Début novembre 2017, Qualcomm Datacenter Technologies (QDT) a achevé les travaux sur sa nouvelle invention - un processeur basé sur la technologie 10 nm - Centriq 2400. Quel avenir attend l'industrie selon les créateurs de cette innovation? Quels sont les avantages d'obtenir des serveurs et pourquoi le Centriq 2400 est-il si unique? En savoir plus à ce sujet et plus encore.
Le 8 novembre, une conférence de presse de QDT s'est tenue à San Jose (Californie), au cours de laquelle le début des livraisons du nouveau processeur a été officiellement annoncé. Anand Chandrasekher, vice-président principal et chef de la direction, a déclaré:
La présentation d'aujourd'hui est une réalisation importante et l'aboutissement de plus de 4 ans de conception, de développement et de soutien diligents du système ... Nous avons créé le processeur de serveur le plus avancé au monde, qui offre des performances élevées combinées à un haut niveau d'efficacité énergétique, permettant à nos clients de réduire considérablement leurs coûts.
Outre la fierté non dissimulée de leur produit, les représentants de l'entreprise n'hésitent pas à déclarer que leur processeur Centriq 2400 est nettement supérieur aux produits concurrents, par exemple Intel Xeon Platinum 8180. Selon leurs calculs, pour chaque dollar dépensé (et le coût du processeur est de 1995 $), l'utilisateur obtiendra des performances dans 4 fois. Et lorsque recalculé en performances de 1 watt - de 45% de plus. Des déclarations audacieuses, cependant, de nombreux représentants de diverses sociétés intéressées par le nouveau produit sont plus qu'heureux de les entendre.
Spécifications techniques du Qualcomm Centriq 2400
Architecture CPU:- jusqu'à 48 cœurs 64 bits avec une fréquence de pointe de 2,6 GHz;
- Compatibilité Armv8
- AArch64 uniquement;
- Armv8 FP / SIMD;
- Extension de CRC et Armv8 Crypto;
Cache CPU:- 64 Ko de cache d'instructions (instructions) L1 et 24 Ko de cache à cycle unique L0;
- Cache de données L1 de 32 Ko;
- 512 Ko de cache L2 total pour 2 cœurs;
- 60 Mo de cache L3 partagé;
- filtrage des requêtes interprocesseurs L2;
- QoS;
où, L (L1, L2, L3, L0) est le niveau, c'est-à-dire L0 est le niveau zéro.La technologie:- La technologie FinFET 10 nm de Samsung;
Bande passante mémoire:- 6 canaux pour connecter des modules de mémoire DDR4;
- jusqu'à 2667 MT / s par connexion;
- 128 Go / s - bande passante totale maximale;
- Compression de bande passante intégrée
Capacité mémoire:- 768 Go = 128 Go x 6 connexions;
Type de mémoire:- Connexions DDR4 64 bits avec ECC 8 bits;
- RDIMM et LRDIMM;
Interface prise en charge:- GPIO
- I²C;
- SPI
- SATA 8 bandes Gen 3;
- 32 PCIe Gen3 avec la possibilité de connecter jusqu'à 6 contrôleurs PCIe;
En plus des caractéristiques ci-dessus, il convient de noter que ce processeur possède 18 milliards de transistors sur chaque puce. Et tous ses cœurs sont connectés par un bus en anneau bidirectionnel. À charge maximale, le Centriq 2400 ne consomme que 120 watts.
Le principal objectif du nouveau processeur reste les solutions cloud. Selon les représentants de l'entreprise, Centriq 2400 vous permettra de créer des systèmes de serveurs qui se caractériseront par des performances, une efficacité et une évolutivité élevées.
Cela ne pouvait qu'attirer de nombreuses entreprises, dont les technologies cloud sont presque à la base de leurs activités. Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Cadence Design Systems, Canonical, Chelsio Communications, Excelero, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ont assisté à la présentation. ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Synopsys, Uber, Xilinx. La liste est assez impressionnante, ce qui indique une attention accrue à ce produit.
Pour le moment, le processeur Qualcomm Centriq 2400 ne fait que gagner du terrain, tant en prévalence qu'en popularité. Ce qui, naturellement, conduira à l'émergence de quelque chose de nouveau, similaire ou même plus productif, de la part des concurrents de QDT.
Mais tout le monde ne croit pas aveuglément à la fraîcheur des nouveaux articles. Si ceux qui croient que la réalisation de tests et d'analyses comparatives de plusieurs processeurs vous permettront de voir des résultats bien plus indicatifs que les propos des promoteurs du Centriq 2400.
Cloudflare a effectué une analyse comparative de trois plates-formes: Grantley (Intel), Purley (Intel) et Centriq (Qualcomm).
Ci-dessous seront présentés des graphiques de cette analyse et les conclusions de leur auteur -
Vlad Krasnov . (
Original de cette analyse sur le blog de Cloudflare )
Cryptographie à clé publique
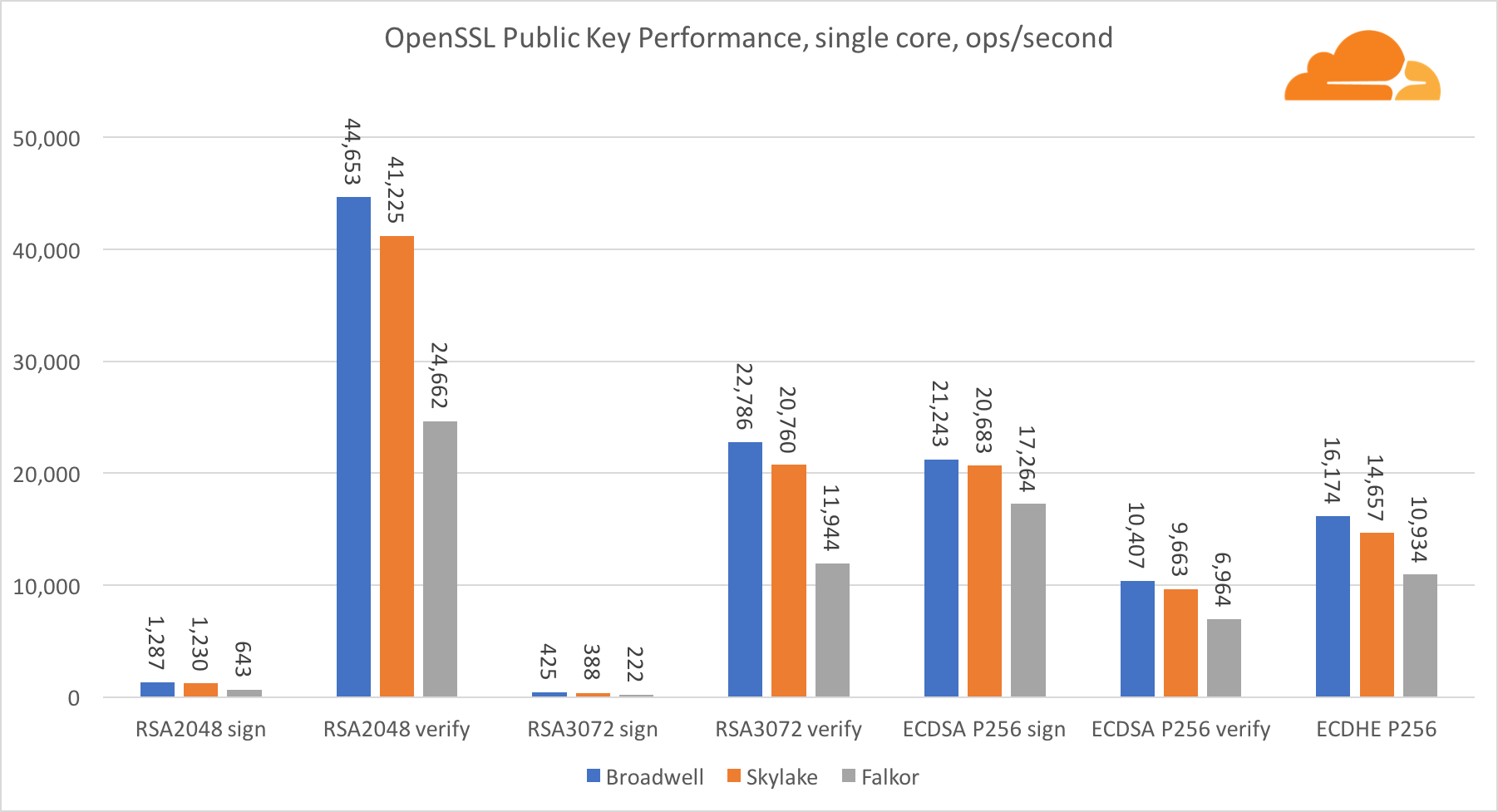
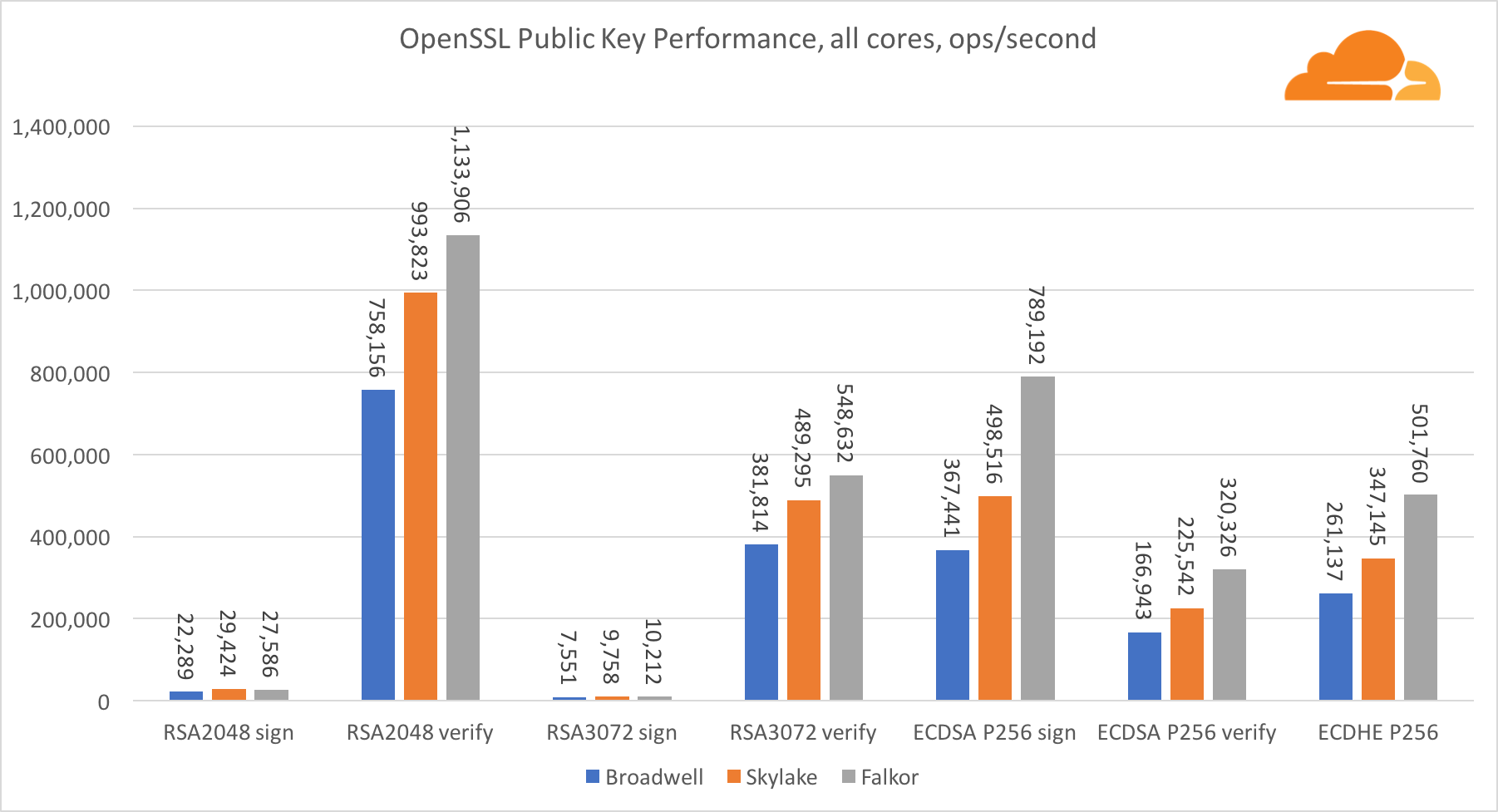
La cryptographie à clé publique est la plus pure performance d'ALU (dispositif de logique arithmétique). Il est intéressant, mais pas surprenant, que dans un référentiel de base, le noyau Broadwell soit plus rapide que Skylake, et les deux soient plus rapides que Falkor. En effet, Broadwell fonctionne à une fréquence plus élevée, bien qu'en termes d'architecture, il ne soit pas très inférieur à Skylake.
