 Spectrogramme avant réduction du bruit, parole humaine enregistrée à 15 dB SNR
Spectrogramme avant réduction du bruit, parole humaine enregistrée à 15 dB SNR Spectrogramme du son après traitement par le réseau neuronal RNNoise
Spectrogramme du son après traitement par le réseau neuronal RNNoiseLa réduction du bruit est restée un sujet urgent de la recherche scientifique
depuis au moins
les années 70 du siècle dernier . Malgré des améliorations significatives de la qualité des systèmes, leur architecture de haut niveau n'a pratiquement pas changé. La technique d'estimation spectrale repose sur une estimation du bruit spectral, qui à son tour fonctionne à l'aide d'un détecteur d'activité vocale (VAD) ou d'un algorithme similaire. Chacun des trois composants nécessite un ajustement soigné - et ils sont difficiles à configurer. Par conséquent, les réalisations de Mozilla et Xiph.org en apprentissage profond sont si importantes. Le système hybride RNNoise qu'ils ont créé démontre déjà un bon résultat dans la réduction du bruit (voir
code source et
démo ).
En créant RNNoise, les développeurs ont cherché à obtenir un petit algorithme rapide qui fonctionnera efficacement en temps réel même sur le Raspberry Pi. Et ils ont réussi, et RNNoise montre un meilleur résultat que les filtres modernes les plus cool et les plus sophistiqués.
 La structure de haut niveau de la plupart des algorithmes de réduction du bruit
La structure de haut niveau de la plupart des algorithmes de réduction du bruitLes réseaux de neurones ont déjà été utilisés pour supprimer le bruit; ces dernières années, il s'agit d'un domaine de recherche populaire. Mais la plupart suggèrent l'utilisation dans les applications de reconnaissance automatique de la parole, où le retard et la puissance de traitement ne sont pas des facteurs déterminants. En revanche, le projet Mozilla se concentre sur les applications en temps réel, telles que la vidéoconférence, et sur le traitement du son avec une fréquence d'échantillonnage complète de 48 kHz.
