Le réseau neuronal Pix2pix colore de manière réaliste les croquis au crayon et les photos en noir et blanc
 Quatre exemples du programme, dont le code est publié dans le domaine public. Les images source sont affichées à gauche, résultat du traitement automatique à droite.De nombreuses tâches de traitement d'images, d'infographie et de vision par ordinateur peuvent être réduites à la tâche de «traduire» une image (en entrée) en une autre (en sortie). Tout comme le même texte peut être représenté en anglais ou en russe, l'image peut être représentée en couleurs RVB, en dégradés, comme une carte des limites des objets, une carte des étiquettes sémantiques, etc. Basé sur le modèle des systèmes de traduction automatique, les développeurs du Berkeley AI Research Laboratory (BAIR) de l'Université de Californie à Berkeley ont créé une applicationpour diffuser automatiquement des images d'une vue à une autre. Par exemple, d'une esquisse en noir et blanc à une image en couleur.Pour une personne non informée, le travail d'un tel programme semblera magique, mais il est basé sur un modèle de programme de réseaux contradictoires génératifs conditionnels (cGAN) - des variétés du type connu de réseaux contradictoires génératifs (GAN).Les auteurs des travaux scientifiques écrivent que la plupart des problèmes qui se posent lors de la traduction d'images sont liés soit à la traduction «plusieurs à un» (vision par ordinateur - traduction de photos en cartes sémantiques, segments, limites d'objets, etc.), soit «un à plusieurs» "(Infographie - traduction d'étiquettes ou de données d'entrée de l'utilisateur en images réalistes). Traditionnellement, chacune de ces tâches est effectuée par une application spécialisée distincte. Dans leur travail, les auteurs ont essayé de créer un cadre universel unique pour tous ces problèmes. Et ils l'ont fait.Les réseaux de neurones convolutifs formés pour minimiser la fonction de perte sont parfaits pour diffuser des images., c'est-à-dire une mesure de l'écart entre la valeur réelle du paramètre estimé et l'estimation du paramètre. Bien que la formation elle-même se déroule automatiquement, néanmoins, un travail manuel important est nécessaire pour minimiser efficacement la fonction de perte. En d'autres termes, nous devons encore expliquer et montrer aux réseaux de neurones ce qui doit spécifiquement être minimisé. Et ici, il existe de nombreux pièges qui affectent négativement le résultat, si nous travaillons avec une fonction de perte de bas niveau telle que «minimiser la distance euclidienne entre les pixels prédits et réels» - cela conduira à la génération d'images floues.
Quatre exemples du programme, dont le code est publié dans le domaine public. Les images source sont affichées à gauche, résultat du traitement automatique à droite.De nombreuses tâches de traitement d'images, d'infographie et de vision par ordinateur peuvent être réduites à la tâche de «traduire» une image (en entrée) en une autre (en sortie). Tout comme le même texte peut être représenté en anglais ou en russe, l'image peut être représentée en couleurs RVB, en dégradés, comme une carte des limites des objets, une carte des étiquettes sémantiques, etc. Basé sur le modèle des systèmes de traduction automatique, les développeurs du Berkeley AI Research Laboratory (BAIR) de l'Université de Californie à Berkeley ont créé une applicationpour diffuser automatiquement des images d'une vue à une autre. Par exemple, d'une esquisse en noir et blanc à une image en couleur.Pour une personne non informée, le travail d'un tel programme semblera magique, mais il est basé sur un modèle de programme de réseaux contradictoires génératifs conditionnels (cGAN) - des variétés du type connu de réseaux contradictoires génératifs (GAN).Les auteurs des travaux scientifiques écrivent que la plupart des problèmes qui se posent lors de la traduction d'images sont liés soit à la traduction «plusieurs à un» (vision par ordinateur - traduction de photos en cartes sémantiques, segments, limites d'objets, etc.), soit «un à plusieurs» "(Infographie - traduction d'étiquettes ou de données d'entrée de l'utilisateur en images réalistes). Traditionnellement, chacune de ces tâches est effectuée par une application spécialisée distincte. Dans leur travail, les auteurs ont essayé de créer un cadre universel unique pour tous ces problèmes. Et ils l'ont fait.Les réseaux de neurones convolutifs formés pour minimiser la fonction de perte sont parfaits pour diffuser des images., c'est-à-dire une mesure de l'écart entre la valeur réelle du paramètre estimé et l'estimation du paramètre. Bien que la formation elle-même se déroule automatiquement, néanmoins, un travail manuel important est nécessaire pour minimiser efficacement la fonction de perte. En d'autres termes, nous devons encore expliquer et montrer aux réseaux de neurones ce qui doit spécifiquement être minimisé. Et ici, il existe de nombreux