Falkor est inférieur aux autres dans ce test. Tout d'abord, le mode turbo a été activé dans l'une des références de base, ce qui signifie que les processeurs Intel fonctionnent à une fréquence plus élevée. De plus, Intel a introduit deux instructions spéciales à Broadwell pour accélérer le traitement des grands nombres: ADCX et ADOX. Ils effectuent deux opérations d'ajout avec report indépendantes par cycle, tandis qu'ARM ne peut en effectuer qu'une seule. De même, le jeu d'instructions ARMv8 n'a pas de commande unique pour effectuer une multiplication 64 bits; à la place, une paire d'instructions MUL et UMULH est utilisée.
Cependant, au niveau SoC, Falkor gagne. Il est légèrement plus lent que Skylake en termes de RSA2048, et uniquement parce que RSA2048 n'a pas d'implémentation optimisée pour ARM. La performance de l'ECDSA est ridiculement élevée. Une seule puce Centriq peut répondre aux besoins de presque toutes les entreprises du monde avec ECDSA.
Il est également très intéressant de voir que Skylake surpasse Broadwell de 30%, malgré le fait qu'il ait perdu un cœur dans le test et ne compte que 20% de cœurs de plus que Broadwell. Cela peut s'expliquer par un mode turbo plus efficace et un hyper-threading amélioré.
Cryptographie symétrique
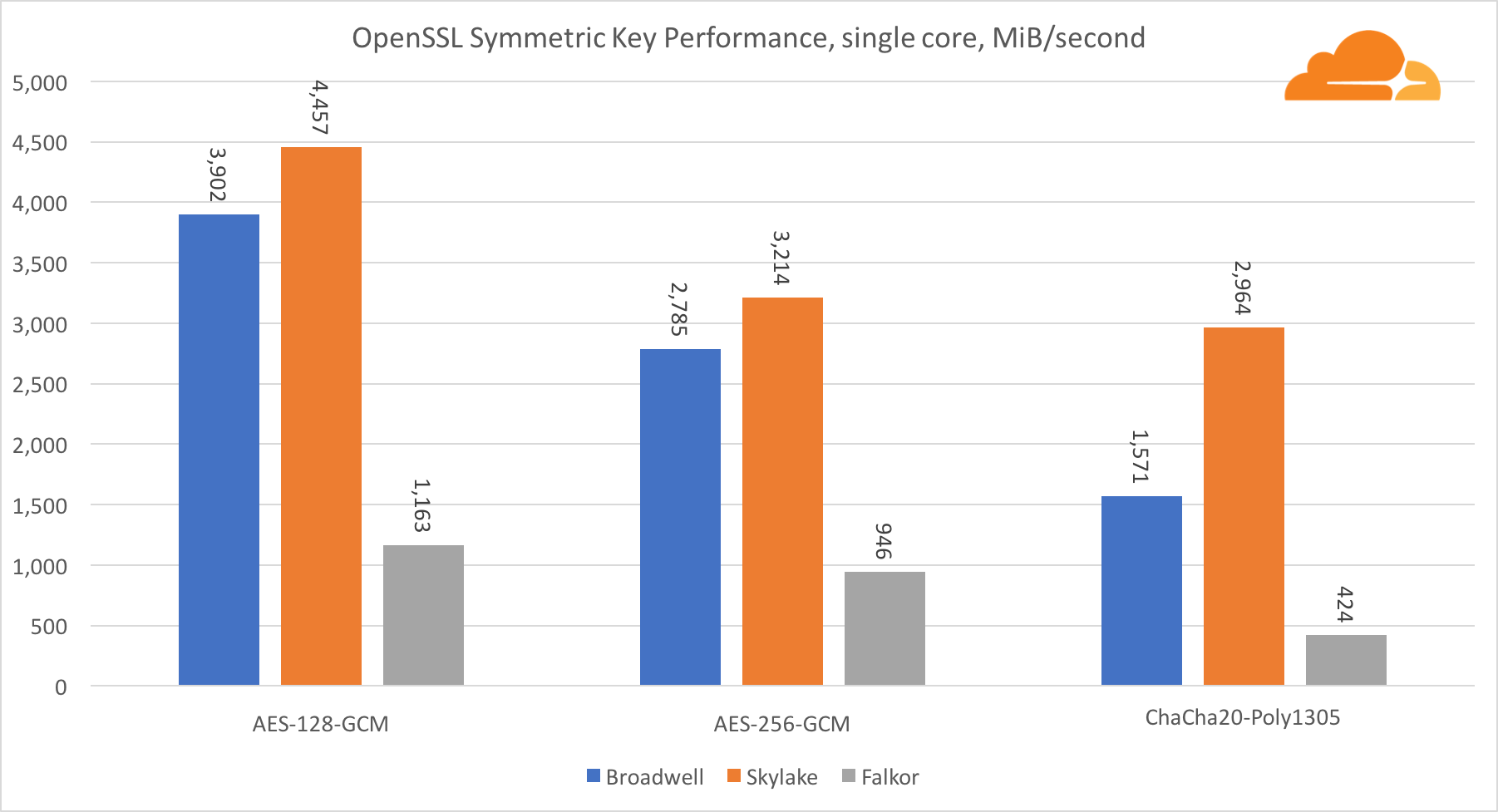
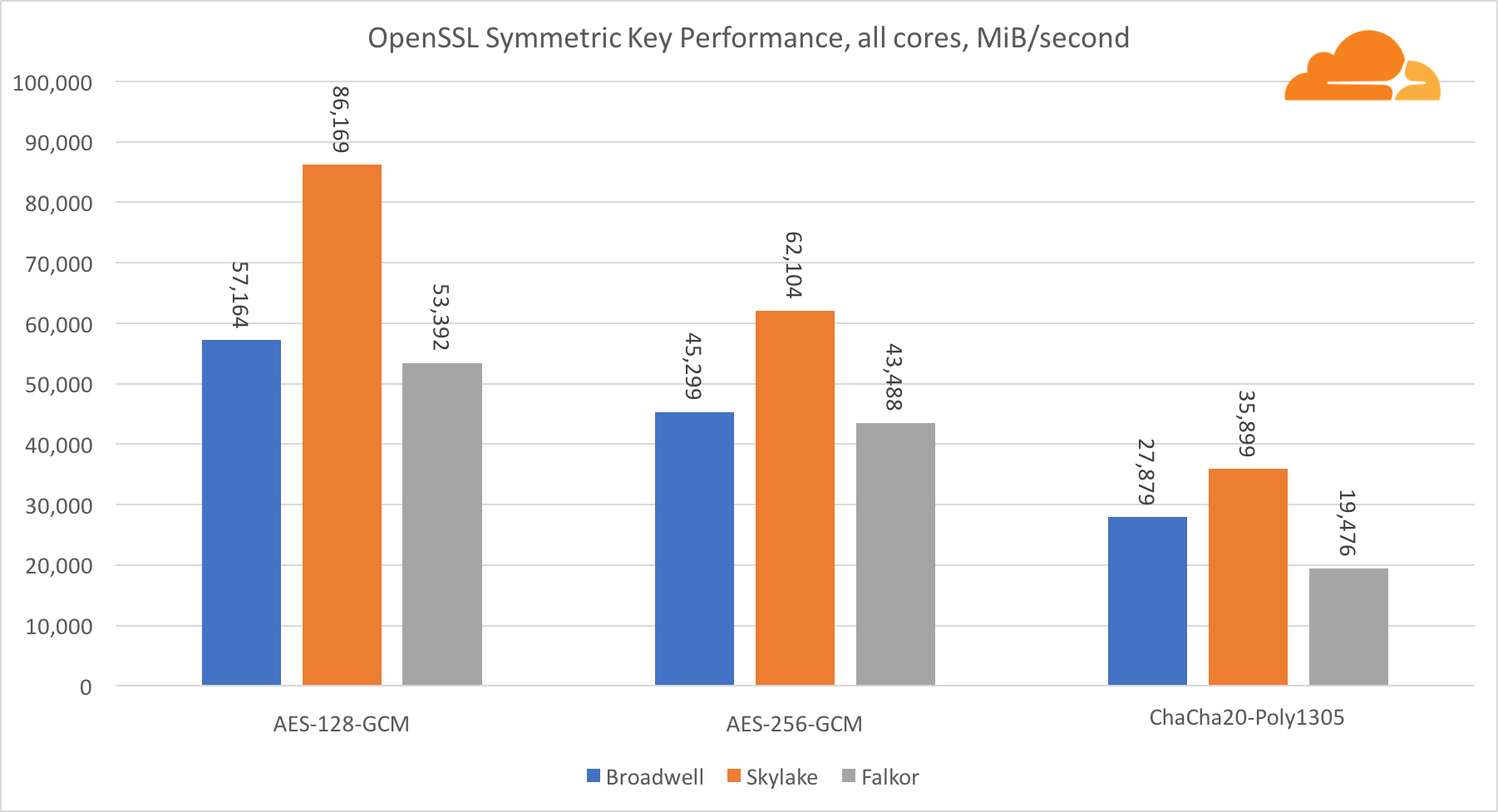
Les performances des cœurs Intel en cryptographie symétrique sont tout simplement excellentes.
AES-GCM utilise une combinaison d'instructions matérielles spéciales pour accélérer AES et CLMUL. Intel a introduit ces instructions pour la première fois en 2010, avec son processeur Westmere et à chaque génération, il a amélioré ses performances. ARM a récemment introduit un ensemble d'instructions similaires avec leur jeu d'instructions 64 bits comme ajout facultatif. Heureusement, tous les fournisseurs d'équipement que je connais les ont mis en œuvre. Il est très probable que Qualcomm améliorera les performances des instructions cryptographiques dans les générations futures.
ChaCha20-Poly1305 est un algorithme plus général conçu de manière à mieux utiliser les modules SIMD larges. Qualcomm n'a que 128 bits NEON SIMD, Broadwell a 256 bits AVX2 et Skylake a 512 bits AVX-512. Cela explique pourquoi Skylake avec une telle marge reste en tête dans l'évaluation du travail avec un seul noyau. Dans le test de tous les cœurs, en même temps, l'écart de Skylake par rapport au reste a été réduit, car il devrait réduire la fréquence d'horloge lors de l'exécution des charges de travail AVX-512. Lors de l'exécution de l'AVX-512 sur tous les cœurs, la fréquence de base diminue à 1,4 GHz. Gardez cela à l'esprit si vous mélangez AVX-512 et un autre code.
