Microsoft a réussi à enregistrer 200 Mo de données sur des brins d'ADN synthétiques
Le but ultime des scientifiques est de créer un "stockage d'ADN" d'une énorme capacité. Théoriquement, un milliard de téraoctets de données peuvent être placés dans un gramme d'ADN. Sous certaines conditions, un enregistrement peut être conservé pendant des milliers d'années. Mais le problème de l'écriture et de la lecture efficaces des informations issues de l'ADN n'est pas encore résolu. Microsoft et l'Université de Washington travaillent actuellement sur ce problème. En avril de cette année, les partenaires ont réussi à enregistrer 150 Ko d'informations dans l'ADN - trois photos. Maintenant, le processus a été amélioré et 202 Mo ont déjà été enregistrés. Un clip vidéo OK Go haute résolution a été enregistré dans les molécules d'acide désoxyribonucléique, auquel a été ajoutée la Déclaration universelle des droits de l'homme, traduite en 100 langues, les 100 meilleurs livres du projet Gutenberg et la base de données des brins d'ADN du Crop Trust .Le projet d'enregistrement des informations dans l'ADN s'appelait Project Palix.Le travail a été réalisé avec de l'ADN synthétique acheté auprès de Twist Bioscience à hauteur de 10 millions de brins. L'ADN synthétique d'une configuration spécifique est développé sur commande. Le coût d'une paire de bases de ce matériau est de 10 cents. Le prix baisse progressivement et le fabricant prévoit d'atteindre 2 cents pour deux raisons.Microsoft et l'Université de Washington ne sont pas les premiers à avoir décidé d'écrire des données dans l'ADN. En 2010, des biologistes de Hong Kong ont proposéla méthode d'introduction d'ADN synthétique dans le génome de la bactérie E. coli. Les Chinois ont utilisé le système de numérotation à quatre chiffres pour coder les informations, selon le nombre de nucléotides (0 = A, 1 = T, 2 = C, 3 = G). Les scientifiques ont traduit les données de test en nombres selon le tableau ASCII (i = 105; G = 71; E = 69; M = 77), puis - dans le système quaternaire (105 → 1221; 71 → 0113; 69 → 0111; 77 → 0131), et après cela - dans la chaîne nucléotidique.Deux ans plus tard, les scientifiques de Harvard , en utilisant une autre méthode, ont écrit 643 kilo-octets de données dans l'ADN. À Harvard, ils ont décidé d'abandonner le travail avec les organismes vivants. Au lieu de cela, l'ADN synthétique a été introduit dans une molécule générée sur une puce à ADN spéciale. L'avantage de cette méthode est l'absence de risque de perte d'information due à des mutations de l'organisme hôte.Ces scientifiques ont pu coder le livre de l'Église, en préservant la mise en forme et les illustrations.
Théoriquement, un milliard de téraoctets de données peuvent être placés dans un gramme d'ADN. Sous certaines conditions, un enregistrement peut être conservé pendant des milliers d'années. Mais le problème de l'écriture et de la lecture efficaces des informations issues de l'ADN n'est pas encore résolu. Microsoft et l'Université de Washington travaillent actuellement sur ce problème. En avril de cette année, les partenaires ont réussi à enregistrer 150 Ko d'informations dans l'ADN - trois photos. Maintenant, le processus a été amélioré et 202 Mo ont déjà été enregistrés. Un clip vidéo OK Go haute résolution a été enregistré dans les molécules d'acide désoxyribonucléique, auquel a été ajoutée la Déclaration universelle des droits de l'homme, traduite en 100 langues, les 100 meilleurs livres du projet Gutenberg et la base de données des brins d'ADN du Crop Trust .Le projet d'enregistrement des informations dans l'ADN s'appelait