Pouvons-nous ouvrir la boîte noire de l'intelligence artificielle?
 Dean Pomerleau se souvient encore de la première fois où il a dû faire face au problème de la boîte noire. En 1991, il a fait l'une des premières tentatives dans le domaine qui est maintenant étudiée par tous ceux qui essaient de créer une voiture robot: apprendre à conduire un ordinateur.Et cela signifiait que vous deviez conduire un Humvee (véhicule tout-terrain de l'armée) spécialement préparé et rouler dans les rues de la ville. C'est ainsi que Pomelo, alors ancien étudiant diplômé en robotique à l'Université Carnegie Mellon, en parle. Un ordinateur est programmé pour suivre la caméra, interpréter ce qui se passe sur la route et se souvenir de tous les mouvements du conducteur. Pomelo espérait que la voiture finirait par créer suffisamment d'associations pour une conduite indépendante.Pour chaque voyage, Pomelo a entraîné le système pendant plusieurs minutes, puis l'a laissé se diriger seul. Tout semblait bien se passer - jusqu'à ce qu'une fois Humvee, ayant approché du pont, se tourna soudainement sur le côté. Un homme a réussi à éviter un accident en ne saisissant que rapidement le volant et en lui rendant le contrôle.Au laboratoire, Pomelo a essayé de trouver une erreur informatique. «L'une des tâches de mon travail scientifique était d'ouvrir la« boîte noire »et de comprendre à quoi il pensait», explique-t-il. Mais comment? Il a programmé l'ordinateur comme un "réseau neuronal" - un type d'intelligence artificielle qui imite le fonctionnement du cerveau, promettant d'être meilleur que les algorithmes standard pour gérer des situations complexes liées au monde réel. Malheureusement, ces réseaux sont opaques comme un vrai cerveau. Ils ne stockent pas tout ce qui a été appris dans un bloc de mémoire soigné, mais diffusent plutôt les informations de sorte qu'il est très difficile à déchiffrer. Ce n'est qu'après une large gamme de tests de réaction logicielle pour divers paramètres d'entrée, Pomelo a découvert un problème: le réseau a utilisé de l'herbe le long des bords des routes pour déterminer les directions, et donc l'apparence du pont l'a déroutée.Après 25 ans, le décodage des boîtes noires est devenu exponentiellement plus difficile, tout en augmentant l'urgence de cette tâche. Il y a eu une augmentation explosive de la complexité et de la prévalence de la technologie. Un pomelo, enseignant la robotique à temps partiel chez Carnegie Mellon, décrit son système de longue date comme un «réseau de neurones pour les pauvres», par rapport aux énormes réseaux de neurones vendus sur les machines modernes. La technique d'apprentissage en profondeur (GI), dans laquelle les réseaux s'entraînent sur les archives à partir du "big data", trouve diverses applications commerciales, de la robotique aux recommandations de produits sur des sites en fonction de l'historique de navigation.La technologie promet d'être omniprésente en science. Les futurs observatoires radio utiliseront GO pour rechercher des signaux significatifs dans des réseaux de données quisinon vous ne ratisserez pas . Les détecteurs d'ondes gravitationnelles les utiliseront pour comprendre et éliminer les petits bruits. Les éditeurs les utiliseront pour filtrer et étiqueter des millions de documents de recherche et de livres. Certains croient qu'à terme, les ordinateurs, avec l'aide de GO Transit, pourront faire preuve d'imagination et de capacités créatives. «Vous pouvez simplement déposer