pièges qui affectent négativement le résultat, si nous travaillons avec une fonction de perte de bas niveau telle que «minimiser la distance euclidienne entre les pixels prédits et réels» - cela conduira à la génération d'images floues. L'effet de diverses fonctions de perte sur le résultatIl serait beaucoup plus simple de définir des réseaux de neurones avec des tâches de haut niveau telles que «générer une image impossible à distinguer de la réalité», puis d'entraîner automatiquement le réseau de neurones pour minimiser la fonction de perte qui exécute le mieux la tâche. C'est ainsi que fonctionnent les réseaux antagonistes génératifs (GAN) - l'un des domaines les plus prometteurs dans le développement des réseaux de neurones aujourd'hui. Le réseau GAN forme la fonction de perte, dont la tâche est de classer l'image comme «réelle» ou «fausse», tout en entraînant le modèle génératif pour minimiser cette fonction. Ici, les images floues ne peuvent en aucun cas être produites, car elles ne passeront pas le contrôle de classification comme «réelles».Les développeurs ont utilisé des réseaux contradictoires génératifs conditionnels (cGAN) pour la tâche, c'est-à-dire GAN avec un paramètre conditionnel. Tout comme le GAN assimile le modèle de données génératives, le cGAN assimile le modèle génératif dans une certaine condition, ce qui le rend approprié pour diffuser des images «une à une».
L'effet de diverses fonctions de perte sur le résultatIl serait beaucoup plus simple de définir des réseaux de neurones avec des tâches de haut niveau telles que «générer une image impossible à distinguer de la réalité», puis d'entraîner automatiquement le réseau de neurones pour minimiser la fonction de perte qui exécute le mieux la tâche. C'est ainsi que fonctionnent les réseaux antagonistes génératifs (GAN) - l'un des domaines les plus prometteurs dans le développement des réseaux de neurones aujourd'hui. Le réseau GAN forme la fonction de perte, dont la tâche est de classer l'image comme «réelle» ou «fausse», tout en entraînant le modèle génératif pour minimiser cette fonction. Ici, les images floues ne peuvent en aucun cas être produites, car elles ne passeront pas le contrôle de classification comme «réelles».Les développeurs ont utilisé des réseaux contradictoires génératifs conditionnels (cGAN) pour la tâche, c'est-à-dire GAN avec un paramètre conditionnel. Tout comme le GAN assimile le modèle de données génératives, le cGAN assimile le modèle génératif dans une certaine condition, ce qui le rend approprié pour diffuser des images «une à une». Diffusez des dispositions de paysages urbains sur des photos réalistes. À gauche, le balisage, au centre, l'original et à droite, l'imagegénérée.Au cours des deux dernières années, de nombreuses applications GAN ont été décrites et la base théorique de leur travail a été bien étudiée. Mais dans tous ces travaux, GAN est utilisé uniquement pour des tâches spécialisées (par exemple, la génération d'images effrayantes ou la génération d'images porno) Il n'était pas tout à fait clair comment le GAN est adapté à la traduction efficace d'images un à un. L'objectif principal de ce travail est de démontrer qu'un tel réseau de neurones est capable d'effectuer une grande liste de tâches diverses, montrant un résultat tout à fait acceptable.Par exemple, la coloration des croquis au crayon noir et blanc (colonne de gauche) semble très bonne, sur la base de laquelle le réseau neuronal génère des images photoréalistes (colonne de droite). Dans certains cas, le résultat du fonctionnement du réseau neuronal semble encore plus réaliste qu'une vraie photographie (la colonne centrale, à titre de comparaison).
Diffusez des dispositions de paysages urbains sur des photos réalistes. À gauche, le balisage, au centre, l'original et à droite, l'imagegénérée.Au cours des deux dernières années, de nombreuses applications GAN ont été décrites et la base théorique de leur travail a été bien étudiée. Mais dans tous ces travaux, GAN est utilisé uniquement pour des tâches spécialisées (par exemple, la génération d'images effrayantes ou la génération d'images porno) Il n'était pas tout à fait clair comment le GAN est adapté à la traduction efficace d'images un à un. L'objectif principal de ce travail est de démontrer qu'un tel réseau de neurones est capable d'effectuer une grande liste de tâches diverses, montrant un résultat tout à fait acceptable.Par exemple, la coloration des croquis au crayon noir et blanc (colonne de gauche) semble très bonne, sur la base de laquelle le réseau neuronal génère des images photoréalistes (colonne de droite). Dans certains cas, le résultat du fonctionnement du réseau neuronal semble encore plus réaliste qu'une vraie photographie (la colonne centrale, à titre de comparaison). Diffusez des croquis au crayon sur des photos réalistes. A gauche se trouve un dessin au crayon, au centre l'original et à droite une image générée.
