
Au début du XXe siècle, Wilhelm von Austin, entraîneur de chevaux et mathématicien allemand, a annoncé au monde qu'il avait appris à compter sur un cheval. Pendant des années, von Austin a voyagé à travers l'Allemagne avec une démonstration de ce phénomène. Il a demandé à son cheval, surnommé
Clever Hans (race
Orlov trotter ), de calculer les résultats d'équations simples. Répondit Hans en tapant du sabot. Deux plus deux? Quatre coups sûrs.
Mais les scientifiques ne pensaient pas que Hans était aussi intelligent que von Austin le prétendait. Le psychologue
Karl Stumpf a mené une enquête approfondie, surnommée le «comité Hans». Il a découvert que Smart Hans ne résout pas les équations, mais répond aux signaux visuels. Hans a tapoté son sabot jusqu'à ce qu'il obtienne la bonne réponse, après quoi son entraîneur et une foule enthousiaste ont éclaté en cris. Et puis il s'est juste arrêté. Quand il n'a pas vu ces réactions, il a continué à frapper.
L'informatique peut apprendre beaucoup de Hans. L'accélération du rythme de développement dans ce domaine suggère que la plupart de l'IA que nous avons créée s'est suffisamment formée pour fournir les bonnes réponses, mais ne comprend pas vraiment les informations. Et c'est facile de duper.
Les algorithmes d'apprentissage automatique se sont rapidement transformés en bergers qui voient tout du troupeau humain. Le logiciel nous connecte à Internet, surveille le spam et le contenu malveillant dans notre courrier, et conduira bientôt nos voitures. Leur déception déplace le fondement tectonique de l'Internet et menace notre sécurité à l'avenir.
De petits groupes de recherche - de la Pennsylvania State University, de Google, de l'armée américaine - élaborent des plans pour se protéger contre les attaques potentielles contre l'IA. Les théories avancées dans l'étude disent qu'un attaquant peut changer ce que «voit» un robot. Ou activez la reconnaissance vocale sur le téléphone et forcez-le à accéder à un site Web malveillant en utilisant des sons qui ne seront que du bruit pour une personne. Ou laissez le virus s'infiltrer à travers le pare-feu du réseau.
 À gauche, l'image du bâtiment, à droite, l'image modifiée, que le réseau neuronal profond concerne les autruches. Au milieu, toutes les modifications appliquées à l'image principale sont affichées.
À gauche, l'image du bâtiment, à droite, l'image modifiée, que le réseau neuronal profond concerne les autruches. Au milieu, toutes les modifications appliquées à l'image principale sont affichées.Au lieu de prendre le contrôle du contrôle d'un robot, cette méthode lui montre quelque chose comme une hallucination - une image qui n'existe pas réellement.
De telles attaques utilisent des images avec une astuce [exemples contradictoires - il n'y a pas de terme russe établi, mot pour mot il s'avère quelque chose comme «exemples avec contraste» ou «exemples rivaux» - env. trad.]: images, sons, textes qui semblent normaux aux gens mais qui sont perçus par une machine complètement différente. Les petits changements apportés par les attaquants peuvent amener le réseau neuronal profond à tirer des conclusions erronées sur ce qu'il montre.
«Tout système qui utilise l'apprentissage automatique pour prendre des décisions critiques en matière de sécurité est potentiellement vulnérable à ce type d'attaque», a déclaré Alex Kanchelyan, chercheur à l'Université de Berkeley qui étudie les attaques d'apprentissage automatique à l'aide d'images usurpées.
Connaître ces nuances aux premiers stades du développement de l'IA donne aux chercheurs un outil pour comprendre comment corriger ces lacunes. Certains l'ont déjà compris et disent que leurs algorithmes sont devenus de plus en plus efficaces à cause de cela.
La majeure partie du courant principal de la recherche sur l'IA est basée sur des réseaux de neurones profonds, qui à leur tour sont basés sur un domaine plus large de l'apprentissage automatique. Les technologies MoD utilisent le calcul différentiel et intégral et les statistiques pour créer des logiciels utilisés par la plupart d'entre nous, tels que les filtres anti-spam dans le courrier ou la recherche sur Internet. Au cours des 20 dernières années, les chercheurs ont commencé à appliquer ces techniques à une nouvelle idée, les réseaux de neurones - des structures logicielles qui imitent la fonction cérébrale. L'idée est de décentraliser les calculs sur des milliers de petites équations («neurones») qui reçoivent les données, les traitent et les transmettent plus loin, à la couche suivante de milliers de petites équations.
