a pas donné d'image sur le moniteur. Il n'a été possible de résoudre ce problème qu'en entrant les lignes suivantes dans config.txt:
Il a fallu beaucoup de temps pour configurer Windows IoT sur Raspberry. Elle n'a pas donné d'image sur le moniteur. Il n'a été possible de résoudre ce problème qu'en entrant les lignes suivantes dans config.txt:hdmi_ignore_edid=0xa5000080hdmi_drive=2hdmi_group=2hdmi_mode=16Cela a réglé le pilote vidéo sur le format, la résolution et la fréquence souhaités. Cependant, le temps consacré à cette leçon a clairement montré que vous pourriez ne pas avoir le temps d'organiser la réception des données de l'accéléromètre. Par conséquent, il a été décidé d'utiliser le capteur que j'avais pris en réserve.De nombreuses applications ont déjà été écrites pour le capteur. L'un d'eux a affiché à l'écran un graphique des données «brutes»:
Cependant, le temps consacré à cette leçon a clairement montré que vous pourriez ne pas avoir le temps d'organiser la réception des données de l'accéléromètre. Par conséquent, il a été décidé d'utiliser le capteur que j'avais pris en réserve.De nombreuses applications ont déjà été écrites pour le capteur. L'un d'eux a affiché à l'écran un graphique des données «brutes»: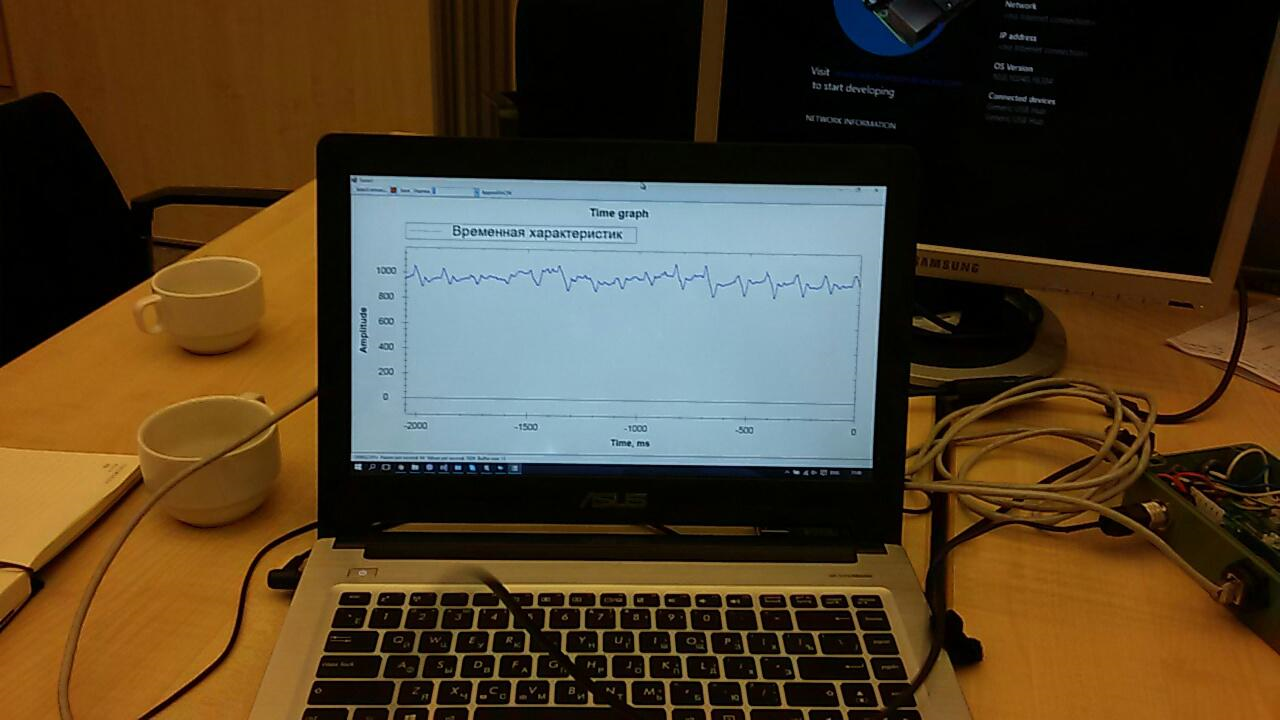 Il a fallu le compléter un peu afin de préparer les données pour l'envoi vers le cloud.Event Hub n'a pas non plus fonctionné tout de suite. Pour commencer, nous avons essayé d'y envoyer juste une séquence aléatoire. Mais les données ne voulaient pas apparaître dans les rapports. Il y avait plusieurs problèmes et, en fin de compte, ils étaient tous «puérils»: quelque part ils l'ont mal configuré, quelque part ils ont utilisé la mauvaise clé, etc. Travailler dans cette direction a été difficile et a pris beaucoup d'énergie:
Il a fallu le compléter un peu afin de préparer les données pour l'envoi vers le cloud.Event Hub n'a pas non plus fonctionné tout de suite. Pour commencer, nous avons essayé d'y envoyer juste une séquence aléatoire. Mais les données ne voulaient pas apparaître dans les rapports. Il y avait plusieurs problèmes et, en fin de compte, ils étaient tous «puérils»: quelque part ils l'ont mal configuré, quelque part ils ont utilisé la mauvaise clé, etc. Travailler dans cette direction a été difficile et a pris