
Aujourd'hui, le graphique est l'un des moyens les plus acceptables pour décrire les modèles créés dans le système d'apprentissage automatique. Ces graphiques de calcul sont composés de sommets de neurones reliés par des bords de synapse qui décrivent les connexions entre les sommets.
Contrairement à un processeur graphique central ou vectoriel scalaire, IPU - un nouveau type de processeur conçu pour l'apprentissage automatique, vous permet de construire de tels graphiques. Un ordinateur conçu pour la gestion des graphes est une machine idéale pour les modèles de graphes informatiques créés dans le cadre de l'apprentissage automatique.
L'une des façons les plus simples de décrire le fonctionnement de l'intelligence artificielle est de la visualiser. L'équipe de développement de Graphcore a créé une collection de ces images affichées sur l'UIP. La base était le logiciel Poplar, qui visualise le travail de l'intelligence artificielle. Les chercheurs de cette entreprise ont également découvert pourquoi les réseaux profonds nécessitent autant de mémoire et quelles solutions existent.
Poplar inclut un compilateur graphique qui a été créé à partir de zéro pour traduire les opérations standard utilisées dans le cadre de l'apprentissage automatique en code d'application hautement optimisé pour les IPU. Il vous permet de rassembler ces graphiques ensemble sur le même principe que les POPNN sont assemblés. La bibliothèque contient un ensemble de différents types de sommets pour les primitives généralisées.
Les graphiques sont le paradigme sur lequel tous les logiciels sont basés. Dans Poplar, les graphiques vous permettent de définir le processus de calcul, où les sommets effectuent des opérations et les arêtes décrivent la relation entre eux. Par exemple, si vous souhaitez ajouter deux nombres ensemble, vous pouvez définir un sommet avec deux entrées (les nombres que vous souhaitez ajouter), quelques calculs (la fonction d'ajouter deux nombres) et la sortie (résultat).
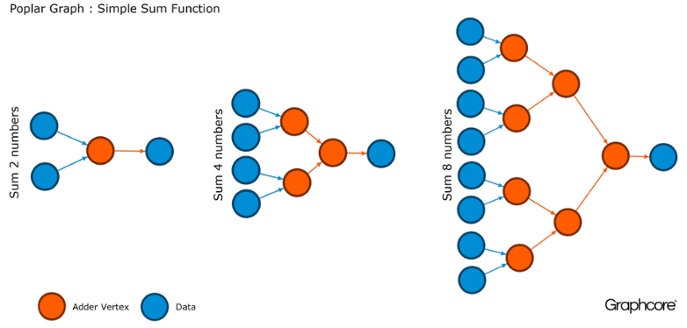
Habituellement, les opérations de sommet sont beaucoup plus compliquées que dans l'exemple décrit ci-dessus. Ils sont souvent définis par de petits programmes appelés codelets (noms de code). L'abstraction graphique est intéressante car elle ne fait aucune hypothèse sur la structure des calculs et décompose le calcul en composants que le processeur IPU peut utiliser pour fonctionner.
Poplar utilise cette abstraction simple pour construire de très grands graphiques qui sont représentés sous forme d'images. La génération programmatique du graphique signifie que nous pouvons l'adapter aux calculs spécifiques nécessaires pour assurer l'utilisation la plus efficace des ressources de l'UIP.
Le compilateur traduit les opérations standard utilisées dans les systèmes d'apprentissage automatique en un code d'application hautement optimisé pour les IPU. Un compilateur de graphiques crée une image intermédiaire d'un graphique de calcul qui est déployé sur un ou plusieurs périphériques IPU. Le compilateur peut afficher ce graphe de calcul, donc une application écrite au niveau de la structure du réseau neuronal affiche une image du graphe de calcul qui s'exécute sur l'UIP.
 Graphique d'apprentissage complet AlexNet en avant et en arrière
Graphique d'apprentissage complet AlexNet en avant et en arrièreLe compilateur graphique Poplar a transformé
la description
d'AlexNet en un graphe de calcul de 18,7 millions de sommets et 115,8 millions d'arêtes. Le clustering clairement visible est le résultat d'une forte connexion entre les processus dans chaque couche du réseau avec une connexion plus facile entre les niveaux.
Un autre exemple est un réseau simple avec une connectivité complète, formé au
MNIST - un simple ensemble de données pour la vision par ordinateur, une sorte de «Bonjour, monde» dans l'apprentissage automatique. Un réseau simple pour explorer cet ensemble de données permet de comprendre les graphiques contrôlés par les applications Poplar. En intégrant des bibliothèques de graphes à des environnements tels que TensorFlow, la société fournit l'un des moyens les plus simples d'utiliser les IPU dans les applications d'apprentissage automatique.
