 Un exemple de réseau neuronal après une formation basée sur des visages de célébrités. À gauche, l'ensemble initial d'images de 8 × 8 pixels à l'entrée du réseau neuronal, au centre est le résultat d'une interpolation jusqu'à 32 × 32 pixels selon la prédiction du modèle. À droite, de vraies photographies de visages de célébrités, réduites à 32 × 32, à partir desquelles des échantillons ont été obtenus pour la colonne de gauche
Un exemple de réseau neuronal après une formation basée sur des visages de célébrités. À gauche, l'ensemble initial d'images de 8 × 8 pixels à l'entrée du réseau neuronal, au centre est le résultat d'une interpolation jusqu'à 32 × 32 pixels selon la prédiction du modèle. À droite, de vraies photographies de visages de célébrités, réduites à 32 × 32, à partir desquelles des échantillons ont été obtenus pour la colonne de gaucheEst-il possible d'augmenter la résolution des photos à l'infini? Est-il possible de générer des images crédibles basées sur 64 pixels? La logique suggère que cela est impossible.
Le nouveau réseau neuronal de Google Brain pense différemment. Cela élève vraiment la résolution des photos à un niveau incroyable.
Une telle «sur-résolution» n'est pas une restauration de l'image originale à partir d'une copie basse résolution. Il s'agit d'une synthèse d'une photographie crédible qui pourrait
probablement être l'image d'origine. Il s'agit d'un processus probabiliste.
Lorsque la tâche consiste à "augmenter la résolution" d'une photographie, mais qu'il n'y a pas de détails pour l'améliorer, la tâche du modèle est de générer l'image la plus plausible d'un point de vue humain. À son tour, il est impossible de générer une image réaliste jusqu'à ce que le modèle ait créé des contours et pris une décision «volontaire» sur les textures, les formes et les motifs qui seront présents dans les différentes parties de l'image.
Par exemple, regardez simplement le KDPV, où dans la colonne de gauche sont de vraies images de test pour le réseau neuronal. Ils manquent de détails sur la peau et les cheveux. Ils ne peuvent en aucun cas être restaurés par des méthodes d'interpolation traditionnelles telles que linéaire ou bicubique. Cependant, si vous avez d'abord une connaissance approfondie de toute la diversité des visages et de leurs contours typiques (et sachant qu'il est nécessaire d'augmenter la résolution du visage ici), alors le réseau neuronal est capable d'accomplir une chose fantastique - et de "dessiner" les détails manquants qui sont le plus susceptibles d'être là.
Des spécialistes de Google Brain ont publié l'article scientifique
Recursive Pixel Super Resolution, qui décrit un modèle entièrement probabiliste formé sur un ensemble de photographies haute résolution et leurs copies réduites de 8 × 8 pour générer des images 32 × 32 à partir de petits échantillons 8 × 8.
Le modèle se compose de deux composants qui sont entraînés simultanément: un réseau neuronal de conditionnement et un réseau antérieur. Le premier superpose efficacement une image basse résolution sur la répartition des images haute résolution correspondantes, et le second modèle des détails haute résolution pour rendre la version finale plus réaliste. Un réseau de neurones climatisé se compose d'unités
ResNet , et le précédent est une architecture
PixelCNN .
Schématiquement, le modèle est représenté dans l'illustration.
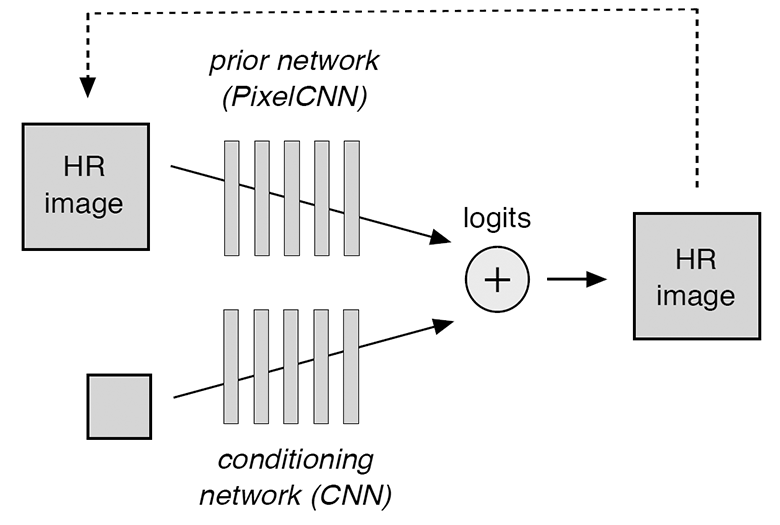
Un réseau neuronal convolutionnel conditionné reçoit des images basse résolution à l'entrée et produit des logits - des valeurs qui prédisent la probabilité logit conditionnelle pour chaque pixel dans une image haute résolution. À son tour, le réseau de neurones convolutif fait des prédictions sur la base de prédictions aléatoires précédentes (indiquées par une ligne pointillée sur le diagramme). La distribution de probabilité pour l'ensemble du modèle est calculée comme un opérateur softmax en plus de la somme de deux ensembles de logits d'un réseau neuronal conditionné et antérieur.
