AlphaGo a-t-il une chance dans le match contre Lee Sedol: avis et notes des joueurs professionnels en e
Le go-pro 9e match de Google et l'IA de Google auront lieu en mars
 Aucun ordinateur n'est capable de battre un joueur professionnel dans le jeu de plateau asiatique. Le problème réside dans les caractéristiques du jeu: il y a trop de positions et il est difficile de décrire l'algorithme humain intuitivement. Le monde avait des vues similaires jusqu'au 27 janvier. Il y a quelques jours, Google a publié des données de recherche de sa division DeepMind . Il parle du système AlphaGo, qui, en octobre de l'année dernière, a pu battre le deuxième joueur professionnel Dan Fan en 5 matchs sur cinq.Néanmoins, les joueurs professionnels et les connaissances de départ avaient des questions sur la qualité du jeu. Hui est triple champion, mais il est champion d'Europe, où le niveau de jeu n'est pas trop élevé. Ce n'est pas seulement le choix du joueur de démontrer la puissance d'AlphaGo qui soulève des questions, mais aussi certains mouvements dans les jeux.
Aucun ordinateur n'est capable de battre un joueur professionnel dans le jeu de plateau asiatique. Le problème réside dans les caractéristiques du jeu: il y a trop de positions et il est difficile de décrire l'algorithme humain intuitivement. Le monde avait des vues similaires jusqu'au 27 janvier. Il y a quelques jours, Google a publié des données de recherche de sa division DeepMind . Il parle du système AlphaGo, qui, en octobre de l'année dernière, a pu battre le deuxième joueur professionnel Dan Fan en 5 matchs sur cinq.Néanmoins, les joueurs professionnels et les connaissances de départ avaient des questions sur la qualité du jeu. Hui est triple champion, mais il est champion d'Europe, où le niveau de jeu n'est pas trop élevé. Ce n'est pas seulement le choix du joueur de démontrer la puissance d'AlphaGo qui soulève des questions, mais aussi certains mouvements dans les jeux.Algorithme
Guo a longtemps été considéré comme un jeu d'entraînement dans lequel l'intelligence artificielle est difficile en raison de l'énorme espace de recherche et de la complexité du choix des mouvements. Go appartient à la classe des jeux avec des informations parfaites, c'est-à-dire que les joueurs sont conscients de tous les mouvements que d'autres joueurs ont déjà effectués. La solution au problème de la recherche du résultat du jeu consiste à calculer la fonction de valeur optimale dans un arbre de recherche contenant environ b d mouvements possibles. Ici b est le nombre de coups corrects dans chaque position, et d est la durée de la partie. Pour les échecs, ces valeurs sont b ≈ 35 et d ≈ 80, et une recherche complète n'est pas possible. Par conséquent, les positions des figures sont évaluées, puis l'évaluation est prise en compte dans la recherche. En 1996, pour la première fois, un ordinateur a gagné aux échecs contre un champion et depuis 2005, aucun champion n'a pu battre un ordinateur.Pour go b ≈ 250, d ≈ 150. Les positions possibles des pierres sur une planche standard sont plus de googol (10 100 ) fois plus que dans les échecs. Le nombre de positions possibles est supérieur aux atomes de l'univers. Pour compliquer la situation, il est difficile de prédire la valeur des états en raison de la complexité du jeu. Deux joueurs placent des