Le réseau de neurones de vision industrielle est formé sur des jeux informatiques réalistes.
 Images du jeu informatique Grand Theft Auto V et balisage sémantique pour la formation d'unréseau de neurones de vision industrielle Les réseaux de neurones établissent de nouveaux records dans presque toutes les compétitions de vision par ordinateur et sont également de plus en plus utilisés dans d'autres applications d'IA. L'un des éléments clés de ces performances incroyables de réseau neuronal est la disponibilité de grands ensembles de données pour la formation et l'évaluation. Par exemple, le défi de reconnaissance visuelle à grande échelle Imagenet (ILSVRC) avec plus d'un million d'images est utilisé pour évaluer les réseaux neuronaux modernes. Mais à en juger par les derniers résultats (ResNet montre le résultat de seulement 3,57% d'erreurs), les chercheurs devront bientôt compiler des ensembles de données plus étendus. Et puis - encore plus étendu. Soit dit en passant, annoter de telles photos représente beaucoup de travail, dont une partie doit être effectuée manuellement.Certains développeurs de systèmes de vision par ordinateur offrent une autre façon de former et de tester ces systèmes. Au lieu d'annoter manuellement les photos d'entraînement, ils utilisent des cadres synthétisés à partir de jeux informatiques réalistes.Il s'agit d'une approche tout à fait logique. Dans les jeux modernes, les graphismes ont atteint un tel niveau de réalisme que les images synthétisées ne sont que légèrement différentes des photographies du monde réel. Dans le même temps, le moteur de jeu peut générer un nombre infini de telles images - cela résout immédiatement le problème de la collecte de millions de photos pour la formation et l'évaluation du réseau neuronal.Bien que le moteur de jeu utilise un nombre fini de textures, il existe une grande variété de combinaisons d'angles de vision, d'éclairage, de météo et de niveau de détail, ce qui fournit une variété suffisante d'ensembles de données.Cette année, deux groupes de chercheurs ont vérifié dans la pratique s'il était possible d'utiliser les images générées à partir de jeux informatiques pour former des réseaux de neurones de vision par ordinateur. Un groupe de chercheurs du département d'informatique de l'Université de la Colombie-Britannique (Canada) a publié un article scientifique pour lequel plus de 60000 images d'un jeu informatique avec des vues de route similaires aux jeux de données CamVid et Cityscapes ont été collectées . Les chercheurs ont réussi à prouver que le réseau neuronal après une formation sur des images synthétiques montre un niveau d'erreur similaire à celui d'une formation sur de vraies photographies. De plus, une formation sur des images synthétisées à l'aide de vraies photos montre un résultat encore meilleur.Les 60 000 images ont été prises par temps ensoleillé virtuel, à l'heure virtuelle à 11h00, avec une résolution de 1024 × 768 et des paramètres graphiques maximaux (le nom du jeu n'a pas été divulgué en raison de problèmes de droit d'auteur). Un véhicule sans pilote a accidentellement roulé le long des rues du jeu, observant les règles de la route. Les images ont été tournées une fois par seconde. Chacun d'eux est accompagné d'une segmentation sémantique automatique (ciel, piéton, voitures, arbres, arrière-plan - la segmentation est absolument précise et tirée du jeu), une image profonde (image en profondeur, carte avec le balisage des objets), ainsi que des normales à la surface.En plus de l'ensemble de données VG de base, les chercheurs ont créé un autre ensemble de données VG + avec beaucoup d'informations sémantiques, non limitées à cinq étiquettes - ici, la segmentation n'est pas précise. Le balisage a été effectué automatiquement à l'aide de SegNet .