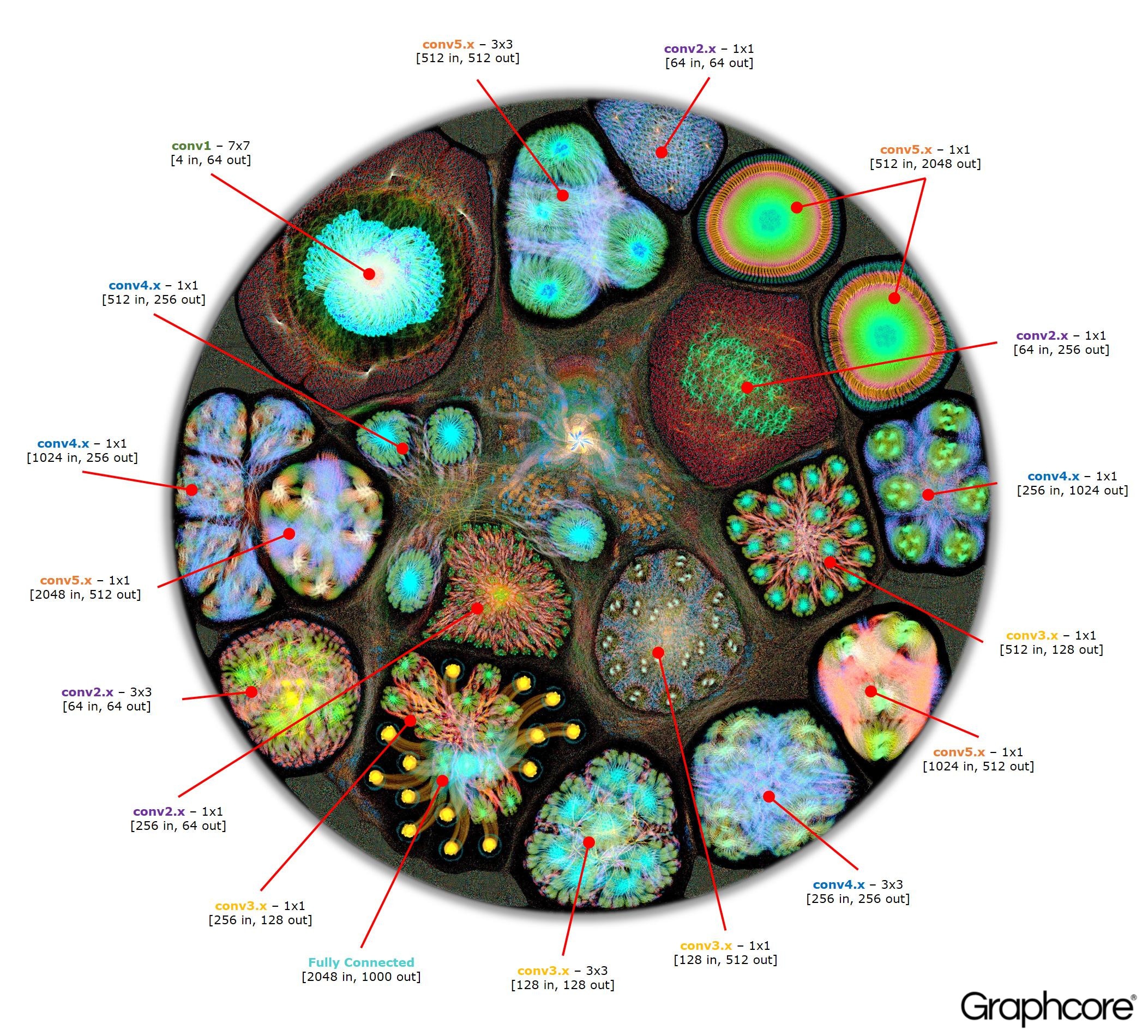
Une fois le graphique construit à l'aide du compilateur, il doit être exécuté. Cela est possible en utilisant le moteur graphique. En utilisant ResNet-50 comme exemple, son fonctionnement est démontré.
