Quel que soit le fabricant ou le type de RAM, presque toute la mémoire de l'ordinateur contient une sorte de microdéfauts. Un fabricant de mémoire peut dépenser entre 10 et 15% du coût d'un module DIMM pour des tests approfondis d'erreurs, mais la mémoire peut toujours être sujette à des pannes et des pannes pendant le fonctionnement du système. Une grande variété de facteurs - du chauffage excessif au «vieillissement» et à la présence de micro-défauts en elle - peuvent entraîner des erreurs de mémoire.

En fait, les taux d'erreur de la mémoire dynamique à accès aléatoire (DRAM) sont de plusieurs ordres de grandeur supérieurs à ceux des rapports. Dans une récente étude à grande échelle des erreurs DRAM sur le terrain basée sur des données collectées sur deux ans, environ un tiers de toutes les machines et plus de 8% des modules DIMM ont enregistré au moins une erreur corrigible par an (
erreurs DRAM dans la nature: une grande étude de terrain à grande échelle ). Sur certaines plates-formes, dans près de 50% des systèmes, des erreurs corrigibles se sont produites (rapport IBID), et en moyenne, seulement 1,3% environ des systèmes ont été soumis à des erreurs irréparables, et pour certaines plates-formes, ce chiffre était de 2 à 4%.
Sur les ordinateurs de bureau standard, les erreurs de mémoire affectent rarement les performances des logiciels d'application standard. Cependant, dans les systèmes haut de gamme avec des calculs intensifs dans le monde de la finance, la recherche dans le domaine du pétrole et du gaz, dans les tâches d'imagerie médicale, de production de supports (rendu et édition), etc. l'intégrité des données est une composante essentielle de l'architecture globale du système. Dans de tels systèmes hautes performances, le remplacement de la mémoire est l'un des premiers endroits à réparer en raison de composants défaillants, et les erreurs de mémoire sont l'un des problèmes matériels les plus courants pouvant entraîner des pannes du système (rapport IBID).

Ainsi, la capacité de détecter, signaler et prévenir les erreurs DIMM dans les postes de travail hautes performances devient une nécessité.
Compte tenu de la forte demande de performances RAM extrêmes, Dell a breveté une technologie innovante et exclusive utilisée dans les stations de travail Dell Precision qui permet de marquer et de mettre hors service la mémoire inutilisable. Cette fonctionnalité unique de Dell permet de réduire les temps d'arrêt du système, de simplifier le support informatique et de réduire les coûts de maintenance globaux, en augmentant la longévité de la mémoire et en augmentant la productivité des utilisateurs.
Examinons les concepts de base de Dell Reliable Memory Technology PRO (RMT PRO), certaines des principales causes d'erreurs de mémoire et comment RMT PRO aide à résoudre ces erreurs.
RAM
Parallèlement aux nouvelles avancées de la technologie des processeurs, aux vitesses de bus accrues et aux améliorations de l'architecture globale, les systèmes informatiques deviennent plus complexes et la RAM doit également suivre ces changements.

Essentiellement (très simplifiées), les puces DRAM sont un tableau d'éléments avec des états marche / arrêt qui conservent cet état (1 ou 0) lorsqu'il y a de la puissance. Lorsque l'alimentation est coupée, ils reviennent à l'état zéro. Plusieurs puces sont assemblées dans un sous-système de mémoire et placées sur une carte de circuit imprimé - un DIMM (module de mémoire double en ligne).
La plupart des stations de travail, telles que Dell Precision, utilisent le type DIMM appelé DDR4 SDRAM, un périphérique de stockage dynamique synchrone à accès aléatoire. Essentiellement, par rapport aux versions antérieures des types de mémoire (par exemple DDR3), DDR4 est plus rapide, a une bande passante plus élevée et une densité de mémoire plus élevée, et nécessite moins d'alimentation.
Erreurs de mémoire
Les erreurs de mémoire peuvent être causées par un grand nombre de facteurs, à la suite desquels un bit DRAM passe automatiquement à l'état opposé (par exemple, de 1 à 0, lorsque pendant ce cycle la mémoire doit rester à 1). Les erreurs peuvent être affectées par des facteurs tels que la surchauffe, l'âge de la mémoire, les défauts, etc. Comme les études l'ont montré, au cours des 10 premiers mois de fonctionnement du module DIMM, le niveau d'erreurs augmente fortement.
Ces types d'erreurs sont appelés erreurs récupérables: ils endommagent aléatoirement les bits, mais ne laissent pas de dommages physiques et peuvent être corrigés en mettant à jour l'état de la mémoire.
Cependant, dans de nombreux cas, des erreurs non corrigibles se produisent. Il s'agit d'une erreur binaire répétée due à un défaut physique ou à une autre anomalie du module DIMM, ou lorsque deux erreurs se produisent simultanément dans le même bloc de mémoire. Une erreur de mémoire irrécupérable peut entraîner un plantage du système (un redémarrage est nécessaire) ou une application (code d'erreur d'arrêt au niveau du système, vidage du noyau ou «écran bleu de la mort» - BSoD). Des erreurs fréquemment corrigibles avertissent des erreurs fatales imminentes. Dans les études, environ 65 à 80% des erreurs non corrigibles au cours du même mois ont été précédées d'une erreur corrigeable.
Gestion des erreurs
Aujourd'hui, de nombreux PC de classe station de travail incluent des algorithmes de parité de mémoire qui, tout simplement, garantissent que chaque fois qu'un octet de données est lu, les données envoyées correspondent aux données reçues.