Images du jeu informatique Grand Theft Auto V et balisage sémantique pour la formation d'unréseau de neurones de vision industrielle Les réseaux de neurones établissent de nouveaux records dans presque toutes les compétitions de vision par ordinateur et sont également de plus en plus utilisés dans d'autres applications d'IA. L'un des éléments clés de ces performances incroyables de réseau neuronal est la disponibilité de grands ensembles de données pour la formation et l'évaluation. Par exemple, le défi de reconnaissance visuelle à grande échelle Imagenet (ILSVRC) avec plus d'un million d'images est utilisé pour évaluer les réseaux neuronaux modernes. Mais à en juger par les derniers résultats (ResNet montre le résultat de seulement 3,57% d'erreurs), les chercheurs devront bientôt compiler des ensembles de données plus étendus. Et puis - encore plus étendu. Soit dit en passant, annoter de telles photos représente beaucoup de travail, dont une partie doit être effectuée manuellement.Certains développeurs de systèmes de vision par ordinateur offrent une autre façon de former et de tester ces systèmes. Au lieu d'annoter manuellement les photos d'entraînement, ils utilisent des cadres synthétisés à partir de jeux informatiques réalistes.Il s'agit d'une approche tout à fait logique. Dans les jeux modernes, les graphismes ont atteint un tel niveau de réalisme que les images synthétisées ne sont que légèrement différentes des photographies du monde réel. Dans le même temps, le moteur de jeu peut générer un nombre infini de telles images - cela résout immédiatement le problème de la collecte de millions de photos pour la formation et l'évaluation du réseau neuronal.Bien que le moteur de jeu utilise un nombre fini de textures, il existe une grande variété de combinaisons d'angles de vision, d'éclairage, de météo et de niveau de détail, ce qui fournit une variété suffisante d'ensembles de données.Cette année, deux groupes de chercheurs ont vérifié dans la pratique s'il était possible d'utiliser les images générées à partir de jeux informatiques pour former des réseaux de neurones de vision par ordinateur. Un groupe de chercheurs du département d'informatique de l'Université de la Colombie-Britannique (Canada) a publié un article scientifique pour lequel plus de 60000 images d'un jeu informatique avec des vues de route similaires aux jeux de données CamVid et Cityscapes ont été collectées . Les chercheurs ont réussi à prouver que le réseau neuronal après une formation sur des images synthétiques montre un niveau d'erreur similaire à celui d'une formation sur de vraies photographies. De plus, une formation sur des images synthétisées à l'aide de vraies photos montre un résultat encore meilleur.Les 60 000 images ont été prises par temps ensoleillé virtuel, à l'heure virtuelle à 11h00, avec une résolution de 1024 × 768 et des paramètres graphiques maximaux (le nom du jeu n'a pas été divulgué en raison de problèmes de droit d'auteur). Un véhicule sans pilote a accidentellement roulé le long des rues du jeu, observant les règles de la route. Les images ont été tournées une fois par seconde. Chacun d'eux est accompagné d'une segmentation sémantique automatique (ciel, piéton, voitures, arbres, arrière-plan - la segmentation est absolument précise et tirée du jeu), une image profonde (image en profondeur, carte avec le balisage des objets), ainsi que des normales à la surface.En plus de l'ensemble de données VG de base, les chercheurs ont créé un autre ensemble de données VG + avec beaucoup d'informations sémantiques, non limitées à cinq étiquettes - ici, la segmentation n'est pas précise. Le balisage a été effectué automatiquement à l'aide de SegNet . Images étroitement marquées de l'ensemble VG +Pour comparer l'efficacité de l'entraînement des réseaux de neurones, des ensembles de données CamVid et Cityscapes (cinq étiquettes), ainsi que CamVid + et Cityscapes + avec des ensembles d'étiquettes étendus ont été préparés.
Images étroitement marquées de l'ensemble VG +Pour comparer l'efficacité de l'entraînement des réseaux de neurones, des ensembles de données CamVid et Cityscapes (cinq étiquettes), ainsi que CamVid + et Cityscapes + avec des ensembles d'étiquettes étendus ont été préparés. Photos CamVid originales avec annotations
Photos CamVid originales avec annotations Deux images aléatoires de Cityscapes + avec annotations détailléesPour la classification sémantique, un long réseau neuronal convolutionnel avec une architecture FCN8 simple au-dessus du VGG Net 16 couches de Simonyan et Sisserman a été utilisé.Les chercheurs ont mené plusieurs expériences pour évaluer l'efficacité de reconnaissance des objets par un réseau neuronal formé sur différents ensembles de données. Dans presque tous les cas, un réseau neuronal formé sur des données synthétiques a montré un meilleur résultat qu'un réseau neuronal formé sur de vraies photographies. Elle a montré le meilleur résultat même en vérifiant de vraies photos.Par exemple, le tableau donne une évaluation des performances de réseaux neuronaux identiques formés sur trois ensembles de données (vraies photos, données synthétiques du jeu, ensemble mixte) lorsque les objets sont reconnus dans de vraies photos des ensembles CamVid + et Cityscapes +.
