Défi:
séparer les séquences d'événements souvent répétées en une chaîne distincte dans laquelle il n'y aura rien de superflu.Cette tâche a de nombreuses solutions. Souvent utilisé "cuisson" - ces relations qui sont souvent utilisées sont fixes, tandis que d'autres sont affaiblies. En finale, vous devriez obtenir une chaîne dans laquelle les événements les plus répétés ont des liens étroits. Cette solution présente de nombreuses lacunes, parmi lesquelles - la faible vitesse. Mais nous avons des ondes d'identification de Redozubov, nous pouvons utiliser d'autres algorithmes qui peuvent former une nouvelle chaîne après la première répétition. Commençons par un simple.Dans la dernière noteUne méthode pour enregistrer tous les événements dans une chaîne de mémoire est décrite. Laissez le système lire une fois le mot "décroissance", et à un autre moment - le mot "cascade". Ces deux mots ont la même partie - la fin de trois lettres. Selon les conditions du problème, il est nécessaire de mettre en évidence la chaîne "pad". Cette chaîne n'a pas de conditions préalables, c'est-à-dire qu'elle reconnaît facilement l'entrée correspondante.Une solution
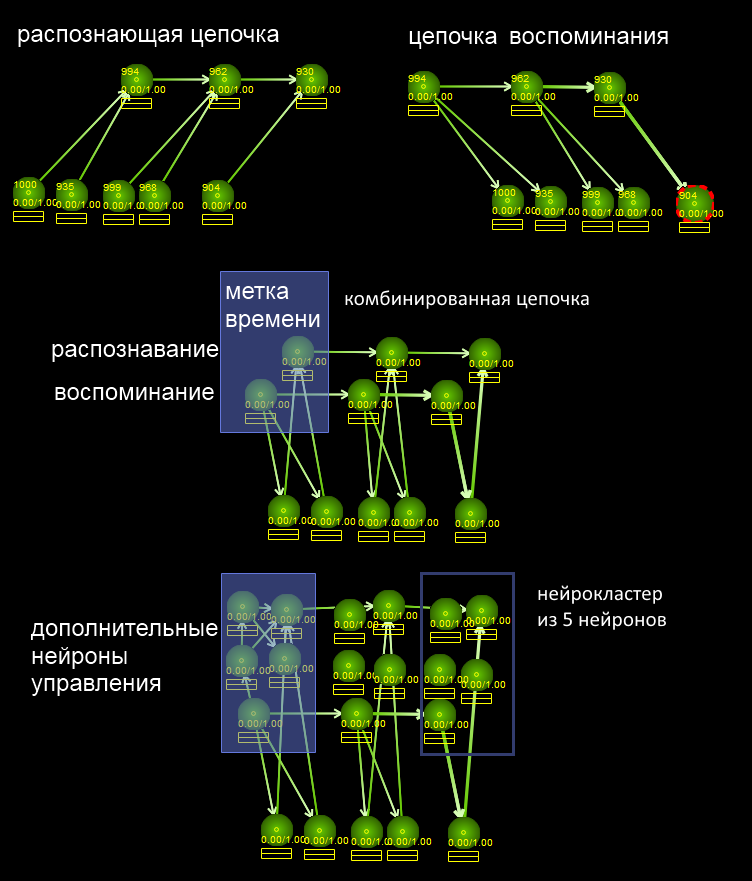 Nous divisons la tâche en deux:1) trouver deux séries d'événements similaires (vous devez comprendre qu'environ ces deux mots contiennent des séquences similaires)2) les sélectionner dans une chaîne distincte («pad»)Commençons par la partie 2. Nous compliquons le neurocluster avec des horodatages, qui stockent tous les événements dans la chaîne de mémoire, comme indiqué dans l'image. Grâce à la partie reconnaissante (la direction des connexions vers le haut depuis les attributs vers l'horodatage généralisant), la sous-tâche 1 sera résolue - pour trouver une position avec des attributs communs, et grâce à la chaîne de mémoire avec des liens vers le bas, la sous-tâche 2 sera résolue. La solution à la sous-tâche 2 est la suivante: nous allons commencer à rappeler deux mots en même temps où ils ont en commun. Autrement dit, le système enverra l'activation par des neurones qui correspondent à ces lettres. Si la lettre se trouve dans les deux mots, il faut s'en souvenir. Pour ce faire, laissez la mémoire se produire avec la moitié de la force. Si le seuil d'activation du neurone est T, alors la chaîne de mémoire doit envoyer 0,5 T du potentiel d'action. Le seuil d'activation ne sera alors dépassé que silorsque le symptôme s'est rencontré dans les deux chaînes. Après cela, le symptôme devient activé. Ensuite, vous pouvez utiliser l'algorithme de mémorisation habituel avec le code de l'article précédent - l'hippocampe va créer une chaîne de mémoire, en lui affectant les signes communs aux deux chaînes. Nous avons réduit la solution à la précédente.En ENS (NS naturel), la «demi-activation» peut être obtenue en variant le temps d'envoi (le nombre de pointes qui sont arrivées), le nombre de neurotransmetteurs, ou peut-être en utilisant des connexions inhibitrices (pour transformer 1T en 0,5T).La sous-tâche 1 est un peu plus compliquée, car elle devrait fonctionner avec une reconnaissance floue. Autrement dit, même s'il n'y a que quelques signes communs dans la chaîne qui sont perdus quelque part au milieu de la chaîne, vous devriez toujours remarquer cette situation. Permettez-moi de vous rappeler que, relativement parlant, les neurones peuvent être dans