 «Un scientifique peut découvrir une nouvelle étoile, mais ne peut pas la créer. Pour ce faire, il devra contacter un ingénieur. » Gordon Lindsay Glass, Design Design (1969)
«Un scientifique peut découvrir une nouvelle étoile, mais ne peut pas la créer. Pour ce faire, il devra contacter un ingénieur. » Gordon Lindsay Glass, Design Design (1969)Il y a quelques mois, j'ai écrit sur les différences entre experts en théorie et méthodes d'analyse de données (data scientist) et spécialistes en informatique (data engineer). J'ai parlé de leurs compétences et de leurs points de départ communs. Quelque chose d'intéressant s'est produit: les scientifiques des données ont commencé à avancer, affirmant qu'ils étaient en fait aussi compétents dans le domaine de l'ingénierie des données que les spécialistes du traitement des données. C'était intéressant car les experts en informatique ne s'y opposaient pas et ne disaient pas qu'ils étaient des spécialistes de la théorie de l'analyse des données.
Par conséquent, depuis quelques mois, je collecte des informations et surveille le comportement des spécialistes de la théorie de l'analyse des données dans leur environnement de travail naturel. Dans cet article, j'expliquerai plus en détail pourquoi un data scientist n'est pas un ingénieur de données.
Pourquoi est-ce même important?
Certains se plaignent que la différence entre un spécialiste de la théorie de l'analyse des données et un spécialiste du traitement des données réside uniquement dans le nom. "Les
noms ne doivent pas empêcher les gens d'apprendre ou de faire quelque chose de nouveau "
, disent-ils. Je suis d'accord, vous devez apprendre autant que possible. Mais sachez que votre formation ne peut se rapporter qu'à distance à ce qui devra être fait dans la pratique. Sinon, cela peut entraîner l'échec des projets avec des données volumineuses.
Cela dépend aussi beaucoup du niveau de gestion dans les entreprises. La direction embauche des spécialistes de la théorie de l'analyse des données, s'attendant à ce qu'ils soient des spécialistes du traitement des données.
J'ai entendu la même histoire dans différentes entreprises: l'entreprise décide que la science des données est un moyen d'obtenir de l'argent des investisseurs, des tonnes de profits, de gagner en crédibilité dans leur communauté d'affaires, etc. Cette décision est prise au niveau de la haute direction. Par exemple, laissez une certaine Alice appartenir à ces cadres supérieurs. Après une longue recherche, l'entreprise trouve le meilleur spécialiste de la théorie de l'analyse de données au monde - appelons-le Bob.
Le premier jour ouvrable de Bob est arrivé. Alice s'approche de lui et parle avec enthousiasme de tous ses plans.
«Génial. Où sont les pipelines de données et votre cluster Spark? », Demande Bob.
Alice répond: «C'est ce que nous attendons de vous. Nous vous avons engagé pour faire l'analyse des données. "
«Je ne sais pas comment faire cela», explique Bob.
Alice a l'air surprise: «Mais vous êtes un spécialiste de la théorie du traitement des données. Non? C'est ce que vous faites. "
"Non, j'utilise des pipelines et des données déjà créés."
Alice retourne à son bureau pour découvrir ce qui s'est passé. Elle examine des graphiques simplifiés comme celui illustré à la figure 1 et ne comprend pas pourquoi Bob est incapable d'effectuer des tâches simples avec des données volumineuses.
 Figure 1. Un diagramme de Venn simplifié avec un spécialiste de la théorie de l'analyse des données et un spécialiste du traitement des données.
Figure 1. Un diagramme de Venn simplifié avec un spécialiste de la théorie de l'analyse des données et un spécialiste du traitement des données.Spotlight
Deux problèmes découlent de ces interactions:
- Pourquoi la direction ne comprend-elle pas qu'un spécialiste de la théorie de l'analyse des données n'est pas un spécialiste du traitement des données?
- Pourquoi certains théoriciens de l'analyse pensent-ils être des spécialistes du traitement?
Je vais commencer du côté du leadership. Plus tard, nous parlerons des spécialistes de la théorie de l'analyse des données eux-mêmes.