Deux images aléatoires de Cityscapes + avec annotations détailléesPour la classification sémantique, un long réseau neuronal convolutionnel avec une architecture FCN8 simple au-dessus du VGG Net 16 couches de Simonyan et Sisserman a été utilisé.Les chercheurs ont mené plusieurs expériences pour évaluer l'efficacité de reconnaissance des objets par un réseau neuronal formé sur différents ensembles de données. Dans presque tous les cas, un réseau neuronal formé sur des données synthétiques a montré un meilleur résultat qu'un réseau neuronal formé sur de vraies photographies. Elle a montré le meilleur résultat même en vérifiant de vraies photos.Par exemple, le tableau donne une évaluation des performances de réseaux neuronaux identiques formés sur trois ensembles de données (vraies photos, données synthétiques du jeu, ensemble mixte) lorsque les objets sont reconnus dans de vraies photos des ensembles CamVid + et Cityscapes +.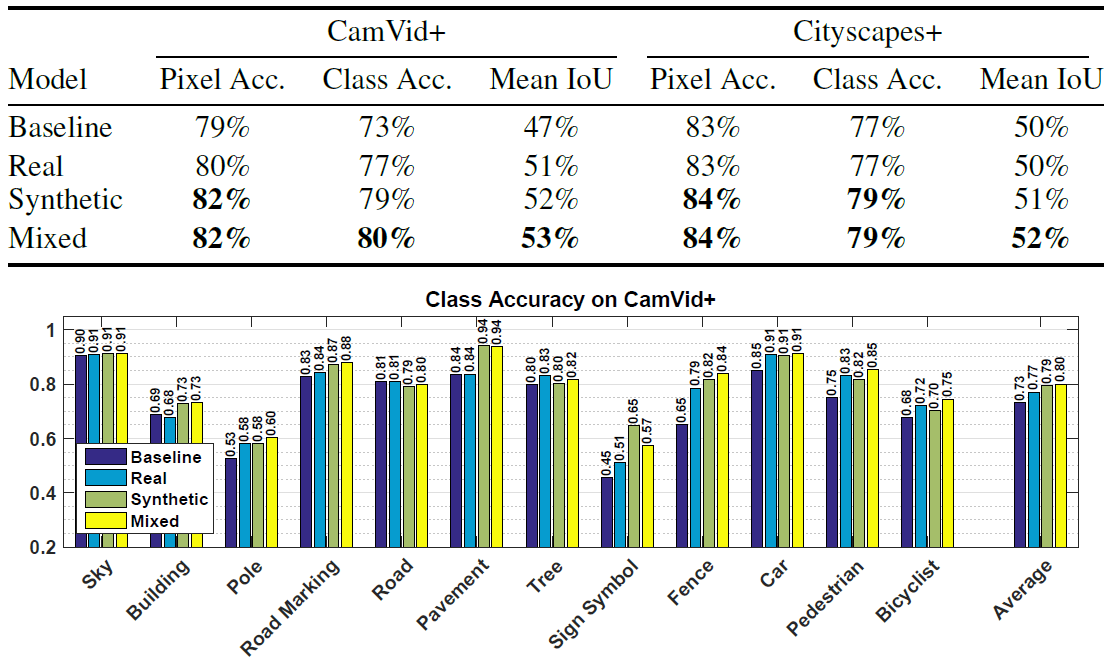 Comme vous pouvez le voir, lors de la formation d'un réseau de neurones, il est préférable de compléter les images synthétiques d'un jeu informatique avec de vraies photographies.Article scientifiquepublié le 5 août 2016 sur arXiv.org, la deuxième version est le 15 août ( pdf ).En plus des chercheurs de l'Université de la Colombie-Britannique, le même travail a été effectué presque simultanément par un autre groupe de scientifiques de l'Université technique de Darmstadt (Allemagne) et d'Intel Labs . Ils ont pris 24 966 images du jeu informatique en monde ouvert Grand Theft Auto V. Les chercheurs sont arrivés au même résultat: lors de l'utilisation d'un ensemble de données de formation composé de 2/3 d'images synthétiques et 1/3 de photos CamVid, précision la reconnaissance est plus élevée que lorsque vous utilisez des photos CamVid.
