
Malgré l'existence d'obstacles et de difficultés évidents qui entravent parfois le développement et la mise en œuvre de produits de génie génétique (IG), le 21e siècle ne peut être imaginé sans les fruits de cette technologie importante et diversifiée dans l'arsenal d'un biologiste moderne. L'organisme le plus couramment utilisé en GI est la bactérie.
Qu'est-ce que l'IG et pourquoi en avons-nous besoin? Pourquoi les bactéries sont-elles si populaires auprès des ingénieurs génétiques? Sous quelle forme est le moyen le plus simple d'introduire le gène souhaité dans la bactérie? Quelles difficultés peut-on rencontrer en travaillant avec ces organismes? Que s'est-il passé avant: la création de la première bactérie génétiquement modifiée ou la découverte de la structure de l'ADN et du génome? Lisez à ce sujet et bien plus encore sous le chat.
0. Bref programme éducatif en biologie
Ce paragraphe fournit une brève description du soi-disant
dogme central de la biologie moléculaire . Si vous avez des connaissances de base en biologie moléculaire, n'hésitez pas à passer à l'étape 1.
 Le dogme central de la biologie moléculaire en une seule image
Le dogme central de la biologie moléculaire en une seule imageCommençons donc. Toutes les informations sur tous les stades de développement et les propriétés de tout organisme, qu'il s'agisse de
procaryotes (bactéries), d'
archées ou d'
eucaryotes (tous les autres sont uniques et multicellulaires), sont codées dans l'ADN génomique, qui est un complexe de deux chaînes polynucléotidiques complémentaires l'une de l'autre, formant une double hélice ( nucléotides d'ADN complémentaires: AT et GC). Les chromosomes eucaryotes sont des molécules d'ADN double brin linéaires et les chromosomes procaryotes sont bouclés. Souvent, les gènes ne constituent qu'une petite partie de l'ensemble du génome (chez l'homme - environ 1,5%).
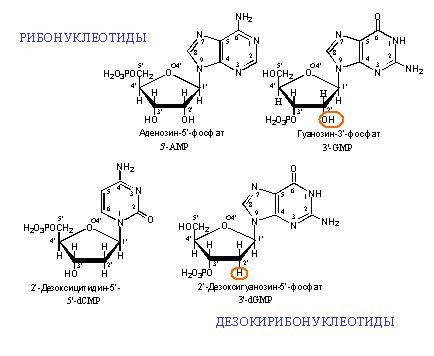 Exemples de monomères d'ADN et d'ARN. "Désoxy" dans le nom d'ADN signifie l'absence d'un atome d'oxygène en position 2 '(sur la figure, la position 2' est entourée en rouge).
Exemples de monomères d'ADN et d'ARN. "Désoxy" dans le nom d'ADN signifie l'absence d'un atome d'oxygène en position 2 '(sur la figure, la position 2' est entourée en rouge).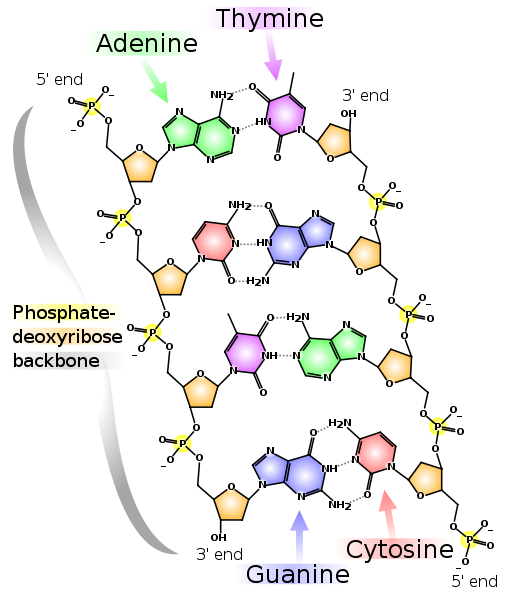 Deux brins d'ADN complémentaires. Les lignes pointillées montrent les liaisons hydrogène entre les bases. Comme on peut le voir, l'adénine et la thymine forment deux liaisons hydrogène entre elles, et la guanine et la cytosine en forment trois. Par conséquent, la liaison GC est plus forte et les sections riches en GC d'ADN double brin sont plus difficiles à séparer en deux chaînes.
