
Il y a quatre ans, Google a réalisé le réel potentiel de l'utilisation des réseaux de neurones dans ses applications. Puis elle a commencé à les introduire partout - dans la traduction de texte, la recherche vocale avec reconnaissance vocale, etc. Mais il est immédiatement devenu clair que l'utilisation des réseaux de neurones augmente considérablement la charge sur les serveurs Google. En gros, si tout le monde effectuait une recherche vocale sur Android (ou dictait du texte avec reconnaissance vocale) pendant seulement trois minutes par jour, alors Google devrait doubler le nombre de centres de données (!) Juste pour que les réseaux de neurones traitent une telle quantité de trafic vocal.
Il fallait faire quelque chose - et Google a trouvé une solution. En 2015, elle a développé sa propre architecture matérielle pour l'apprentissage automatique (Tensor Processing Unit, TPU), qui est jusqu'à 70 fois plus rapide que les GPU et CPU traditionnels en termes de performances et jusqu'à 196 fois plus en termes de nombre de calculs par watt. Les GPU / CPU traditionnels font référence aux processeurs à usage général Xeon E5 v3 (Haswell) et Nvidia Tesla K80 GPU.
L'architecture TPU a été décrite pour la première fois cette semaine dans un
article scientifique (pdf) qui sera présenté lors du 44e Symposium international sur les architectures informatiques (ISCA), le 26 juin 2017 à Toronto. Un des principaux auteurs de plus de 70 auteurs de ce travail scientifique,
un ingénieur exceptionnel Norman Jouppi, connu comme l'un des créateurs du processeur MIPS, dans
une interview avec
The Next Platform, a expliqué dans ses propres mots les caractéristiques de l'architecture TPU unique, qui est en fait un ASIC spécialisé, c'est-à-dire circuit intégré à usage spécial.
Contrairement aux FPGA conventionnels ou aux ASIC hautement spécialisés, les modules TPU sont programmés de la même manière qu'un GPU ou un CPU; ce n'est pas un équipement à courte portée pour un seul réseau de neurones. Norman Yuppy dit que TPU prend en charge les instructions CISC pour différents types de réseaux de neurones: réseaux de neurones convolutionnels, modèles LSTM et grands modèles entièrement connectés. Pour qu'elle reste toujours programmable, n'utilise la matrice qu'en tant que primitive, et non pas des primitives vectorielles ou scalaires.
Google souligne que tandis que d'autres développeurs optimisent leurs micropuces pour les réseaux de neurones convolutionnels, ces réseaux de neurones ne fournissent que 5% de la charge dans les centres de données Google. La majorité des applications Google utilisent les
perceptrons multicouches Rumelhart , il était donc très important de créer une architecture plus universelle qui n'était pas «affûtée» uniquement pour les réseaux de neurones convolutifs.
 L'un des éléments de l'architecture est le moteur de flux de données systolique, un tableau de 256 × 256, qui reçoit l'activation (poids) des neurones de gauche, puis tout se déplace pas à pas, multiplié par les poids dans la cellule. Il s'avère que la matrice systolique effectue 65 536 calculs par cycle. Cette architecture est idéale pour les réseaux de neurones.
L'un des éléments de l'architecture est le moteur de flux de données systolique, un tableau de 256 × 256, qui reçoit l'activation (poids) des neurones de gauche, puis tout se déplace pas à pas, multiplié par les poids dans la cellule. Il s'avère que la matrice systolique effectue 65 536 calculs par cycle. Cette architecture est idéale pour les réseaux de neurones.Selon Yuppy, l'architecture des TPU ressemble plus à un coprocesseur FPU qu'à un GPU ordinaire, bien que de nombreuses matrices de multiplication ne stockent aucun programme en elles-mêmes, elles exécutent simplement les instructions reçues de l'hôte.
