 Il se trouve que la langue principale pour travailler avec des microcontrôleurs est C. De nombreux grands projets y sont écrits. Mais la vie ne s'arrête pas. Les outils de développement modernes peuvent depuis longtemps utiliser C ++ lors du développement de logiciels pour les systèmes embarqués. Cependant, cette approche est encore rare. Il n'y a pas si longtemps, j'ai essayé d'utiliser C ++ en travaillant sur un autre projet. Je vais parler de cette expérience dans cet article.
Il se trouve que la langue principale pour travailler avec des microcontrôleurs est C. De nombreux grands projets y sont écrits. Mais la vie ne s'arrête pas. Les outils de développement modernes peuvent depuis longtemps utiliser C ++ lors du développement de logiciels pour les systèmes embarqués. Cependant, cette approche est encore rare. Il n'y a pas si longtemps, j'ai essayé d'utiliser C ++ en travaillant sur un autre projet. Je vais parler de cette expérience dans cet article.Entrée
La plupart de mon travail avec les microcontrôleurs est lié à C. Tout d'abord, c'était les exigences des clients, puis c'est devenu une habitude. Dans le même temps, en ce qui concerne les applications pour Windows, C ++ y a été utilisé en premier, puis C # en général.Il n'y a pas eu de question sur C ou C ++ depuis longtemps. Même la sortie de la prochaine version du MDK de Keil avec prise en charge C ++ pour ARM ne me dérangeait pas beaucoup. Si vous regardez les projets de démonstration de Keil, tout y est écrit en C. En même temps, C ++ est déplacé dans un dossier séparé avec le projet Blinky. CMSIS et LPCOpen sont également écrits en C. Et si «tout le monde» utilise C, il y a quelques raisons.Mais beaucoup de choses ont changé .Net Micro Framework. Si quelqu'un ne le sait pas, il s'agit d'une implémentation .Net qui vous permet d'écrire des applications pour microcontrôleurs en C # dans Visual Studio. Vous pouvez en savoir plus sur lui dansces articles.Ainsi, .Net Micro Framework est écrit en utilisant C ++. Impressionné par cela, j'ai décidé d'essayer d'écrire un autre projet en C ++. Je dois dire tout de suite que je n'ai pas trouvé d'arguments précis en faveur du C ++, mais il y a quelques points intéressants et utiles dans cette approche.Quelle est la différence entre les projets C et C ++?
L'une des principales différences entre C et C ++ est que le second est un langage orienté objet. L'encapsulation, le polymorphisme et l'héritage bien connus sont monnaie courante ici. C est un langage procédural. Il n'y a que des fonctions et des procédures, et pour le regroupement logique du code, des modules sont utilisés (une paire de .h + .c). Mais si vous regardez attentivement comment C est utilisé dans les microcontrôleurs, vous pouvez voir l'approche orientée objet habituelle.Regardons le code pour travailler avec les LED de l'exemple Keil pour MCB1000 ( Keil_v5 \ ARM \ Boards \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo ):LED.h:#ifndef __LED_H
#define __LED_H
#define LED_NUM 8
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:#include "LPC11xx.h"
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6);
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
Si vous regardez attentivement, vous pouvez faire une analogie avec la POO. La LED est un objet qui a une constante publique, un constructeur, 3 méthodes publiques et un champ privé:class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED();
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
Malgré le fait que le code soit écrit en C, il utilise le paradigme de la programmation d'objets. Un fichier .C est un objet qui vous permet d'encapsuler dans les mécanismes d'implémentation des méthodes publiques décrites dans le fichier .h. Mais il n'y a pas d'héritage ici, et donc aussi de polymorphisme.La plupart du code des projets rencontrés est écrit dans le même style. Et si l'approche POO est utilisée, alors pourquoi ne pas utiliser un langage qui la prend pleinement en charge? Dans le même temps, lors du passage au C ++, dans l'ensemble, seule la syntaxe changera, mais pas les principes de développement.Prenons un autre exemple. Supposons que nous ayons un appareil qui utilise un capteur de température connecté via I2C. Mais une nouvelle révision de l'appareil est sortie et le même capteur est maintenant connecté au SPI. Que faire Il est nécessaire de prendre en charge les première et deuxième révisions de l'appareil, ce qui signifie que le code doit prendre en compte ces modifications de manière flexible. En C, vous pouvez utiliser des prédéfinitions #define pour éviter d'écrire deux fichiers presque identiques. Par exemple#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
et ainsi de suite.En C ++, vous pouvez résoudre ce problème un peu plus élégamment. Créer une interfaceclass ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
et faire 2 implémentationsclass Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
Et puis utilisez telle ou telle implémentation en fonction de la révision:class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
Il semble que la différence n'est pas très grande entre le code C et C ++. L'option orientée objet semble encore plus encombrante. Mais cela vous permet de prendre une décision plus flexible.Lors de l'utilisation de C, deux solutions principales peuvent être distinguées:- Utilisez #define comme indiqué ci-dessus. Cette option n'est pas très bonne car elle «érode» la responsabilité du module. Il s'avère qu'il est responsable de plusieurs révisions du projet. Lorsqu'il existe de nombreux fichiers de ce type, il devient assez difficile de les conserver.