Deux brins d'ADN complémentaires. Les lignes pointillées montrent les liaisons hydrogène entre les bases. Comme on peut le voir, l'adénine et la thymine forment deux liaisons hydrogène entre elles, et la guanine et la cytosine en forment trois. Par conséquent, la liaison GC est plus forte et les sections riches en GC d'ADN double brin sont plus difficiles à séparer en deux chaînes.Notez que chacune des chaînes a une extrémité 5 'et une extrémité 3'. On peut voir que près de l'extrémité 5 'de la chaîne gauche se trouve l'extrémité 3' de la droite et vice versa, donc les chaînes sont appelées "antiparallèles". L'ARN a également une extrémité 5 'et 3'. Les positions 5 'et 3' elles-mêmes ont été choisies pour indiquer le début et la fin car c'est à travers elles que se forment les liaisons covalentes dans les chaînes d'ADN et d'ARN.
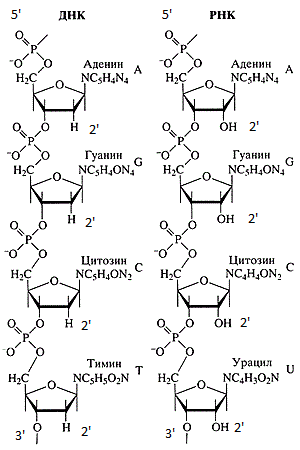 Chaînes d'ADN et d'ARN.
Chaînes d'ADN et d'ARN.Les séquences d'ADN et d'ARN sont toujours enregistrées de l'extrémité 5 'à l'extrémité 3'. Il y a plusieurs raisons:
- La synthèse de nouvelles chaînes d'ADN et d'ARN commence à l'extrémité 5 '( ADN polymérase (enzymes synthétisant une chaîne d'ADN complémentaire sur une matrice d'ADN ou d'ARN) et ARN polymérase (enzymes synthétisant une chaîne d'ARN complémentaire sur une matrice d'ADN ou d'ARN) direction 3 '-> 5', donc une nouvelle chaîne est synthétisée dans la direction 5 '-> 3');
- Le ribosome lit les codons, se déplaçant le long de l'ARNm dans la direction de 5 '-> 3';
- La séquence d'acides aminés est écrite dans la chaîne de codage de l'ADN dans le sens 5 '-> 3' (une partie importante de l'ARNm est une copie exacte de la région codante de l'ADN avec de la thymine remplacée par de l'uracile et avec un groupe hydroxyle (-OH) au lieu de l'hydrogène en position 2 ', bien sûr);
- Enfin, il est tout simplement pratique d'avoir une règle d'enregistrement généralement acceptée.
Un gène est une partie de l'ADN génomique qui définit la séquence de nucléotides d'une molécule d'ARN:
- ARN codant: ARN messager (ARNm), dans lequel la séquence d'acides aminés de la protéine correspondante est codée sous forme de codons. Vous pouvez également trouver le nom "ARN informationnel", puis l'abréviation ressemble à "ARNm";
- ARN non codant: ARN de transport, ARN ribosomal et autres.
Le rôle de l'ARNt est de fournir des acides aminés au complexe ARNm-ribosome. De plus, c'est l'ARNt qui est responsable de la reconnaissance des codons d'ARNm, pour cela, chaque ARNt comprend ce qu'on appelle l '«anticodon» - un triplet complémentaire du codon d'ARNm.
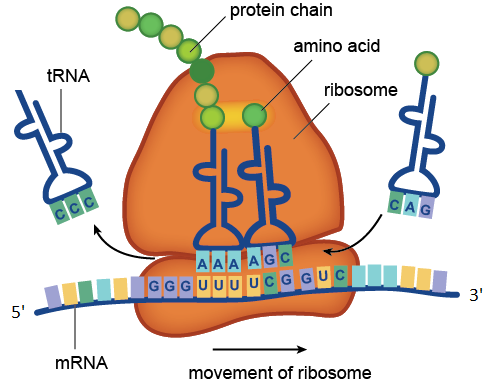 Le processus de traduction catalysé par le ribosome. Sur la figure, les codons UUU et UCG contenus dans l'ARNm sont reconnus par les anticodons AAA et AGC contenus dans les molécules d'ARNt. L'ARN de transport avec anticodon CCC a déjà donné son acide aminé à la chaîne protéique en croissance, et l'ARNt avec anticodon CAG attend en ligne. Le tracé de la molécule d'ARNm montré sur la figure se compose de quatre codons: GGGUUUUCGGUC. Le codon GGG correspond à l'acide aminé glycine, UUU à la phénylalanine, UCG à la sérine, GUC à la valine. Ainsi, cette région d'ARNm code pour un fragment de protéine avec la séquence d'acides aminés glycine-phénylalanine-sérine-valine.
