La dernière fois [
Téléchargement de données à partir du site de données ouvertes data.gov.ru ], j'ai réussi à apprendre à télécharger des données depuis le portail russe de données ouvertes avec quelques problèmes. Le portail de données ouvertes devrait fournir les informations les plus pertinentes sur les données ouvertes des autorités fédérales, des autorités régionales et d'autres organisations (citation de data.gov.ru). Voyons quelles données sur le portail, dans quelle mesure elles sont pertinentes et sous quelle forme elles sont placées.
Le graphique circulaire ci-dessous montre la répartition des ensembles de données par catégorie.
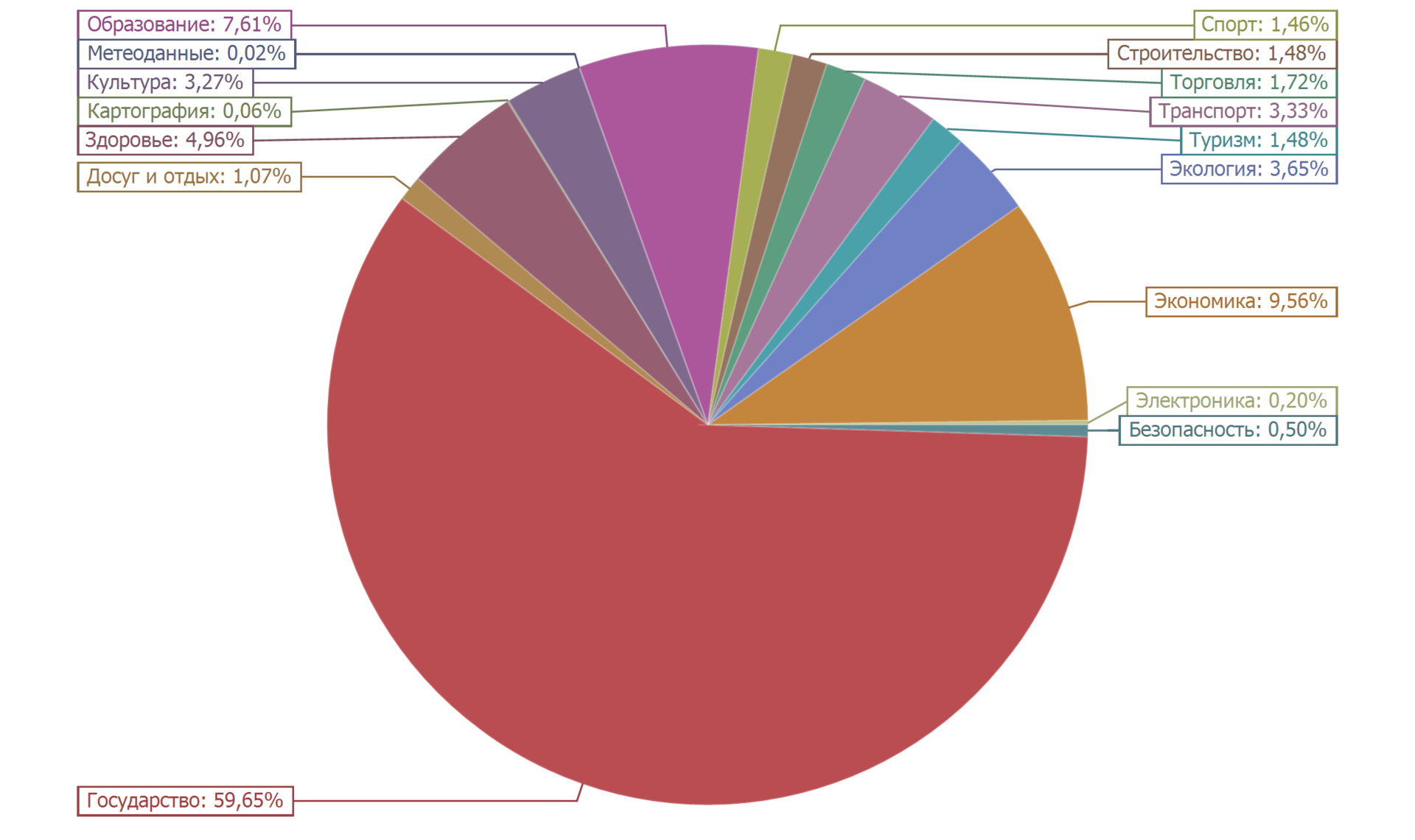
Plus de la moitié des ensembles de données (59,65%) appartiennent à la catégorie «État». Environ dix pour cent (9,56%) appartiennent à la catégorie «Économie». Près de dix pour cent (7,61%) est le nombre d'ensembles de données dans la catégorie Éducation. Le reste est inférieur à cinq pour cent. La distribution est assez naturelle.