Avouons-le: le traitement des données n'est pas à l'honneur. Elle n'est pas déclarée la meilleure œuvre du 21e siècle. Elle n'est pas souvent mentionnée dans les médias. Lors des conférences, les premières personnes de l'entreprise ne sont pas informées des avantages du traitement des données. Tous les messages concernent l'analyse des données et la recherche de spécialistes de la théorie et des méthodes d'analyse des données.
Mais les choses commencent à changer. Nous avons des conférences sur le traitement des données. La nécessité de développer des outils informatiques techniques est progressivement reconnue. J'espère que mon travail aidera les organisations à réaliser ce besoin urgent.
Reconnaissance et appréciation
Même dans les cas où les organisations ont des équipes de spécialistes du traitement des données, leur travail n'est souvent toujours pas évalué de manière adéquate.
Un manque de reconnaissance peut être constaté lors des conférences. Un spécialiste de la théorie de l'analyse des données dit qu'il a créé. Je vois une technologie complète de traitement des données qui a formé la base de son modèle, mais elle n'est jamais mentionnée lors d'une conversation. Je ne m'attends pas à ce qu'il soit examiné en détail, mais il serait bon de noter le travail qui a été fait pour que la création de son modèle devienne possible. La direction et les novices dans le domaine de l'analyse des données pensent que tout est possible avec les compétences d'un spécialiste de la théorie de l'analyse des données.
Comment obtenir la reconnaissance
Récemment, des experts en informatique m'ont demandé comment attirer l'attention sur leur entreprise. Ils estiment que lorsque des experts en théorie de l'analyse montrent leurs derniers développements, ils obtiennent toute la gratitude de la direction. La principale question que me posent les ingénieurs est la suivante: «Comment puis-je amener un scientifique des données à cesser de considérer notre travail commun comme mon mérite?»
C'est une question bien fondée, basée sur les situations que je vois dans les entreprises. La direction ne reconnaît pas (et ne divulgue pas) le travail de traitement des données, qui concerne tout ce qui concerne l'analyse des données. Si vous lisez ceci et pensez:
- Mes spécialistes de la théorie de l'analyse des données sont des spécialistes du traitement des données.
- Mes experts en théorie de l'analyse des données créent des pipelines de données vraiment complexes.
- L'auteur ne doit pas savoir de quoi il parle.
... alors vous avez probablement un spécialiste en informatique qui n'est pas à l'honneur.
Comme les spécialistes de la théorie de l'analyse des données démissionnent en l'absence d'ingénieurs, un ingénieur qui ne reçoit pas une reconnaissance suffisante de son travail va quitter. Ne vous laissez pas berner; pour les spécialistes qualifiés en informatique, le marché du travail est aussi chaud que pour les spécialistes de la théorie de l'analyse des données.
L'analyse des données n'est possible qu'avec le soutien de nos amis
Vous avez probablement entendu le
mythe d'Atlanta . Comme punition, il a été forcé de garder la sphère monde / ciel / céleste sur lui. La Terre n'existe sous sa forme actuelle que parce que l'Atlas la détient.
De même, les scientifiques des données soutiennent le monde de l'analyse des données. Une personne qui tient le monde entier sur ses épaules ne reçoit pas autant d'appréciation, bien qu'il le devrait. A tous les niveaux de l'organisation, il faut comprendre que l'analyse des données n'est possible que grâce au travail d'un groupe d'informaticiens.
 Fig. 2. Même les Italiens des années 1400 connaissaient l'importance des spécialistes du traitement des données.
Fig. 2. Même les Italiens des années 1400 connaissaient l'importance des spécialistes du traitement des données.Les scientifiques des données ne sont pas des ingénieurs de données.
Cela nous amène à la raison pour laquelle la théorie de l'analyse des données pense qu'ils sont des spécialistes du traitement des données.
Avant de continuer, quelques réserves pour avertir les commentaires:
- Je sais que les experts en théorie de l'analyse des données sont vraiment très intelligents et j'aime travailler avec eux.
- Je me demande si un tel intellect provoque un effet QI Dunning-Kruger plus fort.
- Certains des meilleurs experts en théorie de l'analyse des données que je connaissais étaient des experts en traitement des données, mais il y en avait très peu.
- Nous réévaluons constamment nos propres compétences.
 Fig. 3. Un diagramme empirique de la perception de leurs compétences par des spécialistes de la théorie de l'analyse par rapport à leurs compétences réelles.