La conclusion concernant la cryptographie symétrique est que même si Skylake est en tête, Broadwell et Falkor ont montré de très bons résultats, ayant des performances assez élevées pour les cas réels, étant donné que de notre côté, RSA consomme plus de temps processeur que tous les autres algorithmes cryptographiques combinés .
Compression (compression)
Le prochain test que je voulais faire était la compression. Pour deux raisons. Tout d'abord, il s'agit d'une charge de travail importante, car plus la compression est bonne, moins il y a de lacunes dans les capacités, et cela permet une livraison plus rapide du contenu au client. Deuxièmement, il s'agit d'une charge de travail de mauvaise prédiction de branche haute fréquence très exigeante.
Évidemment, le premier test sera la populaire bibliothèque zlib. Chez Cloudflare, nous utilisons une version améliorée de la bibliothèque optimisée pour les processeurs Intel 64 bits, et bien qu'elle soit écrite principalement en C, elle utilise certaines fonctionnalités intégrées spécifiques à Intel. Il serait injuste de comparer cette version optimisée avec le zlib d'origine. Mais ne vous inquiétez pas, un petit effort et j'ai adapté la bibliothèque pour qu'elle fonctionne sur l'architecture ARMv8, en utilisant les propriétés NEON et CRC32. De plus, sa vitesse est 2 fois supérieure à celle d'origine, pour certains fichiers.
Le deuxième test est la nouvelle bibliothèque brotli, écrite en C et permettant l'utilisation de conditions égales pour toutes les plateformes.
Tous les tests ont été effectués sur HTML blog.cloudflare.com, en mémoire, de la même manière que NGINX effectue la compression de streaming. Sauf si la version spécifique du fichier HTML fait 29329 octets, ce qui est un bon indicateur, car il correspond à la taille de la plupart des fichiers que nous compressons. Le test de compression parallèle est la compression parallèle de plusieurs fichiers en même temps, la compression unique est la compression d'un fichier en plusieurs flux, similaire au fonctionnement de NGINX.
gzip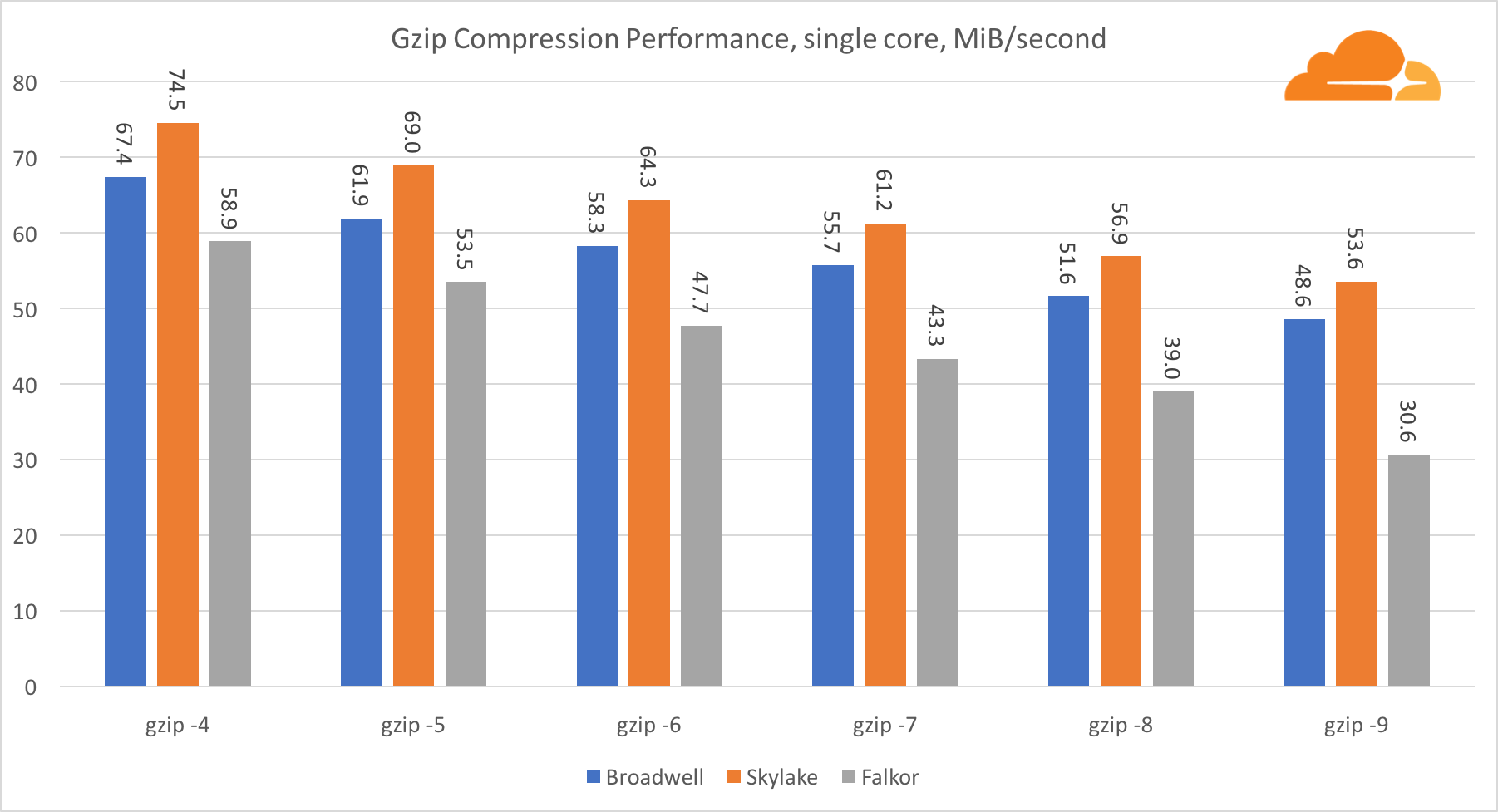
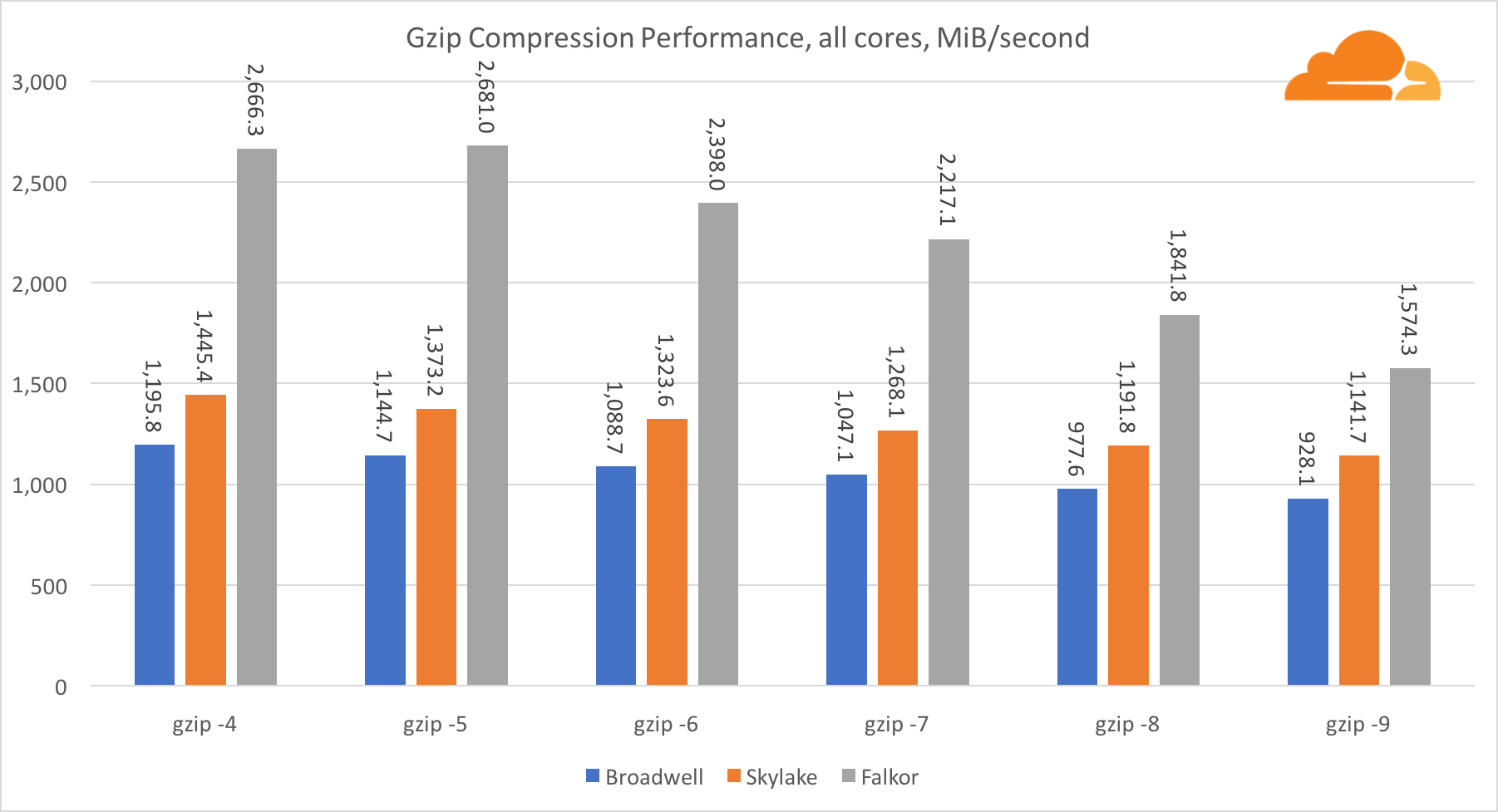
En utilisant gzip au niveau du noyau unique, Skylake gagne sans aucun doute. Avec une fréquence inférieure à Broadwell, Skylake bénéficie d'une exposition moindre à la mauvaise prédiction des branches. Le noyau Falkor n'est pas loin derrière. Au niveau du système, Falkor fonctionne beaucoup mieux avec plus de cœurs. Remarquez comment gzip évolue bien sur plusieurs cœurs.
BrotliAvec brotli sur un noyau, la situation est similaire à la précédente. Skylake est le plus rapide, mais Falkor n'est pas loin derrière. Et sur la norme 9, Falkor est encore plus rapide. Le Standard 4 Brotli est très similaire au gzip niveau 5, tandis que la compression réelle est toujours meilleure (8010B contre 8187B).
Lors de la compression sur plusieurs cœurs, la situation devient un peu confuse. Pour les niveaux 4, 5 et 6, brotli évolue très bien. Aux niveaux 7 et 8, il commence à chuter de manière productive sur le cœur, s'enfonçant au fond au niveau 9, où nous obtenons 3 fois moins de productivité de tous les cœurs par rapport à un.
À mon avis, cela est dû au fait qu'à chaque niveau, brotli commence à consommer plus de mémoire et bloque le cache. Les indicateurs commencent déjà à se redresser aux niveaux 10 et 11.