Nous élargirons notre connaissance des données publiées sur le portail. Examinons les statistiques de placement sur le portail de données à la date de la première publication de l'ensemble de données.
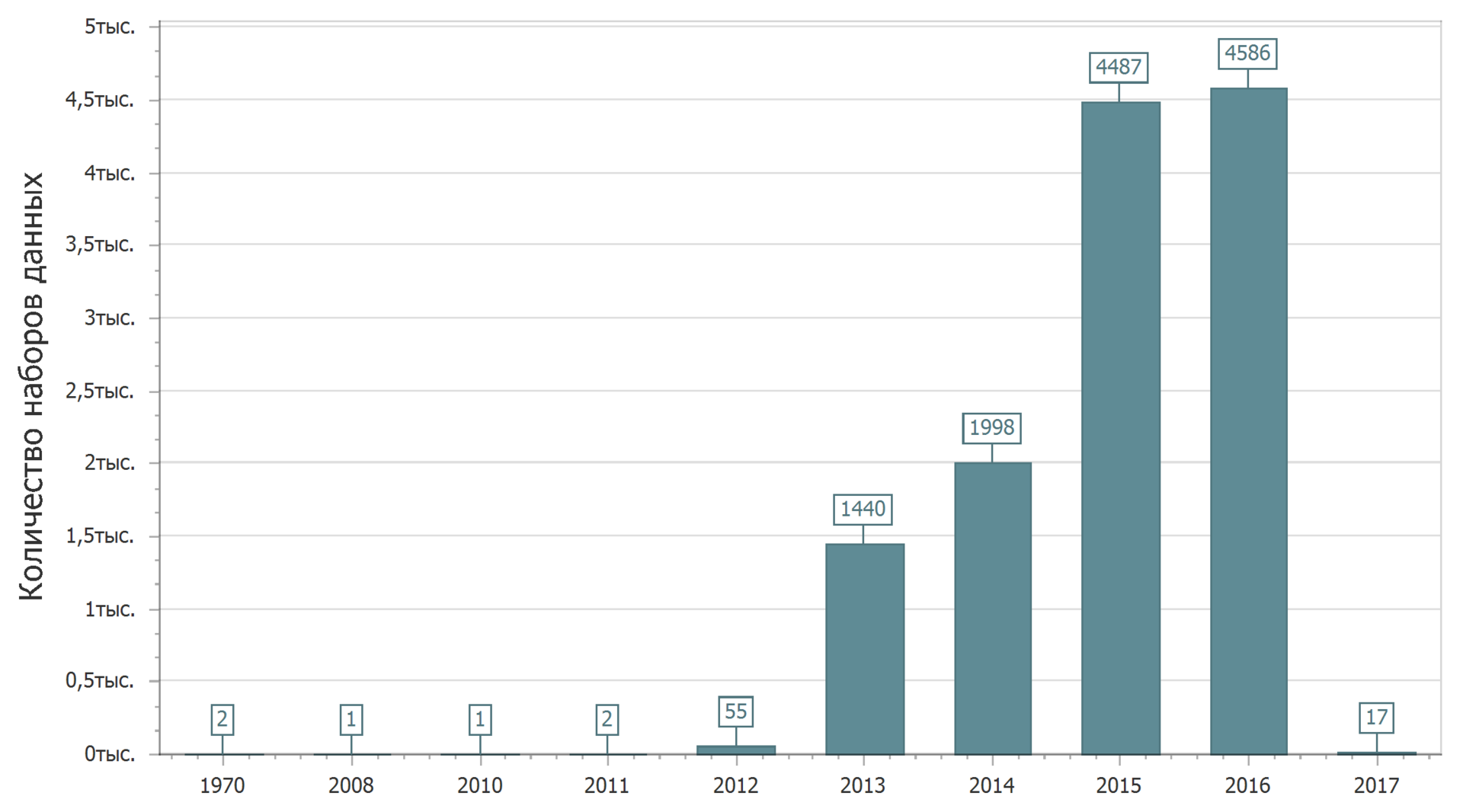
2017 vient de commencer et il est naturel que la quantité de données publiées en 2017 augmente. Oui, pendant que j'écris le texte, de nouveaux ensembles de données sont téléchargés sur le portail.
Apparemment, quelqu'un a réussi à reculer dans le passé, ayant réussi à placer des données dans le lointain 1970.