Fig. 3. Un diagramme empirique de la perception de leurs compétences par des spécialistes de la théorie de l'analyse par rapport à leurs compétences réelles.En discutant de leurs compétences en traitement de données avec des experts en théorie de l'analyse des données, j'ai constaté que leur estime de soi varie considérablement. Il s'agit d'une expérience sociale intéressante avec des préjugés. La plupart des experts en théorie de l'analyse des données ont surestimé leurs propres capacités de traitement des données. Certains ont donné une évaluation précise, mais personne n'a donné une note inférieure à leurs capacités réelles.
Deux éléments manquent dans ce diagramme:
- Quel est le niveau de compétence des professionnels du traitement des données?
- Quel niveau de compétence est requis pour un pipeline de données moyennement complexe?
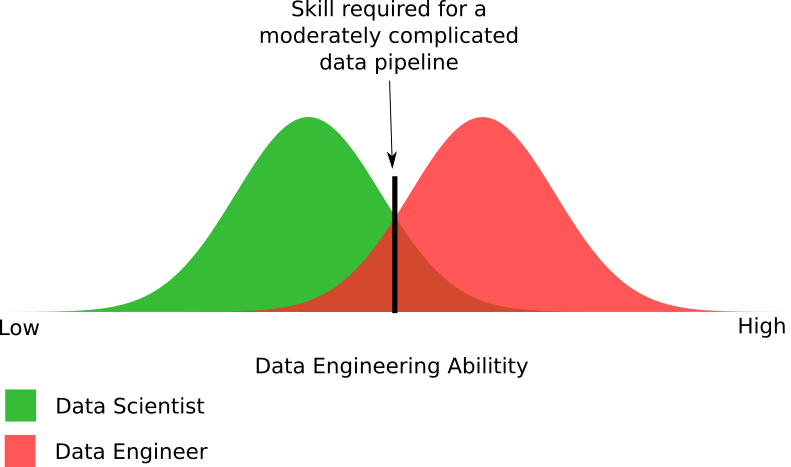 Figure 4. Diagramme empirique des compétences des spécialistes de la théorie de l'analyse et du traitement des données nécessaires pour créer un pipeline de données modérément complexe.
Figure 4. Diagramme empirique des compétences des spécialistes de la théorie de l'analyse et du traitement des données nécessaires pour créer un pipeline de données modérément complexe.La figure montre les différences dans les capacités requises pour le traitement des données. En fait, j'ai exagéré un peu avec le nombre de scientifiques capables de créer un pipeline de données modérément complexe. La réalité peut être que les experts en théorie de l'analyse représentent la moitié de la part indiquée dans le diagramme.
En général, il présente les parties approximatives de ces deux groupes, qui peuvent et ne peuvent pas créer de pipelines de données. Oui, certains spécialistes du traitement des données ne peuvent pas créer un pipeline modérément complexe, comme la plupart des experts en théorie de l'analyse. Cela nous ramène au problème urgent: les organisations donnent leurs projets avec des mégadonnées à ceux qui n'ont pas la possibilité de les mettre en œuvre correctement.
Qu'est-ce qu'un pipeline de données moyennement complexe?
Un pipeline de données moyennement complexe est une étape au-dessus du niveau minimum requis pour créer
un pipeline de données . Un exemple de niveau minimum est le traitement des fichiers texte stockés dans HDFS / S3 à l'aide de Spark: disons, le début de l'optimisation du stockage en utilisant la base de données NoSQL correctement utilisée.
Je pense que les experts en théorie de l'analyse des données pensent que leur pipeline simple est le traitement des données. Mais en réalité, ils parlent des solutions les plus simples, et un tapis roulant beaucoup plus complexe est nécessaire. Dans le passé, un spécialiste du traitement des données dans les coulisses effectuait une ingénierie très complexe, et les experts en théorie de l'analyse n'avaient pas à s'en occuper.
Vous pourriez penser: «Eh bien, 20% de mes experts en théorie de l'analyse des données peuvent gérer cela. Au final, je n'ai pas besoin d'un spécialiste du traitement. » Tout d'abord, rappelez-vous que ce graphique exagère les capacités des experts en théorie de l'analyse des données. Un niveau modérément difficile reste un niveau assez bas. Je dois créer un autre diagramme pour montrer combien peu de théoriciens de l'analyse des données peuvent passer à l'étape suivante. C'est à ce stade que leur part parmi les spécialistes impliqués dans la théorie de l'analyse des données diminue à 1% ou moins.
