 Les doubles numériques de politiciens et d'acteurs célèbres sont sous le contrôle total du «marionnettiste». Illustration: Université de Washington, 2015
Les doubles numériques de politiciens et d'acteurs célèbres sont sous le contrôle total du «marionnettiste». Illustration: Université de Washington, 2015Les programmes graphiques 3D, couplés à des réseaux de neurones, ont atteint une telle qualité que la fausse vidéo est presque impossible à distinguer de la vraie. Bientôt, il ne sera pas possible de dire avec certitude que la personne sur l'écran du téléviseur est un véritable politicien, pas une simulation informatique.
En décembre 2015, des scientifiques de l'Université de Washington ont présenté la
technologie des «doubles numériques» : la création de modèles 3D «en direct» à partir de centaines de photographies d'un même personnage. Une énorme archive de photos a été compilée pour les célébrités et les politiciens sur Internet. Le programme crée un modèle, et celui-ci est comme une poupée sur une corde - il peut être contrôlé comme vous le souhaitez, donner différentes expressions faciales, faire n'importe quel discours avec vos lèvres.
À la veille de la conférence d'infographie
SIGGRAPH 2017 , le même groupe de chercheurs a publié un nouveau
travail scientifique avec une version avancée de «contreparties numériques».
Maintenant, lors de l'enseignement du programme, non seulement des photos sont utilisées, mais aussi des vidéos, de sorte que la formation est devenue beaucoup plus efficace. Pour démontrer la technologie, les scientifiques ont choisi un personnage célèbre - l'ancien président américain Barack Obama. C'est un bon choix, car Internet contient une énorme quantité de matériel vidéo HD. Des millions d'images vidéo sont disponibles pour former un réseau de neurones.
Le réseau neuronal a étudié en détail les caractéristiques des expressions faciales d'Obama: mouvements des lèvres à chaque son, apparition de rides près des yeux, changements de forme des sourcils et inclinaison de la tête. L'expression faciale du personnage expérimental était associée aux sons qu'il prononce: le réseau neuronal a traité non seulement les images des vidéos, mais aussi les pistes audio qui leur sont associées.
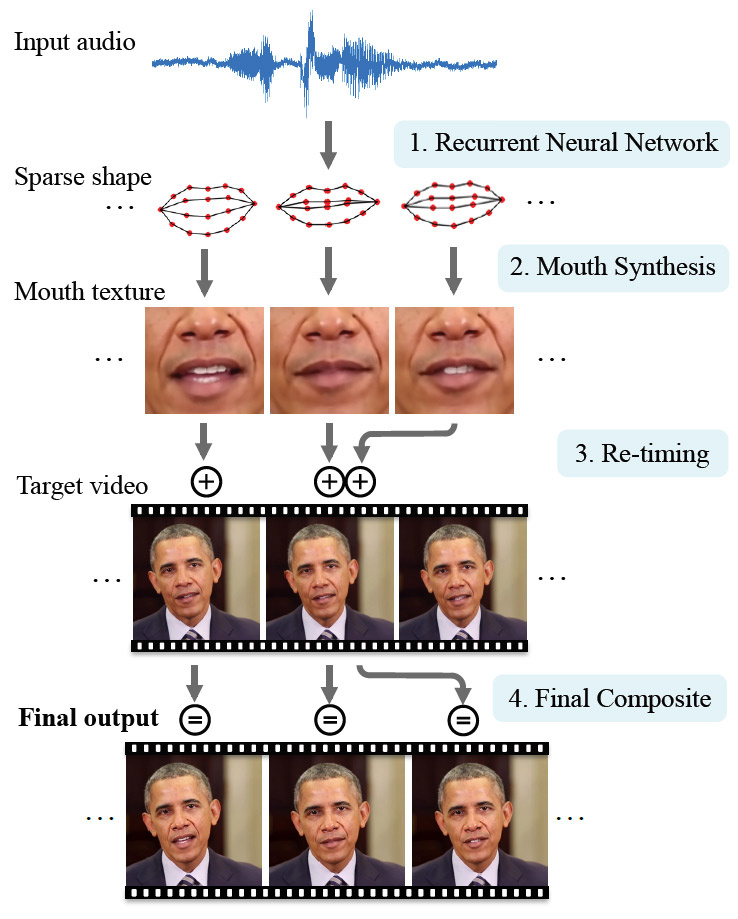
Ainsi, une IA faible a appris à synchroniser les expressions faciales et les mouvements des lèvres avec tout discours arbitraire que les chercheurs alimentent à l'entrée d'un réseau neuronal.
