Une autre étape dans l'auto-apprentissage de la machine
 Bien sûr, il existe de nombreux modèles d'auto-apprentissage en Data Science, mais le sont-ils vraiment? En fait, non: maintenant dans l'apprentissage automatique, il y a une situation où le facteur humain joue un rôle décisif dans la construction de modèles efficaces.La science des données est maintenant une sorte de fusion de la science et de l'intuition, car il n'y a aucune connaissance formalisée sur la façon de prédire correctement les prédicteurs, le modèle à choisir parmi des dizaines de prédicteurs existants et comment configurer de nombreux paramètres dans ce modèle. Tout cela est difficile à formaliser, et donc une situation paradoxale se présente - l' apprentissage automatique nécessite un facteur humain .C'est la personne qui a besoin de construire la chaîne d'apprentissage et d'ajuster les paramètres qui peuvent facilement transformer le meilleur modèle en absolument inutile. La construction de cette chaîne, qui transforme les données initiales en un modèle prédictif, peut prendre plusieurs semaines, selon la complexité de la tâche, et se fait souvent simplement par essais et erreurs.Il s'agit d'un grave défaut, et donc l'idée est née: l'apprentissage automatique peut-il s'éduquer de la même manière qu'une personne? Un tel système a été créé, et il est surprenant que cette nouvelle n'ait pas encore atteint la habrasociety!
Bien sûr, il existe de nombreux modèles d'auto-apprentissage en Data Science, mais le sont-ils vraiment? En fait, non: maintenant dans l'apprentissage automatique, il y a une situation où le facteur humain joue un rôle décisif dans la construction de modèles efficaces.La science des données est maintenant une sorte de fusion de la science et de l'intuition, car il n'y a aucune connaissance formalisée sur la façon de prédire correctement les prédicteurs, le modèle à choisir parmi des dizaines de prédicteurs existants et comment configurer de nombreux paramètres dans ce modèle. Tout cela est difficile à formaliser, et donc une situation paradoxale se présente - l' apprentissage automatique nécessite un facteur humain .C'est la personne qui a besoin de construire la chaîne d'apprentissage et d'ajuster les paramètres qui peuvent facilement transformer le meilleur modèle en absolument inutile. La construction de cette chaîne, qui transforme les données initiales en un modèle prédictif, peut prendre plusieurs semaines, selon la complexité de la tâche, et se fait souvent simplement par essais et erreurs.Il s'agit d'un grave défaut, et donc l'idée est née: l'apprentissage automatique peut-il s'éduquer de la même manière qu'une personne? Un tel système a été créé, et il est surprenant que cette nouvelle n'ait pas encore atteint la habrasociety!TROT (Tree-based Pipeline Optimization Tool)
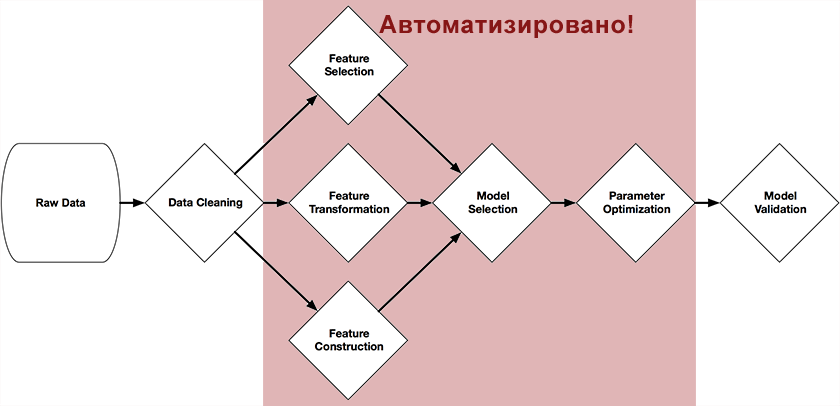
Randy Olson, étudiant diplômé au Computational Genetics Lab (Université de Pennsylvanie), a développé un outil d'optimisation des pipelines basé sur les arbres dans le cadre de son projet de graduation .Ce système se positionne comme un assistant Data Science. Il automatise la partie la plus fastidieuse de l'apprentissage automatique, en étudiant et en choisissant parmi les milliers de chaînes de construction possibles exactement celle qui convient le mieux au traitement de vos données.Le système a été écrit en Python en utilisant la bibliothèque scikit-learn et, grâce à des algorithmes génétiques, construit indépendamment une chaîne complète de préparation et de construction de modèles. La figure au début de cet article présente les parties de la chaîne qui peuvent être automatisées avec son aide: prétraitement et sélection des prédicteurs, sélection des modèles, optimisation de leurs paramètres.L'idée est assez simple - un algorithme génétique .Il s'agit d'un algorithme pour trouver la chaîne dont nous avons besoin par sélection aléatoire, en utilisant des mécanismes similaires à la sélection naturelle dans la nature. Ils sont écrits avec suffisamment de détails à leur sujet sur Wikipédia , sur le Habr , ou dans le livre "Systèmes d'auto-apprentissage"(Je recommande aux personnes intéressées par ce sujet, il existe un réseau sous forme électronique).En fonction de la sélection (fonction Fitness), la précision de la prédiction dans l'ensemble de test est utilisée, en tant qu'objet de la population sont les méthodes scikit et leurs paramètres.Les résultats
L'auteur présente un exemple simple de la façon d'utiliser TPOT pour résoudre le problème de référence pour la classification des chiffres manuscrits de l'ensemble MNISTfrom tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
Lorsque vous exécutez le code, après quelques minutes, TPOT peut obtenir la chaîne de création de modèle, dont la précision atteint 98%. Cela se produit lorsque TPOT découvre que le classificateur Random Forest fonctionne parfaitement sur les données MNIST.Certes, puisque ce processus est probabiliste, il est recommandé de définir le paramètre random_state pour des résultats reproductibles - par exemple, pour 5 générations, je n'ai trouvé qu'une chaîne avec SVC et KNeighborsClassifier.Le test du système sur un autre problème classique, les iris de Fisher , a donné une précision de 97% sur 10 générations.Le futur
Trot est un projet open source né il y a un mois (qui est généralement l'âge d'un enfant pour de tels systèmes) et se développe activement. Sur le site Web du projet, l'auteur encourage la communauté des Data Scientists à se joindre au développement d'un système dont le code est disponible sur github (https://github.com/rhiever/tpot)Bien sûr, maintenant le système est très loin d'être idéal, mais l'idée de ce système semble extrêmement logique - automatisation complète l'ensemble du processus d'apprentissage automatique. Et si l'idée se développe, alors peut-être que des systèmes apparaîtront bientôt où une personne ne doit télécharger des données et obtenir un résultat. Et puis une autre question se posera: faut -il une personne pour construire des modèles d'auto-apprentissage?