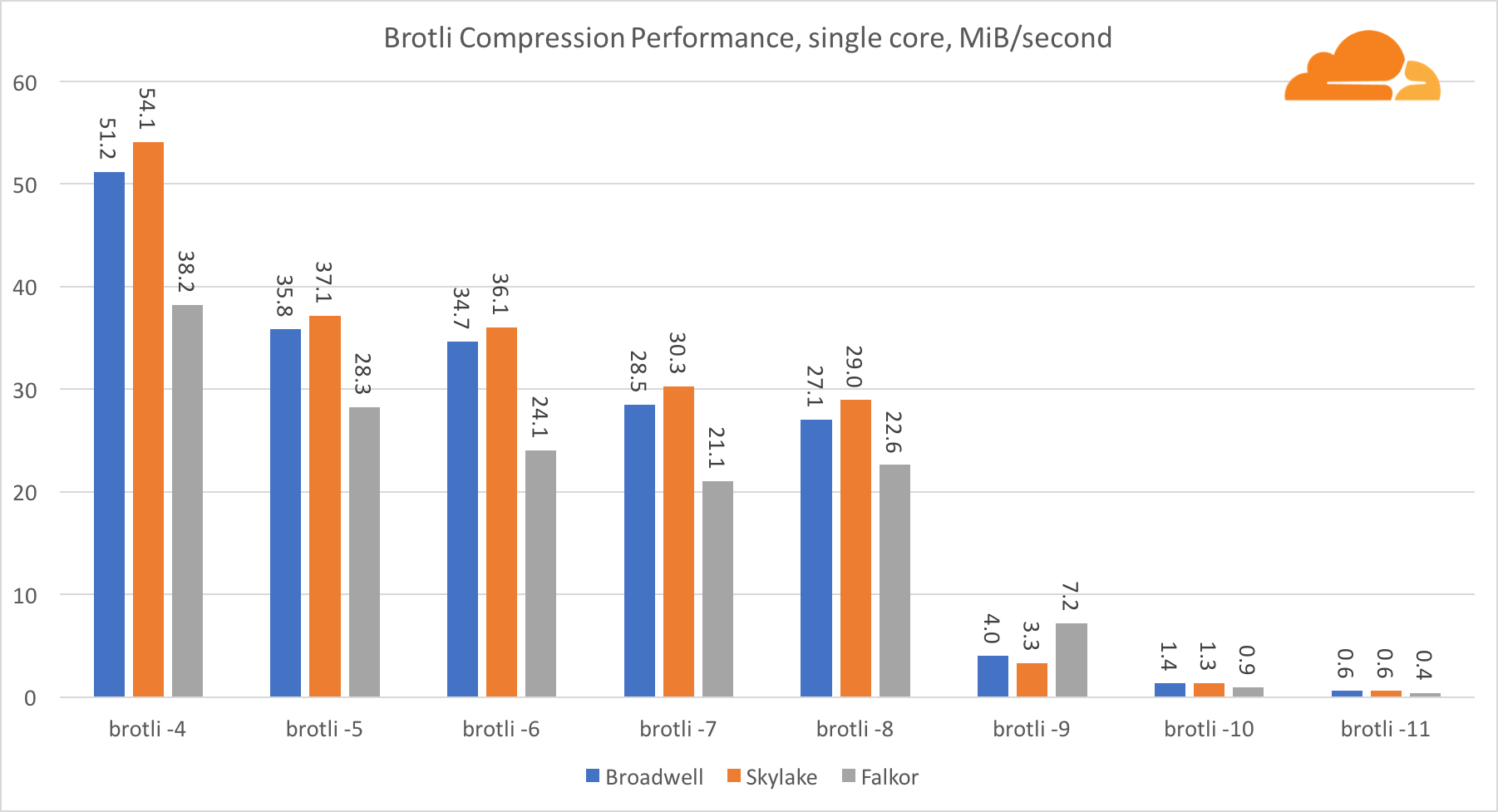
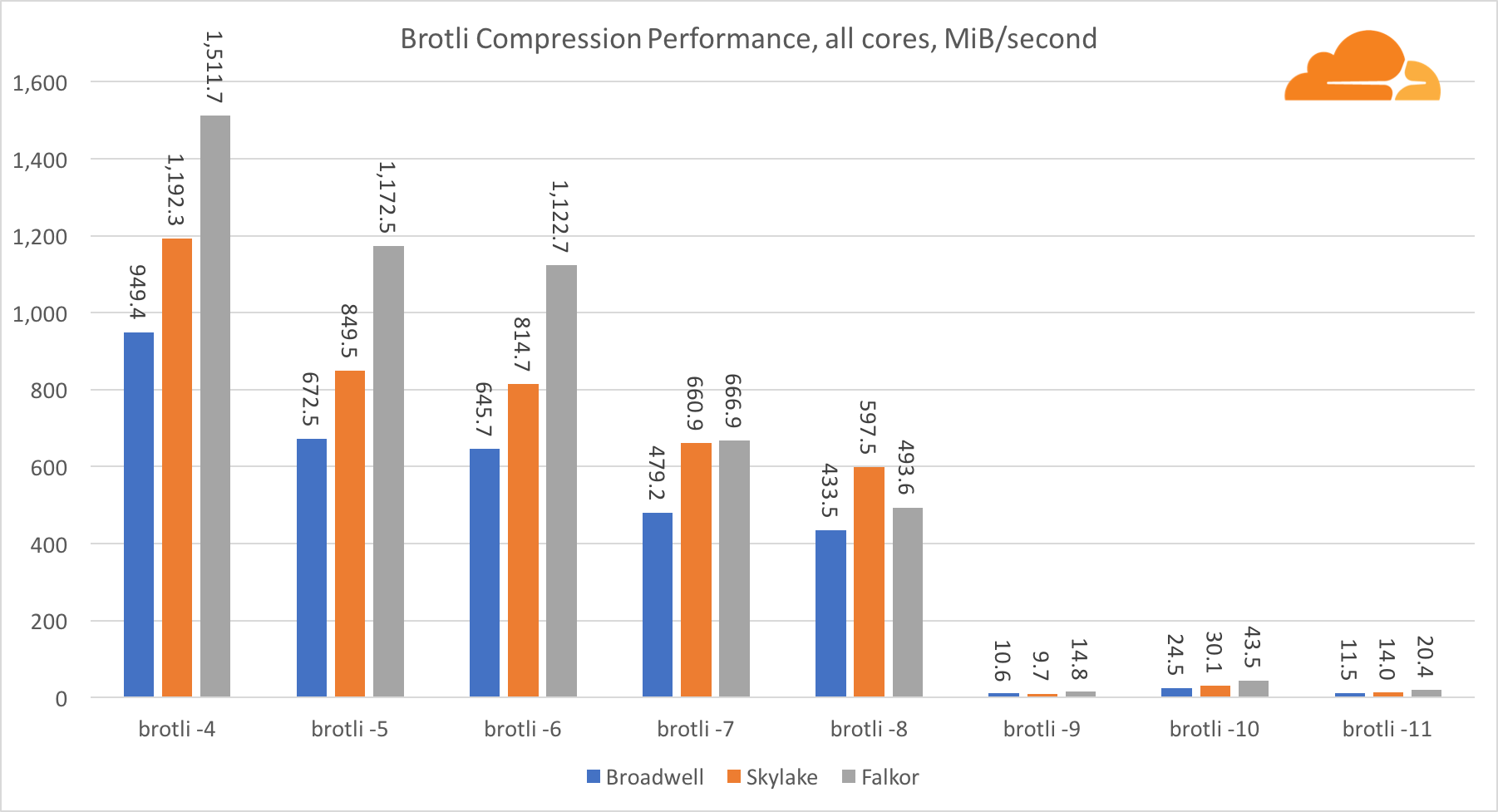
En conclusion, Falkor a gagné, étant donné que la compression dynamique ne dépassera pas le niveau 7.
Golang
Golang est une autre langue très importante pour Cloudflare. C'est également l'une des premières langues à prendre en charge ARMv8, vous pouvez donc vous attendre à de bonnes performances. J'ai utilisé des tests intégrés, mais je les ai modifiés pour plusieurs goroutines.
Allez cryptoJe voudrais commencer par des tests de performances de chiffrement. Grâce à OpenSSL, nous avons d'excellentes données sources, et il sera très intéressant de voir à quel point la bibliothèque Go est bonne.