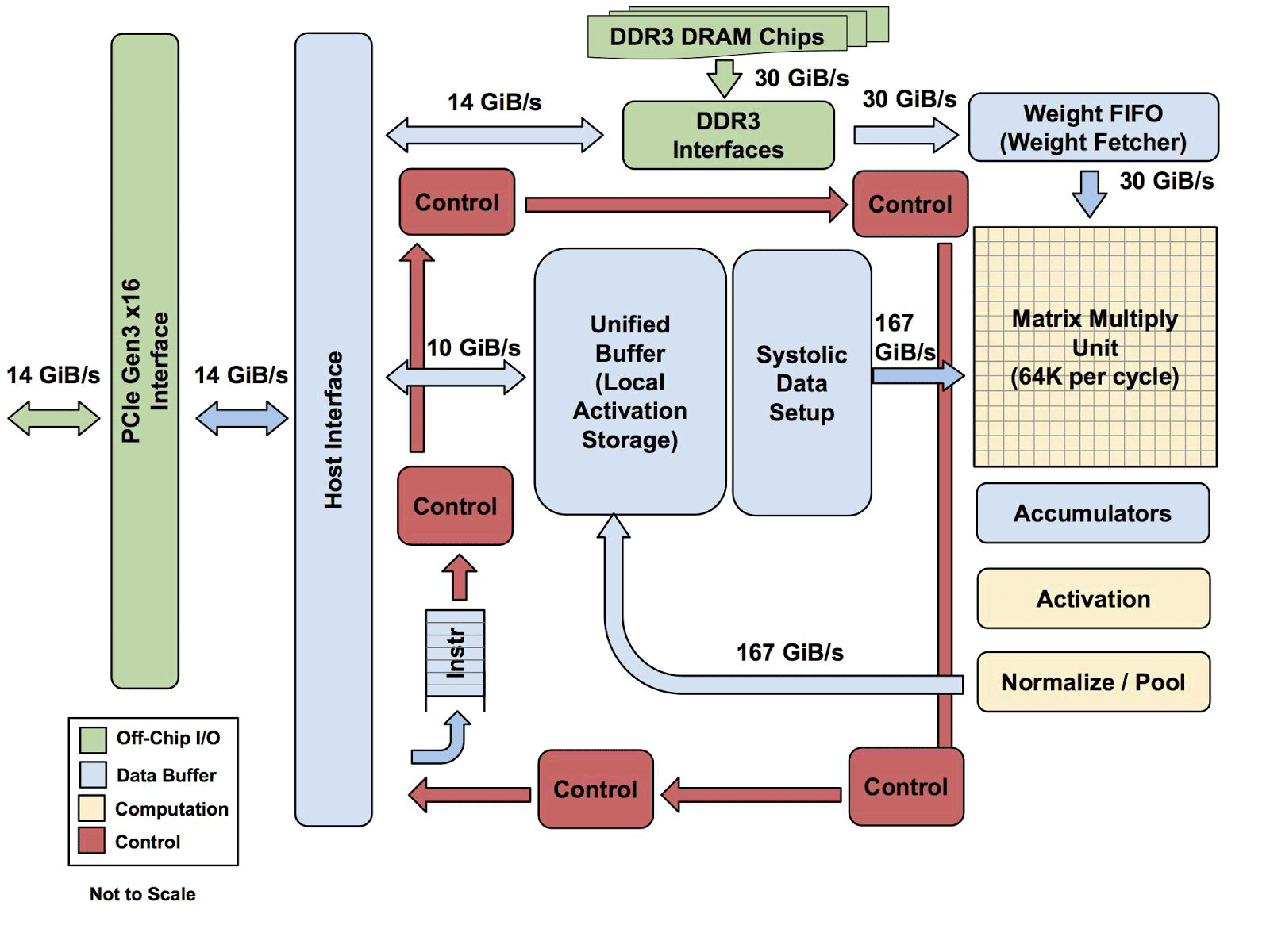 Toute l'architecture TPU à l'exception de la mémoire DDR3. Les instructions sont envoyées de l'hôte (à gauche) à la file d'attente. Ensuite, la logique de contrôle, en fonction de l'instruction, peut exécuter chacun d'eux à plusieurs reprises
Toute l'architecture TPU à l'exception de la mémoire DDR3. Les instructions sont envoyées de l'hôte (à gauche) à la file d'attente. Ensuite, la logique de contrôle, en fonction de l'instruction, peut exécuter chacun d'eux à plusieurs reprisesOn ne sait pas encore à quel point cette architecture est évolutive. Yuppy dit que dans un système avec ce type d'hôte, il y aura toujours une sorte de goulot d'étranglement.