En général, l'image est claire: d'abord, une forte croissance, puis la stabilité. Bien qu'il soit probablement trop tôt pour parler de stabilité.
Une image intéressante peut être vue si nous considérons la distribution des ensembles de données par date de pertinence (la date après laquelle la version actuelle de l'ensemble de données devrait être mise à jour).
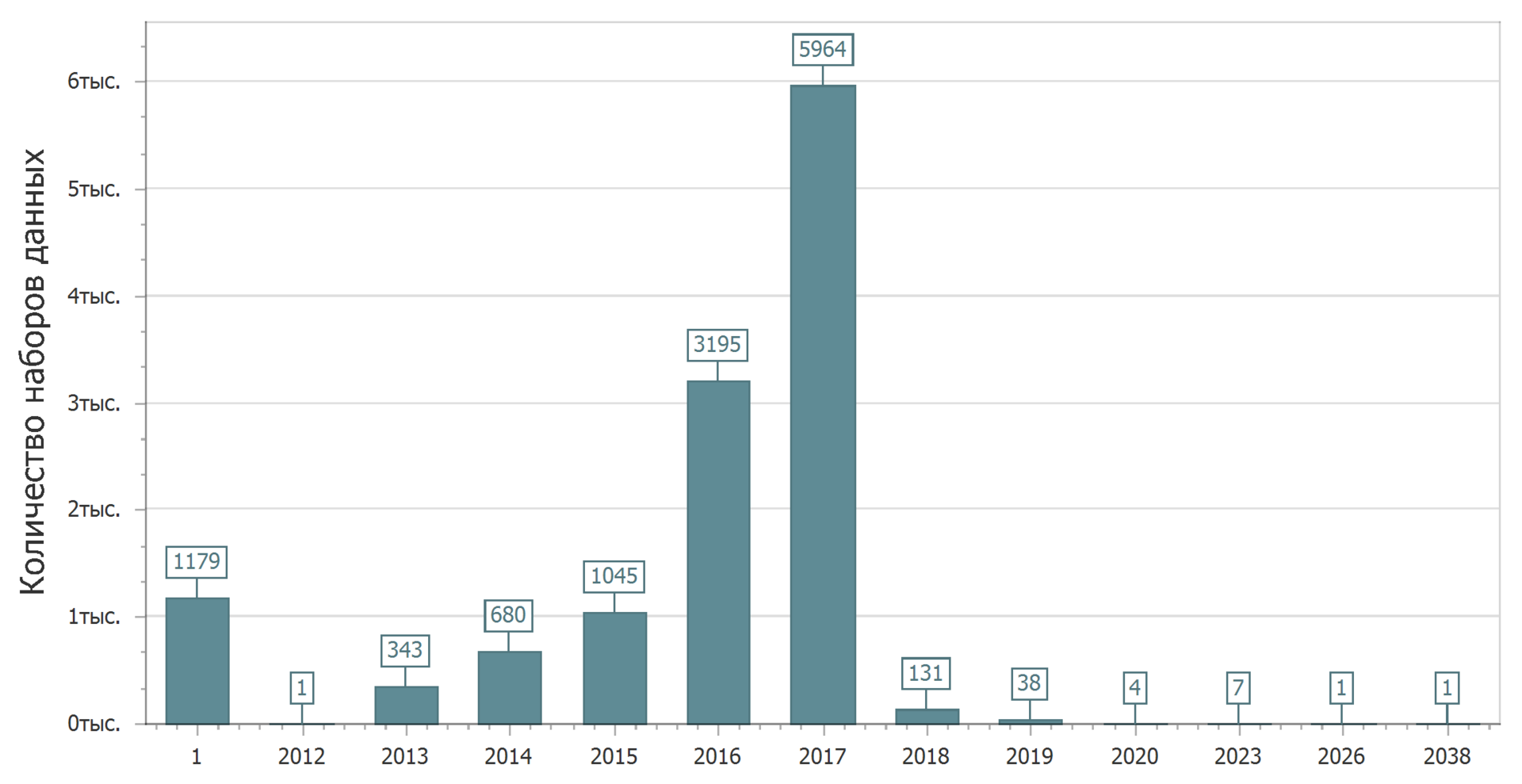
Se précipite immédiatement 1 an. Ainsi, j'ai désigné des ensembles de données qui n'ont pas de date à jour. Sur la base de la détermination de la date de pertinence, nous pouvons conclure qu'il s'agit d'ensembles de données qui n'ont pas du tout besoin d'être mis à jour. Naturellement, ces ensembles de données ont le droit d'exister. Il y a toujours des données d'archives (historiques) qui ne changeront probablement pas (enfin, s'il n'y a pas d'erreurs), et il y a des données actuelles - actuelles qui changent constamment. Ceux-ci et d'autres peuvent être intéressants. Après tout, il arrive que vous ayez besoin de savoir: comment était-ce dans le passé (sous le tsar ou sous le régime soviétique)? Mais, bien sûr, les données réelles (en direct) constamment mises à jour sont plus intéressantes.