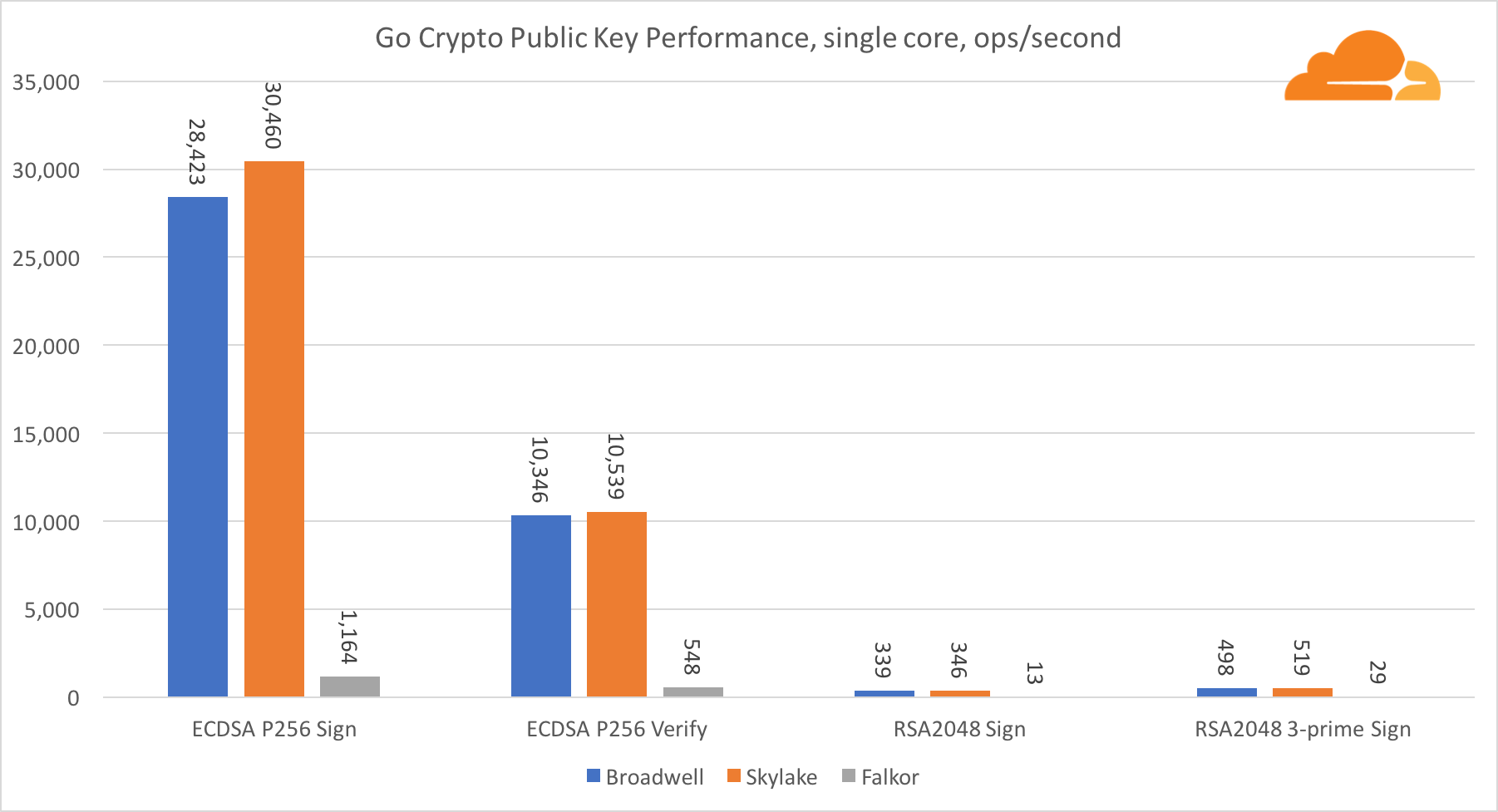
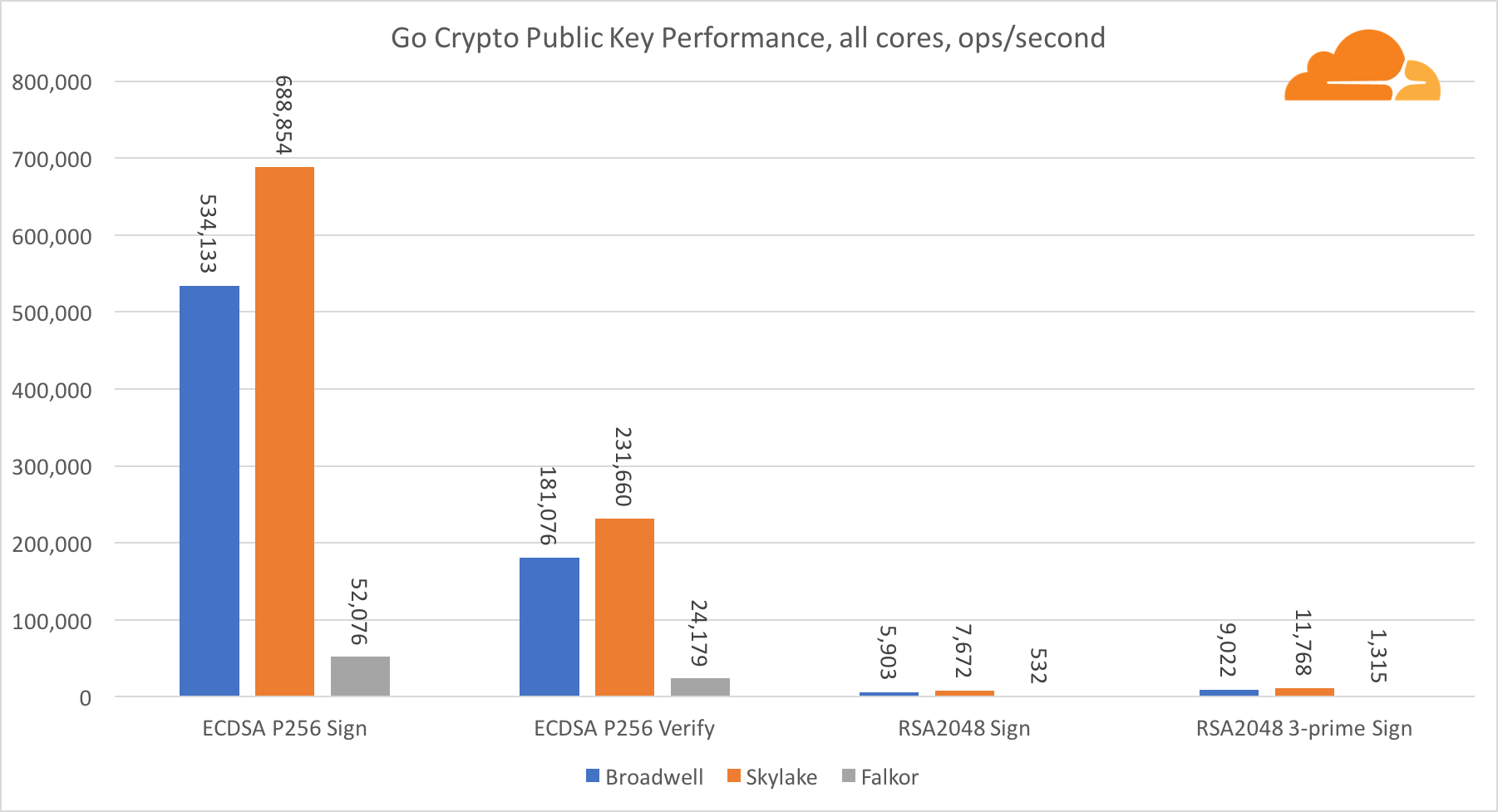
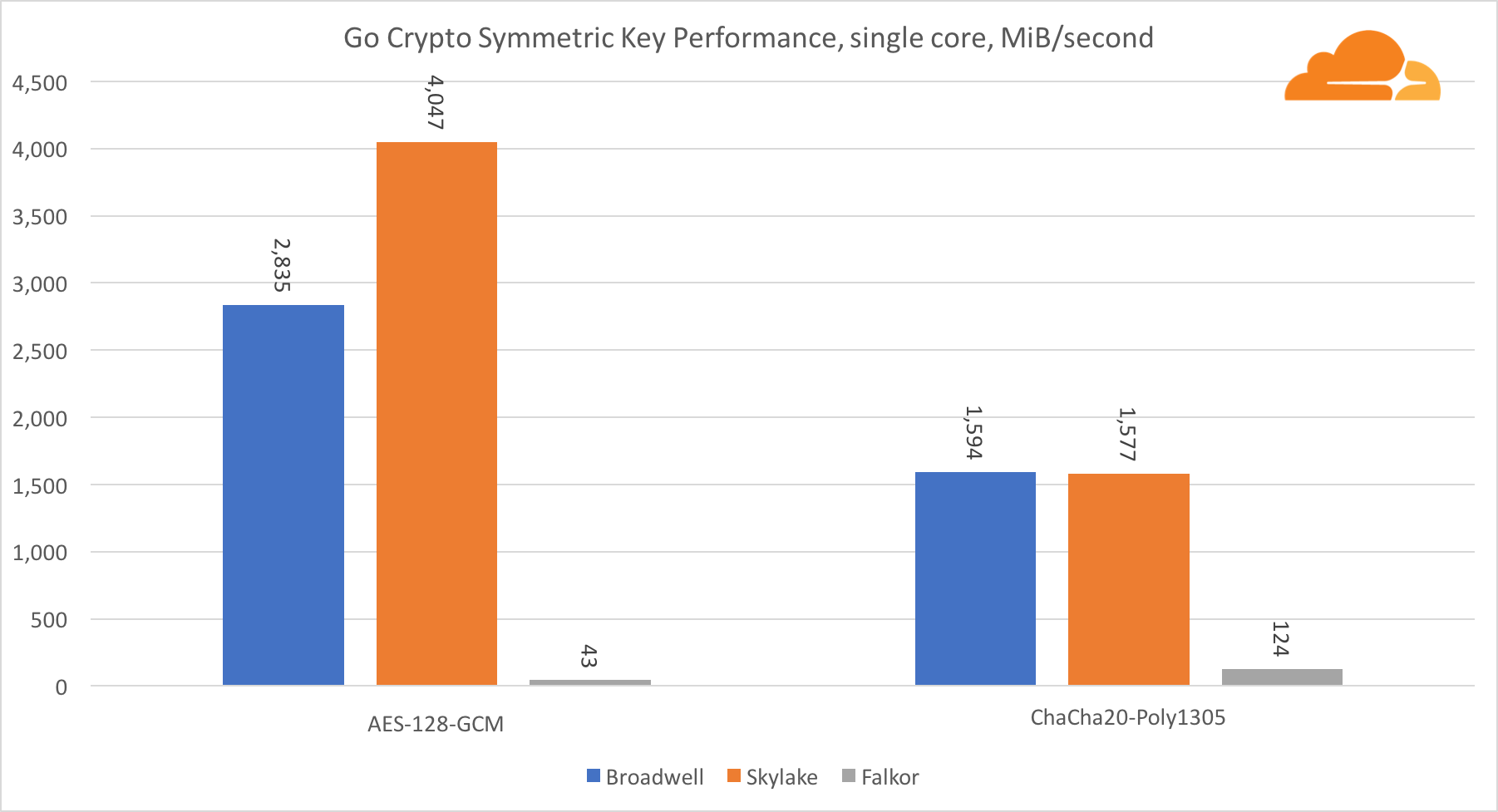
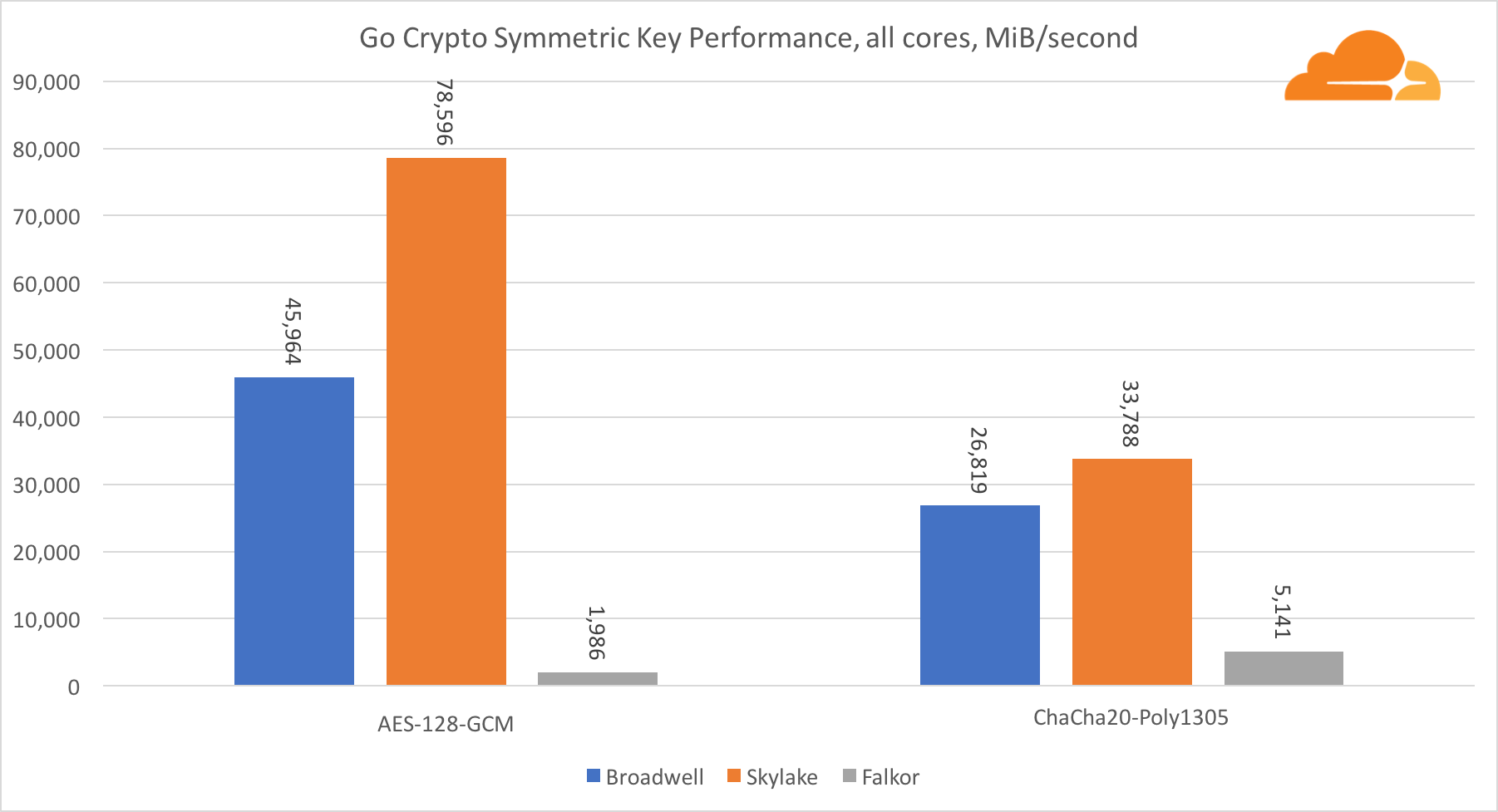
En ce qui concerne Go crypto, l'ARM et Intel ne sont même pas dans la même catégorie de poids. Go a un code assembleur hautement optimisé pour ECDSA, AES-GCM et Chacha20-Poly1305 sur Intel. Il existe également des fonctions mathématiques optimisées utilisées dans les calculs RSA. ARMv8 n'a pas tout cela, ce qui le place dans une position très désavantageuse.
