Le réseau de neurones lit 46,8% des mots sur les lèvres à la télévision, alors que seulement 12,4% des personnes
 Les cadres des quatre programmes sur lesquels le programme a été étudié, ainsi que le mot "après-midi", prononcé par deux locuteurs différentsIl y a deux semaines, ils ont parlé du réseau neuronal LipNet , qui a montré une qualité record de 93,4% de reconnaissance de la parole humaine sur les lèvres. Même alors, de nombreuses applications étaient supposées pour de tels systèmes informatiques: une nouvelle génération d'aides auditives médicales avec reconnaissance vocale, des systèmes pour des conférences silencieuses dans les lieux publics, une identification biométrique, des systèmes pour la transmission secrète d'informations pour l'espionnage, la reconnaissance vocale par vidéo à partir de caméras de surveillance, etc. Et maintenant, des experts de l'Université d'Oxford et un employé de Google DeepMind ont parlé de leurs propres développements dans ce domaine.Le nouveau réseau de neurones a été formé sur des textes arbitraires de personnes agissant sur la chaîne de télévision BBC. Fait intéressant, la formation a été effectuée automatiquement, sans annoter d'abord le discours manuellement. Le système lui-même a reconnu la parole, annoté la vidéo, trouvé des visages dans le cadre, puis appris à déterminer la relation entre les mots (sons) et le mouvement des lèvres.En conséquence, ce système reconnaît efficacement les textes arbitraires , plutôt que les instances du corpus spécial de phrases GRID, comme l'a fait LipNet. Le cas GRID a une structure et un vocabulaire strictement limités, donc seulement 33 000 phrases sont possibles. Ainsi, le nombre d'options est réduit de plusieurs ordres de grandeur et la reconnaissance est simplifiée.Le cas spécial GRID se compose comme suit:commande (4) + couleur (4) + préposition (4) + lettre (25) + chiffre (10) + adverbe (4),où le nombre correspond au nombre de variantes de mots pour chacune des six catégories verbales.Contrairement à LipNet, le développement de DeepMind et de spécialistes de l'Université d'Oxford travaille sur des flux de parole arbitraires sur la qualité d'image de la télévision. Cela ressemble beaucoup plus à un vrai système, prêt à l'emploi.AI a formé 5 000 heures de vidéo enregistrées à partir de six émissions de télévision de la chaîne de télévision britannique BBC de janvier 2010 à décembre 2015: ce sont des communiqués de presse réguliers (1584 heures), des nouvelles du matin (1997 heures), des émissions de Newsnight (590 heures), World News (194 heures), l'heure des questions (323 heures) et World Today (272 heures). Au total, les vidéos contiennent 118.116 phrases de discours humain continu.Après cela, le programme a été vérifié sur des émissions diffusées entre mars et septembre 2016.
Les cadres des quatre programmes sur lesquels le programme a été étudié, ainsi que le mot "après-midi", prononcé par deux locuteurs différentsIl y a deux semaines, ils ont parlé du réseau neuronal LipNet , qui a montré une qualité record de 93,4% de reconnaissance de la parole humaine sur les lèvres. Même alors, de nombreuses applications étaient supposées pour de tels systèmes informatiques: une nouvelle génération d'aides auditives médicales avec reconnaissance vocale, des systèmes pour des conférences silencieuses dans les lieux publics, une identification biométrique, des systèmes pour la transmission secrète d'informations pour l'espionnage, la reconnaissance vocale par vidéo à partir de caméras de surveillance, etc. Et maintenant, des experts de l'Université d'Oxford et un employé de Google DeepMind ont parlé de leurs propres développements