beaucoup d'énergie: Mais, le soir du premier jour, nous avons pu envoyer et recevoir des données du capteur à la volée ... Vrai, ce n'était pas nécessaire dans la solution finale. Je parlerai des raisons un peu plus tard.Avec le Machine Learning, rien n'était clair du tout. Au début, nous avons étudié ensemble la bellearticle avec un exemple d'utilisation d'une application mobile en tant que client. Ensuite, nous avons déterminé le format des données et comment travailler avec elles. Ensuite, ils ont pensé comment créer des séquences d'entraînement.Azure Mashine Learning possède de nombreux algorithmes pour diverses classifications. Ces algorithmes doivent être formés sur un ensemble de données de test. Ensuite, ceux qui donnent le meilleur résultat peuvent être publiés en tant que service Web et connectés à eux depuis l'application.L'apprentissage d'un algorithme est appelé une «expérience». Toutes les actions sont effectuées dans un éditeur visuel:
Mais, le soir du premier jour, nous avons pu envoyer et recevoir des données du capteur à la volée ... Vrai, ce n'était pas nécessaire dans la solution finale. Je parlerai des raisons un peu plus tard.Avec le Machine Learning, rien n'était clair du tout. Au début, nous avons étudié ensemble la bellearticle avec un exemple d'utilisation d'une application mobile en tant que client. Ensuite, nous avons déterminé le format des données et comment travailler avec elles. Ensuite, ils ont pensé comment créer des séquences d'entraînement.Azure Mashine Learning possède de nombreux algorithmes pour diverses classifications. Ces algorithmes doivent être formés sur un ensemble de données de test. Ensuite, ceux qui donnent le meilleur résultat peuvent être publiés en tant que service Web et connectés à eux depuis l'application.L'apprentissage d'un algorithme est appelé une «expérience». Toutes les actions sont effectuées dans un éditeur visuel: glisser-déposer des éléments de la liste de gauche vous permet de recevoir des données, de les modifier et de les transformer, de former des modèles et d'évaluer leur travail.Voici à quoi ressemble une expérience typique:
glisser-déposer des éléments de la liste de gauche vous permet de recevoir des données, de les modifier et de les transformer, de former des modèles et d'évaluer leur travail.Voici à quoi ressemble une expérience typique: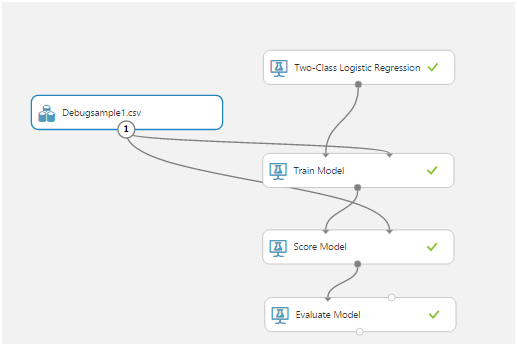 le modèle de train, le modèle de score et le modèle d'évaluation se sont avérés être les plus importants.Le premier, à l'aide des données d'entrée, entraîne l'algorithme, le second teste l'algorithme formé sur l'ensemble de données, le troisième évalue le résultat du test.Les données source dans notre cas sont un fichier csv. Mais que doit-il contenir?L'élément sensible de notre capteur est interrogé 1024 fois par seconde. Chaque levé est une valeur à deux octets correspondant à l'amplitude de l'oscillation actuelle. De plus, l'amplitude est mesurée non pas à partir de zéro, mais à partir du numéro de référence correspondant à un capteur fixe.Après réflexion, nous avons décidé d'utiliser des tranches temporaires. Par exemple, tous les sondages de capteurs pendant 256 ms nous ont donné une ligne dans le tableau csv. Ces données, dans une colonne supplémentaire, pourraient être marquées d'une manière ou d'une autre, selon ce qui se passe avec le capteur. Par exemple, nous avons utilisé 0 pour indiquer le bruit (secouer le capteur avec vos mains, taper, etc.) et 1 pour indiquer le signal (il y a un téléphone vibrant sur le capteur).Voici comment nous avons enregistré les séquences de test:
le modèle de train, le modèle de score et le modèle d'évaluation se sont avérés être les plus importants.Le premier, à l'aide des données d'entrée, entraîne l'algorithme, le second teste l'algorithme formé sur l'ensemble de données, le troisième évalue le résultat du test.Les données source dans notre cas sont un fichier csv. Mais que doit-il contenir?L'élément sensible de notre capteur est interrogé 1024 fois par seconde. Chaque levé est une valeur à deux octets correspondant à l'amplitude de l'oscillation actuelle. De plus, l'amplitude est mesurée non pas à partir de zéro, mais à partir du numéro de référence correspondant à un capteur fixe.Après réflexion, nous avons décidé d'utiliser des tranches temporaires. Par exemple, tous les sondages de capteurs pendant 256 ms nous ont donné une ligne dans le tableau csv. Ces données, dans une colonne supplémentaire, pourraient être marquées d'une manière ou d'une autre, selon ce qui se passe avec le capteur. Par exemple, nous avons utilisé 0 pour indiquer le bruit (secouer le capteur avec vos mains, taper, etc.) et 1 pour indiquer le signal (il y a un téléphone vibrant sur le capteur).Voici comment nous avons enregistré les séquences de test: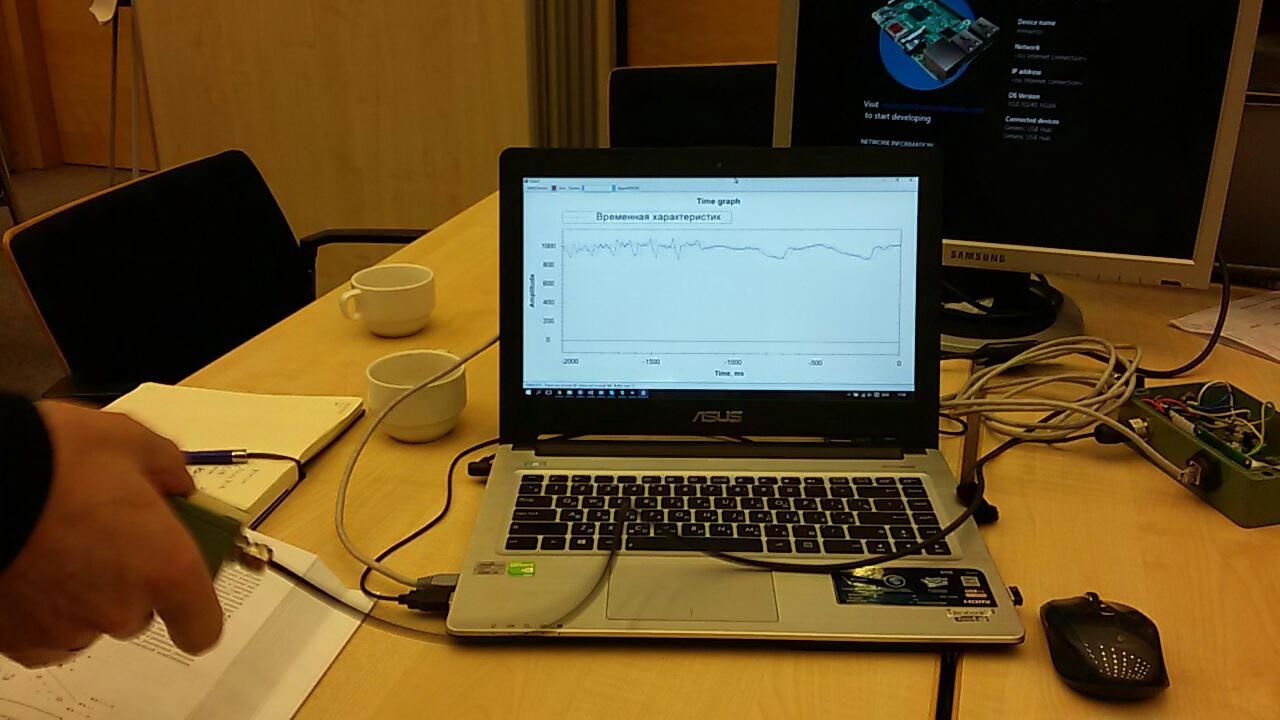 Après avoir reçu les données et réalisé ce qui doit être fait avec elles, nous avons commencé à apprendre le premier modèle:
Après avoir reçu les données et réalisé ce qui doit être fait avec elles, nous avons commencé à apprendre le premier modèle: La première crêpe s'est avérée grumeleuse:
La première crêpe s'est avérée grumeleuse: À l'époque, même la signification de ces indicateurs n'était pas claire. Nous avons été sauvés par un représentant de l'équipe d'assistance, Yevgeny Grigorenko, parlant des courbes ROC. L'essentiel était que si le graphique est en dessous de la ligne médiane à un certain endroit, alors le modèle fonctionne encore pire que s'il donnait un résultat aléatoire! Eugène a continué à nous aider autant qu'il le pouvait, merci beaucoup à lui!
À l'époque, même la signification de ces indicateurs n'était pas claire. Nous avons été sauvés par un représentant de l'équipe d'assistance, Yevgeny Grigorenko, parlant des courbes ROC. L'essentiel était que si le graphique est en dessous de la ligne médiane à un certain endroit, alors le modèle fonctionne encore pire que s'il donnait un résultat aléatoire! Eugène a continué à nous aider autant qu'il le pouvait, merci beaucoup à lui! Ensuite, nous avons réécrit la séquence d'entraînement pendant longtemps et regardé les résultats:
Ensuite, nous avons réécrit la séquence d'entraînement pendant longtemps et regardé les résultats: Il s'est avéré que travailler avec un enregistrement de 2 secondes (sondages de 2048 capteurs) était moins optimal. Cela nous a permis de rendre les lignes de table csv plus significatives. Mais le résultat était encore loin d'être bon.Cela s'est terminé le premier jour.J'ai passé la nuit à étudier le matériel. L' article a vraiment aidésur la classification binaire. J'ai également lu attentivement l' article avec des conseils pour ce hackathon. En général, au début du travail, j'étais plein d'idées nouvelles.Nous avons passé toute la première moitié de la deuxième journée à étudier différents modèles. Le résultat du travail a été une telle «feuille»: à
