 Une capture d'écran de la tâche et de l'émission du réseau neuronal pix2code dans sa propre langue, que le compilateur traduit ensuite en code pour la plate-forme souhaitée (Android, iOS)
Une capture d'écran de la tâche et de l'émission du réseau neuronal pix2code dans sa propre langue, que le compilateur traduit ensuite en code pour la plate-forme souhaitée (Android, iOS)Le nouveau programme
pix2code (un
article scientifique ) est conçu pour faciliter le travail des programmeurs qui sont engagés dans la tâche fastidieuse de codage de l'interface graphique client.
Le concepteur crée généralement des dispositions d'interface et le programmeur doit écrire du code pour implémenter cette conception. Un tel travail prend un temps précieux que le développeur peut consacrer à des tâches plus intéressantes et créatives, c'est-à-dire à la mise en œuvre des fonctions réelles et de la logique du programme, et non de l'interface graphique. Bientôt, la génération de code peut être transférée aux épaules du programme. Une démonstration jouet des possibilités futures de l'apprentissage automatique est le projet
pix2code , qui a déjà atteint la première place dans la
liste des référentiels les plus chauds sur GitHub , bien que l'auteur n'ait même pas publié le code source et les ensembles de données pour former le réseau neuronal! Un tel intérêt pour ce sujet.
Encoder une interface graphique est ennuyeux. Pour aggraver les choses, ce sont différents langages de programmation sur différentes plates-formes. Autrement dit, vous devez écrire un code distinct pour Android, séparé pour iOS, si le programme doit fonctionner en mode natif. Cela prend encore plus de temps et vous fait effectuer les mêmes tâches ennuyeuses. Plus précisément, c'était avant. Le programme pix2code génère du code GUI pour les trois principales plates-formes - Andriod, iOS et multiplateforme HTML / CSS - avec une précision de 77% (la précision est déterminée dans le langage intégré du programme - en comparant le code généré avec le code cible / attendu pour chaque plate-forme).
L'auteur du programme Tony Beltramelli de la startup danoise
UIzard Technologies appelle cela une démonstration du concept. Il pense que lors de la mise à l'échelle, le modèle améliorera la précision du codage et peut potentiellement éviter aux utilisateurs d'avoir à coder manuellement l'interface graphique.
Le programme pix2code est construit sur des réseaux de neurones convolutifs et récurrents. La formation sur le GPU Nvidia Tesla K80 a pris un peu moins de cinq heures - période pendant laquelle le système a été optimisé

paramètres pour un ensemble de données. Donc, si vous voulez la former sur trois plates-formes, cela prendra environ 15 heures.
Le modèle est capable de générer du code en acceptant uniquement les valeurs de pixels d'une capture d'écran à l'entrée. En d'autres termes, un pipeline spécial n'est pas nécessaire pour qu'un réseau de neurones puisse extraire des fonctionnalités et prétraiter des données d'entrée.
La génération de code informatique à partir de la capture d'écran peut être comparée à la génération d'une description textuelle à partir d'une photographie. En conséquence, l'architecture du modèle pix2code se compose de trois parties: 1) un module de vision par ordinateur pour reconnaître les images, les objets qui y sont présentés, leur emplacement, leur forme et leur couleur (boutons, légendes, conteneurs d'éléments); 2) un module de langage pour comprendre le texte (dans ce cas, un langage de programmation) et générer des exemples syntaxiquement et sémantiquement corrects; 3) utiliser les deux modèles précédents pour générer des descriptions textuelles (code) pour les objets reconnus (éléments GUI).
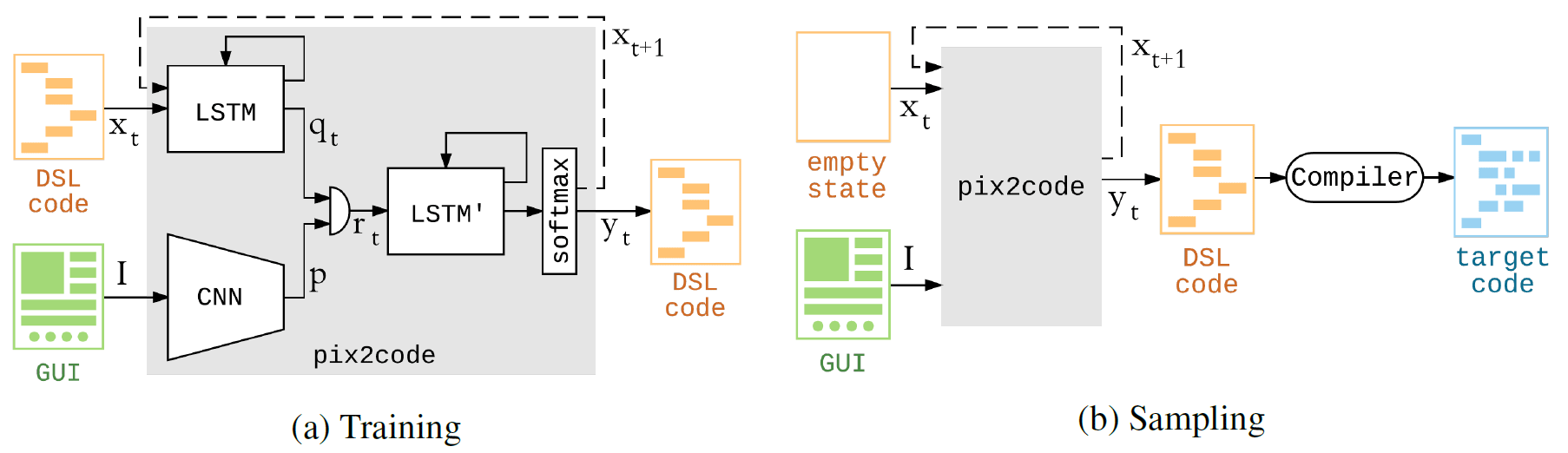
L'auteur attire l'attention sur le fait que le réseau neuronal peut être formé sur un ensemble de données différent - puis il commencera à générer du code dans d'autres langues pour d'autres plates-formes. L'auteur lui-même n'envisage pas de le faire, car il considère pix2code comme une sorte de jouet qui illustre certaines des technologies sur lesquelles sa startup travaille. Cependant, tout le monde peut bifurquer le projet et créer une implémentation pour d'autres langues / plates-formes.
Dans un article scientifique, Tony Beltramelli a écrit qu'il publierait des ensembles de données pour la formation du réseau neuronal dans le domaine public dans le référentiel sur GitHub. Le référentiel a déjà été créé. Là, dans la section FAQ, l'auteur précise qu'il publiera des ensembles de données après la publication (ou le refus de publier) de son article à
la conférence NIPS 2017 . Une notification des organisateurs de la conférence devrait arriver début septembre, de sorte que les ensembles de données apparaîtront dans le référentiel en même temps. Il y aura des captures d'écran de l'interface graphique, le code correspondant dans le langage du programme et la sortie du compilateur pour les trois plates-formes principales.
En ce qui concerne le code source du programme, son auteur n'a pas promis de publier, mais étant donné l'intérêt écrasant pour son développement, il a décidé de l'ouvrir aussi. Cela se fera simultanément avec la publication des ensembles de données.
L'article scientifique a été
publié le 22 mai 2017 sur le site de préimpression arXiv.org (arXiv: 1705.07962).