dans ce domaine.Le nouveau réseau de neurones a été formé sur des textes arbitraires de personnes agissant sur la chaîne de télévision BBC. Fait intéressant, la formation a été effectuée automatiquement, sans annoter d'abord le discours manuellement. Le système lui-même a reconnu la parole, annoté la vidéo, trouvé des visages dans le cadre, puis appris à déterminer la relation entre les mots (sons) et le mouvement des lèvres.En conséquence, ce système reconnaît efficacement les textes arbitraires , plutôt que les instances du corpus spécial de phrases GRID, comme l'a fait LipNet. Le cas GRID a une structure et un vocabulaire strictement limités, donc seulement 33 000 phrases sont possibles. Ainsi, le nombre d'options est réduit de plusieurs ordres de grandeur et la reconnaissance est simplifiée.Le cas spécial GRID se compose comme suit:commande (4) + couleur (4) + préposition (4) + lettre (25) + chiffre (10) + adverbe (4),où le nombre correspond au nombre de variantes de mots pour chacune des six catégories verbales.Contrairement à LipNet, le développement de DeepMind et de spécialistes de l'Université d'Oxford travaille sur des flux de parole arbitraires sur la qualité d'image de la télévision. Cela ressemble beaucoup plus à un vrai système, prêt à l'emploi.AI a formé 5 000 heures de vidéo enregistrées à partir de six émissions de télévision de la chaîne de télévision britannique BBC de janvier 2010 à décembre 2015: ce sont des communiqués de presse réguliers (1584 heures), des nouvelles du matin (1997 heures), des émissions de Newsnight (590 heures), World News (194 heures), l'heure des questions (323 heures) et World Today (272 heures). Au total, les vidéos contiennent 118.116 phrases de discours humain continu.Après cela, le programme a été vérifié sur des émissions diffusées entre mars et septembre 2016.Un exemple de lecture labiale sur un écran de télévision Le programme a montré une qualité de lecture assez élevée. Elle a correctement reconnu des phrases même très complexes avec des constructions grammaticales inhabituelles et l'utilisation de noms propres. Exemples de phrases parfaitement reconnues:- PLUS DE PERSONNES ONT ÉTÉ IMPLIQUÉES DANS LES ATTAQUES
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
L'IA a largement dépassé l'efficacité du travail d'une personne, experte en lecture labiale, qui a tenté de reconnaître 200 clips vidéo aléatoires à partir d'une archive vidéo de vérification enregistrée.Le professionnel n'a pu annoter sans une seule erreur que 12,4% des mots, tandis que l'IA a correctement enregistré 46,8%. Les chercheurs notent que de nombreuses erreurs peuvent être qualifiées de mineures. Par exemple, les «s» manquants à la fin des mots. Si nous abordons l'analyse des résultats de manière moins stricte, alors en réalité le système a reconnu bien plus de la moitié des mots en ondes.Avec ce résultat, DeepMind est nettement supérieur à tous les autres lecteurs de lèvres, y compris le LipNet susmentionné, qui est également développé à l'Université d'Oxford. Cependant, il est trop tôt pour parler de supériorité ultime, car LipNet n'était pas formé sur un si grand ensemble de données.Selon les experts , DeepMind est un grand pas vers le développement d'un système de lecture labiale entièrement automatique.