- 2 , C++. “” , . , #ifdef. , , . , . , , .
L'utilisation du polymorphisme donne un résultat plus beau. D'une part, chaque classe résout un problème atomique clair; d'autre part, le code n'est pas jonché et facile à lire.La «ramification» du code sur la révision devra toujours être effectuée dans les premier et deuxième cas, mais l'utilisation du polymorphisme facilite le transfert de la ramification entre les couches du programme, sans encombrer le code avec #ifdef inutile.L'utilisation du polymorphisme permet de prendre facilement une décision encore plus intéressante.Disons qu'une nouvelle révision est publiée, dans laquelle les deux capteurs de température sont installés.Le même code avec des changements minimes vous permet de choisir une implémentation SPI et I2C en temps réel, simplement en utilisant la méthode Init (& temperature).L'exemple est très simplifié, mais dans un vrai projet, j'ai utilisé la même approche pour implémenter le même protocole sur deux interfaces de transfert de données physiques différentes. Cela a facilité le choix de l'interface dans les paramètres de l'appareil.Cependant, avec tout ce qui précède, la différence entre l'utilisation de C et C ++ n'est pas très grande. Les avantages du C ++ liés à la POO ne sont pas si évidents et appartiennent à la catégorie des "amateurs". Mais l'utilisation de C ++ dans les microcontrôleurs pose de sérieux problèmes.Quel est le danger d'utiliser C ++?
La deuxième différence importante entre C et C ++ est l'utilisation de la mémoire. Le langage C est principalement statique. Toutes les fonctions et procédures ont des adresses fixes et le travail avec un groupe n'est effectué que lorsque cela est nécessaire. C ++ est un langage plus dynamique. Son utilisation implique généralement un travail actif avec l'allocation et la libération de mémoire. C'est ce que le C ++ est dangereux. Les microcontrôleurs ont très peu de ressources, il est donc important de les contrôler. L’utilisation incontrôlée de la RAM est lourde de dommages aux données qui y sont stockées et de tels «miracles» dans le travail du programme que peu de choses ne sembleront à personne. De nombreux développeurs ont rencontré de tels problèmes.Si vous regardez attentivement les exemples ci-dessus, vous pouvez noter que les classes n'ont pas de constructeurs et de destructeurs. En effet, ils ne sont jamais créés dynamiquement.Lors de l'utilisation de la mémoire dynamique (et lors de l'utilisation de new), la fonction malloc est toujours appelée, qui alloue le nombre d'octets requis à partir du tas. Même si vous y réfléchissez (même si c'est très difficile) et contrôlez l'utilisation de la mémoire, vous pouvez rencontrer le problème de la fragmentation.Un groupe peut être représenté sous forme de tableau. Par exemple, sélectionnez 20 octets: chaque fois que la mémoire est allouée, la mémoire entière est analysée (de gauche à droite ou de droite à gauche - ce n'est pas si important) pour la présence d'un nombre donné d'octets inoccupés. De plus, ces octets doivent tous être situés à proximité:
chaque fois que la mémoire est allouée, la mémoire entière est analysée (de gauche à droite ou de droite à gauche - ce n'est pas si important) pour la présence d'un nombre donné d'octets inoccupés. De plus, ces octets doivent tous être situés à proximité: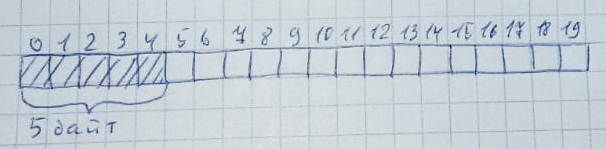 lorsque la mémoire n'est plus nécessaire, elle revient à son état d'origine:Cela peut très facilement se produire lorsqu'il y a suffisamment d'octets libres, mais ils ne sont pas organisés en ligne. Laissez 10 zones de 2 octets chacune allouées:
lorsque la mémoire n'est plus nécessaire, elle revient à son état d'origine:Cela peut très facilement se produire lorsqu'il y a suffisamment d'octets libres, mais ils ne sont pas organisés en ligne. Laissez 10 zones de 2 octets chacune allouées: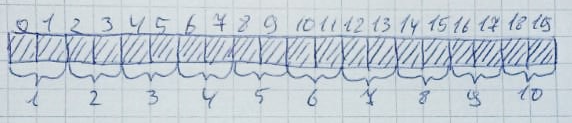 Ensuite, 2,4,6,8,10 zones seront libérées:
Ensuite, 2,4,6,8,10 zones seront libérées: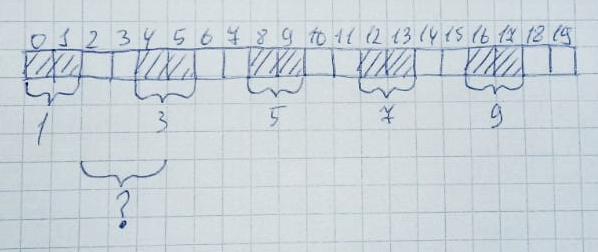 Formellement, la moitié du tas entier (10 octets) reste libre. Cependant, l'allocation d'une zone mémoire de 3 octets échouera toujours, car la baie n'a pas 3 cellules libres d'affilée. C'est ce qu'on appelle la fragmentation de la mémoire.Et gérer cela sur des systèmes sans virtualisation de mémoire est assez difficile. Surtout dans les grands projets.Cette situation peut être facilement émulée. Je l'ai fait dans Keil mVision sur le microcontrôleur LPC11C24.Définissez la taille du tas sur 256 octets:
Formellement, la moitié du tas entier (10 octets) reste libre. Cependant, l'allocation d'une zone mémoire de 3 octets échouera toujours, car la baie n'a pas 3 cellules libres d'affilée. C'est ce qu'on appelle la fragmentation de la mémoire.Et gérer cela sur des systèmes sans virtualisation de mémoire est assez difficile. Surtout dans les grands projets.Cette situation peut être facilement émulée. Je l'ai fait dans Keil mVision sur le microcontrôleur LPC11C24.Définissez la taille du tas sur 256 octets: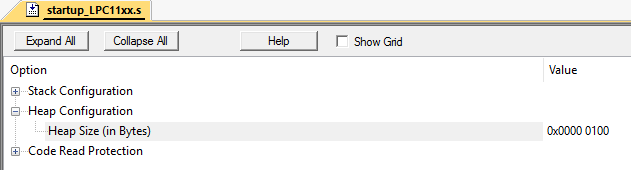 supposons que nous ayons 2 classes:
supposons que nous ayons 2 classes:#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
Comme vous pouvez le voir, la classe de bar prendra plus de mémoire que foo.14 instances de la classe bar sont placées dans le tas et l'instance de la classe foo ne correspond plus:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Si vous ne créez que 7 instances de barre, alors foo sera également créé normalement:int main(void)
{
foo *f;
bar *b[14];
b[1] = new bar();
b[3] = new bar();
b[5] = new bar();
b[7] = new bar();
b[9] = new bar();
b[11] = new bar();
b[13] = new bar();
f = new foo();
}
Cependant, si vous créez d'abord 14 instances de barre, puis supprimez 0,2,4,6,8,10 et 12 instances, alors foo ne pourra pas allouer de mémoire en raison de la fragmentation du tas:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
Il s'avère que vous ne pouvez pas utiliser pleinement C ++, et c'est un inconvénient majeur. D'un point de vue architectural, le C ++, bien que supérieur au C, est insignifiant. Par conséquent, la transition vers C ++ n'apporte pas d'avantages significatifs (bien qu'il n'y ait pas non plus de gros points négatifs). Ainsi, en raison d'une petite différence, le choix de la langue restera simplement la préférence personnelle du développeur.Mais pour moi, j'ai trouvé un point positif significatif dans l'utilisation de C ++. Le fait est qu'avec l'approche C ++ correcte, le code des microcontrôleurs peut être facilement couvert par des tests unitaires dans Visual Studio.Un gros avantage de C ++ est la possibilité d'utiliser Visual Studio.