Les systèmes plus complexes utilisent d'autres méthodes de correction et de détection des erreurs. L'option la plus courante est la mémoire de code de correction d'erreur (ECC). Il est utilisé sur les serveurs et les postes de travail, tels que les postes de travail Dell Precision. En fait, la mémoire ECC comprend des bits supplémentaires et un contrôleur de mémoire intégré qui vérifie la parité de la mémoire, et dans le cas d'une erreur sur un bit, la logique de la mémoire ECC peut corriger l'erreur et produire les données corrigées afin que le système continue de fonctionner.
ECC gère la correction des erreurs de mémoire isolées et garantit un fonctionnement stable du système. Cependant, la mémoire ECC ne fournit pas de solution pour plusieurs erreurs dans un seul bloc de mémoire. Dans ces cas, une corruption des données se produit. Dans cette situation, Dell Reliable Memory Technology PRO peut vous aider.
Avantages de la technologie RMT PRO
Si la plaque du disque dur est physiquement endommagée, le secteur défectueux sera marqué comme inutilisable par le système PC. Cependant, sur la plupart des ordinateurs, y compris les postes de travail avec mémoire ECC, une erreur fatale ou plusieurs erreurs corrigibles dans le même bloc de mémoire sur le module DIMM peuvent provoquer un blocage du système. L'utilisateur, en règle générale, est obligé de signaler une telle erreur à son service d'assistance, qui, à son tour, doit exécuter un certain programme de diagnostic pour détecter l'erreur. Souvent, une seule défaillance peut nécessiter le remplacement de l'intégralité du module DIMM.
Le résultat est une augmentation des temps d'arrêt, une productivité réduite, une perte de temps du personnel informatique, la nécessité de remplacer les modules DIMM et des dommages possibles aux fichiers d'application clés.