Même si vous ne considérez pas le graphique très attentivement, il est clair que certaines données devraient être mises à jour dans un avenir assez lointain. Nous pouvons dire que ceux qui les ont affichés ont une grande confiance dans l'avenir. Les cinq, dix, vingt (?) Prochaines années, ils ne changeront rien. Ou peut-être que c'est juste une erreur? Et c'est possible.
Mais en général, l'image est assez heureuse - près de la moitié des données devraient être mises à jour cette année.
Et maintenant, nous allons confirmer cette image joyeuse. Considérez la distribution des ensembles de données par la date du dernier changement.
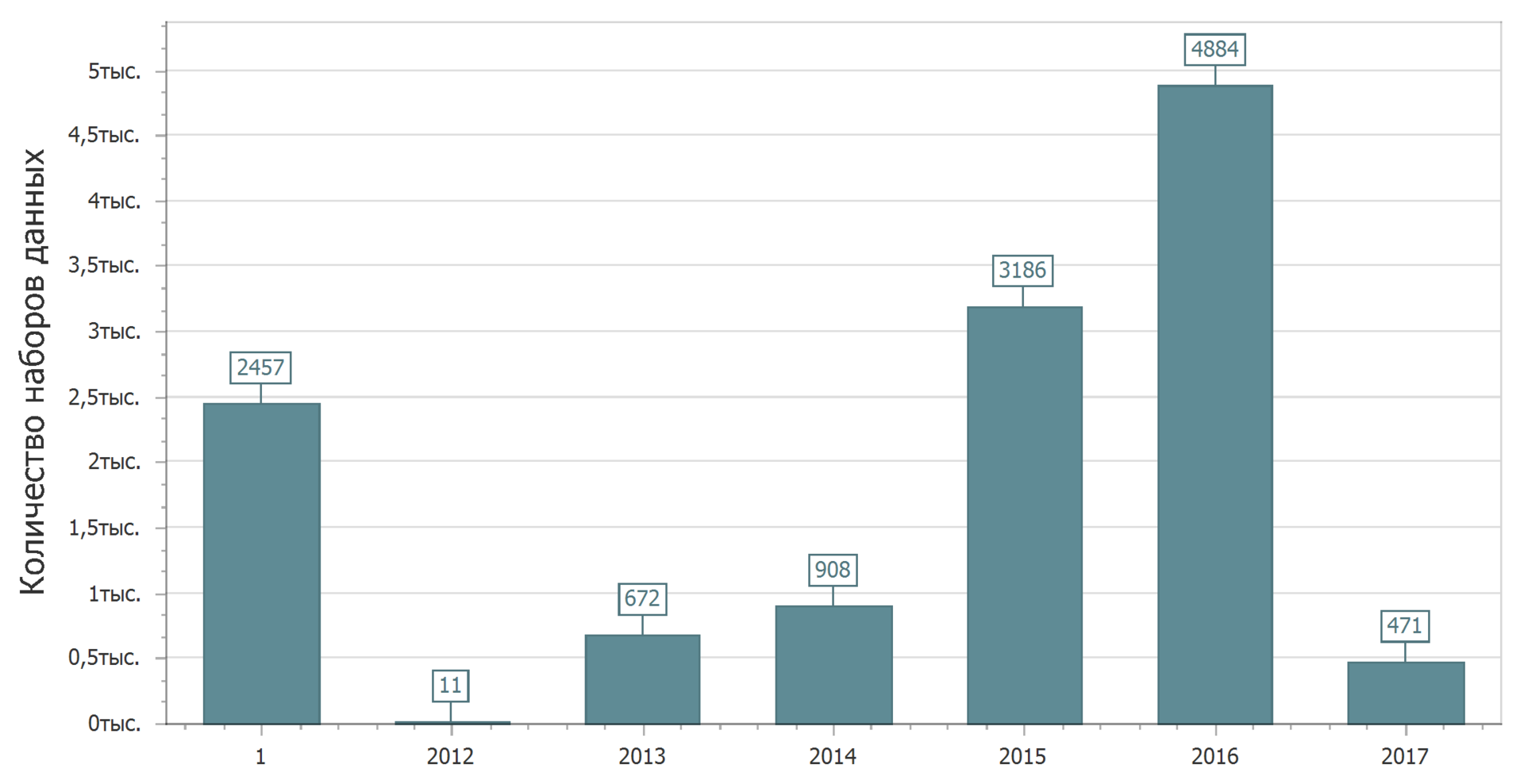
Oui Encore 1 an. Ces jeux de données n'ont pas été modifiés. Je veux juste attraper quelqu'un. Comme, ils ont promis de mettre à jour, mais n'ont apporté aucun changement. Ou ils n'ont pas promis de mettre à jour et mis à jour. Mais la prochaine fois, nous chercherons des modèles (ou leur absence).