Le processus de traduction catalysé par le ribosome. Sur la figure, les codons UUU et UCG contenus dans l'ARNm sont reconnus par les anticodons AAA et AGC contenus dans les molécules d'ARNt. L'ARN de transport avec anticodon CCC a déjà donné son acide aminé à la chaîne protéique en croissance, et l'ARNt avec anticodon CAG attend en ligne. Le tracé de la molécule d'ARNm montré sur la figure se compose de quatre codons: GGGUUUUCGGUC. Le codon GGG correspond à l'acide aminé glycine, UUU à la phénylalanine, UCG à la sérine, GUC à la valine. Ainsi, cette région d'ARNm code pour un fragment de protéine avec la séquence d'acides aminés glycine-phénylalanine-sérine-valine.Les ARN ribosomaux sont des composants indispensables du ribosome. La fonction principale de l'ARNr est d'assurer le processus de traduction: il est impliqué dans la lecture des informations de l'ARNm en utilisant des molécules adaptatrices d'ARNt et en catalysant la formation de liaisons peptidiques entre les acides aminés attachés à l'ARNt et la chaîne protéique en croissance.
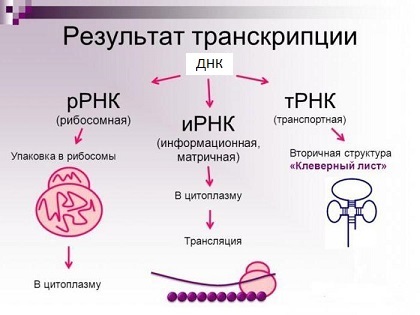 Les principaux types de molécules d'ARN (en fait, il y en a beaucoup plus).
Les principaux types de molécules d'ARN (en fait, il y en a beaucoup plus).Une protéine, d'autre part, est une chaîne d'acides aminés liés de manière covalente via une liaison peptidique (vous pouvez voir un peu plus à quoi elle ressemble dans le spoiler). Après la synthèse, la chaîne d'acides aminés devrait prendre une certaine structure spatiale - la «
conformation » (
ils m'ont déjà parlé de la structure spatiale des protéines
chez Geektimes ). En outre, de nombreuses protéines de grande taille sont en fait constituées de plusieurs protéines combinées par des interactions hydrophobes et des liaisons hydrogène en une seule structure stable. Dans ce cas, chacune des «protéines de construction» est appelée une «sous-unité», et la grosse protéine résultante est appelée une «multi-sous-unité».
20 acides aminés qui composent les protéines  Complexe ribosomal. La photo a été prise à partir de la publication OlegKovalevskiy «Impression 3D de modèles de molécules de protéines» .
Complexe ribosomal. La photo a été prise à partir de la publication OlegKovalevskiy «Impression 3D de modèles de molécules de protéines» .Dans le cas des gènes codant pour une protéine, le processus de décodage des informations génétiques ressemble à ceci:
- L'ARN polymérase reconnaît le promoteur et s'y lie (s'il est «ouvert», nous discuterons plus loin de la régulation de l'activité du promoteur);
- Sur la matrice d'ADN, l'enzyme ARN polymérase, selon le principe de complémentarité, synthétise le «blanc» de l'ARN matriciel (pré-ARNm, chez les eucaryotes) ou de l'ARNm fonctionnel prêt à l'emploi (chez les procaryotes). Ce processus est appelé «transcription» ;
- (uniquement chez les eucaryotes) La molécule pré-ARNm subit des modifications («mûrit») et devient un ARNm fonctionnel;
- L'ARNm est reconnu par le ribosome , une enzyme qui décode le code triplet de l'ARNm et, sur cette base, synthétise un peptide / protéine. Les acides aminés à partir desquels le ribosome construit la protéine sont délivrés en complexe avec l'ARN de transport ( ARNt ). Ce processus est appelé «diffusion» ;
- Le peptide / protéine peut subir des modifications post-traductionnelles ("maturation" par analogie avec l'ARNm) et devient fonctionnel. Un facteur important est que le système de modification post-traductionnelle des eucaryotes est beaucoup plus complexe et diversifié que celui des procaryotes, par conséquent, toutes les protéines eucaryotes ne peuvent pas être correctement synthétisées par une bactérie.