Pourquoi les scientifiques des données ne sont-ils pas des ingénieurs de données?
Parfois, je préfère considérer les manifestations reflétées des problèmes. Voici quelques-uns de ces problèmes qui font que les experts en théorie de l'analyse des données manquent de compétences en traitement.
Université et cours
L'analyse des données est un nouveau programme populaire pour les universités et les cours en ligne. Il y a toutes sortes de suggestions, mais le même problème se retrouve presque partout: le programme ne contient aucun cours de traitement des données, ou une seule paire se démarque.
Quand je vois un nouveau programme de formation à l'analyse des données, je le regarde. Parfois, on me demande de commenter les cours offerts par les universités. Je dis à tout le monde la même chose: «Avez-vous besoin de programmeurs expérimentés? Parce que votre cours ne concerne pas du tout la programmation ou les systèmes nécessaires pour utiliser le pipeline de données créé. »
Le cours, en termes généraux, se concentre sur les outils statistiques et mathématiques nécessaires. Cela reflète à quoi, selon les entreprises et les scientifiques, l'analyse des données devrait ressembler. Mais le monde réel semble très différent. Les élèves pauvres ne peuvent se balancer que jusqu'à la fin de ces cours non triviaux.
Nous pouvons prendre du recul et tout regarder d'un point de vue académique, en considérant les exigences pour une maîtrise dans le domaine des systèmes distribués. De toute évidence, un spécialiste de la théorie de l'analyse de données n'a pas besoin d'un niveau aussi profond, mais cela aide à montrer quelles lacunes existent dans les compétences d'un spécialiste de la théorie de l'analyse de données. Il existe plusieurs lacunes importantes.
Traitement des données! = Spark
Une idée fausse courante parmi les experts de la théorie de l'analyse et de la gestion des données est qu'ils pensent que le traitement des données consiste simplement à écrire une sorte de code Spark pour traiter le fichier. Spark est une bonne solution batch, mais ce n'est pas la seule technologie dont vous avez besoin. Une solution de Big Data nécessitera 10 à 30 technologies différentes qui fonctionneront ensemble.
Cette erreur est au cœur des échecs du Big Data. La direction estime que l'entreprise dispose d'une nouvelle solution universelle pour résoudre les problèmes liés aux mégadonnées. La réalité est beaucoup plus compliquée.
Lorsque je conseille l'organisation sur des problématiques de big data, je vérifie la présence de cette erreur à tous les niveaux de l'entreprise. Si c'est le cas, je dois être sûr que j'énumérerai toutes les technologies dont ils auront besoin. Cela élimine l'idée fausse selon laquelle, dans le domaine des mégadonnées, il existe un simple bouton et une technologie unique pour résoudre tous les problèmes.
D'où vient le code?
Parfois, les experts en théorie de l'analyse des données me disent à quel point la technologie de traitement des données est simple. Je leur demande pourquoi ils le pensent? «Je peux obtenir le code dont j'ai besoin auprès de StackOverflow ou Reddit. Si je dois créer quelque chose à partir de zéro, je peux copier le projet de quelqu'un dans une conférence lors d'une conférence ou dans un document technique. "
Pour un étranger, cela peut sembler normal. Pour un spécialiste de l'informatique, c'est une alarme. Mis à part les questions juridiques, il ne s'agit pas de traitement de données. Dans le domaine des mégadonnées, il y a très peu de problèmes de modèles. Tout ce qui se passe après «bonjour le monde» a une structure plus complexe, ce qui nécessite un spécialiste du traitement des données, car il n'y a pas d'approche modèle pour travailler avec. La copie d'un projet à partir de la documentation technique peut entraîner de
mauvaises performances ou quelque chose de pire .
J'ai dû traiter avec plusieurs groupes sur la théorie de l'analyse des données qui ont essayé l'approche «singe voit - singe fait». Cela ne fonctionne pas très bien. Cela est dû à une forte augmentation de la complexité des mégadonnées et à
une attention particulière aux cas d'utilisation. Une équipe de spécialistes de la théorie de l'analyse de données rejette souvent un projet car il va au-delà de ses capacités en traitement de données. Autrement dit, il y a une grande différence entre «Je peux copier du code à partir de StackOverflow» ou «Je peux changer quelque chose qui a déjà été écrit» et «Je peux créer ce système à partir de zéro».