pierres de deux couleurs sur une planche d'une certaine taille, le champ standard est de 19 × 19 lignes. Les règles varient dans les détails, mais l'objectif principal du jeu est simple: vous devez délimiter une zone plus grande du plateau avec des pierres de votre couleur que votre adversaire.Les programmes existants peuvent jouer au niveau amateur. Ils utilisent la recherche dans l'arbre de Monte Carlo pour évaluer la valeur de chaque état dans l'arbre de recherche. Les programmes comprennent également des politiques qui prédisent les mouvements d'acteurs puissants.Récemment, les réseaux neuronaux convolutionnels profonds ont pu obtenir de bons résultats dans la reconnaissance faciale et la classification des images. Chez Google, l'IA a même appris à jouer seule à 49 anciens jeux Atari . Dans AlphaGo, des réseaux de neurones similaires interprètent la position des pierres sur la carte, ce qui permet d'évaluer et de sélectionner les mouvements. Chez Google, les chercheurs ont adopté l'approche suivante: ils ont utilisé des réseaux de valeur et des réseaux politiques. Ensuite, ces réseaux de neurones profonds sont formés à la fois sur un ensemble de groupes de personnes et sur un jeu contre leurs copies. Une recherche est également nouvelle, associant la méthode de Monte Carlo à des réseaux de politique et de valeur. Schéma et architecture de formation des réseaux de neurones.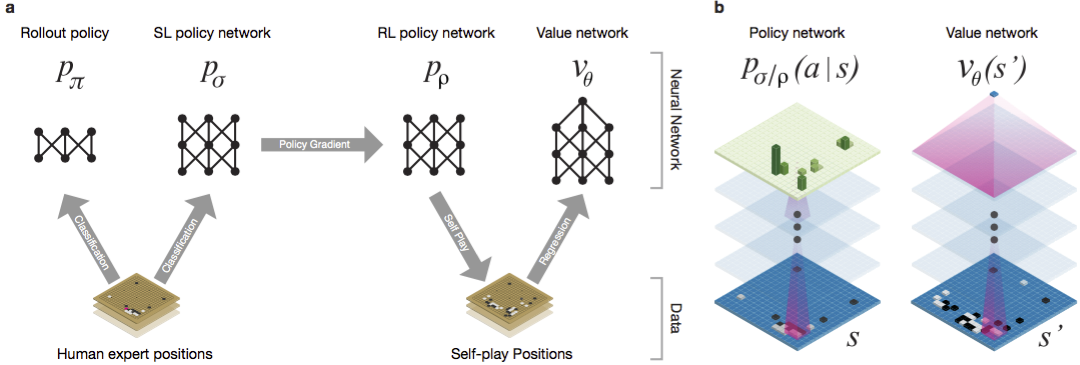 Les réseaux de neurones ont été formés à plusieurs étapes de l'apprentissage automatique. Dans un premier temps, une formation contrôlée du réseau politique a été réalisée directement en utilisant les mouvements des acteurs humains. Un autre réseau de politique a été renforcé l'apprentissage. Le second a joué avec le premier et l'a optimisé pour que la politique passe à une victoire, et pas seulement aux prédictions de mouvements. Enfin, une formation a été menée, renforcée par un réseau de valeur qui prédit le vainqueur des jeux joués par les réseaux politiques. Le résultat final est AlphaGo, une combinaison de la méthode de Monte Carlo et des réseaux de politique et de valeur. Le résultat d'une prédiction correcte du prochain mouvement a été obtenu dans 57% des cas. Avant AlphaGo, le meilleur résultat était de 44% .160 000 jeux avec 29,4 millions de positions du serveur KGS ont été utilisés comme entrée pour la formation. Nous avons pris la fête des joueurs du sixième au neuvième dan. Un million de postes ont été attribués aux tests et la formation elle-même a été dispensée pour 28,4 millions de postes. La force et la précision des politiques et des valeurs de réseautage.
Pour que les algorithmes fonctionnent, ils nécessitent une puissance de calcul supérieure de plusieurs ordres de grandeur par rapport à la recherche traditionnelle. AlphaGo est un programme multithread asynchrone qui effectue une simulation sur les cœurs du processeur central et exécute des réseaux de politiques et de valeurs sur des puces vidéo. La version finale ressemblait à une application à 40 threads fonctionnant sur 48 processeurs (cela signifiait probablement des cœurs séparés ou même de l'hyper-threading) et 8 accélérateurs graphiques. Une version distribuée d'AlphaGo a également été créée, qui utilise plusieurs machines, 40 flux de recherche, 1202 cœurs et 176 accélérateurs vidéo.