Ces algorithmes d'IA sont entraînés de la même manière que dans le cas de MO, qui, à son tour, copie le processus d'apprentissage d'une personne. On leur montre des exemples de différentes choses et leurs balises associées. Montrez à l'ordinateur (ou à l'enfant) l'image d'un chat, dites que le chat ressemble à ceci, et l'algorithme apprendra à reconnaître les chats. Mais pour cela, l'ordinateur devra visualiser des milliers et des millions d'images de chats et de chats.
Les chercheurs ont découvert que ces systèmes peuvent être attaqués avec des données trompeuses spécialement sélectionnées, qu'ils ont appelées «exemples contradictoires».
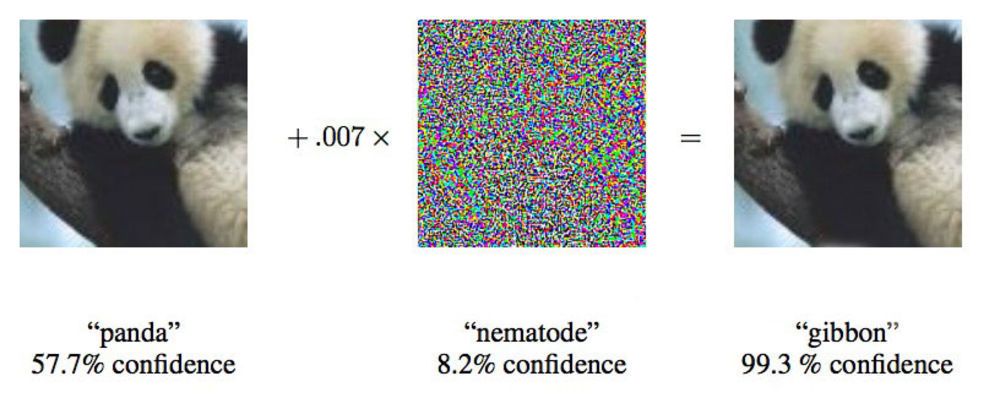 Dans un article de 2015, des chercheurs de Google ont montré que les réseaux de neurones profonds pouvaient être obligés d'attribuer cette image d'un panda aux gibbons.
Dans un article de 2015, des chercheurs de Google ont montré que les réseaux de neurones profonds pouvaient être obligés d'attribuer cette image d'un panda aux gibbons."Nous vous montrons une photo qui montre clairement le bus scolaire et vous fait penser que c'est une autruche", a déclaré Ian Goodfellow, un chercheur de Google qui travaille activement sur de telles attaques contre les réseaux de neurones.
En ne modifiant les images fournies aux réseaux de neurones que de 4%, les chercheurs ont pu les inciter à commettre des erreurs de classification dans 97% des cas. Même s'ils ne savaient pas exactement comment le réseau neuronal traite les images, ils pourraient le tromper dans 85% des cas.
La dernière variante de la fraude sans données sur l'architecture du réseau est appelée «attaque de boîte noire». Il s'agit du premier cas documenté d'une attaque fonctionnelle de ce type sur un réseau neuronal profond, et son importance est qu'environ dans ce scénario, des attaques dans le monde réel peuvent avoir lieu.
Dans l'étude, des chercheurs de la Pennsylvania State University, de Google et du US Navy Research Laboratory ont attaqué un réseau de neurones qui classe les images prises en charge par le projet MetaMind et sert d'outil en ligne pour les développeurs. L'équipe a construit et formé le réseau attaqué, mais leur algorithme d'attaque a fonctionné indépendamment de l'architecture. Avec un tel algorithme, ils ont pu tromper le réseau neuronal de la boîte noire avec une précision de 84,24%.
 La rangée supérieure de photos et de caractères - reconnaissance correcte des caractères.
La rangée supérieure de photos et de caractères - reconnaissance correcte des caractères.