En plus des régions codantes, le génome contient de nombreux fragments qui participent également à la transcription d'une manière ou d'une autre. Les parcelles situées à proximité du gène et appelées promoteurs sont reconnues par les ARN polymérases (elles disent que le gène est sous le contrôle de ce promoteur). Différents promoteurs sont reconnus par différentes ARN polymérases. Par exemple, un gène sous le contrôle d'un promoteur de
bactériophage ne sera pas transcrit en bactérie si l'ARN polymérase du bactériophage correspondant n'y est pas synthétisée.
Généralement .
Chaque gène peut également avoir plusieurs séquences régulatrices, qui peuvent être situées soit directement près du promoteur (ou même se chevaucher avec lui), soit à une distance de dizaines de milliers de paires de nucléotides de celui-ci. Les éléments améliorant la transcription sont appelés
«amplificateurs», les éléments supprimant la transcription sont appelés silencieux, et les protéines qui interagissent avec eux sont appelées
facteurs de transcription . Bien qu'il soit également habituel d'appeler des facteurs de transcription les composants nécessaires du complexe d'initiation de la transcription, sans lesquels la transcription est en principe impossible. Le fait est que pour commencer la synthèse de la molécule d'ARN sur la matrice d'ADN chez les eucaryotes et les archées, l'assemblage de l'ensemble du complexe supramoléculaire est nécessaire. Le complexe le plus simple comprend l'holoenzyme d'ARN polymérase et six soi-disant
«facteurs de transcription communs» (TFIIA, TFIIB, TFIID, TFIIE, TFIIF et TFIIH). Le complexe lui-même est appelé
«complexe de préinitiation de la transcription» (
vidéo , chaque composant du complexe est mis en évidence dans une couleur ou une autre).
Le complexe de transcription procaryote est complètement différent, il est donc inutile d'intégrer le gène eucaryote avec le promoteur eucaryote dans la bactérie. Un analogue procaryote des facteurs de transcription communs des eucaryotes et des archées peut être appelé une protéine appelée
"facteur sigma" .
 Complexe transcriptionnel procaryote. Les lettres montrées sur la figure sont des désignations généralement acceptées des sous-unités correspondantes. σ70 - Facteur sigma des gènes domestiques d' E. coli
Complexe transcriptionnel procaryote. Les lettres montrées sur la figure sont des désignations généralement acceptées des sous-unités correspondantes. σ70 - Facteur sigma des gènes domestiques d' E. coliLes génomes des procaryotes et des eucaryotes ont de nombreuses caractéristiques en commun, et le dogme central de biologie moléculaire, mentionné plus haut, est vrai pour les deux règnes. Cependant, il existe également de nombreuses différences importantes. Par exemple, une bactérie est caractérisée par un système d'opérons - des gènes regroupés qui participent au même processus et ne sont pas transcrits séparément, mais comme faisant partie d'un long ARNm. Chez les eucaryotes, tout est complètement différent: les gènes impliqués dans un processus sont dispersés sur différents chromosomes, et les gènes eux-mêmes sont divisés en fragments codants
d'exons par des régions non codantes
d'introns . Dans ce cas, au début, le gène est complètement transcrit, puis, déjà au stade de l'ARN, les introns sont excisés et les exons se réticulent pour former l'ARNm codant. Ce processus est appelé
épissage . Dans le même temps, tous les exons disponibles ne peuvent pas être cousus dans l'ARNm fini, mais seulement une partie d'entre eux, dans ce cas, parle d '
«épissage alternatif» . Ainsi, une cellule eucaryote peut synthétiser plusieurs protéines, tout en transcrivant le même gène. Entre autres choses, cela donne une conséquence très importante: il est souvent insensé d'insérer le gène eucaryote dans la bactérie «comme il l'est dans le chromosome», car la bactérie n'est tout simplement pas capable d'épissage.