Combinez des informations sur la première publication et la dernière mise à jour. Autrement dit, s'il y a eu une mise à jour - prenez la date de mise à jour, s'il n'y a pas eu de mise à jour - prenez la date de la première publication. Le résultat est la date de la dernière modification des données.

La beauté La tendance est clairement visible - plus de la moitié des données ont été modifiées pour la dernière fois ou ont été créées en 2016-2017. Vous pouvez peut-être les considérer comme pertinentes.
Il est nécessaire de noter une mise en garde. Certains ensembles de données sont répétés: le même nom et propriétaire de l'ensemble de données se trouvent plusieurs fois dans le registre.
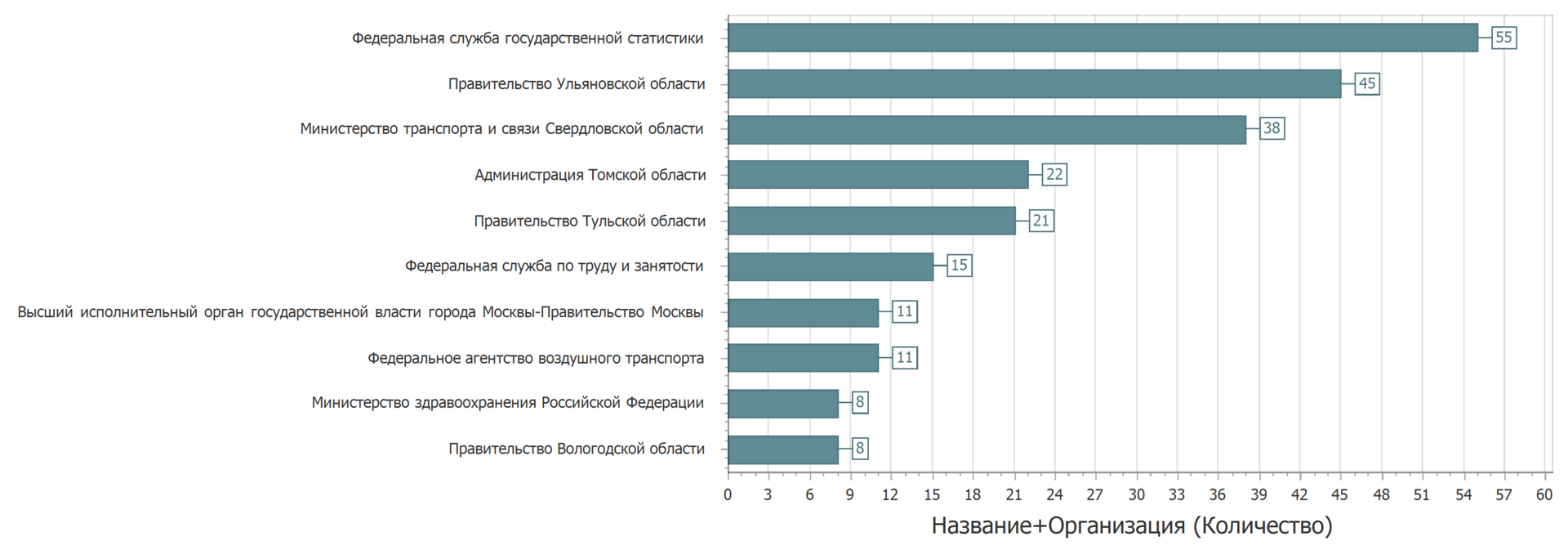
Au lieu de mettre à jour, l'ensemble de données a été à nouveau présenté. Parfois, les décors étaient disposés dans une catégorie différente. Mais si vous regardez des ensembles de données avec le même nom, le même propriétaire et la même catégorie, l'image sera la suivante.