Les réseaux de neurones ont été formés à plusieurs étapes de l'apprentissage automatique. Dans un premier temps, une formation contrôlée du réseau politique a été réalisée directement en utilisant les mouvements des acteurs humains. Un autre réseau de politique a été renforcé l'apprentissage. Le second a joué avec le premier et l'a optimisé pour que la politique passe à une victoire, et pas seulement aux prédictions de mouvements. Enfin, une formation a été menée, renforcée par un réseau de valeur qui prédit le vainqueur des jeux joués par les réseaux politiques. Le résultat final est AlphaGo, une combinaison de la méthode de Monte Carlo et des réseaux de politique et de valeur. Le résultat d'une prédiction correcte du prochain mouvement a été obtenu dans 57% des cas. Avant AlphaGo, le meilleur résultat était de 44% .160 000 jeux avec 29,4 millions de positions du serveur KGS ont été utilisés comme entrée pour la formation. Nous avons pris la fête des joueurs du sixième au neuvième dan. Un million de postes ont été attribués aux tests et la formation elle-même a été dispensée pour 28,4 millions de postes. La force et la précision des politiques et des valeurs de réseautage.
Pour que les algorithmes fonctionnent, ils nécessitent une puissance de calcul supérieure de plusieurs ordres de grandeur par rapport à la recherche traditionnelle. AlphaGo est un programme multithread asynchrone qui effectue une simulation sur les cœurs du processeur central et exécute des réseaux de politiques et de valeurs sur des puces vidéo. La version finale ressemblait à une application à 40 threads fonctionnant sur 48 processeurs (cela signifiait probablement des cœurs séparés ou même de l'hyper-threading) et 8 accélérateurs graphiques. Une version distribuée d'AlphaGo a également été créée, qui utilise plusieurs machines, 40 flux de recherche, 1202 cœurs et 176 accélérateurs vidéo.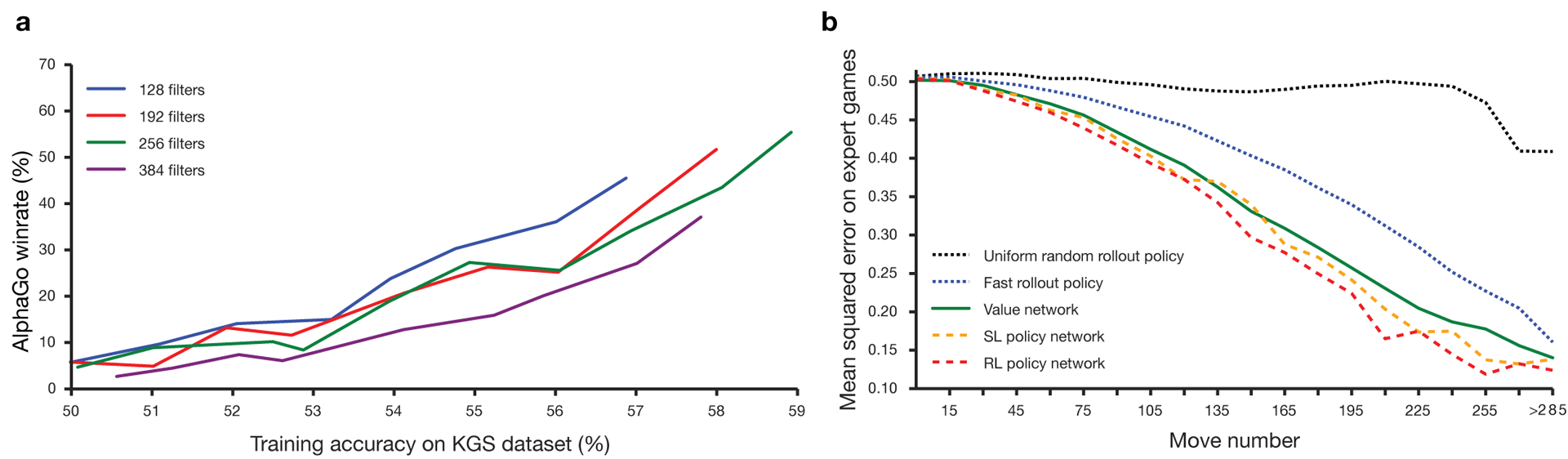 Le rapport DeepMind complet se trouve dans le document . Recherchez Monte Carlo dans AlphaGo.