Il y a une autre différence importante. Les procaryotes sont caractérisés par la présence de matériel génétique à base d'ADN à l'extérieur du "chromosome" du cycle, les soi-disant
"plasmides" - petites molécules d'ADN circulaires double brin. De plus, les procaryotes manquent d'organites, y compris le noyau: tous les composants d'une cellule bactérienne sont libres de voyager à travers l'espace intracellulaire. Les eucaryotes, cependant, n'ont pas de plasmides, mais il y a des
plastides et des
mitochondries dans le génome dont les plasmides sont inclus (selon l'hypothèse la plus étayée, les plastes et les mitochondries sont des «descendants» de l'architecture procaryote du génome des cyanobactéries et des bactéries piégées à l'intérieur par d'anciens proto-eucaryotes unicellulaires). De plus, la présence d'un noyau et d'autres compartiments intracellulaires entourés de sa propre membrane est déjà typique des eucaryotes. Par conséquent, le génie génétique des cellules eucaryotes nécessite des approches différentes de celles du génie génétique des bactéries.
Le code génétique lui-même est structuré comme suit. Chaque gène / exon se compose d'un ensemble de triplets / codons - séquences de trois nucléotides entre lesquelles il n'y a pas de lacunes. L'organisation en triplets est valable à la fois pour les gènes de l'ADN et pour la partie codante de l'ARNm. En cours de traduction, les ARN de transport (ARNt) portant un acide aminé spécifique «reconnaissent» leurs triplets correspondants à trois lettres. Le ribosome déconnecte l'acide aminé de l'ARNt et l'attache à la chaîne d'acides aminés en croissance, qui à la fin de la traduction deviendra immédiatement une protéine mature pleinement fonctionnelle ou avant de subir en outre une série de modifications. Dans ce cas, un seul acide aminé correspond à chaque triplet, mais plusieurs codons différents peuvent correspondre à un acide aminé. Cela est compréhensible, car dans le code génétique standard, il y a 61 codons codants, et il n'y a
que 20 acides aminés protéinogéniques (le nombre total de codons, bien sûr, 4 * 4 * 4 = 64, mais trois d'entre eux sont non codants, ils servent plutôt de signal pour arrêter la traduction et sont appelés " arrêter les codons »).
 Codons dans le code génétique standard. Merci à Wikipedia pour la photo.
Codons dans le code génétique standard. Merci à Wikipedia pour la photo.Ainsi, les protéines sont précisément ces mêmes éléments qui sont le dernier maillon de la chaîne entre l'ADN génomique et les propriétés de l'organisme, le soi-disant
«phénotype» . Par conséquent, afin de changer en quelque sorte les caractéristiques de l'organisme qui sont importantes pour nous, nous devons changer son ADN de telle sorte que, par conséquent, certaines protéines apparaissent dans ses cellules, ce qui nous fournira le résultat cible. C'est l'idée de base de tout génie génétique.
1) À quelles fins les bactéries sont-elles utilisées en génie génétique et pourquoi
Nous avons donc compris comment et pourquoi la séquence d'ADN génomique affecte les propriétés et les caractéristiques du corps. Bien sûr, ce sera très bien si le trait est complètement déterminé par un seul gène - l'insertion d'un petit fragment n'est plus un problème grave. Par exemple, la résistance d'une plante à un herbicide ou à un ravageur est souvent déterminée par un seul gène, il n'est donc pas difficile de créer des variétés présentant la résistance souhaitée dans ce cas (par opposition à la mise sur le marché d'une telle plante). Il en va de même pour de nombreuses résistances aux bactéries des antibiotiques (en fait, les bactéries ont de nombreux mécanismes de protection contre les antibiotiques, mais elles fonctionnent de manière indépendante). L'exemple opposé est, par exemple, une tentative des scientifiques d'enseigner aux plantes à absorber l'azote de l'atmosphère. Le fait est que la seule source d'azote pour les plantes est le sol dans lequel les composés azotés pouvant être assimilés par la plante sont synthétisés par des micro-organismes (ou introduits comme engrais par un jardinier attentionné ou un chien de passage). Évidemment, la création d'une plante avec un mécanisme nutritionnel alternatif serait très bénéfique pour l'agriculture. Mais, malheureusement, ce processus est si compliqué que le problème de son "transfert" du micro-organisme à la plante n'a pas été résolu jusqu'à présent.
Enfin, si notre objectif est d'obtenir des protéines dans un but spécifique (étudier la structure et les fonctions de la protéine, créer des préparations médicales ou des réactifs de laboratoire à partir de celle-ci, etc.), alors, évidemment, nous sommes également très satisfaits de l'intégration d'un seul gène dans la cellule, qui dans ce cas, il est d'usage d'appeler "organisme producteur".