Néanmoins, l'écart peut être réduit avec relativement peu d'efforts, et nous savons qu'avec une optimisation appropriée, les performances peuvent être comparables à OpenSSL. Même des changements très mineurs, tels que la mise en œuvre de la fonction addMulVVW dans l'assemblage, ont conduit à décupler les performances RSA, plaçant Falkor (avec un score de 8009) au-dessus de Broadwell et Skylake.
Il convient de noter une autre chose intéressante - sur Skylake, le code Go Chacha20-Poly1305 qui utilise AVX2 fonctionne de la même manière que le code OpenSSL AVX512. Encore une fois, cela est dû au fait que l'AVX2 fonctionne à des fréquences d'horloge plus élevées.
Allez gzipVoyons maintenant les performances Go de gzip. Il existe également un excellent guide pour un code assez bien optimisé, et nous pouvons le comparer avec Go. Dans le cas de la bibliothèque gzip, il n'y a pas d'optimisations spécifiques pour Intel.
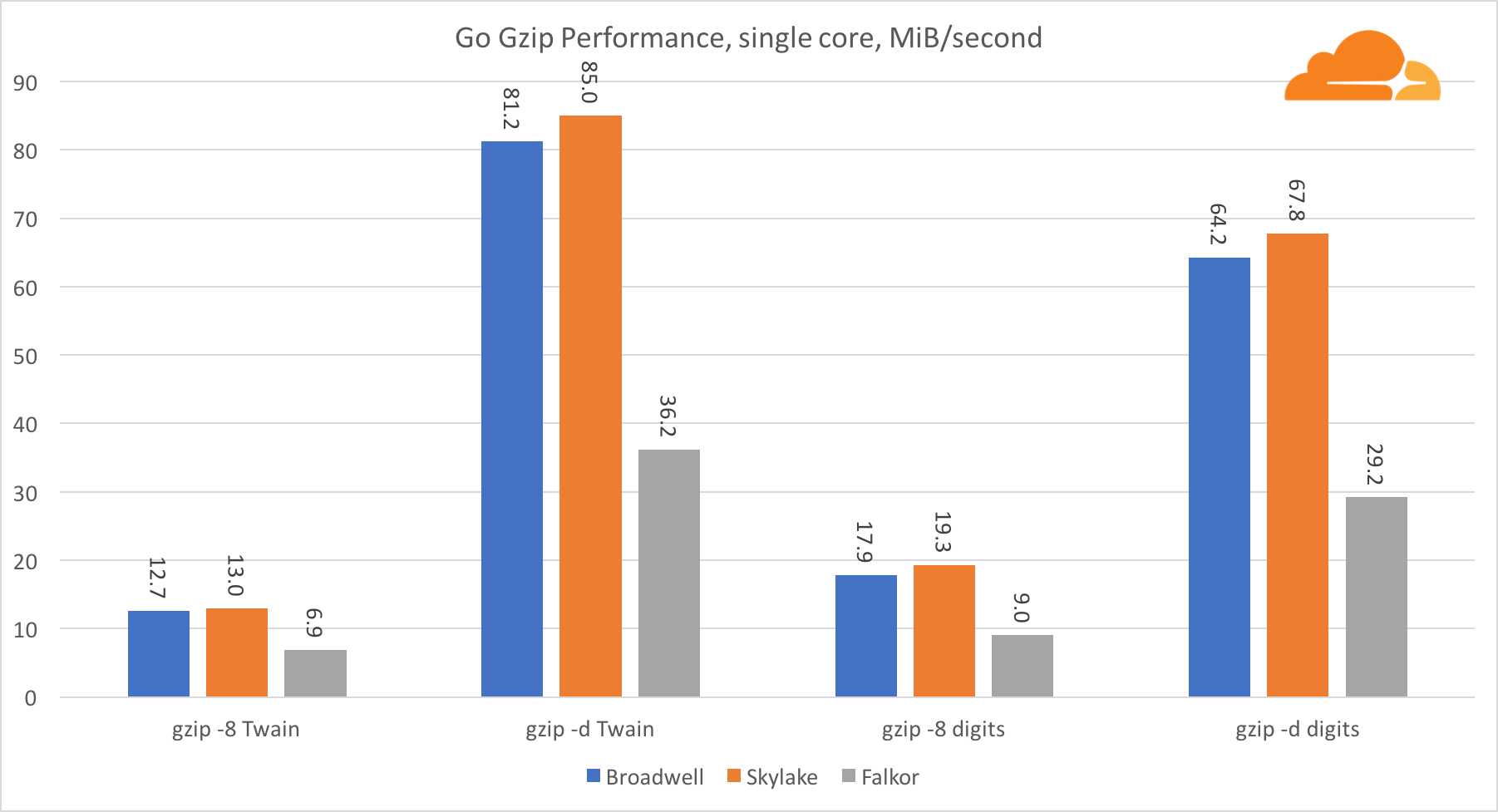

Les performances de Gzip sont plutôt bonnes. Les performances sur un seul cœur Falkor accusent un retard significatif par rapport aux deux processeurs Intel, mais au niveau du système, il a réussi à battre Broadwell et situé sous Skylake. Puisque nous savons déjà que Falkor est supérieur aux deux autres processeurs lors de l'exécution de C. Cela ne peut signifier qu'une chose - le backend Go pour ARMv8 n'est toujours pas finalisé par rapport à gcc.