Pour moi personnellement, le sujet du test de code pour les microcontrôleurs a toujours été assez complexe. Naturellement, le code a été vérifié de toutes les manières possibles, mais la création d'un système de test automatique à part entière a toujours nécessité des coûts énormes, car il était nécessaire d'assembler un support matériel et d'écrire un firmware spécial pour lui. Surtout quand il s'agit d'un système IoT distribué composé de centaines d'appareils.Lorsque j'ai commencé à écrire un projet en C ++, j'ai immédiatement voulu essayer de mettre le code dans Visual Studio et utiliser Keil mVision uniquement pour le débogage. Premièrement, Visual Studio dispose d'un éditeur de code très puissant et pratique, et deuxièmement, Keil mVision n'a pas d'intégration pratique avec les systèmes de contrôle de version, et dans Visual Studio, tout a fonctionné automatiquement. Troisièmement, j'avais l'espoir de pouvoir couvrir au moins une partie du code avec des tests unitaires, qui sont également bien pris en charge dans Visual Studio. Et quatrièmement, c'est l'émergence de Resharper C ++ - une extension Visual Studio pour travailler avec du code C ++, grâce à laquelle vous pouvez éviter de nombreuses erreurs potentielles à l'avance et surveiller le style du code.La création d'un projet dans Visual Studio et sa connexion au système de contrôle de version n'ont posé aucun problème. Mais j'ai dû bricoler avec des tests unitaires.Les classes extraites du matériel (par exemple, les analyseurs de protocole) étaient faciles à tester. Mais j'en voulais plus! Dans mes projets de travail avec des périphériques, j'utilise des fichiers d'en-tête de Keil. Par exemple, pour LPC11C24, il s'agit de LPC11xx.h. Ces fichiers décrivent tous les registres nécessaires conformément à la norme CMSIS. La définition directe d'un registre spécifique se fait via #define:#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
Il s'est avéré que si vous remplacez correctement les registres et créez quelques stubs, le code qui utilise des périphériques peut très bien être compilé dans VisualStudio. Non seulement cela, si vous créez une classe statique et spécifiez ses champs comme adresses de registre, vous obtiendrez un émulateur de microcontrôleur à part entière, qui vous permettra de tester complètement même de travailler avec des périphériques:#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
Et puis faites ceci:#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
De cette façon, vous pouvez compiler et tester tout le code de projet pour les microcontrôleurs dans VisualStudio avec des changements minimes.Dans le processus de développement d'un projet en C ++, j'ai écrit plus de 300 tests couvrant à la fois des aspects purement matériels et du code extrait du matériel. Dans le même temps, une vingtaine d'erreurs assez graves ont été détectées à l'avance, ce qui, en raison de la taille du projet, ne serait pas facile à détecter sans test automatique.Conclusions
Utiliser ou ne pas utiliser C ++ lorsque vous travaillez avec des microcontrôleurs est une question assez compliquée. J'ai montré ci-dessus que, d'une part, les avantages architecturaux d'un POO à part entière ne sont pas si grands, et l'incapacité de travailler pleinement avec un groupe est un problème assez important. Compte tenu de ces aspects, il n'y a pas de grande différence entre C et C ++ pour travailler avec des microcontrôleurs, le choix entre eux peut bien être justifié par les préférences personnelles du développeur.Cependant, j'ai réussi à trouver un gros point positif dans l'utilisation de C ++ en travaillant avec Visaul Studio. Cela vous permet d'augmenter considérablement la fiabilité du développement en raison du travail complet avec les systèmes de contrôle de version, de l'utilisation de tests unitaires complets (y compris des tests pour travailler avec des périphériques) et d'autres avantages de Visual Studio.J'espère que mon expérience sera utile et aidera quelqu'un à augmenter l'efficacité de son travail.Mise à jour :Dans les commentaires sur la version anglaise de cet article a donné des liens utiles sur ce sujet: