Les puces de la plupart des ordinateurs de bureau modernes ont quatre cœurs, mais les fabricants de puces ont déjà annoncé leur intention de passer à six cœurs, et les processeurs à 16 cœurs sont loin d'être rares pour les serveurs hautes performances.
Plus il y a de cœurs, plus le problème de l'allocation de mémoire entre tous les cœurs est important lorsque l'on travaille ensemble. Avec l'augmentation du nombre de cœurs, il devient de plus en plus rentable de minimiser la perte de temps dans la gestion des cœurs pendant le traitement des données - car le taux d'échange de données est en retard par rapport à la vitesse du processeur et du traitement des données en mémoire. Vous pouvez physiquement vous tourner vers le cache rapide de quelqu'un d'autre, ou vous pouvez utiliser votre propre lent, mais économiser du temps de transfert de données. La tâche est compliquée par le fait que la quantité de mémoire demandée par les programmes ne correspond pas clairement aux tailles de cache de chaque type.
Seule une quantité de mémoire très limitée peut être physiquement située le plus près possible du processeur - un cache de processeur de niveau L1, dont la quantité est extrêmement petite. Daniel Sanchez, Po-An Tsai et Nathan Beckmann, chercheurs du laboratoire d'informatique et d'intelligence artificielle du Massachusetts Institute of Technology, ont
enseigné à l' ordinateur
comment configurer différents types de mémoire pour adapter une hiérarchie flexible de programmes à en temps réel. Le nouveau système, appelé Jenga, analyse les besoins volumétriques et la fréquence d'accès des programmes à la mémoire et redistribue la puissance de chacun des 3 types de cache de processeur dans des combinaisons qui offrent une efficacité accrue et des économies d'énergie.

Pour commencer, les chercheurs ont testé l'augmentation des performances avec une combinaison de mémoire statique et dynamique en travaillant sur des programmes pour un processeur monocœur et ont obtenu la hiérarchie principale - quand la combinaison est la meilleure à utiliser. A partir de 2 types de mémoire ou d'un seul. Deux paramètres ont été évalués - le retard du signal (latence) et la consommation d'énergie pendant le fonctionnement de chaque programme. Environ 40% des programmes ont commencé à fonctionner plus mal avec une combinaison de types de mémoire, le reste - mieux. Après avoir corrigé quels programmes «aiment» les performances mixtes et lesquelles - la taille de la mémoire, les chercheurs ont construit leur système Jenga.
Ils ont virtuellement testé 4 types de programmes sur un ordinateur virtuel avec 36 cœurs. Testé le programme:
- omnet - Objective Modular Network Testbed, bibliothèque de modélisation C et plate-forme d'outils de modélisation de réseau (bleu dans l'image)
- mcf - Meta Content Framework (rouge)
- astar - logiciel pour afficher la réalité virtuelle (vert)
- bzip2 - archiveur (couleur violette)
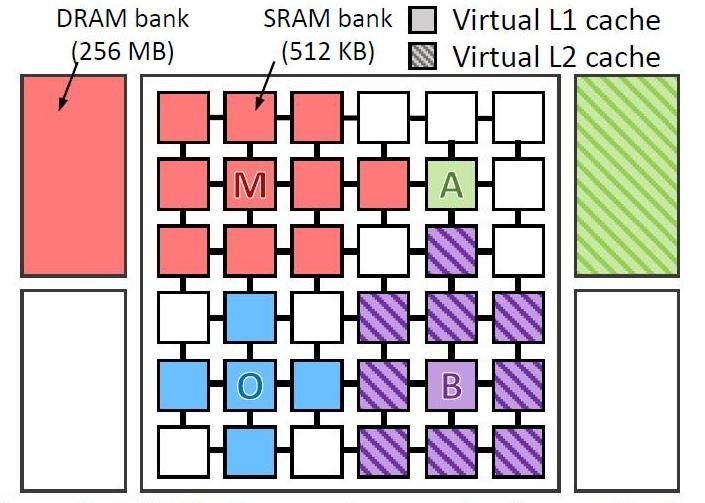
L'image montre où et comment les données de chaque programme ont été traitées. Les lettres indiquent l'emplacement d'exécution de chaque application (une par quadrant), les couleurs indiquent l'emplacement de ses données et les hachures indiquent le deuxième niveau de la hiérarchie virtuelle lorsqu'elle est présente.
Niveaux de cacheLe cache CPU est divisé en plusieurs niveaux. Pour les processeurs universels - jusqu'à 3. La mémoire la plus rapide est le cache de premier niveau - le cache L1, car il est situé sur la même puce que le processeur. Se compose d'un cache de commandes et d'un cache de données. Certains processeurs sans cache L1 ne peuvent pas fonctionner. Le cache L1 fonctionne à la fréquence du processeur et il est accessible à chaque cycle d'horloge. Il est souvent possible d'effectuer plusieurs opérations de lecture / écriture en même temps. Le volume est généralement faible - pas plus de 128 Ko.
Le cache L1 interagit avec un cache de deuxième niveau - L2. C'est le deuxième plus rapide. Habituellement, il est situé soit sur la puce, comme L1, soit à proximité immédiate du cœur, par exemple, dans une cartouche de processeur. Dans les processeurs plus anciens, un chipset sur la carte mère. La taille du cache L2 est de 128 Ko à 12 Mo. Dans les processeurs multicœurs modernes, le cache de deuxième niveau, situé sur la même puce, est une mémoire partagée - avec une taille de cache totale de 8 Mo, 2 Mo par cœur. En règle générale, la latence du cache L2 situé sur la puce principale se situe entre 8 et 20 cycles d'horloge. Dans les tâches liées aux nombreux accès à une zone de mémoire limitée, par exemple un SGBD, son utilisation complète décuple la productivité.
Le cache L3 est généralement encore plus grand, bien que légèrement plus lent que L2 (en raison du fait que le bus entre L2 et L3 est plus étroit que le bus entre L1 et L2). L3 est généralement situé séparément du cœur du processeur, mais peut être volumineux - plus de 32 Mo. Le cache L3 est plus lent que les caches précédents, mais toujours plus rapide que la RAM. Dans les systèmes multiprocesseurs est couramment utilisé. L'utilisation du cache de troisième niveau est justifiée dans une gamme très étroite de tâches et peut non seulement ne pas augmenter la productivité, mais vice versa et entraîner une baisse générale des performances du système.
La désactivation du cache des deuxième et troisième niveaux est plus utile dans les problèmes mathématiques lorsque la quantité de données est inférieure à la taille du cache. Dans ce cas, vous pouvez charger toutes les données immédiatement dans le cache L1, puis les traiter.
Périodiquement, Jenga au niveau du système d'exploitation reconfigure les hiérarchies virtuelles pour minimiser l'échange de données, compte tenu des contraintes de ressources et du comportement des applications. Chaque reconfiguration comprend quatre étapes.
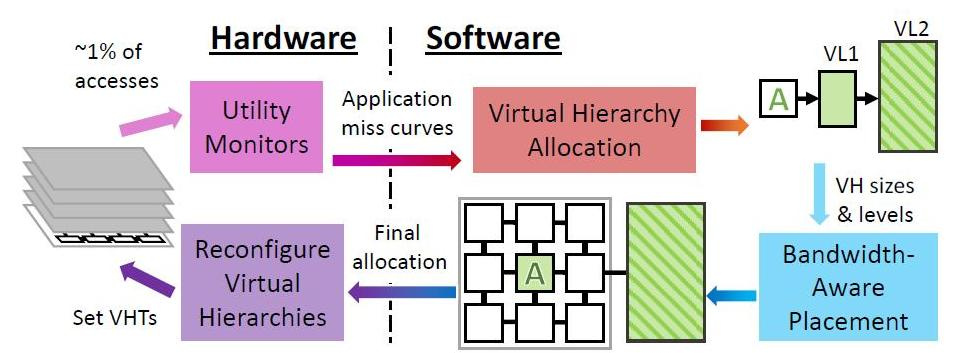
Jenga distribue les données non seulement en fonction des programmes qui sont distribués - ceux qui aiment la grande mémoire à vitesse unique ou qui aiment les performances des caches mixtes, mais aussi en fonction de la proximité physique des cellules de mémoire avec les données en cours de traitement. Quel que soit le type de cache dont le programme a besoin par défaut ou dans la hiérarchie. L'essentiel est de minimiser le retard du signal et la consommation d'énergie. Selon le nombre de types de mémoire que le programme «aime», Jenga modélise la latence de chaque hiérarchie virtuelle avec un ou deux niveaux. Les hiérarchies à deux niveaux forment une surface, les hiérarchies à un niveau forment une courbe. Jenga conçoit ensuite le retard minimum dans les tailles VL1, ce qui donne deux courbes. Enfin, Jenga utilise ces courbes pour sélectionner la meilleure hiérarchie (c'est-à-dire la taille VL1).
L'utilisation de Jenga a donné un effet tangible. La puce virtuelle à 36 cœurs était 30% plus rapide et consommait 85% moins d'énergie. Bien sûr, bien que Jenga ne soit qu'une simulation d'un ordinateur qui fonctionne, il faudra du temps avant de voir de vrais exemples de ce cache et même avant que les fabricants de puces l'acceptent s'ils aiment la technologie.
Configuration conditionnelle de 36 machines nucléaires
- Processeurs . 36 cœurs, ISA x86-64, 2,4 GHz, OOO de type Silvermont: 8B de large
ifetch; Bpred à 2 niveaux avec 512 × 10 bits BHSR + 1024 × 2 bits PHT, décodage / émission / renommage / validation à 2 voies, IQ et ROB à 32 entrées, LQ à 10 entrées, SQ à 16 entrées; 371 pJ / instruction, 163 mW / puissance statique de base - Caches de niveau L1 . 32 ko, ensemble de 8 voies, données divisées et caches d'instructions,
Latence à 3 cycles; 15/33 pJ par coup / coup manqué - Prefetchers Prefetch Service . Préfetchers de flux à 16 entrées modélisés et validés par
Nehalem - Caches de niveau L2 . 128 Ko privé par cœur, 8 voies associatif ensemble, inclusif, latence 6 cycles; 46/93 pJ par coup / coup manqué
- Mode cohérent (cohérence) . Banques de répertoires de latence à 16 voies et 6 cycles pour Jenga; répertoires L3 en cache pour les autres
- NoC mondial . Maillage 6 × 6, flits et liens 128 bits, routage XY, routeurs pipelinés à 2 cycles, liens à 1 cycle; 63/71 pJ par routeur / traversée de flit de liaison, puissance statique de routeur / liaison de 12 / 4mW
- Blocs de mémoire statique SRAM . 18 Mo, une banque de 512 Ko par tuile, zcache à 4 voies, 52 candidats, latence de banque à 9 cycles, partitionnement Vantage; 240/500 pJ par coup / manque, 28 mW / puissance statique de banque
- Mémoire dynamique multicouche DRAM empilée . 1152 Mo, un coffre de 128 Mo par 4 tuiles, alliage avec MAP-I DDR3-3200 (1600 MHz), bus 128 bits, 16 rangées, 8 banques / rang, mémoire tampon de 2 Ko; 4,4 / 6,2 nJ par coup / manque, puissance statique de 88 mW / voûte
- Mémoire principale . 4 canaux DDR3-1600, bus 64 bits, 2 rangs / canal, 8 banques / rang, 8 Ko de mémoire tampon de ligne; 20 nJ / accès, puissance statique 4 W
- Timings DRAM . tCAS = 8, tRCD = 8, tRTP = 4, tRAS = 24, tRP = 8, tRRD = 4, tWTR = 4, tWR = 8, tFAW = 18 (toutes les temporisations en tCK; la DRAM empilée a la moitié du tCK comme mémoire principale )