Il s'est avéré que travailler avec un enregistrement de 2 secondes (sondages de 2048 capteurs) était moins optimal. Cela nous a permis de rendre les lignes de table csv plus significatives. Mais le résultat était encore loin d'être bon.Cela s'est terminé le premier jour.J'ai passé la nuit à étudier le matériel. L' article a vraiment aidésur la classification binaire. J'ai également lu attentivement l' article avec des conseils pour ce hackathon. En général, au début du travail, j'étais plein d'idées nouvelles.Nous avons passé toute la première moitié de la deuxième journée à étudier différents modèles. Le résultat du travail a été une telle «feuille»: à ce moment-là, il était déjà clair que nous n'avions tout simplement pas le temps de faire la distinction entre deux anneaux de vibration, car la qualité des données d'entraînement laissait beaucoup à désirer et il n'y avait pas assez de temps pour en enregistrer de nouvelles. Par conséquent, nous nous sommes concentrés sur la séparation des données en «signal» et «bruit».Pour le travail, nous avons utilisé 3 ensembles de données:
ce moment-là, il était déjà clair que nous n'avions tout simplement pas le temps de faire la distinction entre deux anneaux de vibration, car la qualité des données d'entraînement laissait beaucoup à désirer et il n'y avait pas assez de temps pour en enregistrer de nouvelles. Par conséquent, nous nous sommes concentrés sur la séparation des données en «signal» et «bruit».Pour le travail, nous avons utilisé 3 ensembles de données:- Un ensemble d'entraînement dans lequel il y avait un signal (lignes du fichier csv marquées 1) et du bruit (lignes marquées 0)
- Un ensemble contenant uniquement du bruit (lignes à partir de 0)
- Un ensemble contenant uniquement le signal (lignes à partir de 1)
Les modèles ont d'abord été formés, puis testés et évalués sur chacun des ensembles de données. Les résultats ont été encourageants: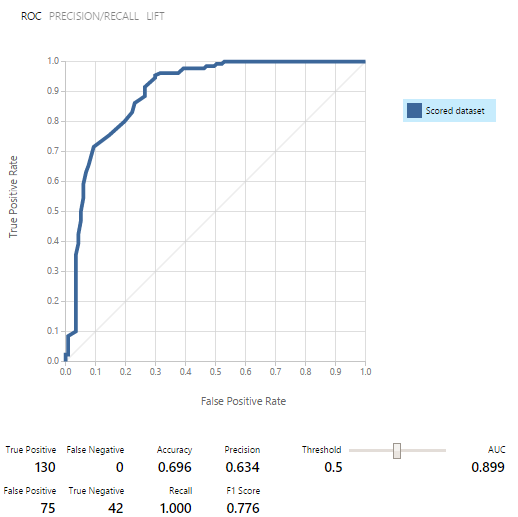 En conséquence, sur neuf modèles de classification binaire, nous en avons sélectionné cinq.Il s'est avéré qu'il est beaucoup plus facile d'utiliser le modèle en tant que service Web que de le visser au concentrateur d'événements. Par conséquent, nous avons décidé de publier les 5 modèles et de travailler avec eux via DEMANDE / RÉPONSE, qui est accompagné d'un très bon exemple.