Pour évaluer les capacités d'AlphaGo, des correspondances internes ont eu lieu avec d'autres versions du programme, ainsi qu'avec d'autres produits similaires. Y compris une comparaison a été menée avec des programmes commerciaux populaires tels que Crazy Stone et Zen, et les projets open source les plus solides Pachi et Fuego. Tous sont basés sur des algorithmes Monte Carlo hautes performances. Mais aussi AlphaGo par rapport à GnuGo non Monte Carlo. Les programmes ont reçu 5 secondes par coup. Une comparaison a été faite à la fois de l'AlphaGo fonctionnant sur une seule machine et de la version distribuée de l'algorithme.
Le rapport DeepMind complet se trouve dans le document . Recherchez Monte Carlo dans AlphaGo.
Pour évaluer les capacités d'AlphaGo, des correspondances internes ont eu lieu avec d'autres versions du programme, ainsi qu'avec d'autres produits similaires. Y compris une comparaison a été menée avec des programmes commerciaux populaires tels que Crazy Stone et Zen, et les projets open source les plus solides Pachi et Fuego. Tous sont basés sur des algorithmes Monte Carlo hautes performances. Mais aussi AlphaGo par rapport à GnuGo non Monte Carlo. Les programmes ont reçu 5 secondes par coup. Une comparaison a été faite à la fois de l'AlphaGo fonctionnant sur une seule machine et de la version distribuée de l'algorithme.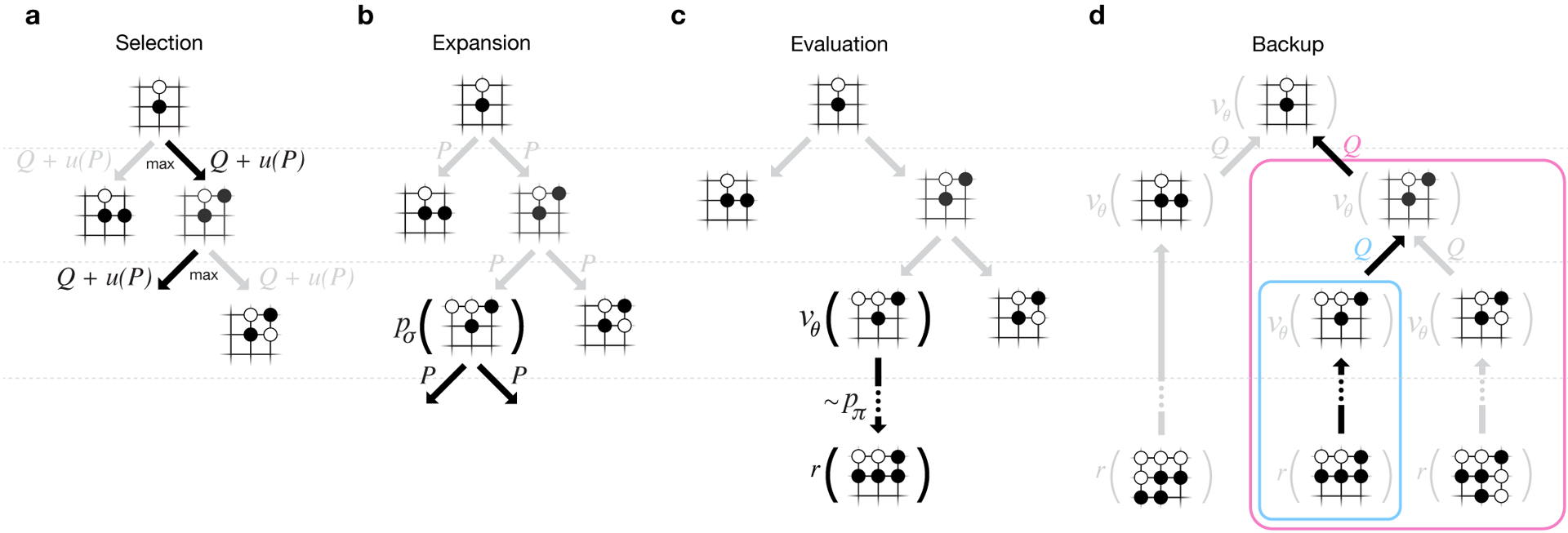 Selon les développeurs, les résultats ont montré qu'AlphaGo est beaucoup plus puissant que tous les programmes de go précédents. AlphaGo a remporté 494 des 495 matchs, soit 99,8% des matchs contre d'autres produits similaires. Les règles de go permettent un handicap , handicap: jusqu'à 9 pierres noires peuvent être posées sur le terrain avant les mouvements blancs. Mais même avec 4 pierres de handicap, la machine unique AlphaGo a remporté 77%, 86% et 99% du temps contre Crazy Stone, Zen et Pachi, respectivement. La version distribuée d'AlphaGo était nettement plus forte: dans 77% des jeux, elle battait la version mono-machine et dans 100% des jeux - tous les autres programmes. AlphaGo vs d'autres programmes.
