Microsoft a acheté 10 millions de brins d'ADN synthétique
Pour des expériences avec stockage de données à long terme
 Microsoft achète 10 millions de brins d'ADN synthétique à Twist Bioscience . Une telle quantité de biomatériaux est nécessaire pour vérifier dans quelle mesure elle convient au stockage à long terme des informations.La densité des informations dans l'ADN a longtemps attiré l'attention des scientifiques: dans un gramme d'ADN, 1 zettaoctet (milliard de téraoctets) de données est stocké et stocké inchangé pendant des milliers d'années dans des conditions appropriées. Le point est petit: apprendre à lire et à écrire des informations à moindre coût et de manière fiable.Des expériences réussies ont été menées à plusieurs reprises au fil des ans avec l'enregistrement de données binaires dans des paires de bases d'ADN. En 2010, des biologistes de Hong Kong ont réussi à introduire de l'ADN synthétique dans la cellule bactérienne d'E.coli , et en 2012, les scientifiques de Harvard ont écrit 643 kilo-octets de données dans l'ADN , établissant un nouveau record pour la quantité d'informations enregistrées.Pour coder les informations dans l'ADN, un système de nombres quadratiques est utilisé, en fonction du nombre de nucléotides (0 = A, 1 = T, 2 = C, 3 = G). Par exemple, des spécialistes de l'Université chinoise de Hong Kong ont traduit le texte en chiffres selon le tableau ASCII (i = 105; G = 71; E = 69; M = 77), puis dans le système quaternaire (105 → 1221; 71 → 0113; 69 → 0111; 77 → 0131), puis dans la chaîne nucléotidique.iGem → 1221011301110131 → ATCTATTGATTTATGTLes spécialistes de Harvard ont utilisé une méthode différente. Premièrement, ils ont essentiellement abandonné l'utilisation d'organismes vivants et introduit de l'ADN synthétique dans une molécule générée sur une puce à ADN commerciale. Ainsi, les informations enregistrées ne peuvent pas être perdues en raison de mutations génétiques au cours de l'évolution de l'organisme hôte. Deuxièmement, ils n'utilisaient pas de texte ASCII, mais du code binaire - un fichier avec un livre, préservant le formatage HTML et les illustrations JPEG. Le code a été divisé en blocs de 96 bits, y compris une adresse unique de 19 bits pour chaque bloc (indiquée en rouge sur le diagramme).
Microsoft achète 10 millions de brins d'ADN synthétique à Twist Bioscience . Une telle quantité de biomatériaux est nécessaire pour vérifier dans quelle mesure elle convient au stockage à long terme des informations.La densité des informations dans l'ADN a longtemps attiré l'attention des scientifiques: dans un gramme d'ADN, 1 zettaoctet (milliard de téraoctets) de données est stocké et stocké inchangé pendant des milliers d'années dans des conditions appropriées. Le point est petit: apprendre à lire et à écrire des informations à moindre coût et de manière fiable.Des expériences réussies ont été menées à plusieurs reprises au fil des ans avec l'enregistrement de données binaires dans des paires de bases d'ADN. En 2010, des biologistes de Hong Kong ont réussi à introduire de l'ADN synthétique dans la cellule bactérienne d'E.coli , et en 2012, les scientifiques de Harvard ont écrit 643 kilo-octets de données dans l'ADN , établissant un nouveau record pour la quantité d'informations enregistrées.Pour coder les informations dans l'ADN, un système de nombres quadratiques est utilisé, en fonction du nombre de nucléotides (0 = A, 1 = T, 2 = C, 3 = G). Par exemple, des spécialistes de l'Université chinoise de Hong Kong ont traduit le texte en chiffres selon le tableau ASCII (i = 105; G = 71; E = 69; M = 77), puis dans le système quaternaire (105 → 1221; 71 → 0113; 69 → 0111; 77 → 0131), puis dans la chaîne nucléotidique.iGem → 1221011301110131 → ATCTATTGATTTATGTLes spécialistes de Harvard ont utilisé une méthode différente. Premièrement, ils ont essentiellement abandonné l'utilisation d'organismes vivants et introduit de l'ADN synthétique dans une molécule générée sur une puce à ADN commerciale. Ainsi, les informations enregistrées ne peuvent pas être perdues en raison de mutations génétiques au cours de l'évolution de l'organisme hôte. Deuxièmement, ils n'utilisaient pas de texte ASCII, mais du code binaire - un fichier avec un livre, préservant le formatage HTML et les illustrations JPEG. Le code a été divisé en blocs de 96 bits, y compris une adresse unique de 19 bits pour chaque bloc (indiquée en rouge sur le diagramme).