Diffusez des croquis au crayon sur des photos réalistes. A gauche se trouve un dessin au crayon, au centre l'original et à droite une image générée.
 Traduction de croquis au crayon en photos réalistes.Comme dans d'autres réseaux génératifs, dans ce GAN, les réseaux de neurones sont en guerre entre eux . L'un d'eux (le générateur) essaie de créer une fausse image afin de tromper l'autre (discriminateur). Avec le temps, le générateur apprend à mieux tromper le discriminateur, c'est-à-dire à générer des images plus réalistes. Contrairement aux GAN conventionnels, dans Pix2Pix, le discriminateur et le générateur ont accès à l'image d'origine.
Traduction de croquis au crayon en photos réalistes.Comme dans d'autres réseaux génératifs, dans ce GAN, les réseaux de neurones sont en guerre entre eux . L'un d'eux (le générateur) essaie de créer une fausse image afin de tromper l'autre (discriminateur). Avec le temps, le générateur apprend à mieux tromper le discriminateur, c'est-à-dire à générer des images plus réalistes. Contrairement aux GAN conventionnels, dans Pix2Pix, le discriminateur et le générateur ont accès à l'image d'origine.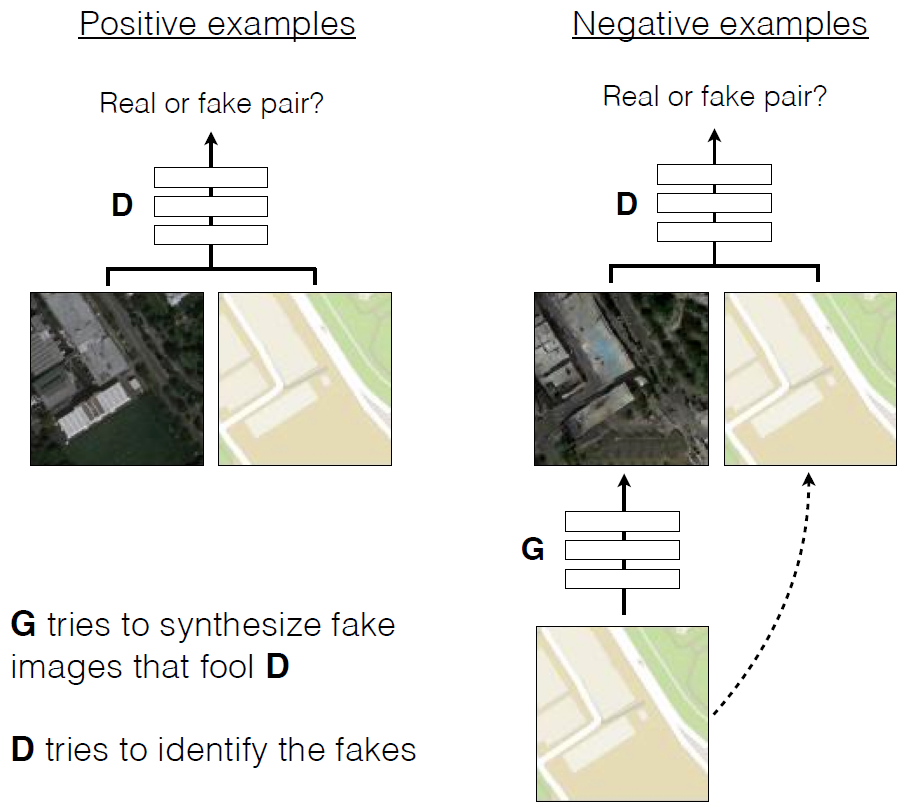 Formation de cGAN pour prédire des photographies aériennes à partir de cartes de terrain
Formation de cGAN pour prédire des photographies aériennes à partir de cartes de terrain Exemples de travaux de cGAN dans la traduction de photographies aériennes en cartes de terrain et vice versa Unarticle scientifique est publié dans le domaine public, le code source de Pix2pix est sur GitHub . Les auteurs proposent à chacun de découvrir le programme.
Exemples de travaux de cGAN dans la traduction de photographies aériennes en cartes de terrain et vice versa Unarticle scientifique est publié dans le domaine public, le code source de Pix2pix est sur GitHub . Les auteurs proposent à chacun de découvrir le programme.Source: https://habr.com/ru/post/fr399469/
All Articles