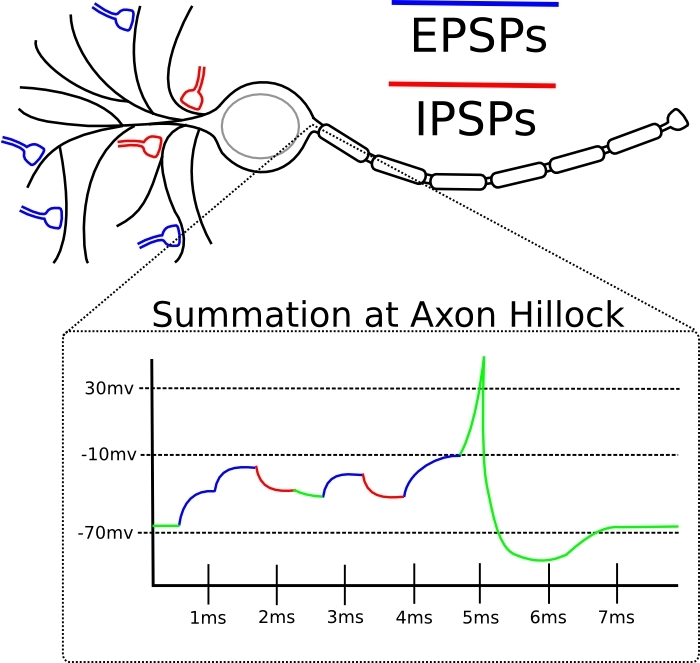
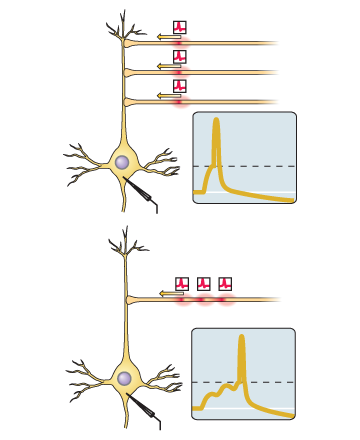
Si le pic d'entrée d'une synapse donnée a tendance à venir juste avant que le neurone lui-même génère un pic, alors la synapse est amplifiée.Si la pointe d'entrée de cette synapse a tendance à venir immédiatement après la génération de la pointe par le neurone lui-même, alors la synapse est affaiblie.
Source: https://habr.com/ru/post/fr390385/More articles:15 ans du premier contact de l'appareil terrestre avec un astéroïdeLe nombre d'utilisateurs de sites et d'applications de rencontres en ligne croît rapidementUbuntu Tablet: "tout ce dont vous avez besoin depuis un PC est dans une tablette"Travaillez-vous trop? Les vacances n'aideront pas14 février - Lawrence Day: Cadeaux pour votre bien-aiméLes titulaires de droits inventent de nouvelles façons de convertir les pirates en utilisateurs payantsTechnologie FRAMQualité de la communication - Application Android du ministère des CommunicationsComment susciter des jeux d'intérêt pour l'histoire ou la table ronde WargamingLe cheval de Troie bancaire intelligent vous permet de retirer une somme d'argent presque illimitée aux distributeurs automatiques de billetsAll Articles