Pensez juste, quelle est la puissance de calcul totale de tous les smartphones dans le monde? Il s'agit d'une énorme ressource informatique qui peut même imiter le travail du cerveau humain. Une telle ressource ne peut pas être inactive au ralenti, brûlant stupidement des kilowatts d'énergie sur les forums de discussion et les flux de médias sociaux. Si vous donnez ces ressources informatiques à une seule IA mondiale distribuée et que vous lui fournissez même des données provenant des smartphones des utilisateurs - pour la formation - alors un tel système peut faire un bond en avant dans ce domaine.
Les méthodes standard d'apprentissage automatique nécessitent que l'ensemble de données pour la formation du modèle («principal») soit collecté en un seul endroit - sur un ordinateur, un serveur ou dans un centre de données ou un cloud. De là, il est pris par un modèle qui est formé sur ces données. Dans le cas d'un cluster d'ordinateurs dans le centre de données,
la méthode de descente de gradient stochastique (SGD) est utilisée - un algorithme d'optimisation qui s'exécute en permanence dans des parties d'un ensemble de données réparties de manière homogène sur les serveurs du cloud.
Google, Apple, Facebook, Microsoft et d'autres acteurs de l'IA font exactement cela depuis longtemps: ils collectent des données - parfois confidentielles - à partir des ordinateurs et des smartphones des utilisateurs dans un seul stockage sécurisé (vraisemblablement) sur lequel leurs réseaux de neurones sont formés.
Maintenant, les scientifiques de Google Research ont proposé un ajout intéressant à cette méthode standard d'apprentissage automatique. Ils ont proposé une approche innovante appelée Federated Learning. Il permet à tous les appareils participant à l'apprentissage automatique de partager un modèle unique pour les prévisions, mais
pas de partager les données primaires pour la formation des modèles !
Cette approche inhabituelle réduit peut-être l'efficacité de l'apprentissage automatique (bien que ce ne soit pas un fait), mais elle réduit considérablement les coûts de maintenance des centres de données par Google. Pourquoi une entreprise investirait-elle d'énormes sommes d'argent dans son équipement si elle a des milliards d'appareils Android dans le monde qui peuvent partager la charge? Les utilisateurs peuvent être satisfaits d'une telle charge, car ils contribuent ainsi à rendre de meilleurs services qu'ils utilisent eux-mêmes. Et ils protègent leurs données confidentielles sans les envoyer au centre de données.
Google souligne que dans ce cas, il ne s'agit pas seulement du fait que le modèle déjà formé est exécuté directement sur l'appareil de l'utilisateur, comme cela se produit dans les services
Mobile Vision API et
On-Device Smart Reply . Non, c'est la
formation sur modèle qui est effectuée sur les terminaux.
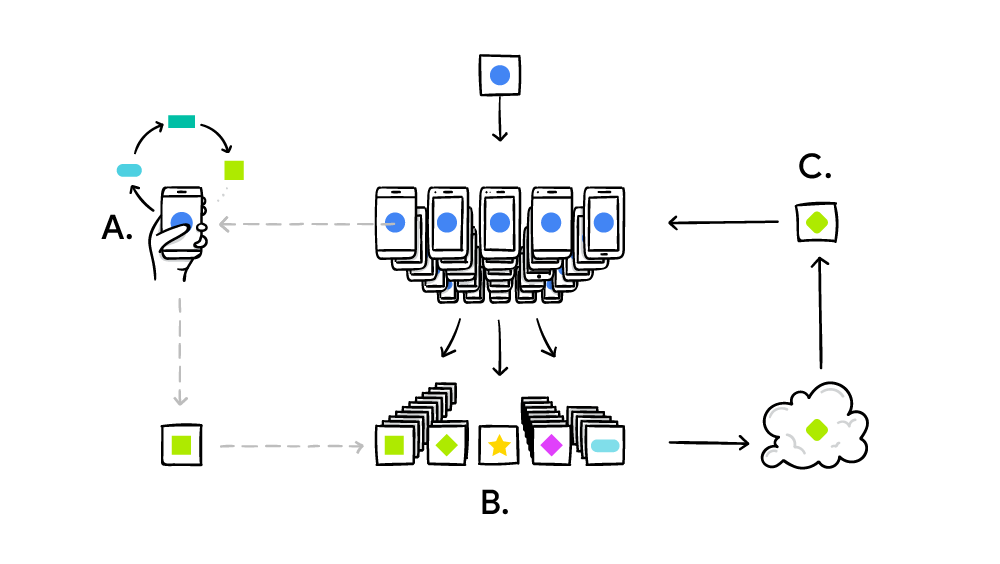
Le système d'apprentissage fédéré fonctionne selon le principe standard de l'informatique distribuée comme SETI @ Home, lorsque des millions d'ordinateurs résolvent un gros problème complexe. Dans le cas de SETI @ Home, il s'agissait d'une recherche d'anomalies dans le signal radio de l'espace sur l'ensemble du spectre. Et dans le cas de l'apprentissage automatique fédéré, Google met au point un modèle unique et commun d'IA faible (jusqu'à présent). En pratique, le cycle de formation est mis en œuvre comme suit:
- smartphone télécharge le modèle actuel;
- à l'aide de la mini-version, TensorFlow effectue un cycle de formation sur les données uniques d'un utilisateur spécifique;
- améliore le modèle;
- calcule la différence entre les modèles source améliorés, compile un correctif à l'aide du protocole cryptographique Secure Aggregation , qui permet le déchiffrement des données uniquement s'il existe des centaines ou des milliers de correctifs provenant d'autres utilisateurs;
- envoie le patch au serveur central;
- le patch adopté est immédiatement moyenné avec des milliers de patchs reçus d'autres participants à l'expérience en utilisant l'algorithme de moyenne fédérée;
- une nouvelle version du modèle est déployée;
- un modèle amélioré est envoyé aux participants à l'expérience.