Une bactérie en génie génétique est un matériau source potentiel pour créer:
- un producteur de la protéine dont nous avons besoin à l'échelle du laboratoire ou de l'industrie;
- agent actif dans une certaine transformation chimique d'un composé en un autre, qu'il s'agisse d'un processus de fermentation dans l'industrie alimentaire, de la création de conditions plus favorables à la croissance des plantes par l'introduction d'un «producteur d'engrais bactérien» dans le sol ou l'élimination des ferrailles d'acier;
- klonotek des gènes (un sujet, dont une bonne description augmentera la taille de l'article à l'indécence);
- un médicament médicalement important, par exemple, pour restaurer la microflore du tube digestif;
- souches bactériennes d' Agrobacterium tumefaciens pour une modification génétique ultérieure des plantes.
* Je pourrais oublier quelque chose, donc les ajouts dans les commentaires sont les bienvenus.
Un fait intéressant est que les premières expériences réussies dans le domaine du génie génétique des bactéries ont eu lieu bien avant les travaux marquants de Watson et Crick. De plus, sur la base de ces expériences, le fait même que l'information est contenue dans l'ADN a été prouvé, après quoi les scientifiques n'ont pas pu consacrer leur temps à des hypothèses sur l'ARN et les protéines.
Ce travail, mené en 1944, est connu sous le nom d'
expérience Avery, MacLeod et McCarthy , d'après les
travaux de Frederick Griffith , au cours desquels il a été constaté que l'infection de souches de pneumocoques pathogènes et non pathogènes vivantes tuées provoque le développement de la maladie, tandis que individuellement, ils ne provoquent pas de symptômes significatifs. De cette expérience, il a été conclu qu'une bactérie tuée est capable de transmettre quelque chose à un «collègue» non pathogène, ce qui la rend dangereuse. Mais que se transmettent-ils? En 1944, il y avait trois candidats principaux: l'ADN, l'ARN et les protéines. Afin d'établir le support, une expérience élégante a été réalisée: à cette époque, des enzymes capables de détruire séparément l'ADN (DNase), séparément l'ARN (RNase) et séparément les protéines (protéinase) étaient déjà disponibles. Il a été montré que le transfert des propriétés pathogènes ne se produisait pas seulement dans les cas où la préparation d'une souche pathogène morte était traitée avec la DNase et ne dépendait pas du traitement du médicament avec la RNase et la protéinase.
Ainsi, il a été prouvé que l'ADN est porteur d'informations sur les signes. De plus, il a été clairement démontré qu'une pénétration spontanée d'une molécule d'ADN étrangère dans une cellule bactérienne est possible.
Pourquoi les bactéries sont-elles si populaires avec des défauts évidents (par exemple, le manque de modifications post-traductionnelles eucaryotes)? Tout est simple. , .
2) ,
( , , ). , - : , - 7
λ . , :
, , (« »). , , : .
:
- ori — . ;
- — , , , . , , (« »). , , . , .
, β- (GUS). , . , . — (GFP) ( GUS GFP );
- , ( — , — );
- — , ( ). , «» .
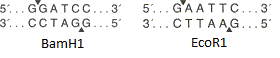 BamH1 EcoR1 . ( -). , « » ( , « »).
BamH1 EcoR1 . ( -). , « » ( , « »).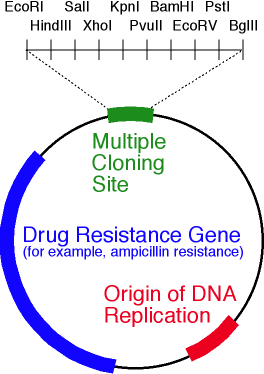 . ori, , 10 .
. ori, , 10 ., . ? , ?
, . :
- , ;
- .
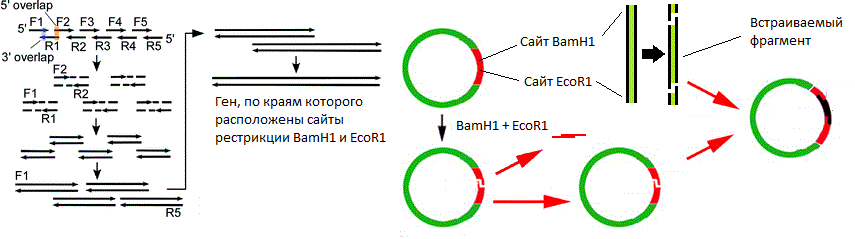 ( ). .