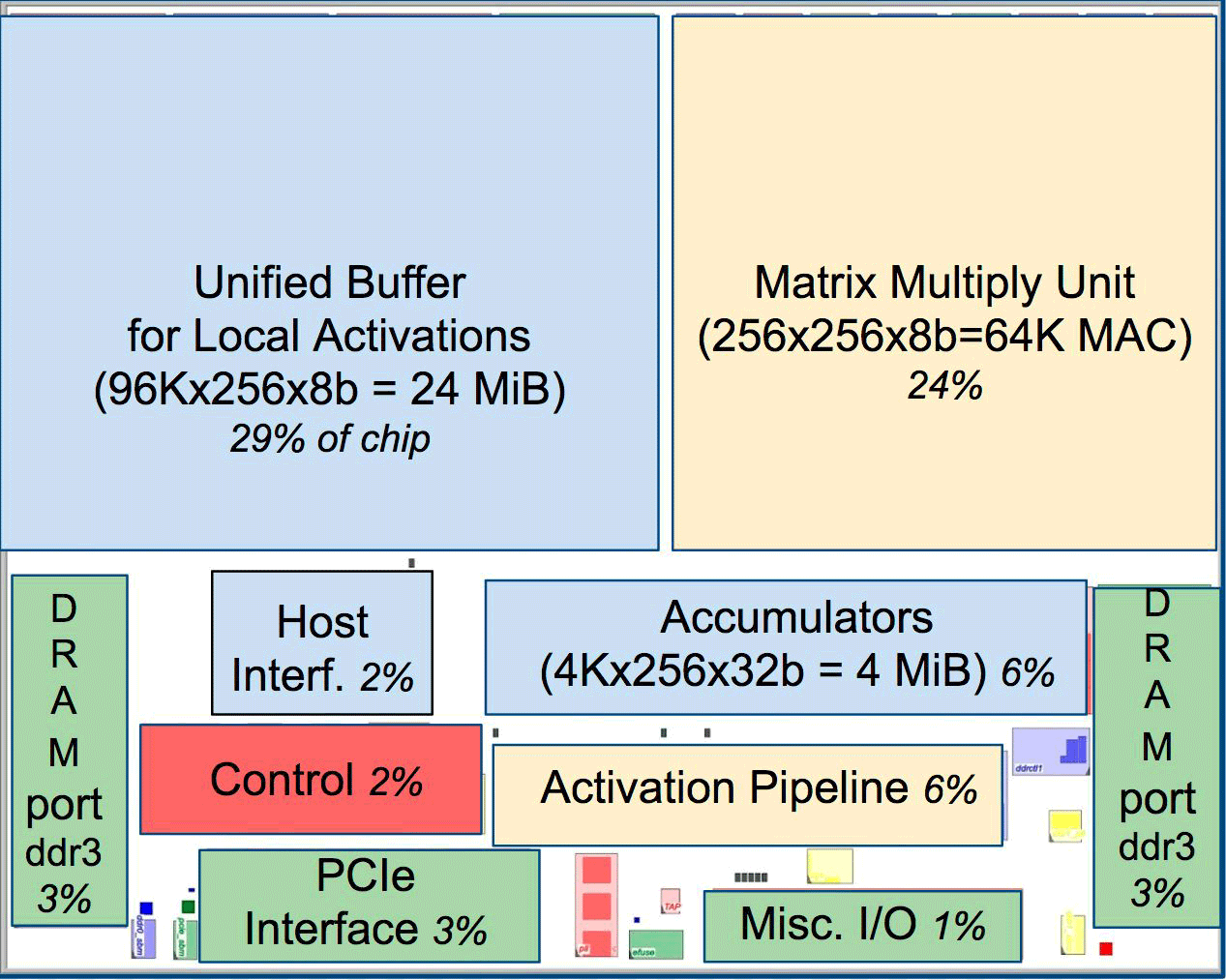
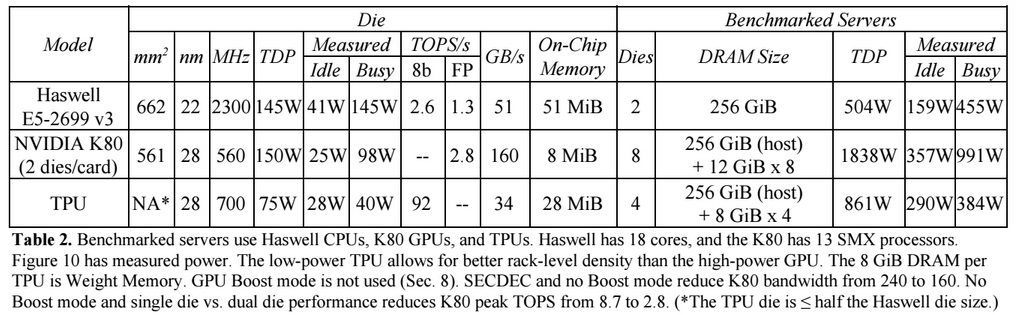
Par rapport aux processeurs et GPU conventionnels, l'architecture des machines de Google les décuple. Par exemple, un processeur Haswell Xeon E5-2699 v3 avec 18 cœurs à une fréquence d'horloge de 2,3 GHz avec une virgule flottante 64 bits effectue 1,3 téra-opérations par seconde (TOPS) et affiche un taux de transfert de données de 51 Go / s. Dans ce cas, la puce elle-même consomme 145 watts, et l'ensemble du système avec 256 Go de mémoire - 455 watts.
À titre de comparaison, le TPU sur les opérations 8 bits avec 256 Go de mémoire externe et 32 Go de mémoire interne démontre la vitesse d'échange avec la mémoire de 34 Go / s, mais en même temps la carte effectue 92 TOPS, soit environ 71 fois plus que le processeur Haswell. La consommation d'énergie du serveur sur TPU est de 384 watts.
Le graphique suivant compare les performances relatives par watt d'un serveur avec un GPU (colonne bleue), un serveur sur TPU (rouge) par rapport à un serveur sur le CPU. Il compare également les performances relatives par watt du serveur avec le TPU par rapport au serveur sur le GPU (orange) et la version améliorée de TPU par rapport au serveur sur le CPU (vert) et au serveur sur le GPU (violet).