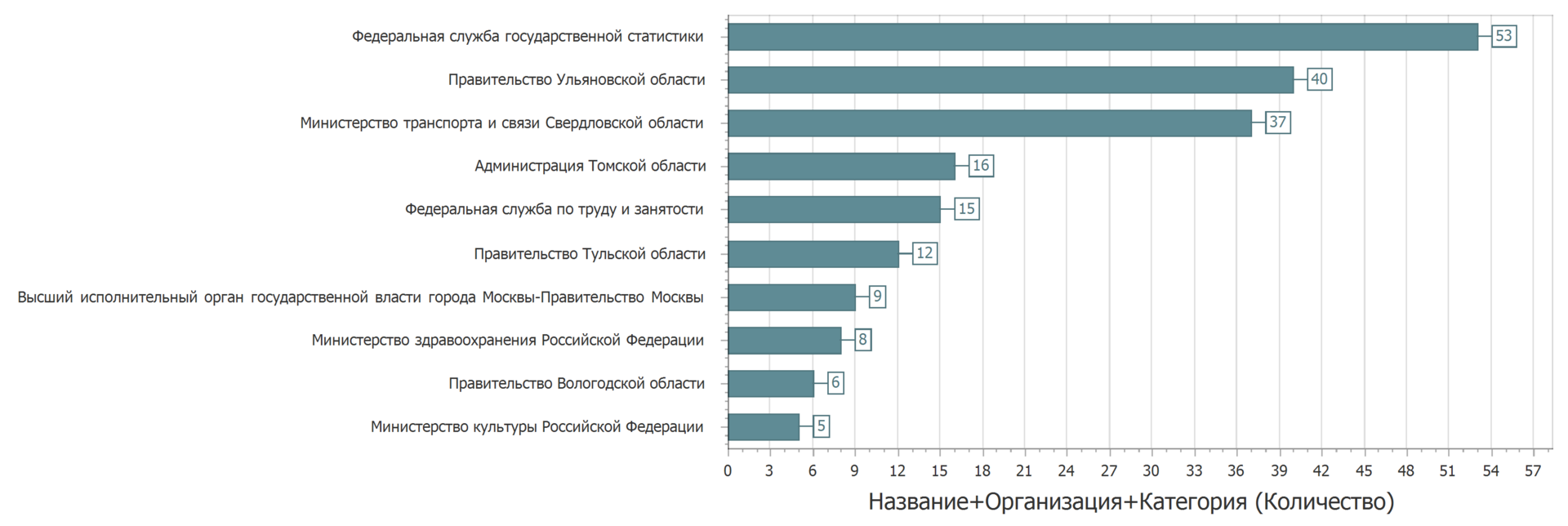
Au moins très similaire. Mais guère critique. Apparemment, certains propriétaires de données doivent diffuser soigneusement les données.
Une petite vérification sur le remplissage des champs de texte dans les ensembles de données de passeports.
| Le terrain | Défini par | Non défini |
|---|
| Le titre | 100% | 0% |
| La description | 80,84% | 19,16% |
| Les catégories | 100% | 0% |
| Le propriétaire | 99,7% | 0,03% |
| Mots clefs | 99,48% | 0,52% |
| Personne responsable | 96,43% | 3,57% |
| Numéro de téléphone de la personne responsable | 96% | 4% |
| Courriel de la personne responsable | 92,68% | 7,32% |
| Format des données | 97,79% | 2,21% |
| Lien de numérotation | 96,86% | 3,14% |
Le nom et la catégorie sont définis partout. Près d'un cinquième des ensembles de données ne contiennent pas de description. Presque partout où le propriétaire est connu et certains mots clés sont définis. La personne responsable est également présente presque partout. On ne sait pas pourquoi nous avons besoin d'ensembles de données qui ne peuvent pas être téléchargés (environ 3%).
Par conséquent, nous divisons tous les ensembles de données en deux catégories: tous les champs sont spécifiés, au moins un champ n'est pas spécifié.

Trente pour cent (30,3%) ont au moins un champ non défini. Dans quel format les données sont-elles téléchargées?
