Les services de sécurité réseau (
NSS ) sont un ensemble de bibliothèques utilisées dans le développement multiplateforme d'applications client et serveur sécurisées.
Le package NSS, comme OpenSSL, offre la possibilité d'utiliser des utilitaires de ligne de commande pour implémenter diverses fonctions PKI (génération de clés, émission de certificats x509v3, utilisation de signatures électroniques, prise en charge TLS, etc.). L'un de ces utilitaires, à savoir Pretty-print (PP), vous permet de visualiser facilement le contenu du certificat x509 v3 et de la signature électronique (pkcs # 7), etc. De plus, le certificat peut être à la fois dans les encodages DER et PEM:
bash-4.3$ pp -h Usage: pp [-t type] [-a] [-i input] [-o output] [-w] [-u] Pretty prints a file containing ASN.1 data in DER or ascii format. -t type Specify input and display type: public-key (pk), certificate (c), certificate-request (cr), certificate-identity (ci), pkcs7 (p7), crl or name (n). (Use either the long type name or the shortcut.) -a Input is in ascii encoded form (RFC1113) -i input Define an input file to use (default is stdin) -o output Define an output file to use (default is stdout) -w Don't wrap long output lines -u Use UTF-8 (default is to show non-ascii as .) bash-4.3$
De plus, la présence du paramètre –u (encodage UTF-8) permet de visualiser le certificat en encodage russe. Mais en
regardant attentivement les captures d'écran de l'interface graphique des utilitaires de ligne de commande du package NSS, vous remarquez que certaines des données de certificat ont simplement disparu:
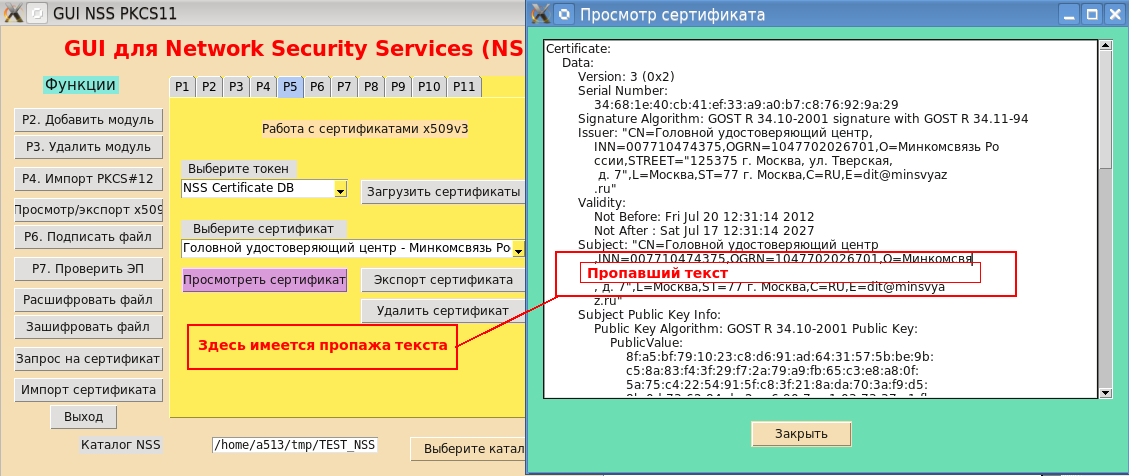
La recherche des informations manquantes a commencé. L'utilitaire "cute print" (qui est la traduction de Pretty-print) pour afficher le certificat racine du CA principal du ministère des Communications a été lancé sur la ligne de commande:
$pp – certificate –u –i _.cer … Subject: "CN= ,INN=007710474375,OGRN=1047702026701,O= ,STREET="125375 . , . , . 7",L=,ST=77 . ,C=RU,E=dit@minsvya z.ru" …. $
Le résultat a confirmé la perte de données. De plus, deux symboles non affichables sont apparus à l'écran (un losange de couleur noire avec un point d'interrogation? À l'intérieur). L'analyse a montré que ces caractères non affichables ont respectivement les codes 0xD0 et 0xBE:
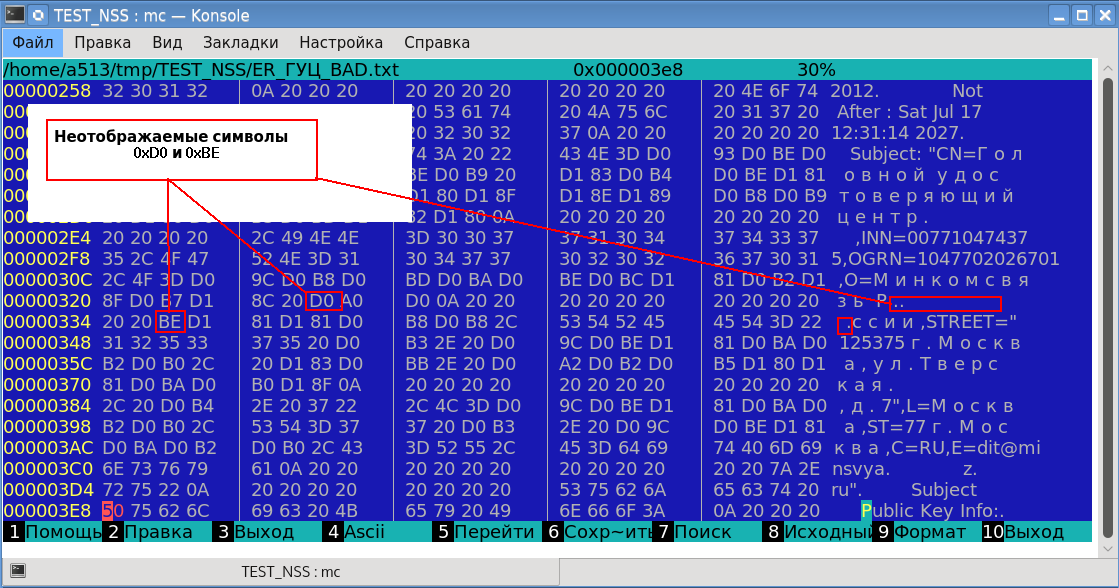
La lettre russe «o» a disparu avec une représentation hexadécimale dans le codage UTF-8 comme 0xD00xBE. Et les codes 0xD0 et 0xBE sont nos caractères non affichables. Et quel genre de caractères est apparu entre ces octets? Et ceci est une «jolie» impression - symboles d'alignement du texte imprimé.