Go regexpRegexp est largement utilisé dans une variété de tâches, car ses performances sont également extrêmement importantes. J'ai exécuté des tests intégrés sur des flux de 32 ko.
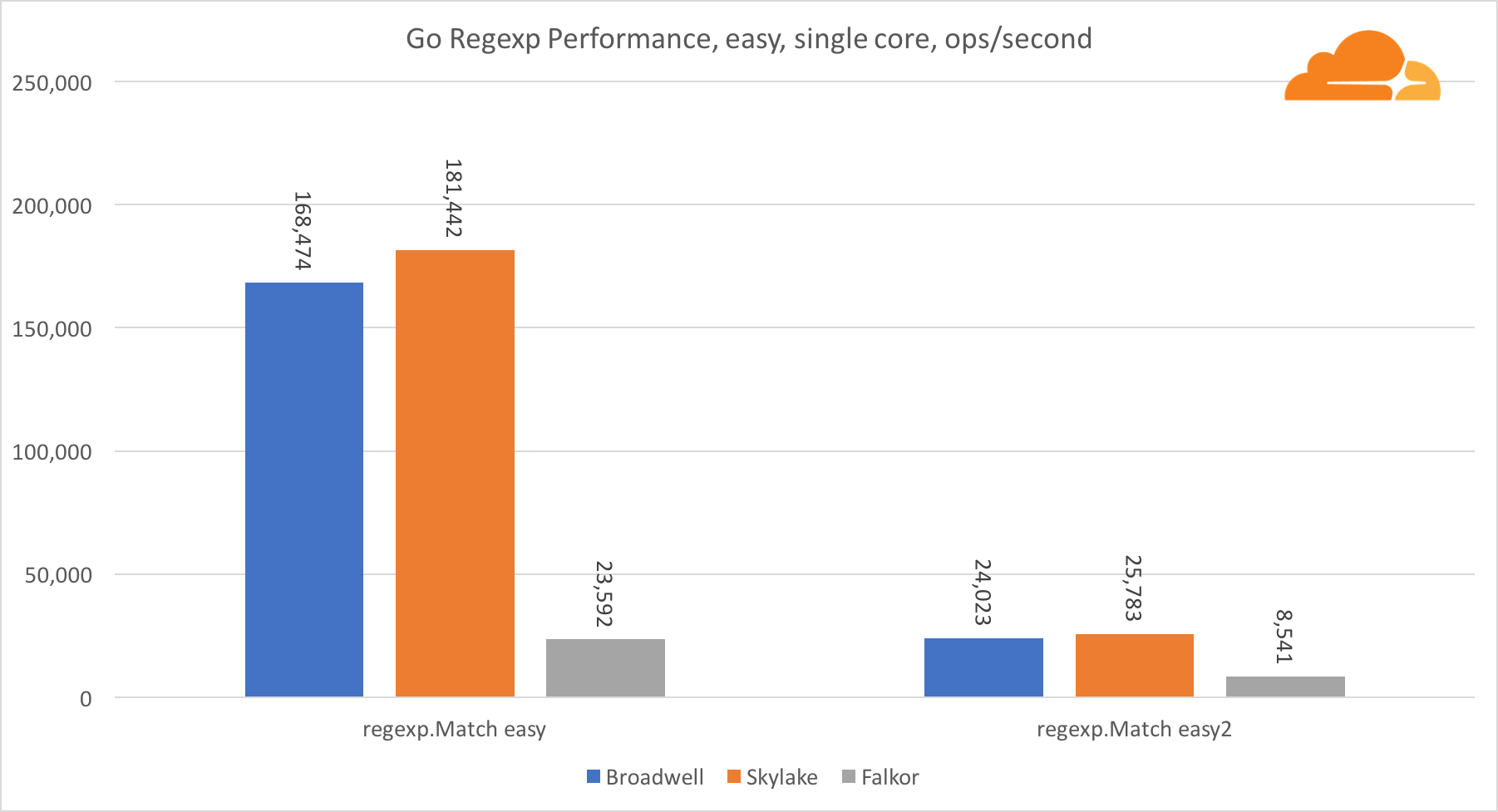
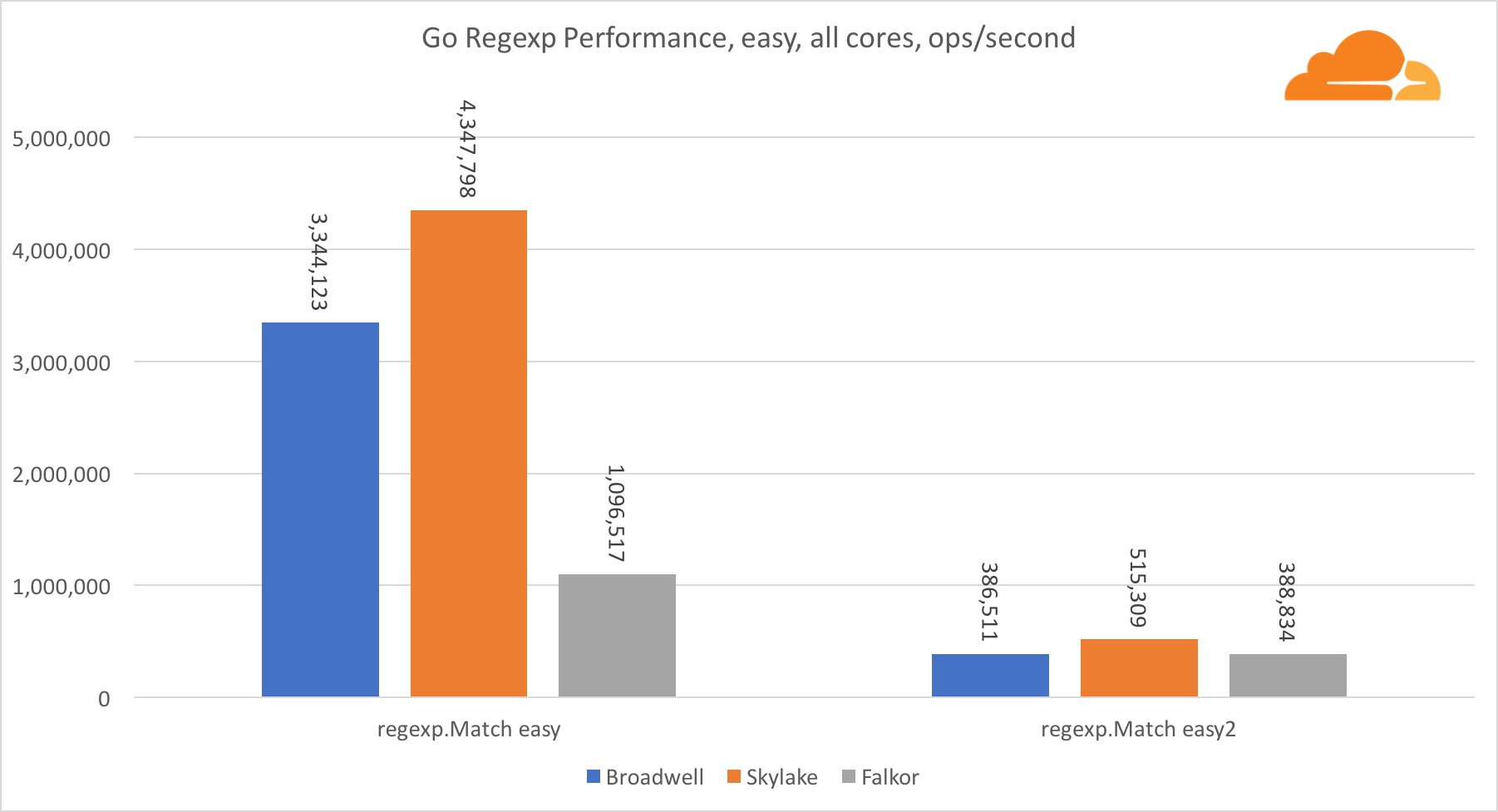
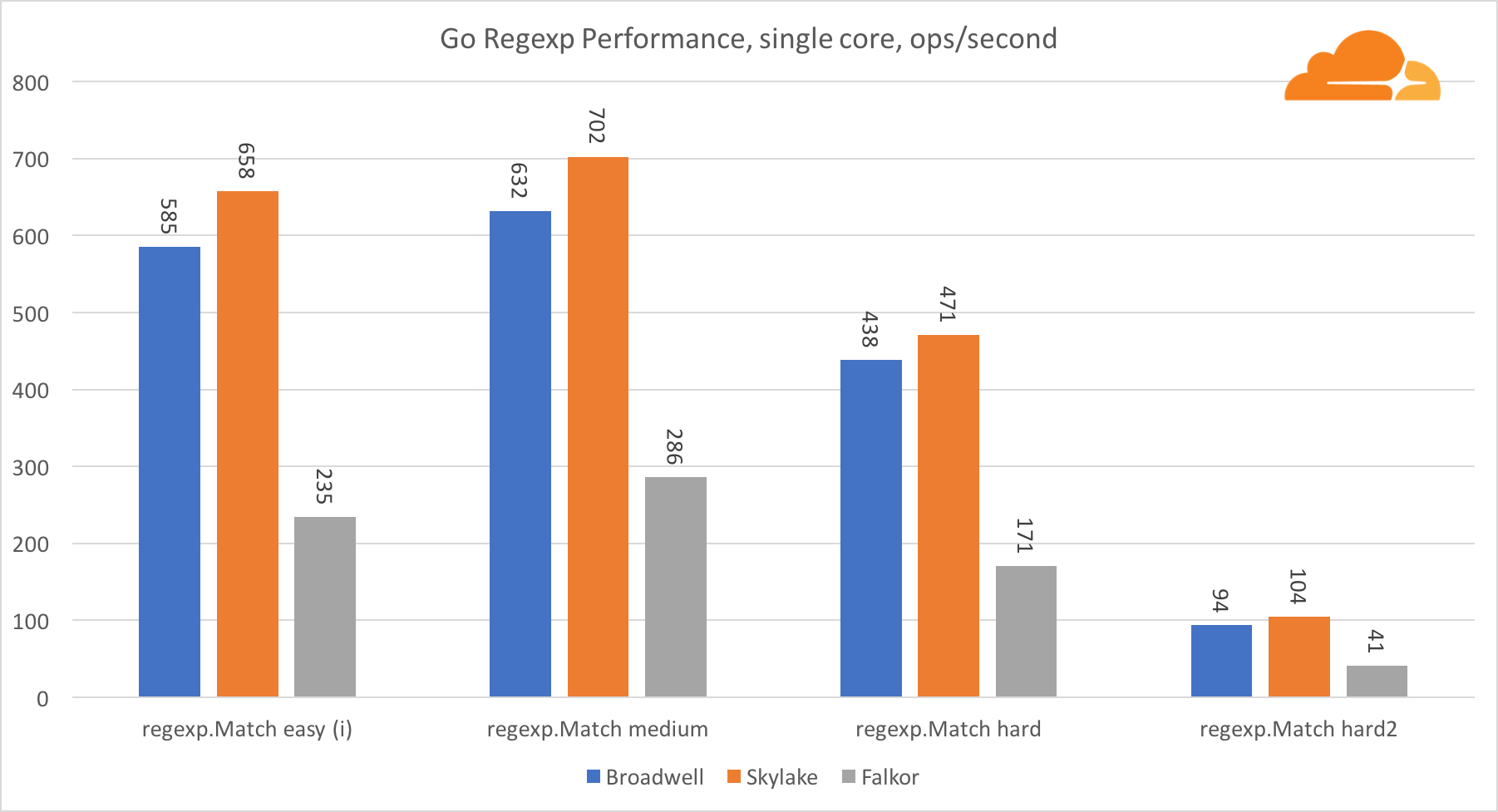
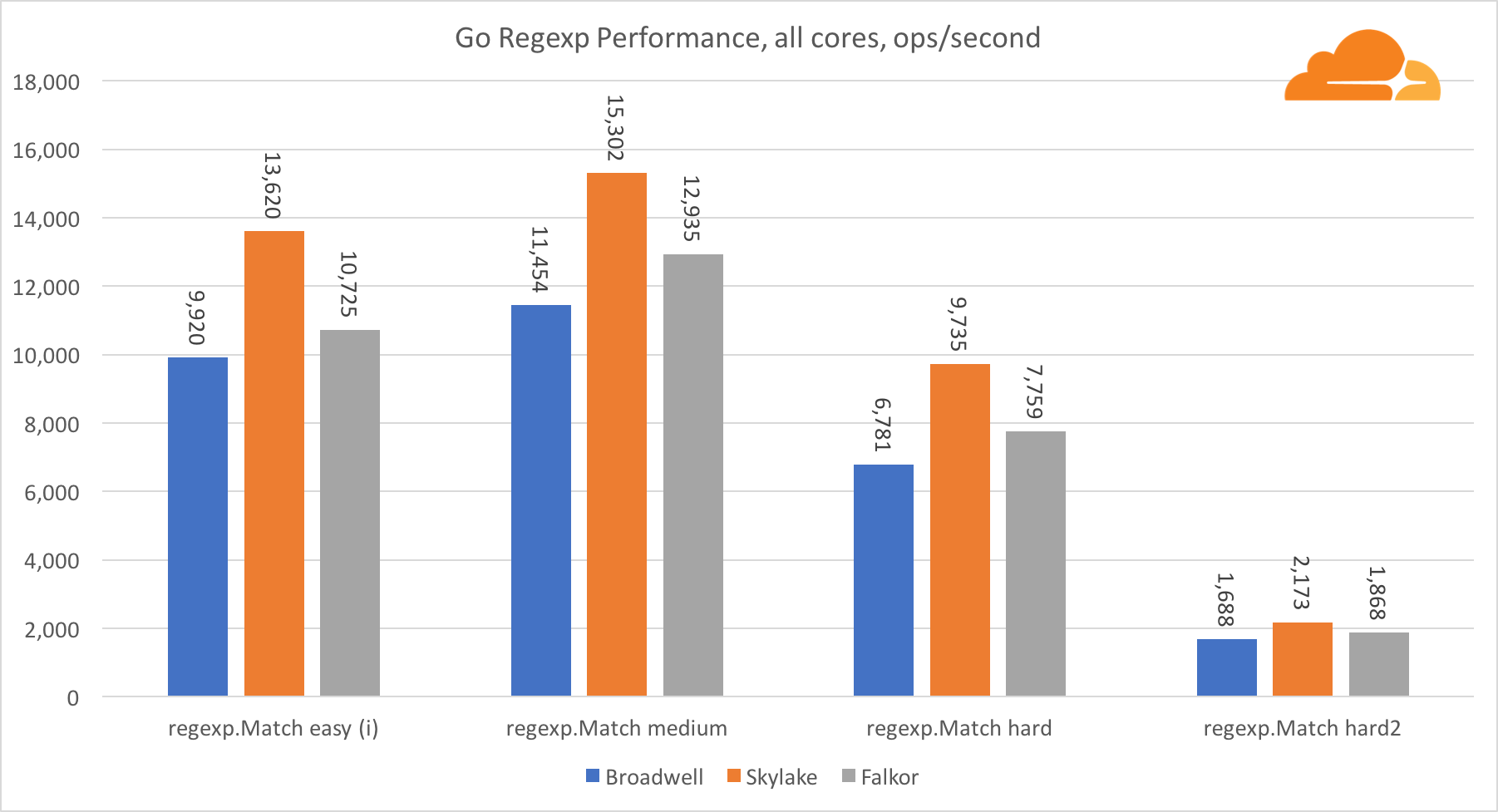
Sur Falkor, les performances de Go regexp ne sont pas très bonnes. Il prend la deuxième place sur les tests moyens et complexes, grâce à un plus grand nombre de cœurs, mais Skylake est cependant beaucoup plus rapide.
Un examen plus approfondi du processus montre que beaucoup de temps est consacré à la fonction bytes.IndexByte. Cette fonction a une implémentation d'assembleur pour amd64 (runtime.indexbytebody), mais l'implémentation principale est pour Go. Lors des tests légers, regexp a passé encore plus de temps sur cette fonctionnalité, ce qui explique l'écart plus large.
Allez cordesUne autre bibliothèque importante pour le serveur Web est Go strings. J'ai testé uniquement la classe Replacer principale.