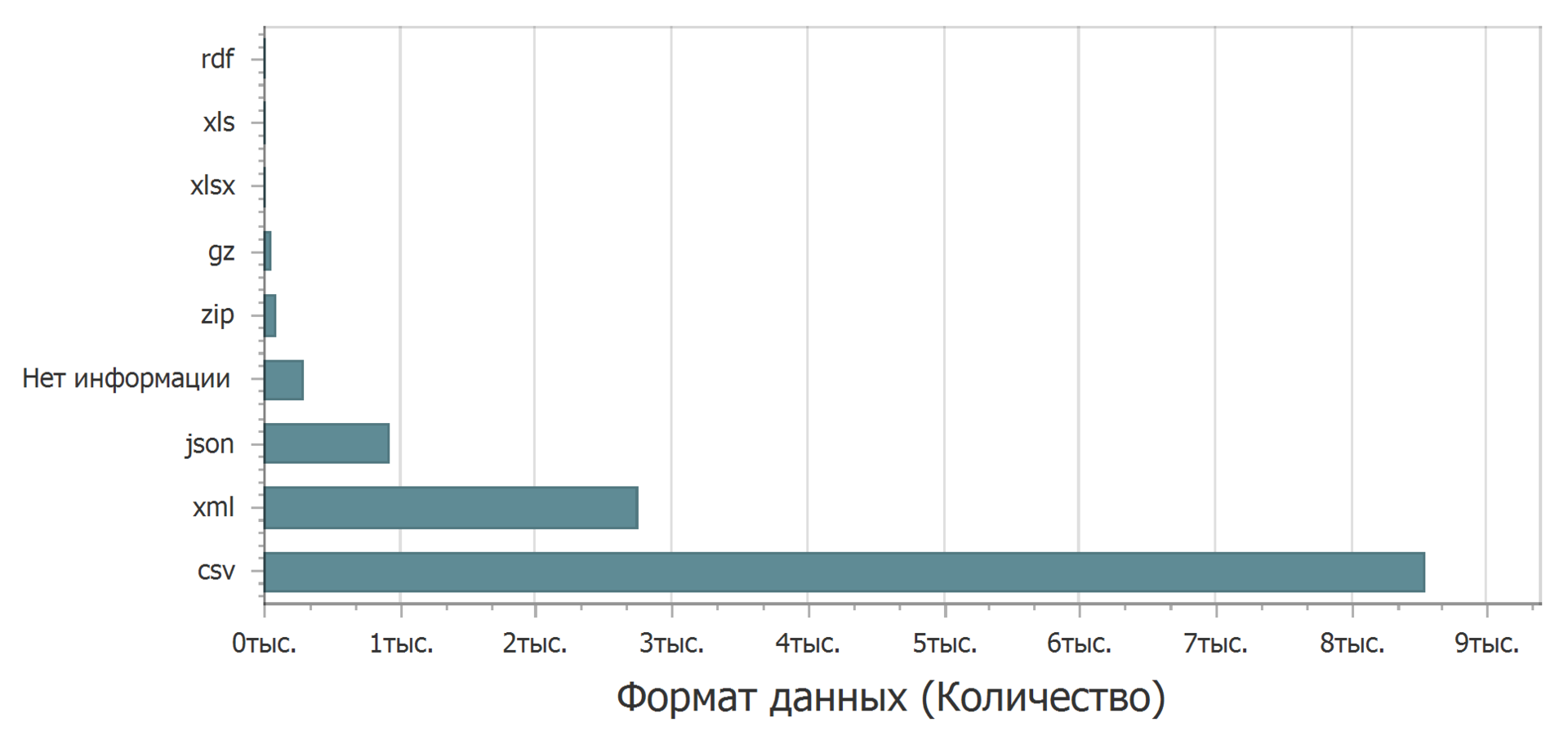
Surtout au format texte délimité (csv). En deuxième place, xml. Le troisième json. Le leader clair est le format csv - vous pouvez l'ouvrir dans n'importe quel éditeur de texte, l'importer presque n'importe où pour le traitement, et avec un petit effort l'insérer sous forme de tableau dans un éditeur de texte. Le format xml est également assez facile à voir. Mais avec le format json, il peut y avoir des problèmes. Si vous vous concentrez sur Excel, en tant qu'éditeur de feuille de calcul le plus couramment utilisé, json est déjà un problème. Vous pouvez google sur ce sujet et trouver un moyen de télécharger, mais pas directement. Excel ne dispose pas d'outils intégrés pour charger json.
Bien sûr, le problème est sans peur, non fatal, mais désagréable. Assurément, ce format arrêtera ou embarrassera quelqu'un.