Selon les développeurs, les résultats ont montré qu'AlphaGo est beaucoup plus puissant que tous les programmes de go précédents. AlphaGo a remporté 494 des 495 matchs, soit 99,8% des matchs contre d'autres produits similaires. Les règles de go permettent un handicap , handicap: jusqu'à 9 pierres noires peuvent être posées sur le terrain avant les mouvements blancs. Mais même avec 4 pierres de handicap, la machine unique AlphaGo a remporté 77%, 86% et 99% du temps contre Crazy Stone, Zen et Pachi, respectivement. La version distribuée d'AlphaGo était nettement plus forte: dans 77% des jeux, elle battait la version mono-machine et dans 100% des jeux - tous les autres programmes. AlphaGo vs d'autres programmes.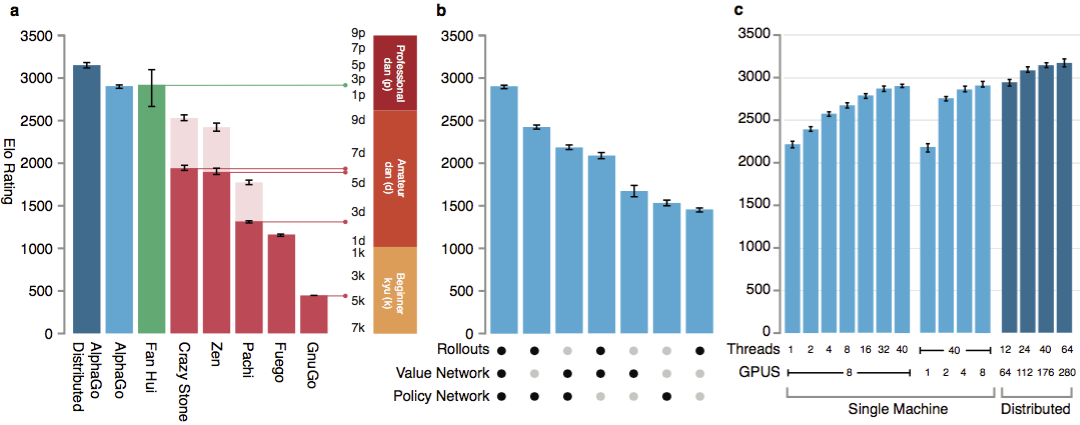 Enfin, le produit créé a été comparé à une personne. Le joueur professionnel 2 dan s'est battu contre la version distribuée d'AlphaGo, Fan Hui, vainqueur du Championnat d'Europe de Go en 2013, 2014 et 2015. Les jeux se sont déroulés avec la participation d'un juge de la Fédération britannique de go et du rédacteur en chef de la revue Nature. 5 matchs ont eu lieu au cours de la période du 5 au 9 octobre 2015. Tous ont remporté l'algorithme de développement de Google DeepMind. Ce sont ces jeux qui ont conduit à déclarer que l'ordinateur était le premier à pouvoir battre un joueur professionnel en déplacement. En plus de 5 partis officiels, 5 partis non officiels ont eu lieu, ce qui n'a pas compté. Fan en a remporté deux.Disponible enregistrement se déplace cinq jeux , l' affichage dans un widget Web et des vidéos sur YouTube .