des données dans la machine et elle vous rendra les lois de la nature», explique Jean-Roch Vlimant, physicien au California Institute of Technology.Mais de telles percées rendront le problème de la boîte noire encore plus aigu. Comment la machine trouve-t-elle exactement des signaux significatifs? Comment pouvez-vous être sûr que ses conclusions sont correctes? À quel point les gens devraient-ils faire confiance à l'apprentissage profond? «Je pense que nous devons céder avec ces algorithmes», explique le spécialiste en robotique Hod Lipson de l'Université Columbia à New York. Il compare la situation à une rencontre avec des extraterrestres intelligents dont les yeux voient non seulement le rouge, le vert et le bleu, mais aussi la quatrième couleur. Selon lui, il sera très difficile pour les gens de comprendre comment ces extraterrestres voient le monde, et pour eux de nous l'expliquer. Les ordinateurs auront les mêmes problèmes pour expliquer leurs décisions, dit-il. "À un certain point, cela commencera à ressembler à des tentatives d'expliquer Shakespeare au chien."Ayant rencontré de tels problèmes, les chercheurs en IA réagissent de la même manière que Pomelo - ils ouvrent une boîte noire et effectuent des actions ressemblant à de la neurologie pour comprendre le fonctionnement des réseaux. Les réponses ne sont pas intuitives, explique Vincenzo Innocente, un physicien du CERN qui a été le premier à utiliser l'IA dans son domaine. «En tant que scientifique, je ne suis pas satisfait de la simple capacité à distinguer les chiens des chats. Un scientifique devrait pouvoir dire: la différence est ceci et cela. »
Dean Pomerleau se souvient encore de la première fois où il a dû faire face au problème de la boîte noire. En 1991, il a fait l'une des premières tentatives dans le domaine qui est maintenant étudiée par tous ceux qui essaient de créer une voiture robot: apprendre à conduire un ordinateur.Et cela signifiait que vous deviez conduire un Humvee (véhicule tout-terrain de l'armée) spécialement préparé et rouler dans les rues de la ville. C'est ainsi que Pomelo, alors ancien étudiant diplômé en robotique à l'Université Carnegie Mellon, en parle. Un ordinateur est programmé pour suivre la caméra, interpréter ce qui se passe sur la route et se souvenir de tous les mouvements du conducteur. Pomelo espérait que la voiture finirait par créer suffisamment d'associations pour une conduite indépendante.Pour chaque voyage, Pomelo a entraîné le système pendant plusieurs minutes, puis l'a laissé se diriger seul. Tout semblait bien se passer - jusqu'à ce qu'une fois Humvee, ayant approché du pont, se tourna soudainement sur le côté. Un homme a réussi à éviter un accident en ne saisissant que rapidement le volant et en lui rendant le contrôle.Au laboratoire, Pomelo a essayé de trouver une erreur informatique. «L'une des tâches de mon travail scientifique était d'ouvrir la« boîte noire »et de comprendre à quoi il pensait», explique-t-il. Mais comment? Il a programmé l'ordinateur comme un "réseau neuronal" - un type d'intelligence artificielle qui imite le fonctionnement du cerveau, promettant d'être meilleur que les algorithmes standard pour gérer des situations complexes liées au monde réel. Malheureusement, ces réseaux sont opaques comme un vrai cerveau. Ils ne stockent pas tout ce qui a été appris dans un bloc de mémoire soigné, mais diffusent plutôt les informations de sorte qu'il est très difficile à déchiffrer. Ce n'est