Il convient de noter que Google a effectué des comparaisons dans les tests d'applications sur TensorFlow avec l'ancienne version relative de Haswell Xeon, tandis que dans la nouvelle version de Broadwell Xeon E5 v4, le nombre d'instructions par cycle a augmenté de 5% en raison d'améliorations architecturales, et dans la version de Skylake Xeon E5 v5 , qui est prévu en été, le nombre d'instructions par cycle pourrait encore augmenter de 9 à 10%. Et avec l'augmentation du nombre de cœurs de 18 à 28 dans Skylake, les performances globales des processeurs Intel dans les tests Google peuvent s'améliorer de 80%. Mais même ainsi, il y aura une énorme différence de performances avec le TPU. Dans la version du test avec virgule flottante 32 bits, la différence entre les TPU et les CPU est réduite à environ 3,5 fois. Mais la plupart des modèles quantifient parfaitement à 8 bits.
Google a réfléchi à la façon d'utiliser le GPU, le FPGA et l'ASIC dans ses centres de données depuis 2006, mais ne les a pas trouvés avant la dernière fois où il a introduit l'apprentissage automatique pour un certain nombre de tâches pratiques, et la charge sur ces réseaux de neurones a commencé à augmenter avec des milliards de demandes d'utilisateurs. Désormais, la société n'a d'autre choix que de s'éloigner des processeurs traditionnels.
La société ne prévoit pas de vendre ses processeurs à quiconque, mais espère que le travail scientifique avec les ASIC de 2015 permettra à d'autres d'améliorer l'architecture et de créer des versions améliorées d'ASIC qui "élèveront la barre encore plus haut". Google lui-même travaille probablement déjà sur une nouvelle version d'ASIC.