Enfin, le produit créé a été comparé à une personne. Le joueur professionnel 2 dan s'est battu contre la version distribuée d'AlphaGo, Fan Hui, vainqueur du Championnat d'Europe de Go en 2013, 2014 et 2015. Les jeux se sont déroulés avec la participation d'un juge de la Fédération britannique de go et du rédacteur en chef de la revue Nature. 5 matchs ont eu lieu au cours de la période du 5 au 9 octobre 2015. Tous ont remporté l'algorithme de développement de Google DeepMind. Ce sont ces jeux qui ont conduit à déclarer que l'ordinateur était le premier à pouvoir battre un joueur professionnel en déplacement. En plus de 5 partis officiels, 5 partis non officiels ont eu lieu, ce qui n'a pas compté. Fan en a remporté deux.Disponible enregistrement se déplace cinq jeux , l' affichage dans un widget Web et des vidéos sur YouTube .Critique des joueurs professionnels
Le choix d'un joueur professionnel et le jeu faible du champion sont remis en cause. Les règles choisies sont également peu claires: une heure par match au lieu de plusieurs heures de serious game. Cependant, le format a été choisi par Hui lui-même. En mars, AlphaGo jouera contre Lee Sedola. L'algorithme peut-il battre le professionnel coréen du neuvième dan, considéré comme l'un des meilleurs joueurs du monde? L'enjeu est un million de dollars. Si une personne gagne, Li Sedol le recevra; si l'algorithme gagne, il ira à la charité.Les chercheurs disent que lors de la bataille d'octobre contre les humains, le système AlphaGo a considéré des milliers de fois moins de positions que Deep Blue lors d'un match historique avec Kasparov. Au lieu de cela, le programme a utilisé un réseau de politiques pour des choix plus intelligents et un réseau de valeurs pour mesurer plus précisément les positions. Cette approche est peut-être plus proche de la façon dont les gens jouent, disent les chercheurs. De plus, le système de notation Deep Blue a été programmé manuellement, tandis que les réseaux de neurones AlphaGo ont été formés directement à partir des jeux en utilisant des algorithmes universels d'apprentissage supervisé et d'apprentissage par renforcement. Lee Sedoll tentera sa chance contre AlphaGo en mars. Les joueurs professionnels ont des points de vue différents. Il semble que Google n'ait spécifiquement choisi pas un joueur très fort, quelqu'un est sûr que Sedol perdra en mars.Kim Mengwang (neuvième dan), l'un des joueurs professionnels anglophones les plus forts du monde, estime que Fan Hui n'a pas joué à pleine puissance. À la 51e minute de la vidéo, il donne un exemple concret du deuxième épisode. Fan a peut-être joué les deux avec un plus faible pour tester la puissance de l'ordinateur, dit Kim. Mengwan a admis qu'AlphaGo est un programme incroyablement puissant, mais il est peu probable qu'il vaincre Lee Sedol.L'arbitre du match Toby Manning a informé le British Go Journal du match. Il a analysé les cinq matchs et a souligné certains points. AlphaGo a fait des erreurs lors des deuxième, troisième et quatrième matchs, mais Fan ne les a pas utilisés. Le triple champion d'Europe a répondu par le sien. L'article du magazine se termine par une évaluation générale positive d'AlphaGo: le programme est solide, mais on ne sait pas combien.De plus, lors de la préparation du matériel, j'ai reçu des commentaires de professionnels russes et d'amateurs de go. Alexander Dinerstein (Kazan), troisième dan (professionnel), sept fois champion d'Europe:
Les joueurs professionnels ont des points de vue différents. Il semble que Google n'ait spécifiquement choisi pas un joueur très fort, quelqu'un est sûr que Sedol perdra en mars.Kim Mengwang (neuvième dan), l'un des joueurs professionnels anglophones les plus forts du monde, estime que Fan Hui n'a pas joué à pleine puissance. À la 51e minute de la vidéo, il donne un exemple concret du deuxième épisode. Fan a peut-être joué les deux avec un plus faible pour tester la puissance de l'ordinateur, dit Kim. Mengwan a admis qu'AlphaGo est un programme incroyablement puissant, mais il est peu probable qu'il vaincre Lee Sedol.L'arbitre du match Toby Manning a informé le British Go Journal du match. Il a analysé les cinq matchs et a souligné certains points. AlphaGo a fait des erreurs lors des deuxième, troisième et quatrième matchs, mais Fan ne les a pas utilisés. Le triple champion d'Europe a répondu par le sien. L'article du magazine se termine par une évaluation générale positive d'AlphaGo: le programme est solide, mais on ne sait pas combien.De plus, lors de la préparation du matériel, j'ai reçu des commentaires de professionnels russes et d'amateurs de go. Alexander Dinerstein (Kazan), troisième dan (professionnel), sept fois champion d'Europe:Deep Blue . , , , . Google . .
