 Nous, au sein de l' équipe du service de paiement blockchain de Wirex , connaissons l'expérience de la nécessité d'affiner et d'améliorer constamment la solution technologique existante. L'auteur du matériel ci-dessous parle de l'histoire de l'évolution du déploiement de code de la célèbre plateforme de nouvelles sociales Reddit.
Nous, au sein de l' équipe du service de paiement blockchain de Wirex , connaissons l'expérience de la nécessité d'affiner et d'améliorer constamment la solution technologique existante. L'auteur du matériel ci-dessous parle de l'histoire de l'évolution du déploiement de code de la célèbre plateforme de nouvelles sociales Reddit.«Il est important de suivre la direction de votre développement afin de pouvoir l'envoyer dans le bon sens dans les délais.»
L'équipe Reddit déploie constamment du code. Tous les membres de l'équipe de développement écrivent régulièrement du code qui est revérifié par l'auteur lui-même, et testé de l'extérieur, pour qu'il puisse ensuite aller à la "production". Chaque semaine, nous effectuons au moins 200 «déploiements», dont chacun prend généralement un total de moins de 10 minutes.
Le système qui fournit tout cela a évolué au fil des ans. Voyons ce qui a changé en elle tout ce temps et ce qui est resté inchangé.
Début de l'histoire: déploiements stables et récurrents (2007-2010)
L'ensemble du système que nous avons aujourd'hui est passé d'une graine - un script Perl appelé push. Il a été écrit il y a longtemps, à des moments très différents pour Reddit. Toute notre équipe technique était si petite à l'époque qu'elle
s'intégrait tranquillement
dans une petite «salle de réunion» . Nous n'avons pas utilisé AWS à l'époque. Le site fonctionnait sur un nombre fini de serveurs et toute capacité supplémentaire devait être ajoutée manuellement. Tout fonctionnait sur une seule grande application Python monolithique appelée r2.
Une chose au fil des ans est restée inchangée. Les demandes ont été classées dans l'équilibreur de charge et réparties entre les "pools" contenant des serveurs d'applications plus ou moins identiques. Par exemple, les pages de
rubrique et de
liste de commentaires sont traitées par différents pools de serveurs. En fait, tout processus r2 peut gérer tout type de demande, cependant, la division en pools vous permet de protéger chacun d'eux contre les sauts brusques de trafic dans les pools voisins. Ainsi, en cas de croissance du trafic, la panne ne menace pas l'ensemble du système, mais ses pools individuels.
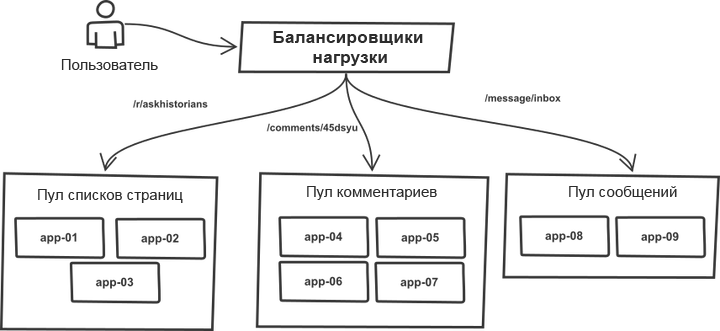
La liste des serveurs cibles a été écrite manuellement dans le code de l'outil push et le processus de déploiement a fonctionné avec un système monolithique. L'outil a parcouru la liste des serveurs, s'est connecté via SSH, a exécuté l'une des séquences de commandes prédéfinies qui ont mis à jour la copie actuelle du code à l'aide de git et redémarré tous les processus d'application. L'essence du processus (le code est grandement simplifié pour une compréhension générale):
# `make -C /home/reddit/reddit static` `rsync /home/reddit/reddit/static public:/var/www/` # app- # , foreach $h (@hostlist) { `git push $h:/home/reddit/reddit master` `ssh $h make -C /home/reddit/reddit` `ssh $h /bin/restart-reddit.sh` }
Le déploiement s'est déroulé séquentiellement, un serveur après l'autre. Pour toute sa simplicité, le schéma avait un avantage important: il est très similaire au «
déploiement canari ». En déployant le code sur plusieurs serveurs et en remarquant des erreurs, vous vous êtes immédiatement rendu compte qu'il y avait des bogues, vous pouviez interrompre (Ctrl-C) le processus et revenir en arrière avant que des problèmes ne surviennent avec toutes les demandes à la fois. La facilité de déploiement a permis de vérifier facilement et sans conséquences graves les éléments en production et de les annuler s'ils ne fonctionnaient pas. De plus, il était pratique de déterminer quel déploiement particulier a provoqué des erreurs, où spécifiquement et ce qui doit être annulé.