La technologie Dell Reliable Memory Technology PRO (RMT PRO) vient à la rescousse.
Similaire dans son concept à la technologie de correction d'erreurs du disque dur, RMT PRO détecte les erreurs fatales et les erreurs corrigeables sur plusieurs bits dans le module DIMM et résout le problème. Au lieu de temps d'arrêt coûteux, exécuter des diagnostics, ouvrir le système et remplacer un module DIMM défectueux par la technologie RMT PRO au redémarrage:
- Marque la partie défectueuse d'un seul module DIMM.
- Signale le défaut et l'emplacement du module DIMM défaillant dans le BIOS.
- Supprime ces cellules défectueuses et un petit nombre de cellules voisines du pool de mémoire système utilisée.
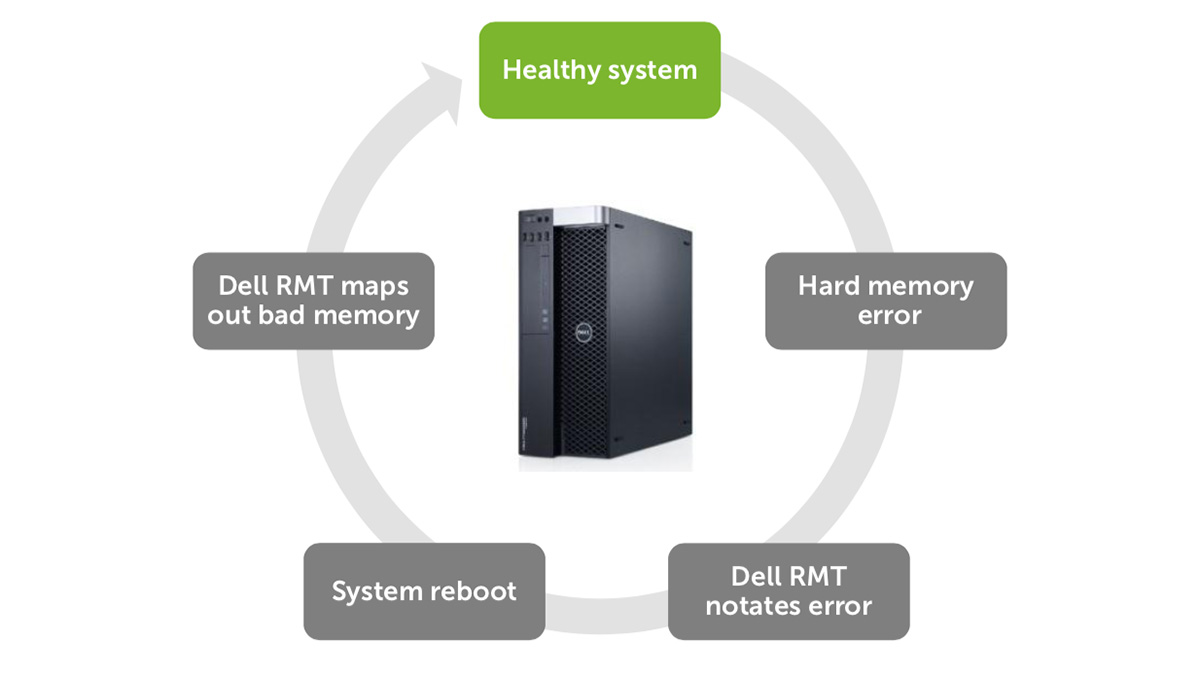
Après un simple redémarrage, le RMT PRO rend la zone défectueuse invisible pour le système d'exploitation. Les applications et les fonctions critiques du système «contourneront» la zone marquée et continueront de fonctionner sans avoir à remplacer l'équipement. Tout sera comme si la mauvaise mémoire n'avait jamais existé. Cela garantit un fonctionnement ininterrompu, réduit le nombre de plantages système et d'erreurs d'application.
RMT PRO peut réduire les coûts matériels - modules de mémoire. Étant donné que la mémoire peut se détériorer avec une utilisation intensive ou une chaleur excessive (généralement en raison d'une charge élevée), le nombre d'erreurs physiques peut augmenter. Malgré la «mauvaise mémoire», les informations restent sur le module DIMM. De plus, si le remplacement des modules DIMM est requis, RMT PRO affichera dans le BIOS exactement quels modules DIMM provoquent des erreurs, accélérant le dépannage et le remplacement des modules DIMM, ce qui permet de réduire les temps d'arrêt et le coût global du service. Ainsi, la technologie RMT PRO prolonge le cycle de vie de la mémoire et permet d'économiser de l'argent.

Conclusions
Bien que certains schémas de détection d'erreurs, tels que la mémoire ECC, puissent détecter des erreurs de mémoire, bon nombre de ces algorithmes ne gèrent que les erreurs corrigibles. Lorsque des défauts physiques ou des erreurs fatales se produisent dans le module DIMM, Dell RMT PRO offre un niveau supplémentaire de détection et de correction de la mémoire défectueuse.
En faisant correspondre et en supprimant les secteurs défectueux, la technologie RMT PRO permet aux applications informatiques intensives d'accéder uniquement à la mémoire utilisable. Cela peut entraîner des économies importantes de temps et d'argent en raison d'une réduction du temps requis pour remplacer l'équipement et les modules DIMM, et pour réduire les temps d'arrêt de l'équipement. Lorsque l'intégrité des données est critique, RMT PRO offre le bon niveau de confiance en fournissant la mémoire disponible pour maximiser la productivité et la fiabilité de la station de travail.