Project Palix.Le travail a été réalisé avec de l'ADN synthétique acheté auprès de Twist Bioscience à hauteur de 10 millions de brins. L'ADN synthétique d'une configuration spécifique est développé sur commande. Le coût d'une paire de bases de ce matériau est de 10 cents. Le prix baisse progressivement et le fabricant prévoit d'atteindre 2 cents pour deux raisons.Microsoft et l'Université de Washington ne sont pas les premiers à avoir décidé d'écrire des données dans l'ADN. En 2010, des biologistes de Hong Kong ont proposéla méthode d'introduction d'ADN synthétique dans le génome de la bactérie E. coli. Les Chinois ont utilisé le système de numérotation à quatre chiffres pour coder les informations, selon le nombre de nucléotides (0 = A, 1 = T, 2 = C, 3 = G). Les scientifiques ont traduit les données de test en nombres selon le tableau ASCII (i = 105; G = 71; E = 69; M = 77), puis - dans le système quaternaire (105 → 1221; 71 → 0113; 69 → 0111; 77 → 0131), et après cela - dans la chaîne nucléotidique.Deux ans plus tard, les scientifiques de Harvard , en utilisant une autre méthode, ont écrit 643 kilo-octets de données dans l'ADN. À Harvard, ils ont décidé d'abandonner le travail avec les organismes vivants. Au lieu de cela, l'ADN synthétique a été introduit dans une molécule générée sur une puce à ADN spéciale. L'avantage de cette méthode est l'absence de risque de perte d'information due à des mutations de l'organisme hôte.Ces scientifiques ont pu coder le livre de l'Église, en préservant la mise en forme et les illustrations.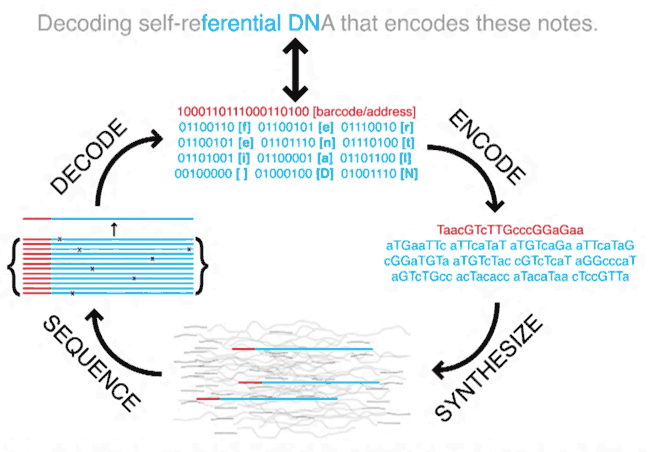
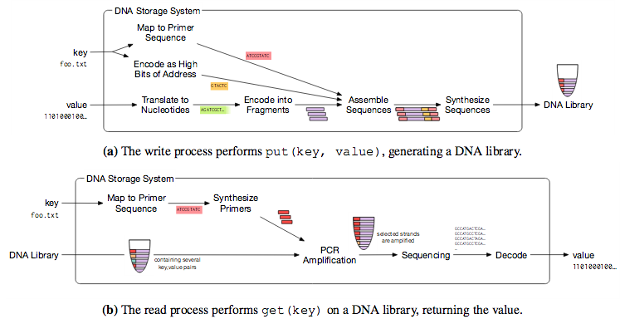 Microsoft et l'Université de Washington utilisent la méthode proposée par des spécialistes de Harvard. Premièrement, les unités et les zéros du code binaire sont traduits en combinaisons de nucléotides - adénine, guanine, cytosine et thymine. Après cela, l'ADN artificiel est synthétisé qui contient ces données. Le codage des informations lui-même est effectué par Twist Bioscience, une société fournissant des brins d'ADN synthétiques. Les clients rapportent la séquence, l'entreprise produit la chaîne à partir de zéro. Quel type d'information est codé dans de telles molécules, Twist Bioscience ne sait pas. Des marqueurs spéciaux sont introduits dans la molécule d'ADN pour déterminer la fin et le début des fichiers enregistrés.Selon Luis Henrique Ceze, l'un des participants au projet, au cours des dernières années, la génétique a fait de grands progrès dans le codage et le décodage des informations sur l'ADN. La précision du codage des informations atteint 100%. La technologie de décryptage des données vous permet de récupérer des informations encodées sans perte. Mais pour l'instant, il ne peut pas être largement utilisé - il ne peut être fait que dans des conditions de laboratoire. Il reste à travailler quelques années avant le moment où la technologie d'enregistrement des données dans l'ADN est disponible à un niveau accessible pour une utilisation de masse.«En utilisant de nouvelles technologies pour un séquençage et une synthèse d'ADN abordables, Twist Bioscience et Microsoft peuvent désormais mettre en pratique la théorie du stockage d'informations dans l'ADN. L'objectif principal est de développer des méthodes pratiques. et évolutif. La capacité de coder des informations numériques dans des brins d'ADN est une réalisation majeure dans le domaine du stockage de données, car les molécules d'ADN sont exemptes des inconvénients des moyens de stockage de données les plus modernes ... Étant donné que presque toute la vie sur Terre