Un tel mécanisme a fait un bon travail pour assurer la stabilité et le contrôle pendant le déploiement. L'outil a fonctionné assez rapidement. Les choses se sont bien passées.
Notre régiment est arrivé (2011)
Ensuite, nous avons embauché plus de personnes, il y avait maintenant six développeurs et notre nouvelle
«salle de réunion» est devenue plus spacieuse . Nous avons commencé à réaliser que le processus de déploiement de code nécessitait désormais plus de coordination, en particulier lorsque les collègues travaillaient à domicile. L'utilitaire push a été mis à jour: maintenant, il a annoncé le début et la fin des déploiements à l'aide du chatbot IRC, qui s'est simplement assis dans l'IRC et a annoncé les événements. Les processus effectués pendant les déploiements n'ont subi pratiquement aucun changement, mais maintenant le système a tout fait pour le développeur et a informé tout le monde des modifications apportées.
À partir de ce moment, l'utilisation du chat a commencé dans le flux de travail de déploiement. Les discussions sur la gestion du déploiement à partir des chats étaient assez populaires à l'époque, cependant, puisque nous utilisions des serveurs IRC tiers, nous ne pouvions pas faire confiance au chat à cent pour cent dans la gestion de l'environnement de production, et donc le processus restait au niveau d'un flux d'informations à sens unique.
À mesure que le trafic vers le site augmentait, l'infrastructure qui le soutenait augmentait également. De temps en temps, nous devions constamment lancer un nouveau groupe de serveurs d'applications et les mettre en service. Le processus n'était toujours pas automatisé. En particulier, la liste d'hôtes en push devait encore être mise à jour manuellement.
La puissance des pools était généralement augmentée en ajoutant plusieurs serveurs à la fois. En conséquence, le fait de pousser successivement dans la liste a réussi à effectuer des modifications sur tout un groupe de serveurs dans le même pool, sans affecter les autres, c'est-à-dire qu'il n'y avait pas de diversification par pools.

UWSGI était utilisé pour contrôler les processus de travail, et donc lorsque nous avons donné à l'application une commande de redémarrage, il a tué tous les processus existants en même temps, les remplaçant par de nouveaux. Les nouveaux processus ont mis du temps à se préparer pour traiter les demandes. Dans le cas d'un redémarrage involontaire d'un groupe de serveurs situés dans le même pool, la combinaison de ces deux circonstances a sérieusement affecté la capacité de ce pool à répondre aux demandes. Nous avons donc rencontré une limite sur la vitesse de déploiement sécurisé du code sur tous les serveurs. À mesure que le nombre de serveurs augmentait, la durée de toute la procédure augmentait.
Déploiement des instruments de recyclage (2012)
Nous avons entièrement repensé l'outil de déploiement. Et bien que son nom, malgré une altération complète, soit resté le même (push), cette fois il a été écrit en Python. La nouvelle version a connu quelques améliorations majeures.
Tout d'abord, il a pris la liste des hôtes du DNS, et non de la séquence codée en dur dans le code. Cela a permis de mettre à jour uniquement la liste, sans avoir à mettre à jour le code push. Les débuts d'un système de découverte de services ont émergé.
Pour résoudre le problème des redémarrages successifs, nous avons mélangé la liste des hôtes avant les déploiements. Le brassage réduit les risques et permet d'accélérer le processus.

La version originale a mélangé la liste au hasard à chaque fois, cependant, cela a rendu difficile une restauration rapide, car chaque fois la liste du premier groupe de serveurs était différente. Par conséquent, nous avons corrigé le mélange: il générait désormais un certain ordre qui pouvait être utilisé lors du déploiement répété après le rollback.
Un autre changement, petit mais important, a été le déploiement constant d'une version fixe du code. La version précédente de l'outil mettait toujours à jour la branche principale sur l'hôte cible, mais que se passe-t-il si le maître change à droite pendant le déploiement en raison du lancement par erreur du code par quelqu'un? Le déploiement d'une révision git donnée au lieu d'appeler par nom de branche a permis de s'assurer que la même version de code était utilisée sur chaque serveur de production.
Enfin, le nouvel outil distingue son code (il fonctionne principalement avec une liste d'hôtes et y accède via SSH) et les commandes exécutées sur les serveurs. Cela dépendait toujours beaucoup des besoins de R2, mais avait quelque chose comme un prototype d'API. Cela a permis à r2 de suivre ses propres étapes de déploiement, ce qui a facilité les changements de roulement et libéré le flux. Voici un exemple de commandes exécutées sur un serveur distinct. Le code, encore une fois, n'est pas le code exact, mais dans l'ensemble, cette séquence décrit bien le flux de travail r2:
sudo /opt/reddit/deploy.py fetch reddit sudo /opt/reddit/deploy.py deploy reddit f3bbbd66a6 sudo /opt/reddit/deploy.py fetch-names sudo /opt/reddit/deploy.py restart all
Les noms de récupération sont particulièrement intéressants: cette instruction est propre à r2.