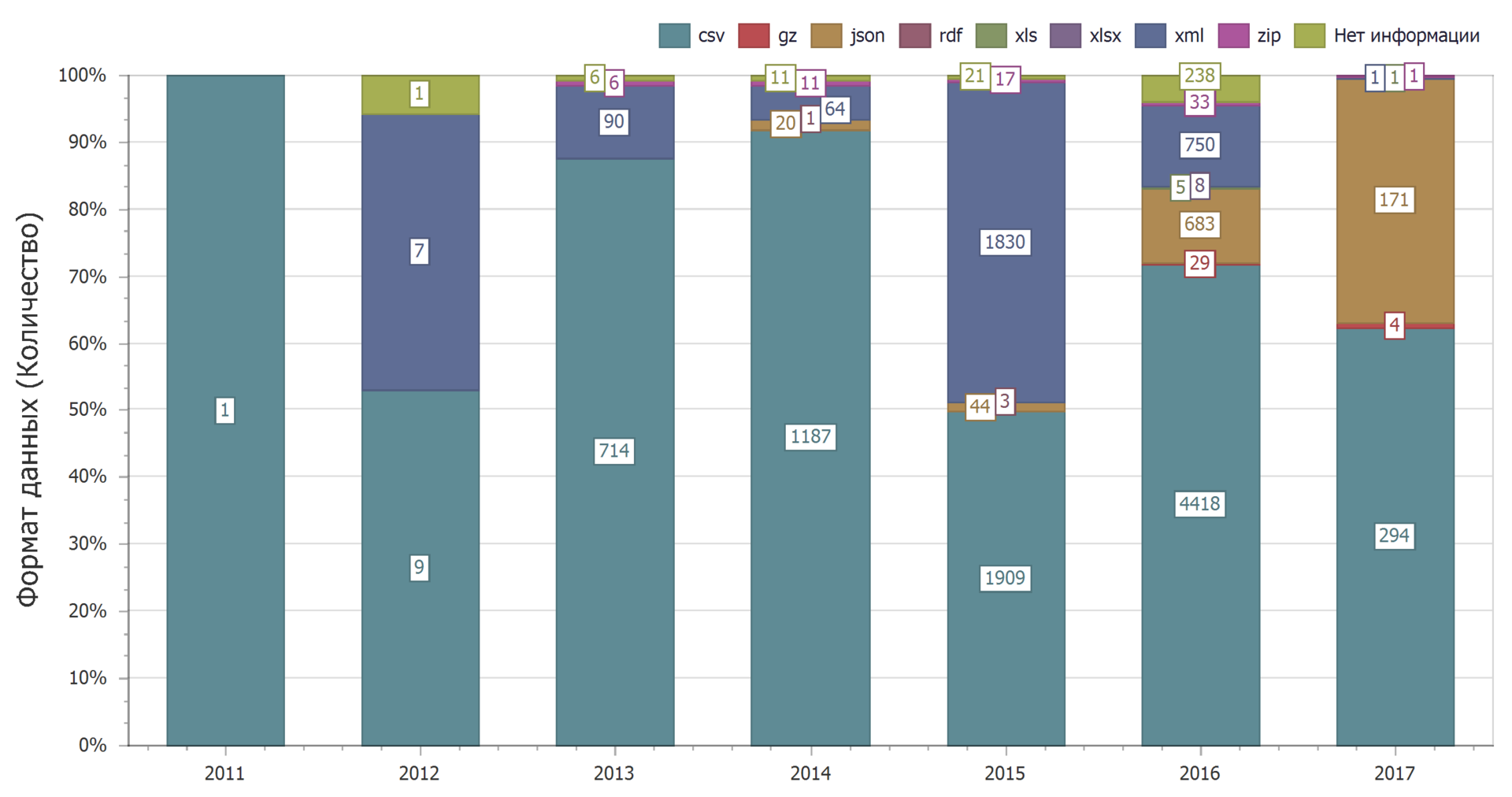
La répartition par années montre qu'au fil du temps, la dominance du format csv persiste.

L'utilisation du format json augmentera considérablement. Cela réduit l'utilisation du format xml.
Et cela peut s'expliquer. Le format csv est le plus simple, il est donc souvent utilisé. Dans le même temps, les services Web utilisent désormais de plus en plus le format json et de moins en moins xml.
Conclusions
Plus de la moitié des données publiées sur le portail russe de données ouvertes appartiennent à la catégorie «État».
Plus de la moitié des données ont été modifiées ou créées pour la dernière fois en 2016-2017.
Trente pour cent des passeports d'ensembles de données ont au moins un champ non attribué.
Les formats les plus courants pour stocker des données ouvertes: csv, xml, json. Dans le même temps, il y a une augmentation du nombre d'ensembles de données au format json et une diminution du nombre d'ensembles de données au format xml.
Et ensuite?
Après avoir analysé les ensembles de données, voyons à quelle fréquence ils sont utilisés - visualisés, téléchargés. Quelles notes les utilisateurs définissent-ils pour les ensembles de données? Quels ensembles de données présentent un intérêt? À quelle fréquence les jeux de données sont-ils mis à jour? Quelle taille de jeux de données? Et y a-t-il une relation entre tout cela?