Personnellement, je crains que des groupes de spécialistes de la théorie de l'analyse de données ne deviennent une source d'énormes dettes techniques qui réduisent l'efficacité des mégadonnées dans les organisations. Au moment où cela deviendra clair, la dette technique sera si grande qu'il sera impossible de la réparer.
Quel a été le code le plus long introduit pour un usage industriel?
La principale différence entre les spécialistes de la théorie de l'analyse des données est leur profondeur. Cette profondeur peut être montrée de deux manières. Quelle est la plus longue période d'application de leur code dans la pratique - et a-t-elle même été mise en œuvre? Quel est le programme le plus long, le plus grand ou le plus complexe qu'ils aient jamais écrit?
Il ne s'agit pas de concurrence, mais de savoir s'ils savent ce qui se passe lorsque vous mettez quelque chose en service et comment maintenir le code. L'écriture d'un programme de 20 lignes de code est relativement simple. C'est une toute autre affaire d'écrire 1000 lignes de code cohérentes et faciles à maintenir. Les personnes qui n'ont jamais écrit plus de 20 lignes ne comprennent pas la différence de facilité d'entretien. Toutes leurs plaintes concernant la verbosité de Java et la nécessité d'utiliser les meilleures pratiques en programmation sont liées à de grands projets logiciels.
Lors de l'évaluation et de la découverte de données, vous devez travailler rapidement et refaire le code. Et travailler avec le code pour une utilisation en production est requis à un niveau différent et plus profond. C'est pourquoi le code de la plupart des experts en théorie de l'analyse des données doit être réécrit avant d'être mis en service.
Conception de systèmes distribués
Une façon de découvrir la différence entre les experts de la théorie de l'analyse des données et les spécialistes du traitement des données est de voir ce qui se passe lorsqu'ils écrivent leurs propres systèmes distribués. Un expert en théorie de l'analyse de données écrira quelque chose de très axé sur les mathématiques mais qui ne fonctionne pas bien. Un spécialiste du traitement des données qui écrit des systèmes distribués créera une solution distribuée qui fonctionnera bien (
mais n'écrivez pas mieux vos propres systèmes ). Je vais raconter plusieurs histoires sur mon interaction avec des organisations dans lesquelles des experts en théorie de l'analyse de données ont créé un système distribué.
Ainsi, en compagnie de mon client, un service composé de spécialistes de la théorie de l'analyse des données a créé un tel système. On m'a envoyé parler avec eux et comprendre pourquoi ils ont écrit leur propre décision et ce qu'elle peut faire. Ils étaient engagés dans le traitement d'image (distribué).
J'ai commencé par leur demander pourquoi ils avaient créé leur propre système distribué? Ils ont répondu qu'il était impossible de distribuer l'algorithme. Pour confirmer leurs conclusions, ils ont signé un contrat avec un autre spécialiste de la théorie de l'analyse des données, spécialisé dans le traitement d'images. L'entrepreneur a confirmé l'impossibilité de distribuer l'algorithme.
Au cours des deux heures que j'ai passées avec l'équipe, il est devenu clair que l'algorithme peut être distribué sur un moteur informatique universel, comme Spark. , . data scientist'e data engineer', -.
, , . , . . , . . RPC- , .
:
- , . , .
- , .
- : « ?» : « ?»
- , , , .
?
, , : — . , ? ?
— , big data.
, , . , . En voici quelques uns:
- , Agile Scrum
- IDE
- Suivi des bogues
, , , , . , . , , : « » « . . ». , . .
? , - , production ? «». , .
data scientist'? , ( ), . , . «» .
?
, , data scientist' data engineer'. , . : , , .
, , , .
, , data scientist' data engineer' , , . 2-5 . , , .
, . , , , . , , . , , , , , .
, . . , . , , , , .
, . , , , , . :
- . , , , .
- , — . , .
- ? , -?
- , data scientist'. .
- , . , . — , .
Que faire?
, , ? , . . .
, . , . .
, . .
big data
, big data — . , . big data-, . .
big data- , . , , . ( ) , .
. , . , .