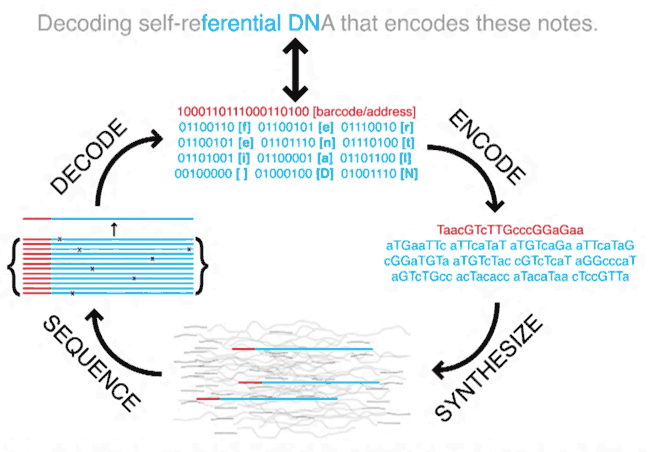 Depuis lors, les techniques d'encodage des données ont été progressivement améliorées. Technologie améliorée pour lire les informations de l'ADN. Les chercheurs de Microsoft Research ont également contribué: ils ont récemment publié un article scientifique.à ce sujet.Twist Bioscience est spécialisée dans les technologies d'enregistrement d'informations dans l'ADN à l'aide d'une machine spéciale pour la production de masse d'ADN synthétique, conçue dans l'entreprise. Les principaux clients de Twist Bioscience sont des laboratoires de recherche qui fabriquent les bactéries génétiquement modifiées nécessaires à certaines réactions chimiques pour produire des médicaments spécifiques. L'utilisation de matériel génétique pour stocker des informations est un nouveau domaine de Twist Bioscience.Les ADN synthétiques sur mesure d'une configuration donnée coûtent environ 10 cents pour une paire de bases. Twist Bioscience prévoit de réduire le prix à 2 cents dans un proche avenir."Ils nous disent la séquence d'ADN, nous produisons la chaîne à partir de zéro," -a déclaré Emily Leproust, directrice générale de Twily Bioscience, concernant un contrat avec Microsoft. Le biomatériau fabriqué est envoyé à Microsoft, tandis que les bio-ingénieurs de Twist Bioscience ne savent même pas quelles informations spécifiques sont codées dans les molécules, car ils n'ont pas de clé de déchiffrement.En laboratoire, à l'aide du vieillissement artificiel, Microsoft testera si l'ADN conservera les informations pendant 1 000 ans.La lecture des informations de l'ADN se fait par séquençage génétique. Au cours des 20 dernières années, le coût de cette procédure a considérablement baissé. Par exemple, le projet de séquençage du génome humain a duré de 1993 à 2003 et a coûté environ 3 milliards de dollars. Aujourd'hui, une telle procédure peut être réalisée pour 1 000 dollars.Si la baisse des prix se poursuit à un tel rythme et qu'il est possible de réduire le niveau des erreurs de lecture , l'ADN peut en effet être considéré comme un support acceptable. Nous devons réduire les prix de 10 000 fois supplémentaires - et la technologie ira aux masses, je suis sûre qu'Emily Leprust.
Depuis lors, les techniques d'encodage des données ont été progressivement améliorées. Technologie améliorée pour lire les informations de l'ADN. Les chercheurs de Microsoft Research ont également contribué: ils ont récemment publié un article scientifique.à ce sujet.Twist Bioscience est spécialisée dans les technologies d'enregistrement d'informations dans l'ADN à l'aide d'une machine spéciale pour la production de masse d'ADN synthétique, conçue dans l'entreprise. Les principaux clients de Twist Bioscience sont des laboratoires de recherche qui fabriquent les bactéries génétiquement modifiées nécessaires à certaines réactions chimiques pour produire des médicaments spécifiques. L'utilisation de matériel génétique pour stocker des informations est un nouveau domaine de Twist Bioscience.Les ADN synthétiques sur mesure d'une configuration donnée coûtent environ 10 cents pour une paire de bases. Twist Bioscience prévoit de réduire le prix à 2 cents dans un proche avenir."Ils nous disent la séquence d'ADN, nous produisons la chaîne à partir de zéro," -a déclaré Emily Leproust, directrice générale de Twily Bioscience, concernant un contrat avec Microsoft. Le biomatériau fabriqué est envoyé à Microsoft, tandis que les bio-ingénieurs de Twist Bioscience ne savent même pas quelles informations spécifiques sont codées dans les molécules, car ils n'ont pas de clé de déchiffrement.En laboratoire, à l'aide du vieillissement artificiel, Microsoft testera si l'ADN conservera les informations pendant 1 000 ans.La lecture des informations de l'ADN se fait par séquençage génétique. Au cours des 20 dernières années, le coût de cette procédure a considérablement baissé. Par exemple, le projet de séquençage du génome humain a duré de 1993 à 2003 et a coûté environ 3 milliards de dollars. Aujourd'hui, une telle procédure peut être réalisée pour 1 000 dollars.Si la baisse des prix se poursuit à un tel rythme et qu'il est possible de réduire le niveau des erreurs de lecture , l'ADN peut en effet être considéré comme un support acceptable. Nous devons réduire les prix de 10 000 fois supplémentaires - et la technologie ira aux masses, je suis sûre qu'Emily Leprust.Source: https://habr.com/ru/post/fr393641/
All Articles