Autoscaling (2013)
Ensuite, nous avons finalement décidé de passer à un cloud avec une mise à l'échelle automatique (un sujet pour un article séparé). Cela nous a permis d'économiser beaucoup d'argent dans les moments où le site n'était pas chargé de trafic et d'augmenter automatiquement la capacité pour faire face à toute forte augmentation des demandes.
Les améliorations précédentes, en chargeant automatiquement la liste des hôtes à partir du DNS, ont fait de cette transition une évidence. La liste des hôtes a changé plus souvent qu'auparavant, mais du point de vue de l'outil de déploiement, cela n'a joué aucun rôle. Le changement, qui a été introduit à l'origine comme une amélioration de la qualité, est devenu l'un des composants clés nécessaires pour exécuter la mise à l'échelle automatique.
Cependant, l'autoscaling a conduit à quelques cas limites intéressants. Il fallait contrôler les lancements. Que se passe-t-il si le serveur démarre juste pendant le déploiement? Nous devions nous assurer que chaque nouveau serveur en cours d'exécution vérifiait la disponibilité du nouveau code et le prenait, le cas échéant. Nous ne pouvions pas oublier que les serveurs se déconnectaient au moment du déploiement. L'outil devait devenir plus intelligent et apprendre à déterminer que le serveur était hors ligne dans le cadre de la procédure, et non à la suite d'une erreur survenue pendant le déploiement. Dans ce dernier cas, il a dû avertir fortement tous les collègues impliqués dans le problème.
En même temps, nous avons, en passant, et pour diverses raisons, passé de uWSGI à
Gunicorn . Cependant, du point de vue du sujet de ce billet, une telle transition n'a pas entraîné de changements significatifs.
Cela a donc fonctionné pendant un certain temps.
Trop de serveurs (2014)
Au fil du temps, le nombre de serveurs nécessaires pour répondre aux pics de trafic a augmenté. Cela a conduit au fait que les déploiements nécessitaient de plus en plus de temps. Dans le pire des cas, un déploiement normal a pris environ une heure - un mauvais résultat.
Nous avons réécrit l'outil afin qu'il puisse prendre en charge le travail parallèle avec les hôtes. La nouvelle version est appelée
rouleau à pâtisserie . L'ancienne version nécessitait beaucoup de temps pour initialiser les connexions ssh et attendre la fin de toutes les commandes, donc la parallélisation dans des limites raisonnables nous a permis d'accélérer le déploiement. Le temps de déploiement a de nouveau été réduit à cinq minutes.

Pour réduire l'impact du redémarrage simultané de plusieurs serveurs, le composant de mixage de l'outil est devenu plus intelligent. Au lieu de mélanger aveuglément la liste, il a trié les pools de serveurs afin que les hôtes d'un pool soient
aussi éloignés que possible .
Le changement le plus important dans le nouvel outil a été que l'
API entre l'outil de déploiement et les outils sur chaque serveur a été définie beaucoup plus clairement et séparée des besoins de r2. Initialement, cela a été fait par désir de rendre le code plus orienté open-source, mais bientôt cette approche a été très utile d'une autre manière. Voici un exemple de déploiement avec la sélection de commandes d'API lancées à distance:

Trop de monde (2015)
Soudain, un moment est venu où, en fin de compte, beaucoup de gens travaillaient déjà sur r2. C'était cool, et en même temps signifiait qu'il y aurait encore plus de déploiements. Le respect de la règle d'un déploiement à la fois est devenu de plus en plus difficile. Les développeurs devaient se mettre d'accord sur la procédure de délivrance du code. Pour optimiser la situation, nous avons ajouté un autre élément au chatbot qui coordonne la file d'attente de déploiement. Les ingénieurs ont demandé une réserve de déploiement et l'ont reçue, ou leur code a été "mis en file d'attente". Cela a aidé à rationaliser les déploiements, et ceux qui voulaient les terminer pouvaient calmement attendre leur tour.
Un autre ajout important à mesure que l'équipe grandissait était de suivre les déploiements en
un seul endroit . Nous avons changé l'outil de déploiement pour envoyer des métriques à Graphite. Cela a permis de suivre facilement la corrélation entre les déploiements et les changements de métrique.