trois modes - repos, envoi d'un signal unique et mode d'activation à haute fréquence. On peut admettre que la «reconnaissance complète» conduit à la transition du neurone en mode d'activation haute fréquence, et la reconnaissance floue conduit à une transmission de signal unique. Ou nous pouvons supposer qu'il y aura des neurones spécialisés dans le neurocluster, dont certains ne fonctionneront qu'avec une coïncidence complète et une reconnaissance sûre, et l'autre neurone fonctionnera si seulement une partie des caractéristiques est reconnue. Il existe de nombreuses solutions, l'essentiel est de remarquer en quelque sorte l'apparition d'une activation sur les clusters souhaités.
Nous divisons la tâche en deux:1) trouver deux séries d'événements similaires (vous devez comprendre qu'environ ces deux mots contiennent des séquences similaires)2) les sélectionner dans une chaîne distincte («pad»)Commençons par la partie 2. Nous compliquons le neurocluster avec des horodatages, qui stockent tous les événements dans la chaîne de mémoire, comme indiqué dans l'image. Grâce à la partie reconnaissante (la direction des connexions vers le haut depuis les attributs vers l'horodatage généralisant), la sous-tâche 1 sera résolue - pour trouver une position avec des attributs communs, et grâce à la chaîne de mémoire avec des liens vers le bas, la sous-tâche 2 sera résolue. La solution à la sous-tâche 2 est la suivante: nous allons commencer à rappeler deux mots en même temps où ils ont en commun. Autrement dit, le système enverra l'activation par des neurones qui correspondent à ces lettres. Si la lettre se trouve dans les deux mots, il faut s'en souvenir. Pour ce faire, laissez la mémoire se produire avec la moitié de la force. Si le seuil d'activation du neurone est T, alors la chaîne de mémoire doit envoyer 0,5 T du potentiel d'action. Le seuil d'activation ne sera alors dépassé que silorsque le symptôme s'est rencontré dans les deux chaînes. Après cela, le symptôme devient activé. Ensuite, vous pouvez utiliser l'algorithme de mémorisation habituel avec le code de l'article précédent - l'hippocampe va créer une chaîne de mémoire, en lui affectant les signes communs aux deux chaînes. Nous avons réduit la solution à la précédente.En ENS (NS naturel), la «demi-activation» peut être obtenue en variant le temps d'envoi (le nombre de pointes qui sont arrivées), le nombre de neurotransmetteurs, ou peut-être en utilisant des connexions inhibitrices (pour transformer 1T en 0,5T).La sous-tâche 1 est un peu plus compliquée, car elle devrait fonctionner avec une reconnaissance floue. Autrement dit, même s'il n'y a que quelques signes communs dans la chaîne qui sont perdus quelque part au milieu de la chaîne, vous devriez toujours remarquer cette situation. Permettez-moi de vous rappeler que, relativement parlant, les neurones peuvent être dans trois modes - repos, envoi d'un signal unique et mode d'activation à haute fréquence. On peut admettre que la «reconnaissance complète» conduit à la transition du neurone en mode d'activation haute fréquence, et la reconnaissance floue conduit à une transmission de signal unique. Ou nous pouvons supposer qu'il y aura des neurones spécialisés dans le neurocluster, dont certains ne fonctionneront qu'avec une coïncidence complète et une reconnaissance sûre, et l'autre neurone fonctionnera si seulement une partie des caractéristiques est reconnue. Il existe de nombreuses solutions, l'essentiel est de remarquer en quelque sorte l'apparition d'une activation sur les clusters souhaités.Quand le faire