qu'après une large gamme de tests de réaction logicielle pour divers paramètres d'entrée, Pomelo a découvert un problème: le réseau a utilisé de l'herbe le long des bords des routes pour déterminer les directions, et donc l'apparence du pont l'a déroutée.Après 25 ans, le décodage des boîtes noires est devenu exponentiellement plus difficile, tout en augmentant l'urgence de cette tâche. Il y a eu une augmentation explosive de la complexité et de la prévalence de la technologie. Un pomelo, enseignant la robotique à temps partiel chez Carnegie Mellon, décrit son système de longue date comme un «réseau de neurones pour les pauvres», par rapport aux énormes réseaux de neurones vendus sur les machines modernes. La technique d'apprentissage en profondeur (GI), dans laquelle les réseaux s'entraînent sur les archives à partir du "big data", trouve diverses applications commerciales, de la robotique aux recommandations de produits sur des sites en fonction de l'historique de navigation.La technologie promet d'être omniprésente en science. Les futurs observatoires radio utiliseront GO pour rechercher des signaux significatifs dans des réseaux de données quisinon vous ne ratisserez pas . Les détecteurs d'ondes gravitationnelles les utiliseront pour comprendre et éliminer les petits bruits. Les éditeurs les utiliseront pour filtrer et étiqueter des millions de documents de recherche et de livres. Certains croient qu'à terme, les ordinateurs, avec l'aide de GO Transit, pourront faire preuve d'imagination et de capacités créatives. «Vous pouvez simplement déposer des données dans la machine et elle vous rendra les lois de la nature», explique Jean-Roch Vlimant, physicien au California Institute of Technology.Mais de telles percées rendront le problème de la boîte noire encore plus aigu. Comment la machine trouve-t-elle exactement des signaux significatifs? Comment pouvez-vous être sûr que ses conclusions sont correctes? À quel point les gens devraient-ils faire confiance à l'apprentissage profond? «Je pense que nous devons céder avec ces algorithmes», explique le spécialiste en robotique Hod Lipson de l'Université Columbia à New York. Il compare la situation à une rencontre avec des extraterrestres intelligents dont les yeux voient non seulement le rouge, le vert et le bleu, mais aussi la quatrième couleur. Selon lui, il sera très difficile pour les gens de comprendre comment ces extraterrestres voient le monde, et pour eux de nous l'expliquer. Les ordinateurs auront les mêmes problèmes pour expliquer leurs décisions, dit-il. "À un certain point, cela commencera à ressembler à des tentatives d'expliquer Shakespeare au chien."Ayant rencontré de tels problèmes, les chercheurs en IA réagissent de la même manière que Pomelo - ils ouvrent une boîte noire et effectuent des actions ressemblant à de la neurologie pour comprendre le fonctionnement des réseaux. Les réponses ne sont pas intuitives, explique Vincenzo Innocente, un physicien du CERN qui a été le premier à utiliser l'IA dans son domaine. «En tant que scientifique, je ne suis pas satisfait de la simple capacité à distinguer les chiens des chats. Un scientifique devrait pouvoir dire: la différence est ceci et cela. »Belle balade