Mais comment évaluer la qualité d'un tel réseau? Les auteurs des travaux scientifiques sont parvenus à la conclusion que des mesures standard telles que le rapport signal / bruit de crête (pSNR) et la similitude structurelle (SSIM) ne sont pas en mesure d'évaluer correctement la qualité de la prédiction pour de tels problèmes d'augmentation ultra-forte de la résolution. Selon ces métriques, il s'avère que le meilleur résultat est des images floues, pas des images photoréalistes dans lesquelles des détails clairs et crédibles ne coïncident pas au lieu de placement avec les détails clairs de l'image réelle. Autrement dit, ces métriques pSNR et SSIM sont extrêmement conservatrices. Des études ont montré que les gens peuvent facilement distinguer les vraies photos des options floues créées par les méthodes de régression, mais il n'est pas si facile pour eux de distinguer les échantillons générés par un réseau de neurones des vraies photos.
Voyons quels résultats le modèle développé par Google Brain et formé sur un ensemble de 200 000 visages de célébrités (ensemble de photos CelebA) et 2 000 000 de chambres (ensemble de photos LSUN Bedrooms) montre. Dans tous les cas, les photos avant l'entraînement du système ont été réduites à une taille de 32 × 32 pixels, puis à nouveau à 8 × 8 en utilisant la méthode d'interpolation bicubique. Les réseaux de neurones TensorFlow formés sur 8 GPU.
Les résultats ont été comparés sur deux bases principales: 1) régression pixel par pixel indépendante (régression) avec une architecture similaire au réseau neuronal
SRResNet , qui montre des résultats exceptionnels sur des métriques standard pour évaluer la qualité de l'interpolation; 2) rechercher l'élément voisin le plus proche (NN), qui recherche dans la base de données des échantillons éducatifs à basse résolution l'image la plus similaire par la proximité des pixels dans l'espace euclidien, puis renvoie l'image haute résolution correspondante à partir de laquelle cet échantillon éducatif a été généré.
Il convient de noter que le modèle probabiliste produit des résultats de qualité différente, en fonction de la température softmax. Il a été établi manuellement que les valeurs optimales
se situent entre 1,1 et 1,3. Mais même si vous installez
de toute façon, les résultats seront différents à chaque fois.
 Résultats différents lors du démarrage d'un modèle avec une température softmax
Résultats différents lors du démarrage d'un modèle avec une température softmax Vous pouvez évaluer la qualité du travail du modèle probabiliste par les échantillons sous le becquet.
Comparaison des résultats des chambres Comparaison des résultats des visages de célébrités Pour vérifier le réalisme des résultats, les scientifiques ont mené une enquête sur le crowdsourcing. On a montré aux participants deux photographies: une réelle et la seconde générée par diverses méthodes à partir d'une copie réduite de 8 × 8 et invité à indiquer quelle photographie a été prise par l'appareil photo.
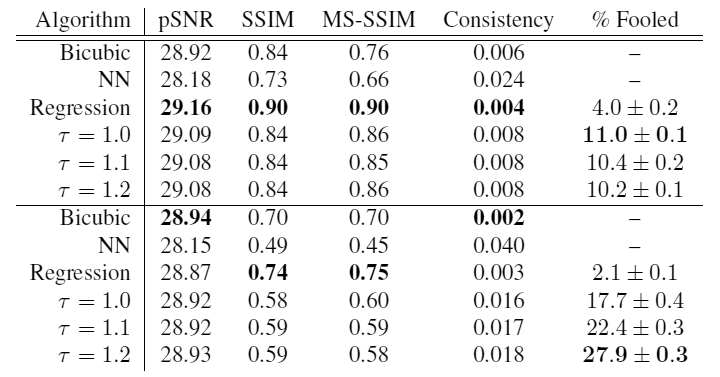
En haut du tableau, les résultats pour la base des célébrités et en dessous pour les chambres. Comme vous pouvez le voir, à température
dans les photographies des chambres, le modèle a montré le résultat maximum: dans 27,9% des cas, sa livraison s'est avérée plus réaliste que l'image réelle! C'est un succès évident.
L'illustration ci-dessous montre le travail le plus réussi du réseau neuronal, dans lequel il «bat» les originaux en termes de réalisme. Pour l'objectivité - et certains des pires.

Dans le domaine de la génération d'images photoréalistes à l'aide de réseaux de neurones, un développement très rapide est désormais observé. En 2017, nous allons certainement entendre beaucoup de nouvelles sur ce sujet.