Que s'est-il passé? L'entrée d'une «belle» impression (fichier /nss/cmd/lib/secutil.c, fonction secu_PrintRawStringQuotesOptional) reçoit des données sous forme de SECITEM, c'est-à-dire adresses par tableau d'octets et sa longueur:
for (i = 0; i < si->len; i++) { unsigned char val = si->data[i]; unsigned char c; if (SECU_GetWrapEnabled() && column > 76) { SECU_Newline(out); SECU_Indent(out, level); column = level * INDENT_MULT; } if (utf8DisplayEnabled) { if (val < 32) c = '.'; else c = val; } else { c = printable[val]; } fprintf(out, "%c", c); column++; }
Et si (SECU_GetWrapEnabled () == True) est fourni pour une impression agréable (l'utilitaire PP n'a pas de paramètre –w) et que le nombre d'octets dans une ligne dépasse 76 (colonne> 76), puis après le caractère suivant une nouvelle ligne (SECU_Newline) et les retraits nécessaires (SECU_Indentent ) Dans le même temps, aucun des développeurs n'a pensé que si le codage UTF-8 était utilisé (utf8DisplayEnabled), la beauté ne pouvait être induite qu'après le caractère suivant, et non l'octet, car le concept d'un octet et d'un caractère dans l'encodage UTF-8 pouvait ne pas coïncider. . Si nous parlons de lettres russes, chacune d'elles
est codée sur deux octets. Un tel écart s'est produit avec notre lettre russe «o» (0xD00xBE).
Quelle est la sortie? Tout est très simple dans la fonction secu_PrintRawStringQuotesOptional pour remplacer la ligne:
if (SECU_GetWrapEnabled() && column > 76) {
sur une ligne du formulaire suivant:
if (SECU_GetWrapEnabled() && column > 76 && (val <= 0x7F || val == 0xD0 || val == 0xD1)) {
Si vous reconstruisez maintenant l'utilitaire PP et l'installez dans le système, alors la "belle" impression justifiera son nom pour la "grande, puissante, véridique et gratuite langue russe!" (I.S.Turgenev):
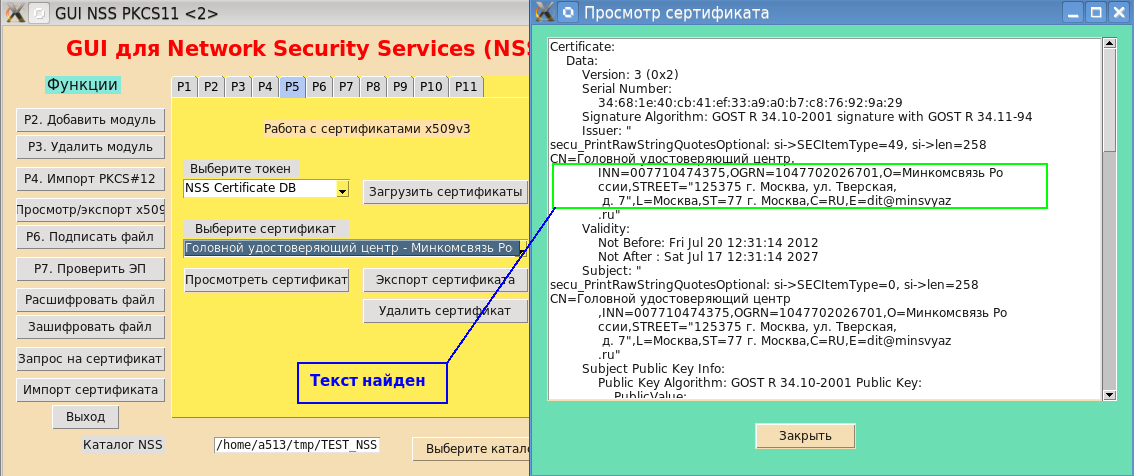
Si nous parlons de la beauté de l'impression, il serait possible d'ajouter une césure non seulement par le nombre de caractères dans la ligne, mais plus correcte, par exemple, par l'espace, la virgule, le deux-points et d'autres caractères. Je ne parle pas de l'analyse sémantique du transfert. Mais c'est déjà un domaine de l'intelligence artificielle.
Et enfin, il s'agit de la deuxième inexactitude découverte dans les utilitaires NSS. Le premier a été découvert dans l'utilitaire
oidcalc .