De nombreux (deux) services (également en 2015)
Tout à coup, le moment de la sortie du deuxième service en ligne est venu. C'était une version mobile du site Web avec sa propre pile complètement différente, ses propres serveurs et le processus de construction. Il s'agissait du premier véritable test d'une API d'outil de déploiement divisé. En y ajoutant la capacité de travailler sur toutes les étapes de montage dans différents «emplacements» pour chaque projet, il a pu supporter la charge et faire face à la maintenance de deux services au sein d'un même système.
25 services (2016)
L'année suivante, nous avons assisté à l'expansion rapide de l'équipe. Au lieu de deux services, deux douzaines sont apparues, au lieu de deux équipes de développement, quinze. La plupart des services ont été construits soit sur
Baseplate , notre infrastructure principale, soit sur des applications clientes, similaires au Web mobile. L'infrastructure derrière les déploiements est la même pour tout le monde. Bientôt, de nombreux autres nouveaux services seront disponibles en ligne, et tout cela est largement dû à la polyvalence du rouleau à pâtisserie. Il vous permet de simplifier le lancement de nouveaux services à l'aide d'outils familiers aux personnes.
Airbag (2017)
À mesure que le nombre de serveurs dans le monolithe augmentait, le temps de déploiement augmentait. Nous voulions augmenter considérablement le nombre de déploiements parallèles, mais cela entraînerait trop de redémarrages simultanés des serveurs d'applications. De telles choses, bien sûr, entraînent une baisse du débit et une perte de la capacité de traiter les demandes entrantes en raison de la surcharge des serveurs restants.
Le processus principal de Gunicorn a utilisé le même modèle que uWSGI, rechargeant tous les travailleurs en même temps. Les nouveaux processus de travail n'ont pas pu répondre aux demandes tant qu'ils n'ont pas été entièrement chargés. Le temps de lancement de notre monolithe variait de 10 à 30 secondes. Cela signifie que pendant cette période, nous ne pourrions pas du tout traiter les demandes. Pour trouver un moyen de sortir de cette situation, nous avons remplacé le processus principal de gunicorn par le gestionnaire de travail
Einhorn de Stripe,
tout en préservant la pile HTTP Gunicorn et le conteneur WSGI . Pendant le redémarrage, Einhorn crée un nouveau travailleur, attend qu'il soit prêt, se débarrasse d'un ancien travailleur et répète le processus jusqu'à la fin de la mise à jour. Cela crée un airbag et nous permet de maintenir la bande passante à un niveau pendant les déploiements.
Le nouveau modèle a créé un autre problème. Comme mentionné précédemment, le remplacement d'un travailleur par un nouveau et entièrement terminé a pris jusqu'à 30 secondes. Cela signifiait que s'il y avait un bogue dans le code, il ne s'affichait pas immédiatement et réussissait à se déployer sur de nombreux serveurs avant d'être détecté. Pour éviter cela, nous avons introduit un mécanisme de blocage de la transition de la procédure de déploiement vers le nouveau serveur, qui était en vigueur jusqu'au redémarrage de tous les processus de travail. Il a été mis en œuvre simplement - en sondant l'état d'Einhorn et en attendant la disponibilité de tous les nouveaux travailleurs. Pour maintenir la vitesse au même niveau, nous avons augmenté le nombre de serveurs traités en parallèle, ce qui était complètement sûr dans les nouvelles conditions.
Un tel mécanisme nous permet de déployer simultanément sur un nombre beaucoup plus important de machines, et le temps de déploiement, couvrant environ 800 serveurs, est réduit à 7 minutes, en tenant compte des pauses supplémentaires pour vérifier les bogues.
En regardant en arrière
L'infrastructure de déploiement décrite ici est un produit né de nombreuses années d'améliorations cohérentes, plutôt que d'un effort ciblé unique. Les échos des décisions prises une fois et prises aux premiers stades des compromis se font encore sentir dans le système actuel, et cela a toujours été le cas à toutes les étapes. Une telle approche évolutive a ses avantages et ses inconvénients: elle nécessite un minimum d'efforts à tout moment, cependant, il y a un risque tôt ou tard de s'arrêter. Il est important de suivre la direction de votre développement afin de pouvoir l'envoyer dans le bon sens dans les délais.
Le futur
L'infrastructure Reddit devrait être prête pour le soutien continu de l'équipe à mesure qu'elle grandit et lance de nouvelles choses. Le taux de croissance de l'entreprise est plus rapide que jamais, et nous travaillons sur des projets encore plus intéressants et de grande envergure que tout ce que nous faisions auparavant. Les problèmes auxquels nous sommes confrontés aujourd'hui sont de double nature: d'une part, il est nécessaire d'augmenter l'autonomie des développeurs, d'autre part, de maintenir la sécurité de l'infrastructure de production et d'améliorer l'airbag, ce qui permet aux développeurs d'effectuer rapidement et en toute confiance des déploiements.