Le premier réseau neuronal a été créé au début des années 1950, presque immédiatement après l'avènement des ordinateurs capables de fonctionner selon les algorithmes nécessaires. L'idée est d'émuler le fonctionnement de petits modules dénombrables - des neurones - disposés en couches et connectés à des «synapses» numériques. Chaque module de la couche inférieure reçoit des données externes, par exemple des pixels de l'image, puis diffuse ces informations jusqu'à certains des modules de la couche suivante. Chaque module de la deuxième couche intègre les entrées de la première couche selon une règle mathématique simple et transmet le résultat. Par conséquent, la couche supérieure donne une réponse - par exemple, attribue l'image d'origine aux «chats» ou aux «chiens».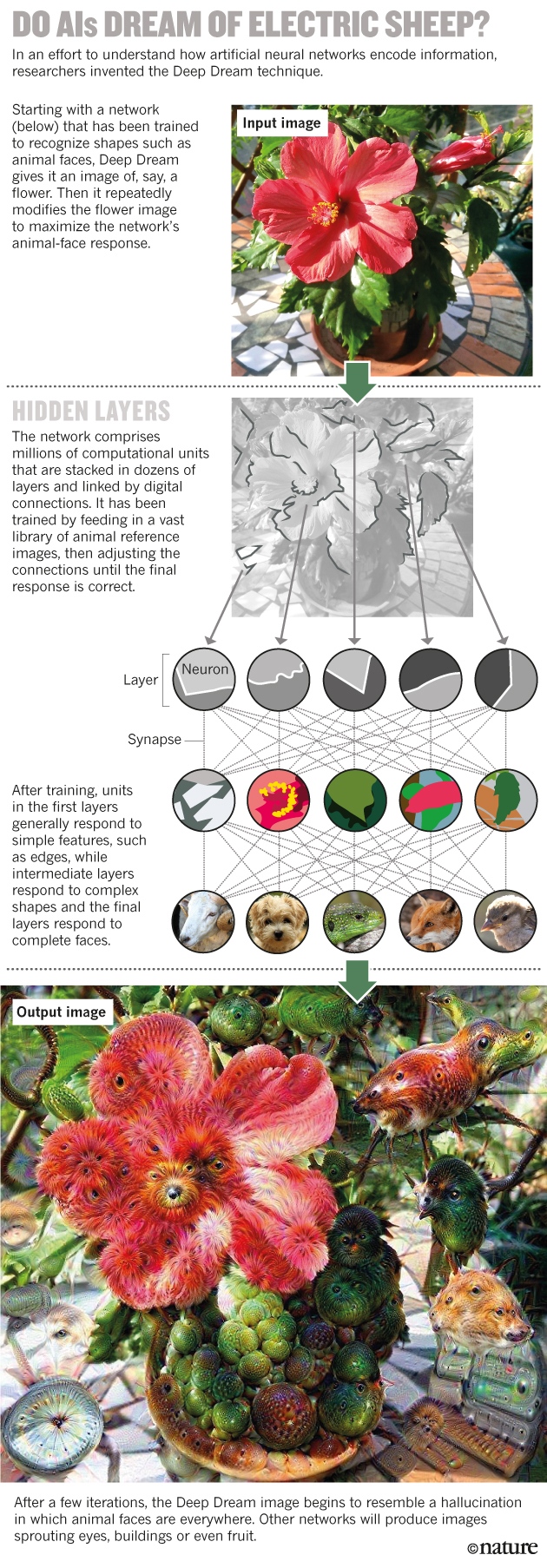 ? « » (Deep Dream) , , , , – , .
? « » (Deep Dream) , , , , – , .
, – , .
Deep Dream .Les capacités de ces réseaux découlent de leur capacité à apprendre. Apprenant de l'ensemble de données initial avec les bonnes réponses données, ils améliorent progressivement leurs caractéristiques, ajustant l'influence de tous les liens pour produire les bons résultats. Le processus émule l'entraînement du cerveau, ce qui renforce et affaiblit les synapses, et fournit une sortie réseau capable de classer des données qui n'étaient pas initialement incluses dans l'ensemble d'entraînement.La possibilité de former a séduit les physiciens du CERN dans les années 1990, lorsqu'ils ont été parmi les premiers à adapter de grands réseaux de neurones au travail scientifique. Les réseaux de neurones ont grandement aidé à reconstruire les trajectoires des éclats subatomiques, se diffusant sur les côtés lors de collisions de particules au Grand collisionneur de hadrons.Cette forme d'apprentissage est également la raison pour laquelle les informations sont très répandues sur le réseau: comme dans le cerveau, sa mémoire est codée dans la force de divers composés et n'est pas stockée à certains endroits, comme dans une base de données familière. «Où est le premier chiffre de votre numéro de téléphone stocké dans votre cerveau? Peut-être dans l'ensemble synapse, peut-être pas loin du reste des chiffres », a déclaré Pierre Baldi, spécialiste en apprentissage automatique (MO), Université de Californie. Mais il n'y a pas de séquence définie de bits codant le nombre. En conséquence, comme le dit l'informaticien Jeff Clune de l'Université du Wyoming, "même si nous créons ces réseaux, nous ne pouvons pas mieux les comprendre que le cerveau humain."Pour les scientifiques travaillant sur les mégadonnées, cela signifie que GO doit être utilisé avec précaution. Andrea Vedaldi, spécialiste de l'informatique à l'Université d'Oxford, explique: Imaginez qu'à l'avenir, le réseau neuronal sera formé sur les mammographies pour indiquer si le cancer du sein est à l'étude chez les femmes étudiées. Après cela, supposons que les tissus d'une femme en bonne santé semblent sensibles à la maladie. «Le réseau neuronal peut apprendre à reconnaître les marqueurs tumoraux - ceux que nous ne connaissons pas, mais qui peuvent prédire le cancer.»Mais si la machine ne peut pas expliquer comment elle le détermine, alors, selon Vedaldi, ce sera un sérieux dilemme pour les médecins et les patients. Il n'est pas facile pour une femme de subir une ablation préventive du sein en raison de la présence de caractéristiques génétiques pouvant conduire au cancer. Et faire un tel choix sera encore plus difficile, car on ne saura même pas ce qu'est ce facteur - même si les prévisions de la machine s'avèrent exactes."Le problème est que les connaissances sont intégrées dans le réseau, pas en nous", explique Michael Tyka, biophysicien et programmeur