La traduction automatique à l'aide de réseaux de neurones a
parcouru un long chemin depuis le moment de la première recherche scientifique sur ce sujet jusqu'au moment où Google a annoncé le
transfert complet du service Google Translate au deep learning .
Comme vous le savez, la base du traducteur neuronal est le mécanisme des réseaux neuronaux récurrents bidirectionnels, basé sur des calculs matriciels, qui vous permet de construire des modèles probabilistes beaucoup plus complexes que les traducteurs automatiques statistiques. Cependant, on a toujours cru que la traduction neuronale, comme la traduction statistique, nécessitait des textes bilingues parallèles pour la formation. Un réseau de neurones est en cours de formation sur ces bâtiments, prenant une traduction humaine comme référence.
Comme il s'est avéré maintenant, les réseaux de neurones sont capables de maîtriser une nouvelle langue pour la traduction même sans corpus parallèle de textes!
Deux ouvrages sur ce sujet ont été publiés sur le site de préimpression arXiv.org.
«Imaginez que vous donnez à une personne beaucoup de livres chinois et beaucoup de livres arabes - il n'y a pas de livres identiques parmi eux - et cette personne apprend à traduire du chinois vers l'arabe. Cela semble impossible, non? Mais nous avons montré qu'un ordinateur en est capable »,
explique Mikel Artetxe, informaticien à l'Université du Pays Basque à Saint-Sébastien (Espagne).
La plupart des réseaux de neurones de traduction automatique sont enseignés «avec un professeur», dont le rôle est précisément le corpus parallèle de textes traduits par l'homme. Dans le processus d'apprentissage, grosso modo, le réseau neuronal fait une hypothèse, vérifie par rapport à la norme, effectue les réglages nécessaires dans ses systèmes, puis apprend davantage. Le problème est que pour certaines langues dans le monde il n'y a pas un grand nombre de textes parallèles, donc ils ne sont pas disponibles pour les réseaux neuronaux de traduction automatique traditionnels.
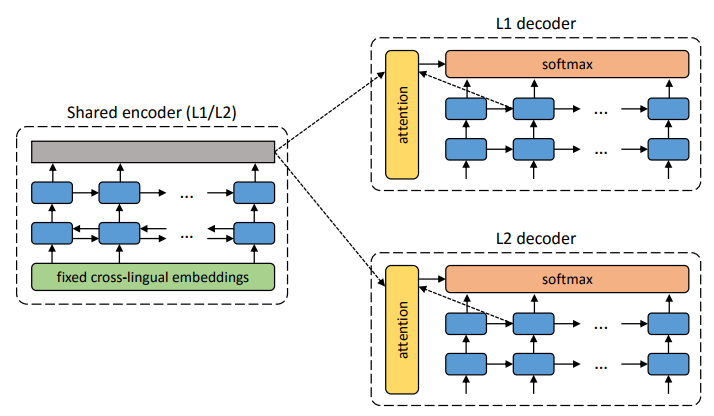
Deux nouveaux modèles proposent une nouvelle approche: enseigner un réseau de neurones de traduction automatique
sans professeur . Le système lui-même essaie de constituer une sorte de corpus parallèle de textes, regroupant les mots les uns autour des autres. Le fait est que dans la plupart des langues du monde, il y a les mêmes significations, qui correspondent simplement à des mots différents. Ainsi, toutes ces significations sont regroupées en grappes identiques, c'est-à-dire que les mêmes significations de mots sont regroupées autour des mêmes significations de mots, presque indépendamment de la langue (voir l'article "
Google Translate Neural Network a compilé une base unifiée de la signification des mots humains ") .