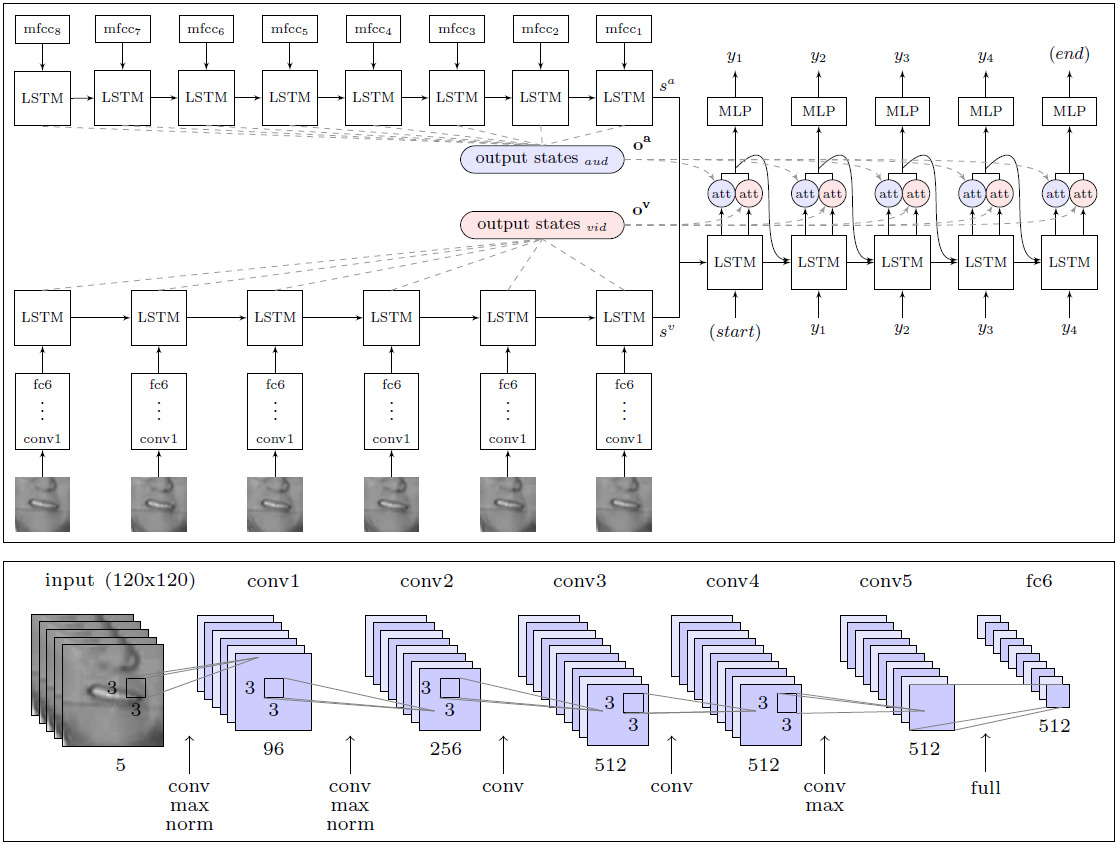 L'architecture du module WLAS (Watch, Listen, Attend and Spell) et un réseau neuronal convolutif pour la lecture des lèvresLe grand mérite des chercheurs réside dans le fait qu'ils ont compilé un gigantesque ensemble de données pour la formation et le test du système avec 17 500 mots uniques. Après tout, ce n'est pas seulement cinq ans d'enregistrement continu de programmes de télévision dans un bon anglais, mais aussi une synchronisation claire de la vidéo et du son (à la télévision, il y a souvent une synchronisation jusqu'à 1 seconde, même sur la télévision anglaise professionnelle), ainsi que le développement d'un module de reconnaissance vocale, qui est superposé en vidéo et est utilisé dans l'enseignement du système de lecture labiale (module WLAS, voir schéma ci-dessus).Dans le cas de la moindre rassynchronisation, l'entraînement du système devient pratiquement inutile, car le programme ne peut pas déterminer la correspondance correcte des sons et des mouvements des lèvres. Après un travail préparatoire approfondi, la formation du programme a été complètement automatique - il a traité indépendamment les 5000 vidéos.Auparavant, un tel ensemble n'existait tout simplement pas, par conséquent, les mêmes auteurs LipNet ont été contraints de se limiter à la base GRID. Au crédit des développeurs de DeepMind, ils ont promis de publier un ensemble de données dans le domaine public pour former d'autres IA. Des collègues de l'équipe de développement LipNet ont déjà déclaré qu'ils l'attendaient avec impatience.Les travaux scientifiques sont publiés dans le domaine public sur le site Web arXiv (arXiv: 1611.05358v1).Si des systèmes commerciaux de lecture labiale apparaissent sur le marché, alors la vie des gens ordinaires sera beaucoup plus simple. On peut supposer que de tels systèmes seront immédiatement intégrés aux téléviseurs et autres appareils électroménagers pour améliorer le contrôle vocal et la reconnaissance vocale presque sans erreur.
L'architecture du module WLAS (Watch, Listen, Attend and Spell) et un réseau neuronal convolutif pour la lecture des lèvresLe grand mérite des chercheurs réside dans le fait qu'ils ont compilé un gigantesque ensemble de données pour la formation et le test du système avec 17 500 mots uniques. Après tout, ce n'est pas seulement cinq ans d'enregistrement continu de programmes de télévision dans un bon anglais, mais aussi une synchronisation claire de la vidéo et du son (à la télévision, il y a souvent une synchronisation jusqu'à 1 seconde, même sur la télévision anglaise professionnelle), ainsi que le développement d'un module de reconnaissance vocale, qui est superposé en vidéo et est utilisé dans l'enseignement du système de lecture labiale (module WLAS, voir schéma ci-dessus).Dans le cas de la moindre rassynchronisation, l'entraînement du système devient pratiquement inutile, car le programme ne peut pas déterminer la correspondance correcte des sons et des mouvements des lèvres. Après un travail préparatoire approfondi, la formation du programme a été complètement automatique - il a traité indépendamment les 5000 vidéos.Auparavant, un tel ensemble n'existait tout simplement pas, par conséquent, les mêmes auteurs LipNet ont été contraints de se limiter à la base GRID. Au crédit des développeurs de DeepMind, ils ont promis de publier un ensemble de données dans le domaine public pour former d'autres IA. Des collègues de l'équipe de développement LipNet ont déjà déclaré qu'ils l'attendaient avec impatience.Les travaux scientifiques sont publiés dans le domaine public sur le site Web arXiv (arXiv: 1611.05358v1).Si des systèmes commerciaux de lecture labiale apparaissent sur le marché, alors la vie des gens ordinaires sera beaucoup plus simple. On peut supposer que de tels systèmes seront immédiatement intégrés aux téléviseurs et autres appareils électroménagers pour améliorer le contrôle vocal et la reconnaissance vocale presque sans erreur.Source: https://habr.com/ru/post/fr399429/
All Articles