Google. «Avons-nous compris quelque chose? Non, c'est le réseau compris. »Plusieurs groupes de scientifiques ont abordé le problème de la boîte noire en 2012. Une équipe dirigée par Geoffrey Hinton, spécialiste en MO de l'Université de Toronto, a participé à un concours de vision par ordinateur et a démontré pour la première fois que l'utilisation de GO pour classer les photographies à partir d'une base de données de 1,2 million d'images surpassait toute autre approche avec en utilisant l'IA.Comprenant comment cela est possible, le groupe Vedaldi a pris des algorithmes de Hinton conçus pour améliorer le réseau neuronal et les a fait reculer. Au lieu de former le réseau pour interpréter correctement la réponse, l'équipe a pris des réseaux pré-formés et a essayé de recréer les images, grâce auxquelles ils se sont entraînés. Cela a aidé les chercheurs à déterminer comment la machine présente certaines des caractéristiques - c'était comme s'ils demandaient une sorte de réseau neuronal hypothétique prédisant le cancer: «Quelle partie de la mammographie vous a conduit à la marque de risque de cancer?»L'année dernière, Taika et ses collègues de Google ont utilisé une approche similaire. Leur algorithme, qu'ils ont appelé Deep Dream, commence par une image, disons, d'une fleur, et la modifie de manière à améliorer la réponse d'un neurone de haut niveau particulier. Si un neurone aime marquer des images d'oiseaux, par exemple, l'image modifiée commencera à montrer des oiseaux partout. Les images obtenues ressemblent à des visions sous LSD, où les oiseaux sont visibles sur les visages, les bâtiments et bien d'autres. «Je pense que cela ressemble beaucoup à une hallucination», explique Taika, qui est également artiste. Quand lui et ses collègues ont vu le potentiel de l'algorithme dans le domaine créatif, ils ont décidé de le rendre gratuit à télécharger. En quelques jours, ce sujet est devenu viral.En utilisant des techniques qui maximisent la sortie de n'importe quel neurone, et pas seulement l'un des meilleurs, l'équipe de Klun en 2014 a découvert que le problème de la boîte noire pouvait être plus compliqué qu'il ne le semblait auparavant. Les réseaux de neurones sont très faciles à tromper à l'aide d'images perçues par les gens comme du bruit aléatoire ou des motifs abstraits. Par exemple, un réseau peut prendre des lignes ondulées et décider qu'il s'agit d'une étoile de mer, ou mélanger des rayures noires et blanches avec un bus scolaire. De plus, les mêmes tendances se sont manifestées dans les réseaux formés sur d'autres ensembles de données.Les chercheurs ont suggéré plusieurs solutions au problème de tromper les réseaux, mais aucune solution générale n'a encore été trouvée. Dans les applications réelles, cela peut être dangereux. Selon Clun, l'un des scénarios effrayants est que les pirates apprennent à tirer parti de ces failles du réseau. Ils peuvent envoyer le robot à un panneau d'affichage qu'il prendra pour la route, ou tromper le scanner de la rétine à l'entrée de la Maison Blanche. «Nous devons retrousser nos manches et mener des recherches scientifiques approfondies afin de rendre le MO plus fiable et intelligent», conclut Klyun.De tels problèmes ont conduit certains informaticiens à penser que vous ne devriez pas vous concentrer uniquement sur les réseaux de neurones. Zoubin Ghahramani, un chercheur en MO à l'Université de Cambridge, dit que si l'IA doit donner des réponses que les gens peuvent facilement