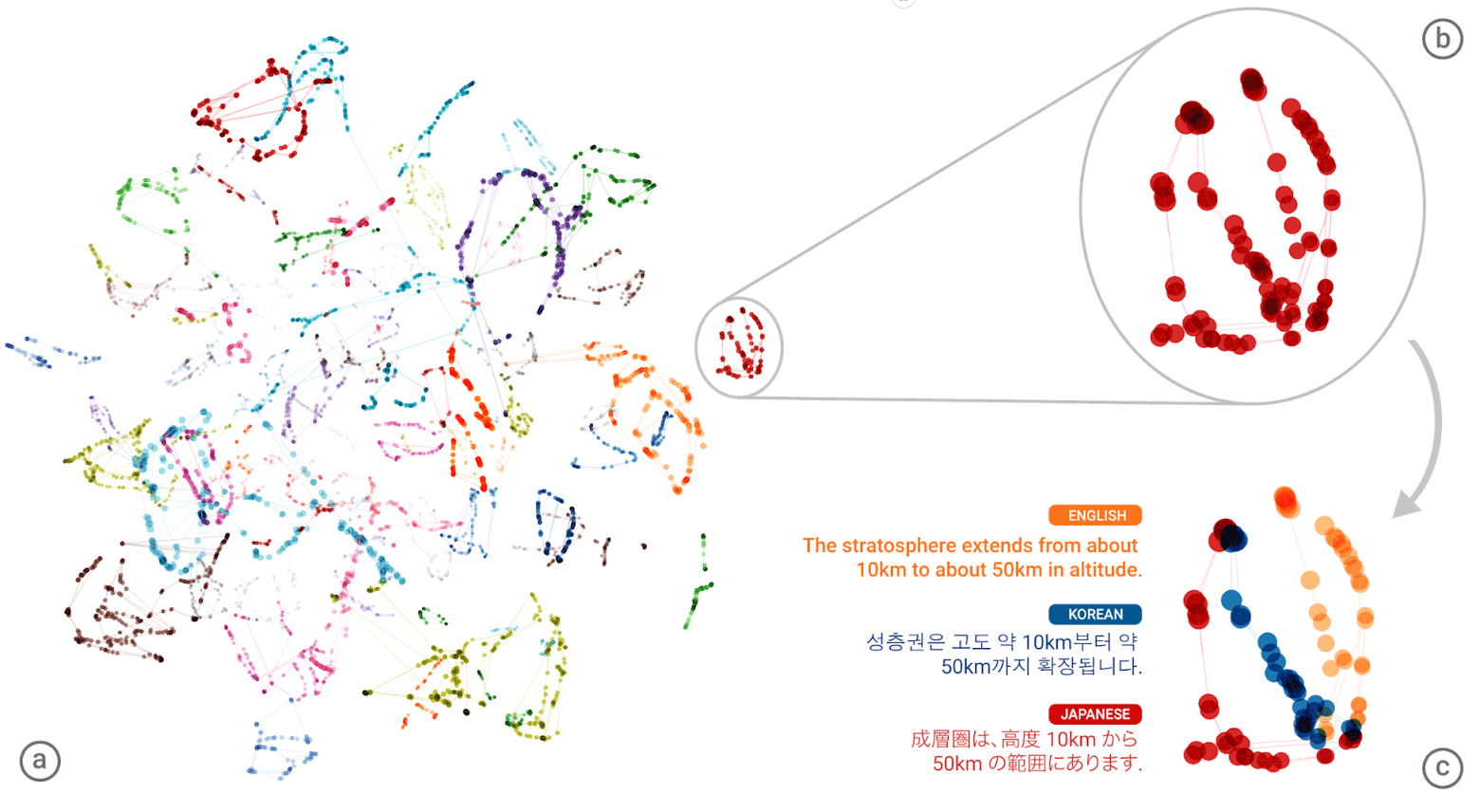 Le «langage universel» du réseau neuronal Google Neural Machine Translation (GNMT). Des groupes de significations de chaque mot sont affichés dans différentes couleurs sur l'illustration de gauche, les significations inférieures sont les significations de mots obtenues pour lui à partir de différentes langues humaines: anglais, coréen et japonais
Le «langage universel» du réseau neuronal Google Neural Machine Translation (GNMT). Des groupes de significations de chaque mot sont affichés dans différentes couleurs sur l'illustration de gauche, les significations inférieures sont les significations de mots obtenues pour lui à partir de différentes langues humaines: anglais, coréen et japonaisAprès avoir compilé un gigantesque «atlas» pour chaque langue, le système essaie de superposer un tel atlas sur une autre - et voilà, vous êtes prêt à avoir une sorte de corpus de texte parallèle!
Vous pouvez comparer les modèles des deux architectures d'apprentissage sans enseignant proposées.