Rangée du bas - le réseau a été forcé de reconnaître des signes complètement faux.Fournir des données inexactes aux machines n'est pas une idée nouvelle, mais Doug Tygar, professeur à l'Université de Berkeley, qui étudie l'apprentissage machine depuis 10 ans en revanche, dit que cette technologie d'attaque a évolué d'un simple MO à des réseaux complexes de neurones profonds. Les pirates malveillants utilisent cette technique sur les filtres anti-spam depuis des années.
Les recherches de Tiger proviennent de
ses travaux de 2006 sur des attaques de ce type sur un réseau avec le ministère de la Défense, qu'il a
élargi en 2011 avec l'aide de chercheurs de UC Berkeley et de Microsoft Research. L'équipe Google, la première à utiliser les réseaux de neurones profonds, a publié ses
premiers travaux en 2014, deux ans après avoir découvert la possibilité de telles attaques. Ils voulaient s'assurer que ce n'était pas une sorte d'anomalie, mais une réelle possibilité. En 2015, ils ont publié un autre
ouvrage dans lequel ils ont décrit un moyen de protéger les réseaux et d'augmenter leur efficacité, et Ian Goodfellow a depuis donné des conseils sur d'autres travaux scientifiques dans ce domaine, y compris
l'attaque de la boîte noire .
Les chercheurs appellent l'idée plus générale d'informations peu fiables «données byzantines» et, grâce aux progrès de la recherche, ils en sont venus à un apprentissage en profondeur. Le terme vient de la fameuse «
tâche des généraux byzantins », une expérience de pensée dans le domaine de l'informatique, dans laquelle un groupe de généraux doit coordonner leurs actions avec l'aide de messagers, sans avoir la certitude que l'un d'eux est un traître. Ils ne peuvent pas faire confiance aux informations reçues de leurs collègues.
«Ces algorithmes sont conçus pour gérer le bruit aléatoire, mais pas les données byzantines», explique Taigar. Pour comprendre le fonctionnement de telles attaques, Goodfello suggère d'imaginer un réseau neuronal sous la forme d'un diagramme de dispersion.
Chaque point du diagramme représente un pixel de l'image traitée par le réseau neuronal. En règle générale, le réseau essaie de tracer une ligne à travers les données qui correspond le mieux à l'ensemble de tous les points. En pratique, c'est un peu plus compliqué, car différents pixels ont des valeurs différentes pour le réseau. En réalité, il s'agit d'un graphe multidimensionnel complexe traité par un ordinateur.
Mais dans notre simple analogie d'un nuage de points, la forme de la ligne tracée à travers les données détermine ce que le réseau pense voir. Pour une attaque réussie sur de tels systèmes, les chercheurs doivent modifier seulement une petite partie de ces points et faire en sorte que le réseau prenne une décision qui n'existe pas. Dans l'exemple d'un bus qui ressemble à une autruche, la photo du bus scolaire est parsemée de pixels disposés selon le motif associé aux caractéristiques uniques des photos d'autruches familières au réseau. Il s'agit d'un contour invisible pour l'œil, mais lorsque l'algorithme
traite et simplifie les données , les points de données extrêmes pour l'autruche lui semblent une option de classification appropriée. Dans la version boîte noire, les chercheurs ont testé l'utilisation de différentes données d'entrée pour déterminer comment l'algorithme voit certains objets.
En donnant au classificateur d'objets de fausses informations et en étudiant les décisions prises par la machine, les chercheurs ont pu restaurer l'algorithme pour tromper le système de reconnaissance d'image. Potentiellement, un tel système dans les robomobiles dans ce cas peut voir le signe «céder le passage» au lieu du panneau d'arrêt. Lorsqu'ils ont compris le fonctionnement du réseau, ils ont pu faire voir quoi que ce soit à la machine.