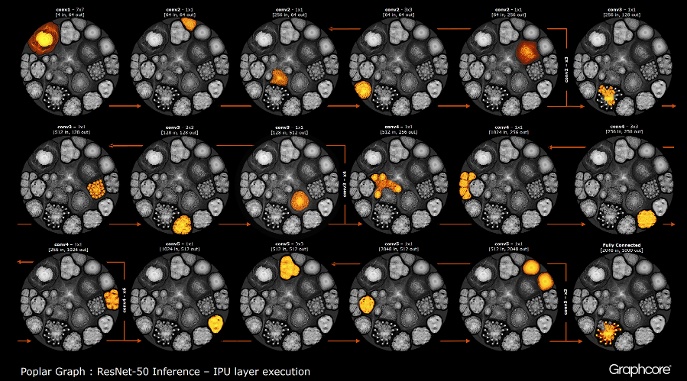 Count ResNet-50
Count ResNet-50L'architecture ResNet-50 vous permet de créer des réseaux profonds à partir de partitions répétitives. Le processeur n'a besoin de déterminer ces partitions qu'une seule fois et de les rappeler. Par exemple, un cluster de niveau conv4 est exécuté six fois, mais une seule fois appliqué au graphique. L'image montre également la variété des formes des couches convolutives, car chacune d'elles a un graphique construit conformément à la forme naturelle de calcul.
Le moteur crée et contrôle l'exécution d'un modèle d'apprentissage automatique à l'aide d'un graphique créé par le compilateur. Une fois déployé, Graph Engine surveille et répond aux IPU ou aux périphériques utilisés par les applications.
L'image ResNet-50 montre l'ensemble du modèle. À ce niveau, il est difficile de faire la distinction entre les sommets individuels, il est donc intéressant de regarder des images agrandies. Voici quelques exemples de sections à l'intérieur des couches d'un réseau neuronal.


Pourquoi les réseaux profonds ont-ils besoin de tant de mémoire?
De grandes quantités de mémoire occupée sont l'un des plus gros problèmes des réseaux de neurones profonds. Les chercheurs tentent de gérer la bande passante limitée des périphériques DRAM, qui devrait être utilisée par les systèmes modernes pour stocker un grand nombre de poids et d'activations dans un réseau neuronal profond.
Les architectures ont été développées à l'aide de puces de processeur conçues pour le traitement séquentiel et l'optimisation de la DRAM pour la mémoire haute densité. L'interface entre les deux appareils est un goulot d'étranglement qui introduit des limitations de bande passante et ajoute une surcharge importante à la consommation d'énergie.
Bien que nous n'ayons toujours pas une image complète du cerveau humain et de son fonctionnement, il est généralement clair qu'il n'y a pas de grande installation de stockage séparée pour la mémoire. On pense que la fonction de la mémoire à long terme et à court terme dans le cerveau humain est intégrée dans la structure des neurones + synapses. Même des organismes simples comme les
vers avec une structure neuronale du cerveau, composée d'un peu plus de 300 neurones,
ont un certain degré de fonction de mémoire.
Construire de la mémoire dans des processeurs conventionnels est un moyen de contourner les goulots d'étranglement de la mémoire en ouvrant une bande passante énorme avec une consommation d'énergie beaucoup moins élevée. Néanmoins, la mémoire sur une puce est une chose coûteuse qui n'est pas conçue pour de très grandes quantités de mémoire, qui sont connectées aux processeurs centraux et graphiques actuellement utilisés pour la préparation et le déploiement de réseaux de neurones profonds.
Par conséquent, il est utile d'examiner comment la mémoire est utilisée aujourd'hui dans les unités centrales de traitement et les systèmes d'apprentissage en profondeur sur les accélérateurs graphiques et de se demander: pourquoi ont-ils besoin de si grands dispositifs de stockage de mémoire alors que le cerveau humain fonctionne bien sans eux?
Les réseaux de neurones ont besoin de mémoire pour stocker les données d'entrée, les paramètres de poids et les fonctions d'activation, car l'entrée est distribuée à travers le réseau. En formation, l'activation en entrée doit être conservée jusqu'à ce qu'elle puisse être utilisée pour calculer les erreurs des gradients en sortie.
Par exemple, un réseau ResNet à 50 couches a environ 26 millions de paramètres de pondération et calcule 16 millions d'activations directes. Si vous utilisez un nombre à virgule flottante 32 bits pour stocker chaque poids et activation, cela nécessitera environ 168 Mo d'espace. En utilisant une valeur de précision inférieure pour stocker ces échelles et activations, nous pourrions diviser par deux, voire quadrupler, cette exigence de stockage.
Un grave problème de mémoire provient du fait que les GPU s'appuient sur des données représentées comme des vecteurs denses. Par conséquent, ils peuvent utiliser un seul flux d'instructions (SIMD) pour obtenir un calcul haute densité. Le processeur central utilise des blocs vectoriels similaires pour un calcul haute performance.
Dans les GPU, la synapse a une largeur de 1024 bits, ils utilisent donc des données à virgule flottante 32 bits, donc ils les décomposent souvent en mini-lot parallèle de 32 échantillons pour créer des vecteurs de données 1024 bits. Cette approche de l'organisation du parallélisme vectoriel augmente le nombre d'activations de 32 fois et le besoin de stockage local d'une capacité supérieure à 2 Go.