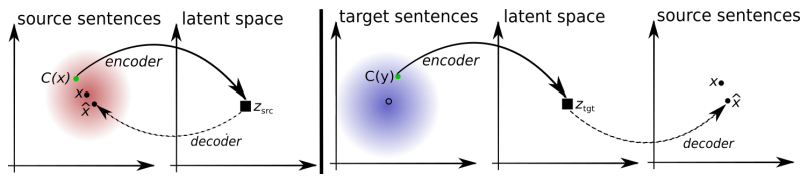
 L'architecture du système proposé. Pour chaque phrase du langage L1, le système apprend l'alternance de deux étapes: 1) débruitage , qui optimise la probabilité de coder une version bruyante de la phrase avec un codeur commun et sa reconstruction par le décodeur L1; 2) rétrotraduction, lorsqu'une phrase est traduite en mode de sortie (c'est-à-dire codée par un codeur commun et décodée par le décodeur L2), puis la probabilité de coder cette phrase traduite avec un codeur commun et de restaurer la phrase originale par le décodeur L1 est optimisée. Illustration: article scientifique de Mikel Artetks et al.
L'architecture du système proposé. Pour chaque phrase du langage L1, le système apprend l'alternance de deux étapes: 1) débruitage , qui optimise la probabilité de coder une version bruyante de la phrase avec un codeur commun et sa reconstruction par le décodeur L1; 2) rétrotraduction, lorsqu'une phrase est traduite en mode de sortie (c'est-à-dire codée par un codeur commun et décodée par le décodeur L2), puis la probabilité de coder cette phrase traduite avec un codeur commun et de restaurer la phrase originale par le décodeur L1 est optimisée. Illustration: article scientifique de Mikel Artetks et al.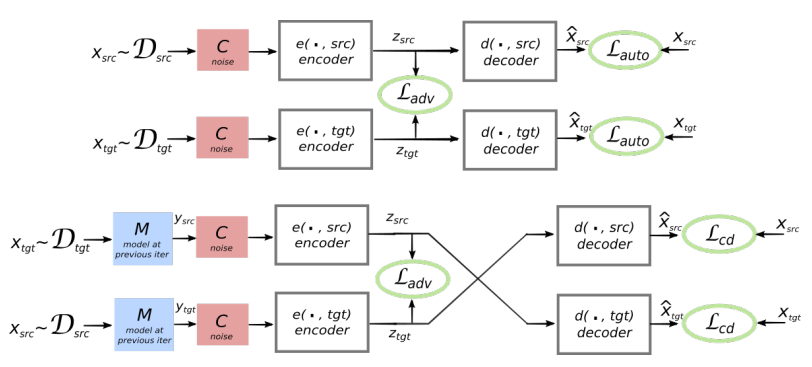 L'architecture proposée et les objectifs d'apprentissage du système (à partir du deuxième travail scientifique). L'architecture est un modèle de traduction de phrases, où l'encodeur et le décodeur fonctionnent dans deux langues, selon l'identifiant de la langue d'entrée, qui permute les tables de recherche. Ci-dessus (auto-codage): le modèle apprend à effectuer une réduction du bruit dans chaque domaine. Ci-dessous (traduction): comme précédemment, plus nous encodons à partir d'une autre langue, en utilisant comme entrée la traduction produite par le modèle dans l'itération précédente (rectangle bleu). Les ellipses vertes indiquent les termes de la fonction de perte. Illustration: article scientifique de Guillaume Lampl et al.
L'architecture proposée et les objectifs d'apprentissage du système (à partir du deuxième travail scientifique). L'architecture est un modèle de traduction de phrases, où l'encodeur et le décodeur fonctionnent dans deux langues, selon l'identifiant de la langue d'entrée, qui permute les tables de recherche. Ci-dessus (auto-codage): le modèle apprend à effectuer une réduction du bruit dans chaque domaine. Ci-dessous (traduction): comme précédemment, plus nous encodons à partir d'une autre langue, en utilisant comme entrée la traduction produite par le modèle dans l'itération précédente (rectangle bleu). Les ellipses vertes indiquent les termes de la fonction de perte. Illustration: article scientifique de Guillaume Lampl et al.Les deux articles scientifiques utilisent une technique sensiblement similaire avec de légères différences. Mais dans les deux cas, la traduction s'effectue à travers un «langage» intermédiaire ou, mieux, une dimension ou un espace intermédiaire. Jusqu'à présent, les réseaux de neurones sans enseignant ne montrent pas une qualité de traduction très élevée, mais les auteurs disent qu'il est facile de s'améliorer si vous utilisez un peu d'aide d'un enseignant, tout à l'heure pour la pureté de l'expérience qu'ils n'ont pas faite.
A noter que le deuxième travail scientifique a été publié par des chercheurs de la division Facebook AI.
Les travaux sont présentés pour la Conférence internationale sur les représentations d'apprentissage 2018. Aucun article n'a encore été publié dans la presse scientifique.