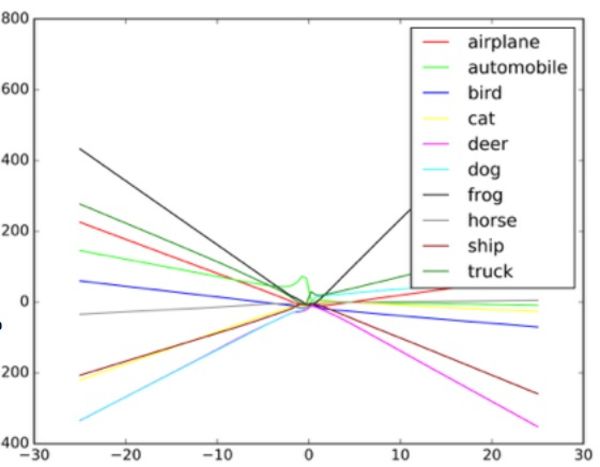 Un exemple de la façon dont le classificateur d'images dessine différentes lignes en fonction des différents objets de l'image. Les faux exemples peuvent être considérés comme des valeurs extrêmes sur le graphique.
Un exemple de la façon dont le classificateur d'images dessine différentes lignes en fonction des différents objets de l'image. Les faux exemples peuvent être considérés comme des valeurs extrêmes sur le graphique.Les chercheurs disent qu'une telle attaque peut être entrée directement dans le système de traitement d'image, en contournant la caméra, ou que ces manipulations peuvent être effectuées avec un vrai signe.
Mais la spécialiste de la sécurité de l'Université Columbia, Alison Bishop, a déclaré qu'une telle prévision est irréaliste et dépend du système utilisé dans le robot. Si les attaquants ont déjà accès au flux de données de la caméra, ils peuvent déjà lui donner n'importe quelle entrée.
«S'ils peuvent arriver à l'entrée de la caméra, de telles difficultés ne sont pas nécessaires», dit-elle. "Vous pouvez simplement lui montrer le panneau d'arrêt."
D'autres méthodes d'attaque, outre le contournement de la caméra - par exemple, dessiner des marques visuelles sur un signe réel, semblent à Bishop peu probables. Elle doute que les caméras basse résolution utilisées sur les robots soient généralement capables de distinguer les petits changements dans l'enseigne.
 L'image vierge à gauche est classée comme un autobus scolaire. Corrigé à droite - comme une autruche. Au milieu - l'image change.
L'image vierge à gauche est classée comme un autobus scolaire. Corrigé à droite - comme une autruche. Au milieu - l'image change.Deux groupes, l'un à l'Université de Berkeley et l'autre à l'Université de Georgetown, ont développé avec succès des algorithmes qui peuvent émettre des commandes vocales à des assistants numériques comme Siri et Google Now, qui sonnent comme un bruit inaudible. Pour une personne, de telles commandes ressembleront à du bruit aléatoire, mais en même temps, elles peuvent donner des commandes à des appareils comme Alexa, non prévus par leur propriétaire.
Nicholas Carlini, l'un des chercheurs dans les attaques audio byzantines, dit que dans leurs tests, ils ont pu activer des programmes de reconnaissance audio open source, Siri et Google Now, avec une précision de plus de 90%.
Le bruit est comme une sorte de négociation extraterrestre de science-fiction. C'est un mélange de bruit blanc et de voix humaine, mais ce n'est pas du tout comme une commande vocale.
Selon Carlini, dans une telle attaque, toute personne qui a entendu un bruit de téléphone (alors qu'il est nécessaire de planifier séparément les attaques sur iOS et Android) peut être obligée de se rendre sur une page Web qui fait également du bruit, ce qui infectera les téléphones situés à proximité. Ou cette page peut télécharger tranquillement un programme malveillant. Il est également possible que de tels bruits disparaissent à la radio et qu'ils soient cachés dans un bruit blanc ou en parallèle avec d'autres informations audio.
De telles attaques peuvent se produire car la machine est formée pour garantir que presque toutes les données contiennent des données importantes, ainsi qu'une chose est plus courante que l'autre, comme l'explique Goodfello.
Tromper le réseau, le forçant à croire qu'il voit un objet commun, est plus facile, car il pense qu'il devrait voir ces objets plus souvent. Par conséquent, Goodfellow et un autre groupe de l'Université du Wyoming ont réussi à classer le réseau des images qui n'existaient pas du tout - il a identifié des objets dans le bruit blanc, créé au hasard des pixels noirs et blancs.