( ). ., , , . , (
BamH1 EcoR1 ) , , « » . , . ,
- , .
, , , «» . , , . , , «» .
 , , , , , . E. coli .
, , , , , . E. coli .. , . , . «» , : , . , , . (, ) , . , .
. . , ( 10% ), -
! . , «» « ». :
- Un système basé sur des éléments régulateurs de l' opéron lactose E. coli ( lac -peron) et un puissant promoteur.
Le fait est que E. coli a ses propres règles nutritionnelles. Premièrement, il existe un mécanisme pour supprimer l'activité du lac -peron, qui n'est activé que lorsque le lactose n'entre pas dans la cellule. C'est logique: pourquoi gaspiller de l'énergie à la synthèse de ce qui n'est pas utile? Mais dès que le lactose commence à pénétrer dans la cellule en quantité suffisante, ce mécanisme est désactivé.
Cependant, il existe un deuxième mécanisme pour supprimer l'activité du lac- peron. S'il y a du glucose dans le milieu, alors la cellule se nourrit exclusivement de glucose, car elle active le deuxième mécanisme d'inhibition de la transcription du lac- péron. Ainsi, le lac- peron n'est actif que lorsqu'il n'y a que du lactose dans l'espace entourant la cellule. Le moins de l'opéron lactose est un promoteur extrêmement faible, par conséquent, dans les souches productrices, il est remplacé par un fort. Les promoteurs puissants sont souvent dérivés d'agents pathogènes. Les promoteurs les plus puissants les plus largement utilisés dans le génie génétique des procaryotes sont isolés des virus bactériens - bactériophages . Par exemple, le promoteur du phage T7 est largement utilisé.
Soit dit en passant, certains promoteurs puissants du génie génétique des plantes sont également isolés des virus, par exemple, il s'agit du promoteur du virus de la mosaïque du chou-fleur.

Comme mentionné ci-dessus, E. coli ne possède pas d'ARN polymérase qui reconnaît les promoteurs du bactériophage; par conséquent, le gène d'ARN polymérase du bactériophage correspondant est préalablement inséré dans le producteur.
Le système populaire de synthèse de protéines à base d' E. Coli porte le gène de l'ARN polymérase du phage T7 sous le contrôle du promoteur bactérien de l'ARN polymérase, régulé par le mécanisme du lacon. Si cette souche est transformée avec un vecteur portant le gène cible sous le contrôle du complexe «promoteur du phage T7 + régulation du type de promoteur lacperon», un mécanisme à deux niveaux d'inhibition de la transcription du gène cible apparaîtra.
Lorsque vous utilisez cette conception, du glucose et du lactose sont ajoutés simultanément au milieu nutritif. Pendant un certain temps, les cellules se nourriront de glucose et se diviseront tranquillement, car la synthèse d'une protéine étrangère est complètement supprimée. Lorsque le glucose sera terminé et que les cellules passeront au métabolisme du lactose, il y aura déjà suffisamment de biomasse dans la culture, c'est le moment de commencer la synthèse de la protéine dont nous avons besoin. Cette procédure est appelée "auto-induction".
Vous pouvez le faire d'une autre manière: n'ajoutez pas de glucose et de lactose au milieu nutritif, puis, lorsque la culture atteint la densité souhaitée, ajoutez ce que la cellule prendra pour le lactose, mais ne peut pas le métaboliser ni le détruire. Maintenant, IPTG est utilisé comme un tel inducteur.
- Un système basé sur le mécanisme de régulation du promoteur pL du bactériophage λ .
Ce promoteur est inactivé par la protéine répressive cI. Dans ce cas, une forme thermosensible de cette protéine appelée cI857 a été découverte: ce facteur de transcription conserve sa fonctionnalité à une température d'environ 30 ° C et la perd à 42 ° C. Par conséquent, lors de l'utilisation d'un tel système, la culture bactérienne est d'abord développée à la densité souhaitée à 30 ° C, puis la température est élevée à 42 ° C, ce qui démarre la synthèse de la protéine cible.
Eh bien, le vecteur est conçu. Ensuite, la petite chose est de trouver une méthode appropriée pour son introduction dans la cellule bactérienne. Mais c'est une histoire complètement différente.