En conséquence, sur neuf modèles de classification binaire, nous en avons sélectionné cinq.Il s'est avéré qu'il est beaucoup plus facile d'utiliser le modèle en tant que service Web que de le visser au concentrateur d'événements. Par conséquent, nous avons décidé de publier les 5 modèles et de travailler avec eux via DEMANDE / RÉPONSE, qui est accompagné d'un très bon exemple. La demande est un tableau d'entrée de 2048 valeurs prises par le capteur. La réponse ressemble à ceci:
La demande est un tableau d'entrée de 2048 valeurs prises par le capteur. La réponse ressemble à ceci: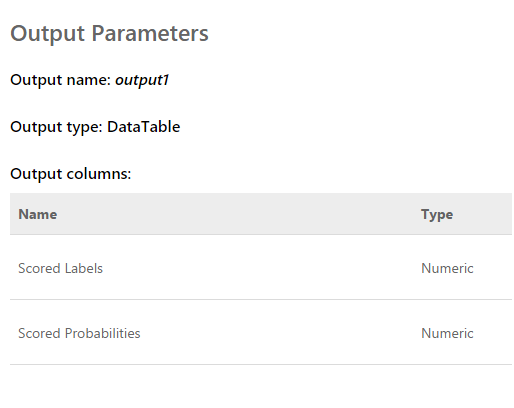 Les étiquettes notées sont 0 ou 1. C'est-à-dire le résultat de la classification. Probabilités notées - un nombre décimal qui reflète l'exactitude de l'évaluation. Si je comprends bien, la première valeur arrondit la seconde. C'est-à-dire que plus la seconde valeur est proche de 0, plus le score 0 est probable, et vice versa. Plus la valeur est proche de 1, le score 1 est plus probable.Après avoir finalisé le programme qui affiche le graphique des «données brutes» à l'écran, nous avons pu recevoir simultanément les données des cinq services Web de plusieurs flux. De plus, après avoir un peu observé les estimations, nous en avons exclu une, car elle a donné un résultat complètement différent des autres et a gâché le tableau d'ensemble.Le résultat est le suivant:
Les étiquettes notées sont 0 ou 1. C'est-à-dire le résultat de la classification. Probabilités notées - un nombre décimal qui reflète l'exactitude de l'évaluation. Si je comprends bien, la première valeur arrondit la seconde. C'est-à-dire que plus la seconde valeur est proche de 0, plus le score 0 est probable, et vice versa. Plus la valeur est proche de 1, le score 1 est plus probable.Après avoir finalisé le programme qui affiche le graphique des «données brutes» à l'écran, nous avons pu recevoir simultanément les données des cinq services Web de plusieurs flux. De plus, après avoir un peu observé les estimations, nous en avons exclu une, car elle a donné un résultat complètement différent des autres et a gâché le tableau d'ensemble.Le résultat est le suivant: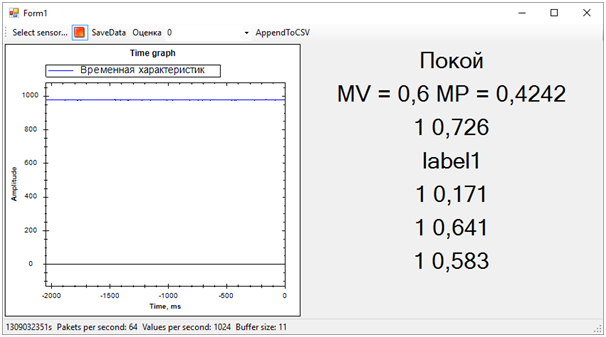
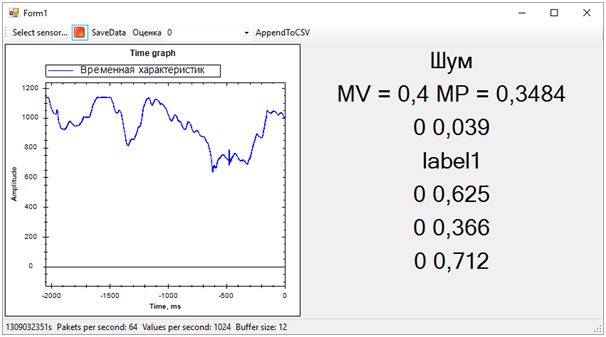
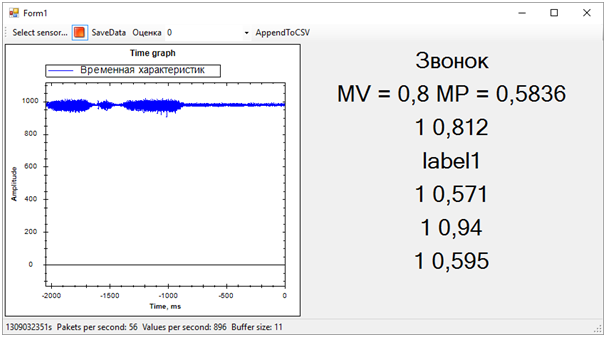 Ensuite, tous les problèmes de la séquence d'entraînement ont immédiatement disparu. Bien que nous ayons essayé de séparer l'alerte vibratoire de tout le reste (bruit et repos), l'état de repos s'est avéré être très proche de l'appel, ce qui était loin d'être toujours déterminé. La différence entre l'appel et le reste, nous avons déterminé par le nombre moyen de probabilités pour chaque modèle. Une valeur plus proche de 1 signifie un appel, une valeur d'environ 0,5 avec un score de 1 est la paix. Eh bien, si le score est 0 - c'est définitivement du bruit.A cette époque, le hackathon a pris fin. Nous n'avons même pas eu le temps de montrer les résultats aux experts, car ils étaient occupés à évaluer les entrées.Mais tout cela n'avait plus d'importance particulière. Plus