4-4 ( -, starpoint ). . : 3-3, 3-4, 5-3, , , , . , . .
, , . . – , . , - . . 20-30 , , , , . , . , . .
, - 2016 (EGC), dans le cadre duquel un tournoi de programmes informatiques a toujours lieu. La Fédération de Russie de Go a invité tous les programmes les plus forts à participer au tournoi. S'ils acceptent l'invitation, c'est peut-être à ce tournoi pour la première fois que les programmes Google et Facebook joueront entre eux. Ce dernier, contrairement à son concurrent, suit une voie honnête. Le bot DarkForest joue des milliers de jeux sur le serveur KGS . La version la plus puissante approche le sixième dan sur le serveur. C'est un très bon niveau. Fan Hui et les joueurs de son niveau - il s'agit du huitième dan sur le serveur (sur neuf possibles). La différence est d'environ deux handicaps en pierre. Avec une telle différence, un programme peut parfois vraiment battre une personne. Si sur un pied d'égalité, alors environ dans un lot de dix.
Maxim Podolyak, (Saint-Pétersbourg), vice-président de la Fédération de Russie de Go:, , , , , , , , . , Google : , . , . : , , , . , : , . Google . , . ? ?
Alexander Krainov (Moscou), amoureux du jeu:Du fait de mon activité professionnelle, je connais assez bien la situation «de l'autre côté».
En 2012, il y a eu un bond en avant dans l'apprentissage automatique en général. La quantité de données pour la formation, le niveau des algorithmes et la puissance de la formation ont atteint un niveau tel que les réseaux de neurones artificiels (développés en principe depuis longtemps) ont commencé à donner des résultats fantastiques.
La différence fondamentale entre la formation sur les réseaux de neurones est qu'ils n'ont pas besoin de recevoir de facteurs d'entrée (dans le cas de go, expliquez, par exemple, quelles formes sont bonnes). A la limite, même les règles ne peuvent pas leur être expliquées. L'essentiel est de donner un grand nombre d'exemples positifs (mouvements du côté gagnant) et négatifs (mouvements du côté perdant). Et le réseau apprendra tout seul.
, , . . : , , ( ) , .
, .
, , , . . . . , , .
Ce que Lee Sedol dit lui-même
Les joueurs professionnels vont non pas pour le titre mondial, mais pour les titres. La reconnaissance et le statut du master sont déterminés par le nombre de titres qu'il a pu obtenir au cours de l'année. Lee Sedol est l'un des cinq joueurs de go les plus forts du monde, et en mars de cette année, il devra se battre avec le système AlphaGo.Le champion coréen lui-même prédit qu'il gagnera avec un score de 4-1 ou 5-0. Mais après 2-3 ans, Google voudra se venger, puis le jeu avec la version mise à jour d'AlphaGo sera plus intéressant, dit Lee.
La tâche de créer un tel algorithme pose de nouvelles questions sur ce que sont l'apprentissage et la réflexion. Comme le rappelle M. Emelyanov, le troisième niveau de compétence (épingle) du haut selon l'ancienne classification chinoise est appelé «clarté totale». Un tel niveau de jeu suggère que les décisions sont prises de manière intuitive, avec peu ou pas d'options. L'un des maîtres les plus forts du XXe siècle, Guo Seigen, a déclaré qu'il lui semblait qu'il aurait gagné contre le «go-god» en prenant deux ou trois pierres de handicap. Seigan croyait qu'il avait presque atteint la limite de la compréhension du jeu. Un réseau de neurones peut-il y parvenir? Peut-être que l'intuition humaine est un algorithme établi par la nature?L'auteur remercie Alexander Dinerstein et le public go_secrets pour leurs commentaires et leur aide dans la publication.Source: https://habr.com/ru/post/fr389825/
All Articles