interpréter, cela conduira à «beaucoup de problèmes que GO ne peut pas résoudre». Une approche scientifique raisonnablement compréhensible a été présentée pour la première fois en 2009 par Lipson et le biologiste informatique Michael Schmidt, qui travaillait alors à l'Université Cornell. Leur algorithme Eureqa a démontré le processus de redécouverte des lois de Newton en observant un simple objet mécanique - un système de pendules - en mouvement.En commençant par une combinaison aléatoire de briques mathématiques comme +, -, sinus et cosinus, Eureqa le modifie par essais et erreurs, similaire à l'évolution darwinienne, jusqu'à ce qu'il en arrive aux formules qui décrivent ces données. Elle propose ensuite des expériences pour tester des modèles. L'un de ses avantages est la simplicité, explique Lipson. «Un modèle développé par Eureqa comporte généralement une dizaine de paramètres. Le réseau de neurones en compte des millions. »Sur pilote automatique
L'année dernière, Garakhmani a publié un algorithme pour automatiser le travail d'un scientifique en fonction des données, des données brutes aux travaux scientifiques finis. Son logiciel Automatic Statistician, note les tendances et les anomalies dans les ensembles de données et fournit un avis, y compris une explication détaillée du raisonnement. Cette transparence, a-t-il dit, est «tout à fait critique» pour une utilisation en science, mais également importante pour une utilisation commerciale. Par exemple, dans de nombreux pays, les banques qui refusent les prêts sont légalement tenues d'expliquer la raison du refus - et cela peut ne pas être possible avec l'algorithme GO.Différentes organisations ont les mêmes doutes, explique Ellie Dobson, directrice de la science des données chez Arundo Analytics à Oslo. Si, par exemple, quelque chose se passe mal en Grande-Bretagne en raison d'une modification du taux de base, la Banque d'Angleterre ne peut pas simplement dire "c'est tout à cause de la boîte noire".Mais, malgré toutes ces craintes, les informaticiens affirment que les tentatives de création d'une IA transparente devraient être un complément à la protection civile et non un remplacement de cette technologie. Certaines techniques transparentes peuvent bien fonctionner dans des domaines déjà décrits comme un ensemble de données abstraites, mais ne font pas face à la perception - le processus d'extraction de faits à partir de données brutes.En conséquence, selon eux, les réponses complexes reçues grâce au ministère de la Défense devraient faire partie des outils de la science, car le monde réel est complexe. Pour des phénomènes tels que la météo ou le marché financier, des descriptions synthétiques réductionnistes peuvent tout simplement ne pas exister. «Il y a des choses qui ne peuvent pas être décrites avec des mots», explique Stéphane Mallat, mathématicien appliqué à l'École polytechnique de Paris. «Lorsque vous demandez à un médecin pourquoi il a posé un tel diagnostic, il vous en explique les raisons», dit-il. - Mais alors pourquoi avez-vous besoin de 20 ans pour devenir un bon médecin? Parce que les informations ne proviennent pas uniquement des livres. »Selon Baldi, le scientifique devrait accepter GO et ne pas s'envoler sur les boîtes noires. Ils ont une telle boîte noire dans la tête. "Vous utilisez constamment le cerveau, vous lui faites toujours confiance et vous ne comprenez pas comment il fonctionne."Source: https://habr.com/ru/post/fr398451/
All Articles