existe grâce à l'ADN, il y aura toujours une technologie pour lire l'ADN, vous pouvez donc être sûr de l'accessibilité données enregistrées. De plus, avec la pertinence croissante de la technologie de l'ADN dans la recherche scientifique et médicale, les méthodes de lecture / écriture d'informations dans les brins d'ADN seront constamment améliorées. Ces technologies sont en demande dans de nombreux domaines de l'activité humaine. "- a déclaré dans une déclaration conjointe des partenaires.Les méthodes de travail avec l'information génétique sont en cours d'amélioration et le coût de lecture de l'ADN est réduit. Le projet de décodage du génome humain a coûté 1 milliard de dollars en 2003. Désormais, le coût de décodage du génome est de la même complexité - seulement 1 000 dollars.
Microsoft et l'Université de Washington utilisent la méthode proposée par des spécialistes de Harvard. Premièrement, les unités et les zéros du code binaire sont traduits en combinaisons de nucléotides - adénine, guanine, cytosine et thymine. Après cela, l'ADN artificiel est synthétisé qui contient ces données. Le codage des informations lui-même est effectué par Twist Bioscience, une société fournissant des brins d'ADN synthétiques. Les clients rapportent la séquence, l'entreprise produit la chaîne à partir de zéro. Quel type d'information est codé dans de telles molécules, Twist Bioscience ne sait pas. Des marqueurs spéciaux sont introduits dans la molécule d'ADN pour déterminer la fin et le début des fichiers enregistrés.Selon Luis Henrique Ceze, l'un des participants au projet, au cours des dernières années, la génétique a fait de grands progrès dans le codage et le décodage des informations sur l'ADN. La précision du codage des informations atteint 100%. La technologie de décryptage des données vous permet de récupérer des informations encodées sans perte. Mais pour l'instant, il ne peut pas être largement utilisé - il ne peut être fait que dans des conditions de laboratoire. Il reste à travailler quelques années avant le moment où la technologie d'enregistrement des données dans l'ADN est disponible à un niveau accessible pour une utilisation de masse.«En utilisant de nouvelles technologies pour un séquençage et une synthèse d'ADN abordables, Twist Bioscience et Microsoft peuvent désormais mettre en pratique la théorie du stockage d'informations dans l'ADN. L'objectif principal est de développer des méthodes pratiques. et évolutif. La capacité de coder des informations numériques dans des brins d'ADN est une réalisation majeure dans le domaine du stockage de données, car les molécules d'ADN sont exemptes des inconvénients des moyens de stockage de données les plus modernes ... Étant donné que presque toute la vie sur Terre existe grâce à l'ADN, il y aura toujours une technologie pour lire l'ADN, vous pouvez donc être sûr de l'accessibilité données enregistrées. De plus, avec la pertinence croissante de la technologie de l'ADN dans la recherche scientifique et médicale, les méthodes de lecture / écriture d'informations dans les brins d'ADN seront constamment améliorées. Ces technologies sont en demande dans de nombreux domaines de l'activité humaine. "- a déclaré dans une déclaration conjointe des partenaires.Les méthodes de travail avec l'information génétique sont en cours d'amélioration et le coût de lecture de l'ADN est réduit. Le projet de décodage du génome humain a coûté 1 milliard de dollars en 2003. Désormais, le coût de décodage du génome est de la même complexité - seulement 1 000 dollars. Source: https://habr.com/ru/post/fr395789/
All Articles