la question est de savoir à quelle heure effectuer une telle recherche. Il peut y avoir plusieurs approches:1) un mode de sommeil spécialisé - plus précisément, un «sommeil lent». Le système passe en revue tous les événements qu'il a appris en une journée et recherche des correspondances avec ses autres souvenirs. Dans ce cas, le système utilise la mémoire - envoi dans une chaîne descendante, puis laisse le temps aux neurones des signes d'envoyer des signaux déjà «vers le haut» vers d'autres mémoires. Après quoi, il résume et recherche les souvenirs qui ont la plus grande quantité d'activation totale. Puis il sélectionne l'un de ces endroits et lance la sous-tâche 2 - «sélectionner la chaîne».2) sans régime de sommeil spécialisé. Le système peut effectuer une recherche à la volée, pendant la perception - et à quoi ressemble la situation actuelle? En fait, la recherche se produit automatiquement pendant la réflexion normale en raison de l'envoi de signaux par les neurones, le système ne peut que prêter attention aux mémoires qui ont beaucoup en commun avec la situation actuelle et, si nécessaire, exécuter l'analyse - mettre en évidence la sous-chaîne générale.Algorithmes similaires
Ces algorithmes semblent simples, mais ils contiennent beaucoup de subtilités, encore plus que dans l'algorithme de tri rapide, qui, comme vous le savez, ne pourrait pas être écrit pendant longtemps sans erreurs.Cette tâche est similaire aux tâches connues, par exemple, la recherche de sous-séquences d'ADN courantes. Seul l'ADN à chaque étape ne peut avoir qu'un seul nucléotide, et dans le réseau neuronal pour chaque horodatage, il peut y avoir un nombre arbitraire de caractères. Par conséquent, cette tâche est un cas plus général que la recherche d'ADN. Si vous essayez de transférer des algorithmes existants et de résoudre un tel problème de «faille», sans réseaux de neurones, en manipulant les listes de signes, alors votre tête commence à tourner - toutes ces listes de correspondances imbriquées, listes de séquences de correspondances, autres questions. Résoudre ce problème en envoyant des activations aux neurones est beaucoup plus simple - les neurones existent déjà, ils font tout automatiquement, leur mémoire est déjà allouée, aucune liste imbriquée n'est nécessaire, il ne reste plus qu'à analyser certains neurones et exécuter les algorithmes nécessaires.J'appelle les sous-tâches 1 et 2 modes avec une et deux chaînes principales, respectivement. C'est-à-dire "combien de neurones descendants actifs dans les chaînes de mémoire envoient des signaux pour mettre en évidence les correspondances". S'il n'y a qu'une seule chaîne rappelée, alors elle recherche un deuxième candidat pour vérification. Et si le candidat a déjà été trouvé, vous pouvez l'activer et commencer à mettre en évidence les signes. De tels noms - «1 ou 2 chaînes de tête» - permettront de faire référence à ces algorithmes par leur nom, plutôt que «sous-tâche 1 ou 2». Le mode avec une chaîne de tête peut également être appelé «mode de recherche de coïncidence», et les 2 chaînes de tête peuvent être appelées le mode de mise en évidence de coïncidence.Rechercher des correspondances ...