Pour atteindre cet objectif, Mozilla a appliqué une approche hybride qui utilise simultanément des méthodes de réduction du bruit bien connues et une formation approfondie pour remplacer les composants difficiles à configurer dans les systèmes conventionnels. L'essence de la méthode est illustrée dans l'organigramme.
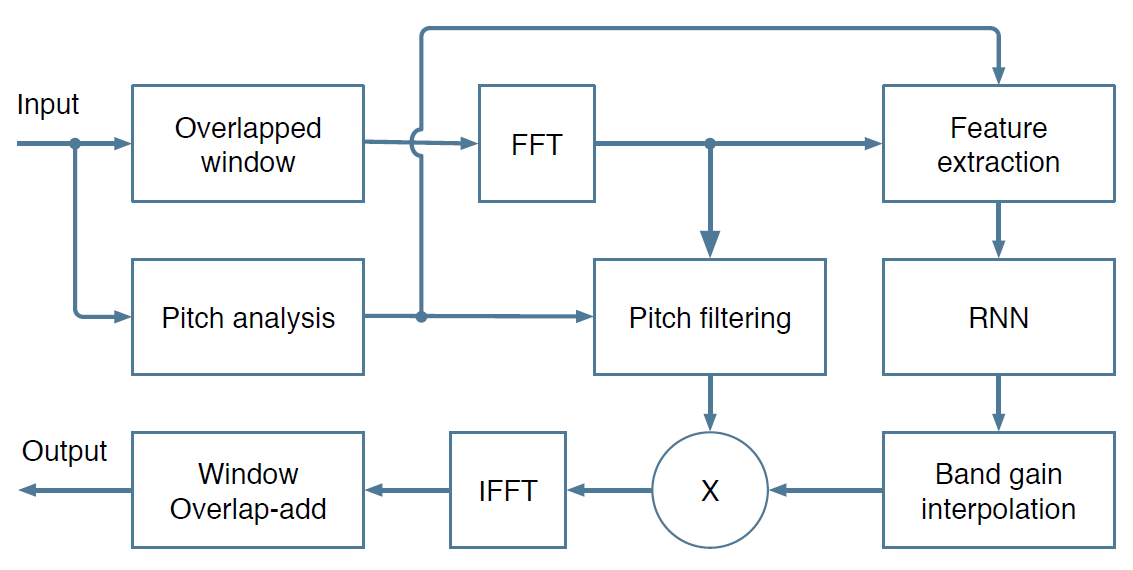 Organigramme de traitement du signal
Organigramme de traitement du signalCette approche hybride diffère des réseaux de bout en bout, où le réseau neuronal prend en charge absolument ou presque tout le traitement du son. Bien sûr, ces systèmes se sont révélés efficaces, mais les développeurs de RNNoise les considèrent comme trop complexes et gourmandes en ressources. Par exemple, dans le
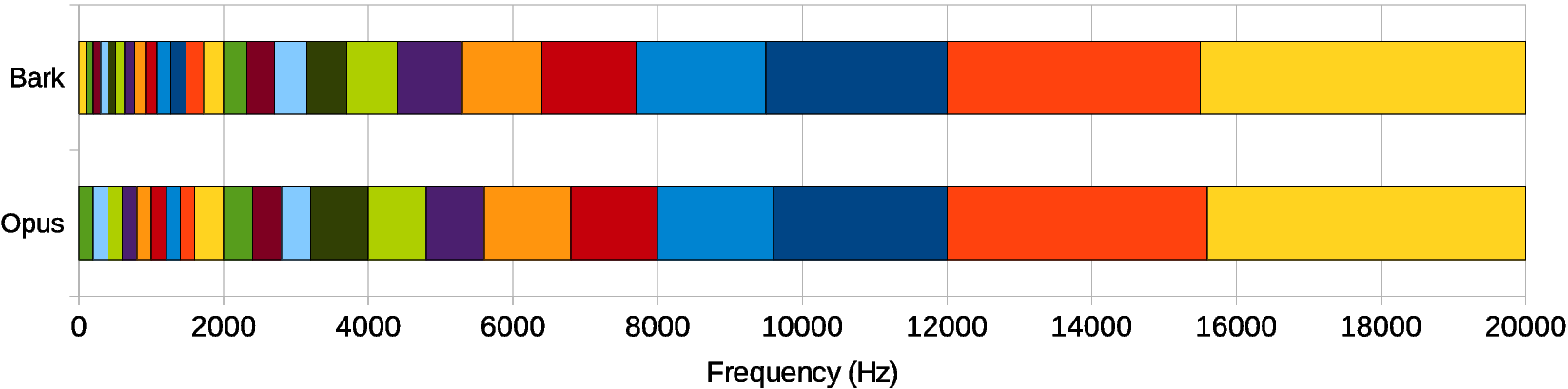
réseau de réduction du bruit RNN de Google (2012), il estime directement les valeurs de fréquence. Pour traiter le son à 8 kHz, il utilise 6144 blocs dans des couches cachées et environ 10 millions d'indicateurs de poids. La mise à l'échelle de la parole à 48 kHz avec des trames de 20 ms crée un système trop complexe avec plus de 400 signaux de sortie (de 0 à 20 kHz). il ne sera certainement pas tiré par le Raspberry Pi. L'objectif de Mozilla était de rendre le modèle simple et rapide, ils ont donc adopté une approche hybride. De plus, ils ont généralement abandonné le travail direct avec les échantillons et le spectre, et ont plutôt divisé le spectre en 22 gammes - et les ont analysés, et non 480 valeurs spectrales (complexes) qui devraient être analysées autrement. Ces 22 gammes correspondent à la perception humaine du son à l'oreille, conformément à l'
échelle psychoacoustique
des aboiements . Une distribution similaire est utilisée dans le codec Opus, et ici Mozilla a emprunté le modèle de base, ne l'ajustant que légèrement.