La moyenne fédérée est très similaire à la méthode de gradient stochastique susmentionnée, seulement ici les calculs initiaux n'ont pas lieu sur des serveurs dans le cloud, mais sur des millions de smartphones distants. La principale réalisation de la moyenne fédérée est 10 à 100 fois moins de trafic avec les clients que le trafic avec les serveurs utilisant la méthode du gradient stochastique. L'optimisation a été obtenue grâce à la
compression de haute qualité des mises à jour envoyées des smartphones au serveur. Eh bien, le plus ici est le protocole cryptographique Secure Aggregation.
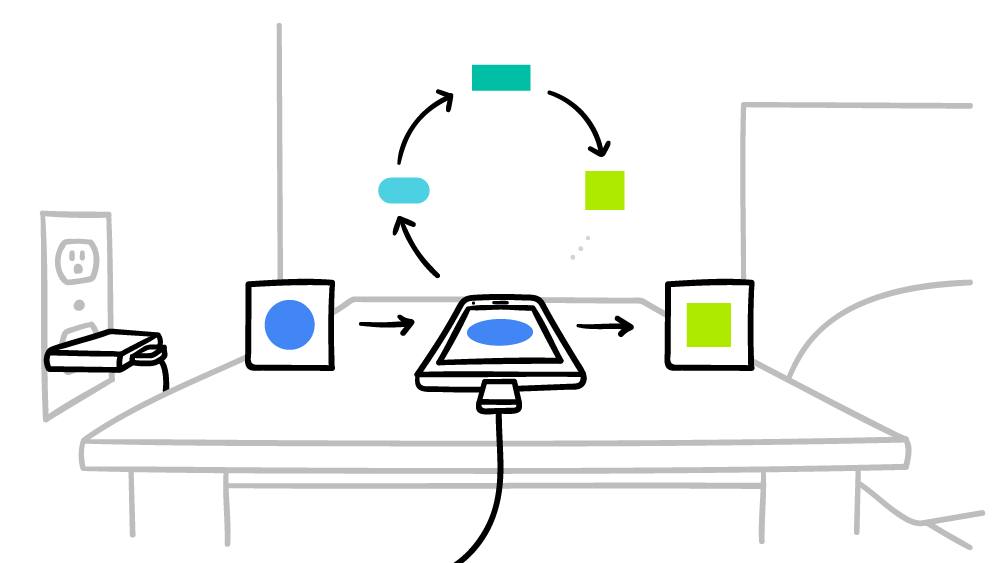
Google promet que le smartphone effectuera uniquement des calculs pour un système d'IA mondial distribué en temps d'arrêt, de sorte que cela n'affectera en rien les performances. De plus, vous ne pouvez régler la durée de fonctionnement que pour le moment où le smartphone est connecté au secteur. Ainsi, ces calculs n'affecteront même pas la durée de vie de la batterie. L'apprentissage automatique fédéré est actuellement testé sur des invites contextuelles sur le clavier Google -
Gboard sur Android .
L'algorithme de moyenne fédérée est décrit plus en détail dans l'article scientifique
Communication-Efficient Learning of Deep Networks from Decentralized Data , qui a été publié le 17 février 2016 sur arXiv.org (arXiv: 1602.05629).