Les GPU et autres machines conçues pour l'algèbre matricielle sont également soumis à une charge mémoire due aux poids ou aux activations du réseau neuronal. Les GPU ne peuvent pas effectuer efficacement de petites convolutions utilisées dans les réseaux de neurones profonds. Par conséquent, une transformation appelée «rétrogradation» est utilisée pour convertir ces convolutions en multiplications matrice-matrice (GEMM), que les accélérateurs graphiques peuvent gérer efficacement.
De la mémoire supplémentaire est également requise pour stocker les données d'entrée, les valeurs de temps et les instructions de programme. La mesure de l'utilisation de la mémoire lors de la formation de ResNet-50 sur un GPU hautes performances a montré qu'il nécessite plus de 7,5 Go de DRAM locale.
Peut-être que quelqu'un décidera qu'une précision moindre peut réduire la quantité de mémoire nécessaire, mais ce n'est pas le cas. Lorsque vous passez les valeurs des données à la moitié de la précision des pondérations et des activations, vous ne remplissez que la moitié de la largeur vectorielle du SIMD, en dépensant la moitié des ressources informatiques disponibles. Pour compenser cela, lorsque vous passez de la précision totale à la demi-précision sur le GPU, vous devrez doubler la taille du mini-lot pour provoquer un parallélisme de données suffisant pour utiliser tous les calculs disponibles. Ainsi, la transition vers des échelles de précision et des activations plus faibles sur le GPU nécessite toujours plus de 7,5 Go de mémoire dynamique en accès libre.
Avec autant de données à stocker, il est tout simplement impossible de tout intégrer dans le GPU. Sur chaque couche du réseau neuronal convolutif, il est nécessaire de sauvegarder l'état de la DRAM externe, de charger la couche de réseau suivante puis de charger les données dans le système. En conséquence, l'interface de mémoire externe, déjà limitée par la bande passante mémoire, souffre de la charge supplémentaire de recharger constamment la balance, ainsi que de sauvegarder et de récupérer les fonctions d'activation. Cela ralentit considérablement le temps d'entraînement et augmente considérablement la consommation d'énergie.
Il existe plusieurs solutions à ce problème. Tout d'abord, des opérations telles que les fonctions d'activation peuvent être effectuées «sur place», ce qui vous permet d'écraser l'entrée directement sur la sortie. Ainsi, la mémoire existante peut être réutilisée. Deuxièmement, l'opportunité de réutilisation de la mémoire peut être obtenue en analysant la dépendance des données entre les opérations sur le réseau et la répartition de la même mémoire pour les opérations qui ne l'utilisent pas à ce moment.
La deuxième approche est particulièrement efficace lorsque l'ensemble du réseau neuronal peut être analysé au stade de la compilation afin de créer une mémoire allouée fixe, car les coûts de gestion de la mémoire sont réduits à presque zéro. Il s'est avéré qu'une combinaison de ces méthodes réduit l'utilisation de la mémoire du réseau neuronal de deux à trois fois.
Une troisième approche significative a été récemment découverte par l'équipe Baidu Deep Speech. Ils ont appliqué diverses méthodes d'économie de mémoire pour obtenir une réduction de 16 fois de la consommation de mémoire par les fonctions d'activation, ce qui leur a permis de former des réseaux avec 100 couches. Auparavant, avec la même quantité de mémoire, ils pouvaient former des réseaux à neuf couches.
La combinaison de la mémoire et des ressources de traitement dans un seul appareil a un potentiel important pour augmenter la productivité et l'efficacité des réseaux de neurones convolutifs, ainsi que d'autres formes d'apprentissage automatique. Vous pouvez faire un compromis entre la mémoire et les ressources informatiques afin d'équilibrer les capacités et les performances du système.
Les réseaux de neurones et les modèles de connaissances dans d'autres méthodes d'apprentissage automatique peuvent être considérés comme des graphiques mathématiques. Dans ces graphiques, une énorme quantité de parallélisme est concentrée. Un processeur parallèle conçu pour utiliser la concurrence dans les graphiques ne repose pas sur un mini-lot et peut réduire considérablement la quantité de stockage local requise.
Les résultats de la recherche moderne ont montré que toutes ces méthodes peuvent améliorer considérablement les performances des réseaux de neurones. Les graphiques modernes et les unités centrales de traitement ont une mémoire interne très limitée, seulement quelques mégaoctets au total. De nouvelles architectures de processeur spécialement conçues pour l'apprentissage automatique offrent un équilibre entre la mémoire et l'informatique sur puce, offrant une augmentation significative des performances et de l'efficacité par rapport aux unités centrales de traitement modernes et aux accélérateurs graphiques.