(1, 1 chaîne de tête) peut être effectuée de la manière suivante:1) visualiser linéairement tous les souvenirs qui se sont rencontrés au cours de la journée. La transition vers ce mode à des fins de débogage peut être effectuée comme suit: un caractère Unicode spécial ou un mot spécial est inséré dans les ensembles de test des données d'entrée pour l'ANN; à la lecture, l'ANN passera en mode «sommeil lent» et commencera à rechercher des correspondances. Le sens est le suivant: ils ont rempli l'ANN de données réelles, ont commencé à déboguer des algorithmes pour rechercher des généralisations.2) de ne pas utiliser une recherche linéaire, mais de commencer l'analyse avec les situations les plus intéressantes - avec celles qui ont la plus grande couleur émotionnelle. Cette optimisation est nécessaire, car ces algorithmes sont très voraces. Chez le rat, il semble que le souvenir de ce qui était le jour ne se produit que 10 fois plus rapidement que pendant la journée. Le sommeil prend moins de temps que l'éveil. Ainsi, avec une distribution uniforme du temps à travers toutes les mémoires, chaque mémoire peut être gérée pour comparer seulement quelques situations similaires, dont la plupart seront des ordures et des coïncidences insignifiantes. Par conséquent, il est avantageux de se concentrer sur les plus importants et de commencer à travailler avec. Nous pouvons dire que l'algorithme ajoute une étape de plus - 0 chaînes de tête, à cette étape, le système doit sélectionner l'événement suivant en mémoire avec une importance maximale,et passez à l'étape suivante - faites-en la chaîne principale pour trouver des correspondances.3) il est possible de faire des empattements à partir du moment de l'éveil - à l'avance pour créer des connexions avec les endroits les plus intéressants qui devront être comparés la nuit.Les chaînes sélectionnées avec des coïncidences sont mémorisées, mais à l'avenir, elles peuvent être oubliées si leur importance s'estompe avec le temps.Oublier
L'oubli entraîne la suppression du neurocluster - l'opération removeNC, l'inverse de l'opération newNC. Dans l'ENS, les neurones n'iront nulle part, ils ne mourront pas, leurs connexions s'affaibliront à tel point qu'ils ne réagiront plus à leurs signes et seront prêts à se réajuster pour se souvenir d'une autre combinaison. Dans notre modèle, ces neurones n'ont pas besoin d'être stockés, ils peuvent être supprimés immédiatement - cela accélérera le fonctionnement de l'ANN, réduira la consommation de mémoire et simplifiera le débogage. Cela vous permet peut-être de réduire les exigences de consommation de mémoire d'un ordre de grandeur.Parallélisation
Afin de faire la transition du mode 1 au mode 2, j'ai d'abord essayé de créer des neurones de contrôle qui produisaient une commutation de signal, une analyse et un changement de mode. Mais j'ai trouvé ce travail trop bas et j'ai commencé à écrire du code C ++ impératif - du code tel que «parcourir tous les clusters, les analyser, sélectionner celui dont vous avez besoin, penser à changer de mode de fonctionnement».: , ( ). ( , ), ++ . ++, . , « » « » ++ — O(1), . , 1 2 ( ) .
Poursuite: prévisions primitives en ANN