Dans un teaser pour un travail scientifique, des images réelles des discours d'Obama et le résultat synthétisé par un réseau de neurones sont comparés.
Il convient de noter que le résultat synthétisé diffère sensiblement de l'original, mais il semble toujours très réaliste.
Les chercheurs soulignent que plus tôt, afin d'obtenir des «doubles numériques», les gens étaient obligés de répéter à plusieurs reprises les mêmes phrases devant les caméras pour enregistrer toutes les combinaisons de morphèmes et d'expressions faciales. Vous pouvez désormais le faire sur des vidéos accessibles au public. Certes, toutes les personnes sur Internet n'ont pas suffisamment de matériel vidéo pour truquer sa personnalité, mais au fil du temps, les utilisateurs eux-mêmes résolvent ce problème en téléchargeant des gigaoctets de leurs photos et vidéos sur les réseaux sociaux.
D'un point de vue pratique, cette technologie peut également être utilisée. Par exemple, Ira Kemelmacher-Shlizerman, l'un des co-auteurs des travaux scientifiques,
dit qu'elle améliorera la qualité de la visioconférence en synthétisant les images manquantes si elles tombent du flux vidéo. Si le son est sans interférence et que la vidéo est en retard, une telle synthèse complétera l'image ou augmentera sa résolution. Bien sûr, la technologie peut trouver une application dans les jeux informatiques et la réalité virtuelle si le joueur communique avec un personnage virtuel. Maintenant, le discours du personnage virtuel deviendra plus réaliste, et il peut s'agir d'une copie numérique d'une personne réelle. Par exemple, vous ne pouvez «faire revivre» une figure historique du passé récent que par ses enregistrements audio. Bien sûr, la création de contrefaçons à des fins politiques sera facilitée. Si maintenant ils
sont moulés dans «Photoshop» et jetés dans les réseaux sociaux , à l'avenir, de fausses vidéos seront diffusées à la télévision.
Les auteurs reconnaissent que la technologie jusqu'à présent n'est pas parfaite. Par exemple, si Obama détourne légèrement son visage de la caméra, des parties de sa bouche peuvent se séparer de son visage et se chevaucher avec l'arrière-plan. Mais ce sont des erreurs mineures qui peuvent être corrigées par une formation supplémentaire du réseau neuronal.
Un autre inconvénient du modèle créé est qu'il ne modélise pas les émotions. Les expressions faciales sont absolument neutres et presque toujours les mêmes. Ainsi, dans certains cas, le double numérique perd son réalisme: son expression faciale semble trop grave pour les mots frivoles qu'il prononce. Ou vice versa - trop frivole pour des discours très sérieux. Cependant, de tels incidents se produisent avec de vrais politiciens dans la vraie vie.

La technologie créée est similaire en principe au travail sur un
programme de création de doubles numériques Face2Face , où les expressions faciales et la parole d'une personne sont transférées sur le visage d'une autre. Dans leur travail scientifique, les auteurs de Washington comparent les résultats de leur réseau neuronal avec Face2Face. Ils expliquent que dans le cas de Face2Face, un flux vidéo est toujours nécessaire pour simuler, et leur modèle ne fonctionne que par enregistrement sonore.