Cette approche s'est avérée efficace. Le programme ne consomme qu'une part modeste des ressources informatiques du processeur ARM Cortex-A53 fonctionnant à 1,2 GHz (Raspberry Pi 3).
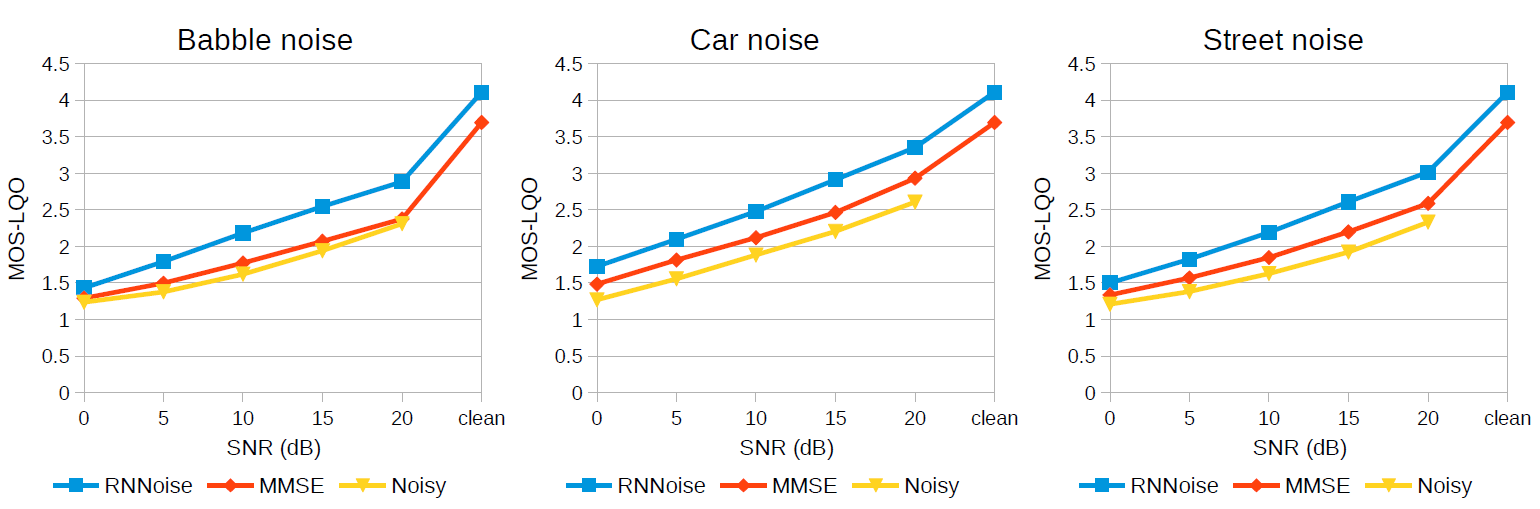
Des tests comparatifs ont montré que l'utilisation d'un réseau neuronal améliore considérablement la qualité de la réduction du bruit. Les diagrammes montrent la réduction du bruit des conversations en arrière-plan (à gauche), des voitures (au centre) et du bruit de la rue (à droite) par rapport à
la bibliothèque SpeexDSP basée sur MMSE .
Désormais, les développeurs demandent à tous les utilisateurs de
donner leur bruit à des fins scientifiques, c'est-à-dire pour former le réseau neuronal. Vous pouvez enregistrer du bruit directement en ligne. Ils vous demandent de le faire dans n'importe quel environnement où la conversation vocale est possible, c'est-à-dire littéralement n'importe où: cela peut être votre voiture, votre bureau, votre rue ou n'importe quel endroit où vous pouvez communiquer par téléphone ou par ordinateur. Sur la page d'enregistrement du bruit, cliquez simplement sur le bouton «Enregistrer» et restez silencieux pendant 1 minute. Pour former le réseau neuronal, vous devez également indiquer dans quel environnement particulier vous avez enregistré le silence (bruit).
Un article scientifique (pdf) décrivant RNNoise n'a pas encore été soumis pour publication dans une revue scientifique.