Dans une étude Goodfellow, un bruit blanc aléatoire passant par un réseau a été classé par elle comme un cheval. Par coïncidence, cela nous ramène à l'histoire de Clever Hans, un cheval peu doué en mathématiques.
Goodfellow dit que les réseaux de neurones, comme Smart Hans, n'apprennent réellement aucune idée, mais apprennent seulement à découvrir quand ils trouvent la bonne idée. La différence est petite mais importante. Le manque de connaissances fondamentales facilite les tentatives malveillantes de recréer l'apparence de trouver les «bons» résultats d'algorithme, qui s'avèrent en fait faux. Pour comprendre ce qu'est quelque chose, une machine doit également comprendre ce qu'elle n'est pas.
Goodfello, après avoir formé le réseau à trier les images à la fois sur les images naturelles et sur les images (fausses) traitées, a constaté qu'il pouvait non seulement réduire l'efficacité de ces attaques de 90%, mais aussi permettre au réseau de mieux faire face à la tâche initiale.
«En permettant d'expliquer de fausses images vraiment inhabituelles, vous pouvez obtenir une explication encore plus fiable des concepts sous-jacents», explique Goodfellow.
Deux groupes de chercheurs audio ont utilisé une approche similaire à celle de l'équipe Google, protégeant leurs réseaux neuronaux de leurs propres attaques par un surentraînement. Ils ont également obtenu des succès similaires, réduisant leur efficacité d'attaque de plus de 90%.
Il n'est pas surprenant que ce domaine de recherche ait intéressé l'armée américaine. Le Laboratoire de recherche de l'armée a même parrainé deux des plus récents travaux sur ce sujet, y compris l'attaque de la boîte noire. Et bien que l'agence finance la recherche, cela ne signifie pas que la technologie sera utilisée pendant la guerre. Selon le représentant du département, jusqu'à 10 ans peuvent passer de la recherche aux technologies adaptées à l'usage d'un soldat.
Ananthram Swami, chercheur au US Army Laboratory, a participé à plusieurs travaux récents sur la tromperie de l'IA. L'armée s'intéresse à la question de la détection et de l'arrêt des données frauduleuses dans notre monde, où toutes les sources d'information ne peuvent pas être soigneusement vérifiées. Swami pointe vers un ensemble de données obtenues à partir de capteurs publics situés dans les universités et travaillant dans des projets open source.
«Nous ne contrôlons pas toujours toutes les données. Il est assez facile pour notre adversaire de nous tromper », dit Swami. «Dans certains cas, les conséquences d'une telle fraude peuvent être frivoles, dans certains cas, le contraire.»
Il dit également que l'armée s'intéresse aux robots autonomes, aux chars et à d'autres véhicules, donc le but de ces recherches est évident. En étudiant ces questions, l'armée sera en mesure de prendre une longueur d'avance dans le développement de systèmes qui ne sont pas susceptibles d'attaques de ce type.
Mais tout groupe utilisant un réseau de neurones devrait s'inquiéter du potentiel d'attaques par usurpation d'IA. L'apprentissage automatique et l'IA en sont à leurs balbutiements, et les failles de sécurité peuvent avoir des conséquences désastreuses pour le moment. De nombreuses entreprises confient des informations hautement sensibles à des systèmes d'IA qui n'ont pas passé l'épreuve du temps. Nos réseaux de neurones sont encore trop jeunes pour que nous sachions tout ce dont nous avons besoin à leur sujet.
Un oubli similaire a conduit
le bot Twitter de Microsoft, Tay , à devenir rapidement un raciste avec un penchant pour le génocide. Le flux de données malveillantes et la fonction «répéter après moi» ont conduit à ce que Tay s'écartait considérablement du chemin prévu. Le bot a été trompé par une entrée de qualité inférieure, et cela sert d'exemple pratique d'une mauvaise mise en œuvre de l'apprentissage automatique.
Kanchelyan dit qu'il ne croit pas que les possibilités de telles attaques aient été épuisées après des recherches réussies par l'équipe de Google.
«Dans le domaine de la sécurité informatique, les attaquants sont toujours en avance sur nous», explique Kanchelyan. «Il sera plutôt dangereux de prétendre que nous avons résolu tous les problèmes de tromperie des réseaux de neurones grâce à leur entraînement répété.»