Comme vous pouvez le voir, lors de la formation d'un réseau de neurones, il est préférable de compléter les images synthétiques d'un jeu informatique avec de vraies photographies.Article scientifiquepublié le 5 août 2016 sur arXiv.org, la deuxième version est le 15 août ( pdf ).En plus des chercheurs de l'Université de la Colombie-Britannique, le même travail a été effectué presque simultanément par un autre groupe de scientifiques de l'Université technique de Darmstadt (Allemagne) et d'Intel Labs . Ils ont pris 24 966 images du jeu informatique en monde ouvert Grand Theft Auto V. Les chercheurs sont arrivés au même résultat: lors de l'utilisation d'un ensemble de données de formation composé de 2/3 d'images synthétiques et 1/3 de photos CamVid, précision la reconnaissance est plus élevée que lorsque vous utilisez des photos CamVid.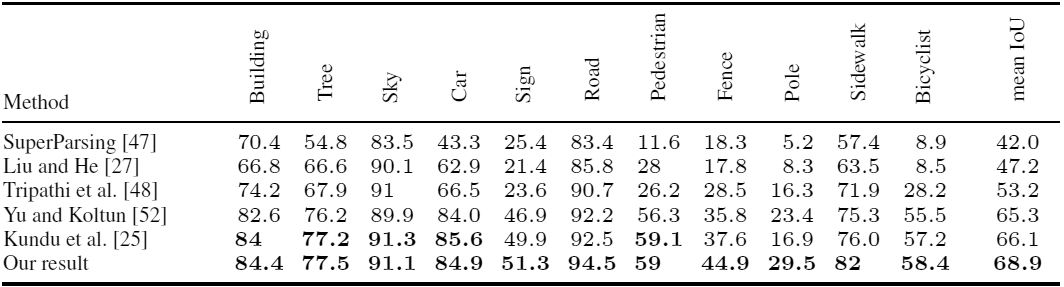 Précision de la reconnaissance de divers objets dans les photos de l'ensemble CamVid lors de l'apprentissage à l'aide de méthodes conventionnelles et lors de l'utilisation d'images de GTA V (résultat)Dans le même temps, l'annotation semi-automatique dans un éditeur spécialement développé réduit considérablement le temps requis pour préparer un ensemble de données pour la formation d'un réseau de neurones. Par exemple, l'annotation d'une photo CamVid prend 60 minutes, une photo Cityscapes prend 90 minutes, et l'annotation d'images semi-automatique GTA V ne prend en moyenne que 7 secondes ( vidéo, démonstration de l'éditeur ).Les travaux des chercheurs de l'Université technique de Darmstadt et d'Intel Labs ont été préparés pour la Conférence européenne sur la vision par ordinateur ECCV'16 (11-14 octobre) et publiés sur le site Web de l'université. Les auteurs ont présenté le code source pour la lecture des étiquettes et des ensembles complets de données : à la fois des photographies sources et des images approfondies avec balisage sémantique. Le code source de l'éditeur d'annotation est susceptible d'être publié à l'avenir.Grâce aux progrès réalisés dans la création de jeux informatiques réalistes, les développeurs de systèmes d'intelligence artificielle auront à leur disposition une excellente plate-forme pour l'apprentissage des systèmes de vision industrielle. Ces systèmes seront utilisés dans des véhicules sans pilote et des robots.Peut-être que les jeux informatiques peuvent être utilisés non seulement pour la vision industrielle, mais aussi pour créer des modèles naturels de comportement dans la société. Ce n'est qu'avec la formation à l'IA que vous devez faire attention au choix d'un jeu.
Précision de la reconnaissance de divers objets dans les photos de l'ensemble CamVid lors de l'apprentissage à l'aide de méthodes conventionnelles et lors de l'utilisation d'images de GTA V (résultat)Dans le même temps, l'annotation semi-automatique dans un éditeur spécialement développé réduit considérablement le temps requis pour préparer un ensemble de données pour la formation d'un réseau de neurones. Par exemple, l'annotation d'une photo CamVid prend 60 minutes, une photo Cityscapes prend 90 minutes, et l'annotation d'images semi-automatique GTA V ne prend en moyenne que 7 secondes ( vidéo, démonstration de l'éditeur ).Les travaux des chercheurs de l'Université technique de Darmstadt et d'Intel Labs ont été préparés pour la Conférence européenne sur la vision par ordinateur ECCV'16 (11-14 octobre) et publiés sur le site Web de l'université. Les auteurs ont présenté le code source pour la lecture des étiquettes et des ensembles complets de données : à la fois des photographies sources et des images approfondies avec balisage sémantique. Le code source de l'éditeur d'annotation est susceptible d'être publié à l'avenir.Grâce aux progrès réalisés dans la création de jeux informatiques réalistes, les développeurs de systèmes d'intelligence artificielle auront à leur disposition une excellente plate-forme pour l'apprentissage des systèmes de vision industrielle. Ces systèmes seront utilisés dans des véhicules sans pilote et des robots.Peut-être que les jeux informatiques peuvent être utilisés non seulement pour la vision industrielle, mais aussi pour créer des modèles naturels de comportement dans la société. Ce n'est qu'avec la formation à l'IA que vous devez faire attention au choix d'un jeu.Source: https://habr.com/ru/post/fr397557/
All Articles