important encore, nous avons atteint un résultat complètement sain et en même temps, nous avons beaucoup appris!En deux jours de dur labeur, nous avons terminé, bien que partiellement, la tâche. Merci aux collègues de l'équipe et aux experts qui nous ont aidés!Nous pouvons maintenant noter les voies de développement de notre projet. Nous avons utilisé des caractéristiques temporelles pour séparer les événements. Cependant, si nous passons au domaine fréquentiel, l'efficacité des algorithmes devrait être plus élevée. Le bruit, la paix et la cloche ont des caractéristiques spectrales sensiblement différentes.De plus, des personnes expérimentées ont suggéré que les données soient normalisées. Autrement dit, les numéros de la séquence d'entrée doivent se situer dans la plage de -1 à +1. Les algorithmes fonctionnent plus efficacement avec ces données.Et bien, il faut travailler sur la formation de séquences d'entraînement afin de séparer plus clairement le signal du bruit.Ces améliorations devraient augmenter considérablement la précision de la détermination de l'état, que je souhaite vérifier à l'avenir.
Ensuite, tous les problèmes de la séquence d'entraînement ont immédiatement disparu. Bien que nous ayons essayé de séparer l'alerte vibratoire de tout le reste (bruit et repos), l'état de repos s'est avéré être très proche de l'appel, ce qui était loin d'être toujours déterminé. La différence entre l'appel et le reste, nous avons déterminé par le nombre moyen de probabilités pour chaque modèle. Une valeur plus proche de 1 signifie un appel, une valeur d'environ 0,5 avec un score de 1 est la paix. Eh bien, si le score est 0 - c'est définitivement du bruit.A cette époque, le hackathon a pris fin. Nous n'avons même pas eu le temps de montrer les résultats aux experts, car ils étaient occupés à évaluer les entrées.Mais tout cela n'avait plus d'importance particulière. Plus important encore, nous avons atteint un résultat complètement sain et en même temps, nous avons beaucoup appris!En deux jours de dur labeur, nous avons terminé, bien que partiellement, la tâche. Merci aux collègues de l'équipe et aux experts qui nous ont aidés!Nous pouvons maintenant noter les voies de développement de notre projet. Nous avons utilisé des caractéristiques temporelles pour séparer les événements. Cependant, si nous passons au domaine fréquentiel, l'efficacité des algorithmes devrait être plus élevée. Le bruit, la paix et la cloche ont des caractéristiques spectrales sensiblement différentes.De plus, des personnes expérimentées ont suggéré que les données soient normalisées. Autrement dit, les numéros de la séquence d'entrée doivent se situer dans la plage de -1 à +1. Les algorithmes fonctionnent plus efficacement avec ces données.Et bien, il faut travailler sur la formation de séquences d'entraînement afin de séparer plus clairement le signal du bruit.Ces améliorations devraient augmenter considérablement la précision de la détermination de l'état, que je souhaite vérifier à l'avenir.Source: https://habr.com/ru/post/fr387857/
All Articles