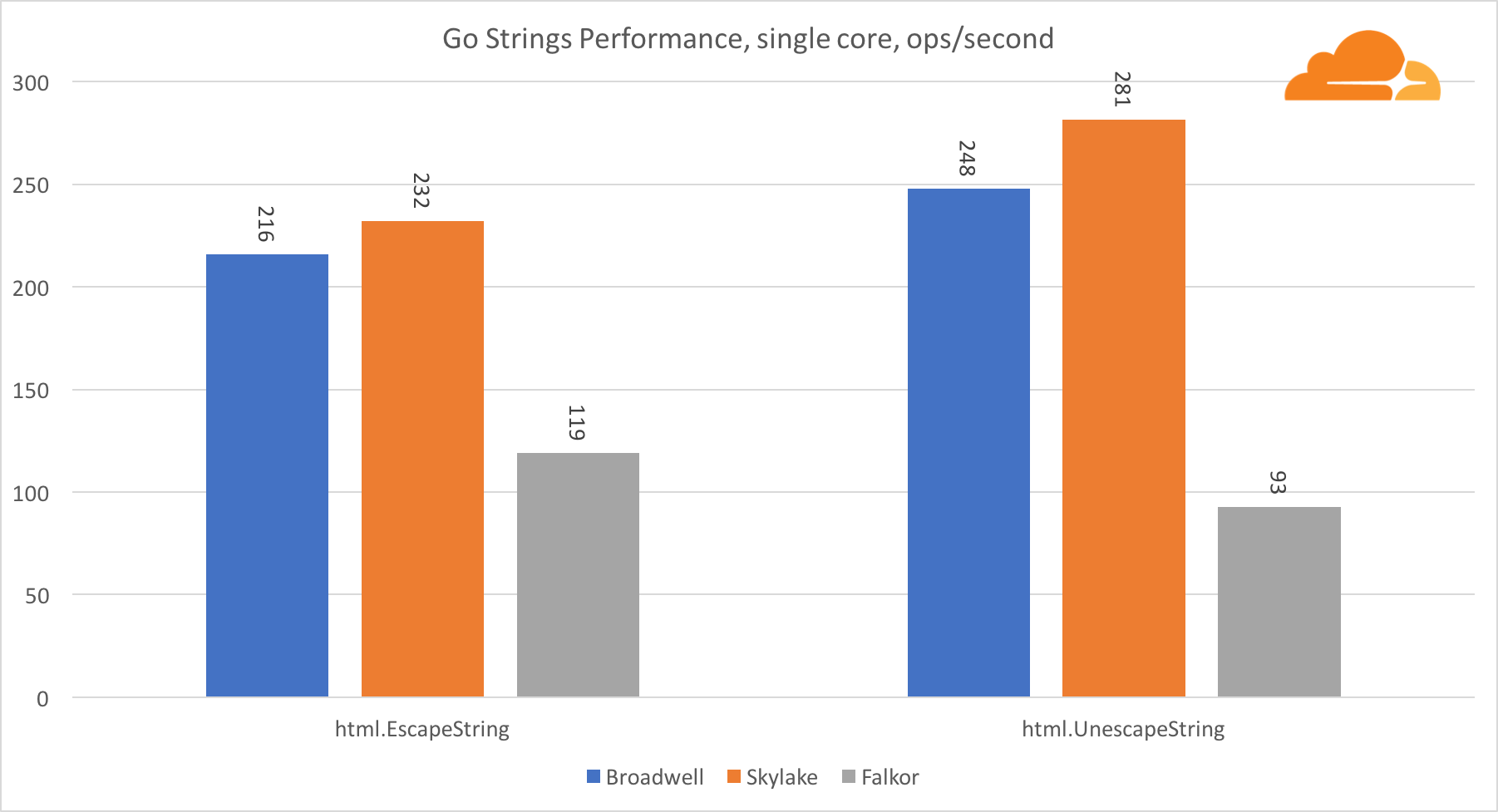
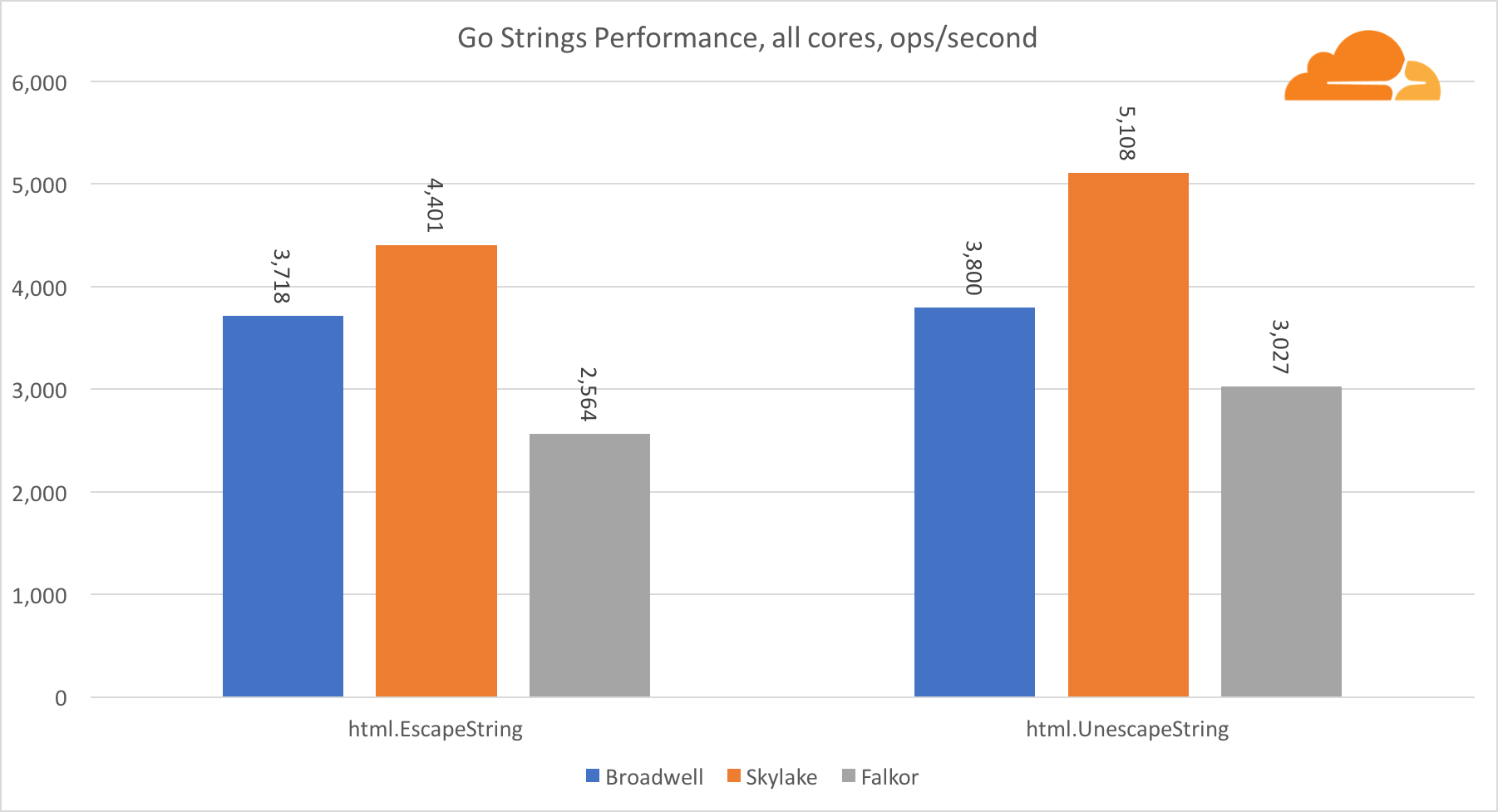
Dans ce test, Falkor est à nouveau à la traîne, même derrière Broadwell. Un examen plus approfondi révèle un long séjour dans la fonction runtime.memmove. Tu sais quoi? Elle a un code assembleur parfaitement optimisé pour amd64 qui utilise AVX2, mais seulement l'assembleur le plus simple qui copie 8 octets à la fois. En modifiant 3 lignes dans ce code et en utilisant les instructions LDP / STP (chargement par paire / stockage par paire), vous pouvez copier 16 octets à la fois, ce qui a augmenté les performances memmove de 30%, ce qui, à son tour, accélère EscapeString et UnescapeString de 20%. Et ce n'est que la pointe de l'iceberg.
Allez conclusionLe support de Go sur aarch64 est assez décevant. Je suis heureux d'annoncer que tout a été compilé et a fonctionné sans problème, mais sur le plan des performances, cela pourrait être mieux. On a l'impression que la majeure partie de l'effort a été dépensée sur le backend du compilateur, et la bibliothèque était presque intacte. Il existe de nombreuses optimisations de bas niveau, par exemple mon correctif addMulVVW, qui a pris 20 minutes. Qualcomm et d'autres fournisseurs d'ARMv8 ont l'intention de dépenser des ressources techniques importantes pour rectifier la situation, mais n'importe qui peut réellement contribuer à Go. Par conséquent, si vous voulez laisser votre empreinte sur l'histoire, le moment est venu.
Luajit
Lua est la colle qui maintient Cloudflare ensemble.
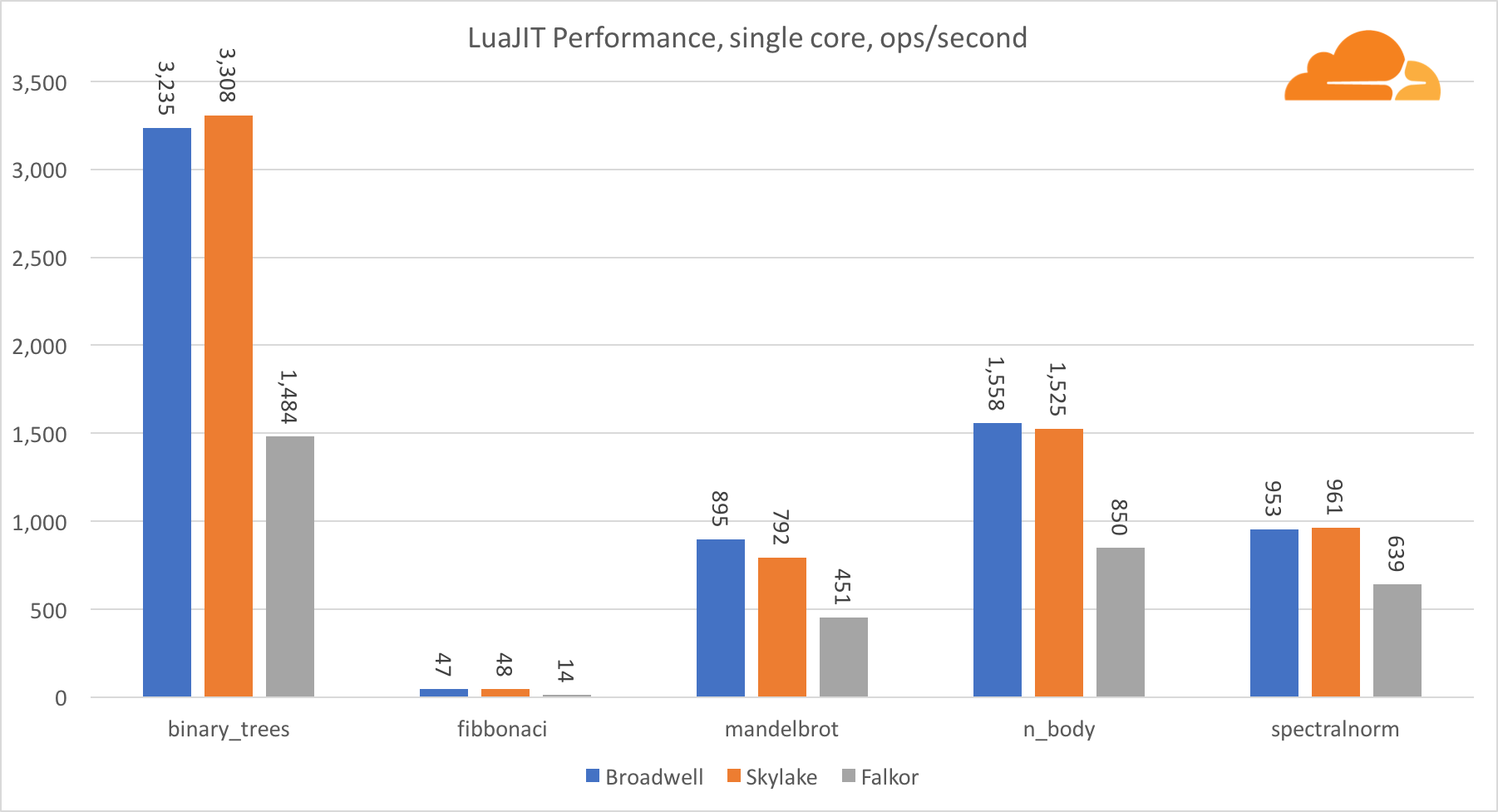
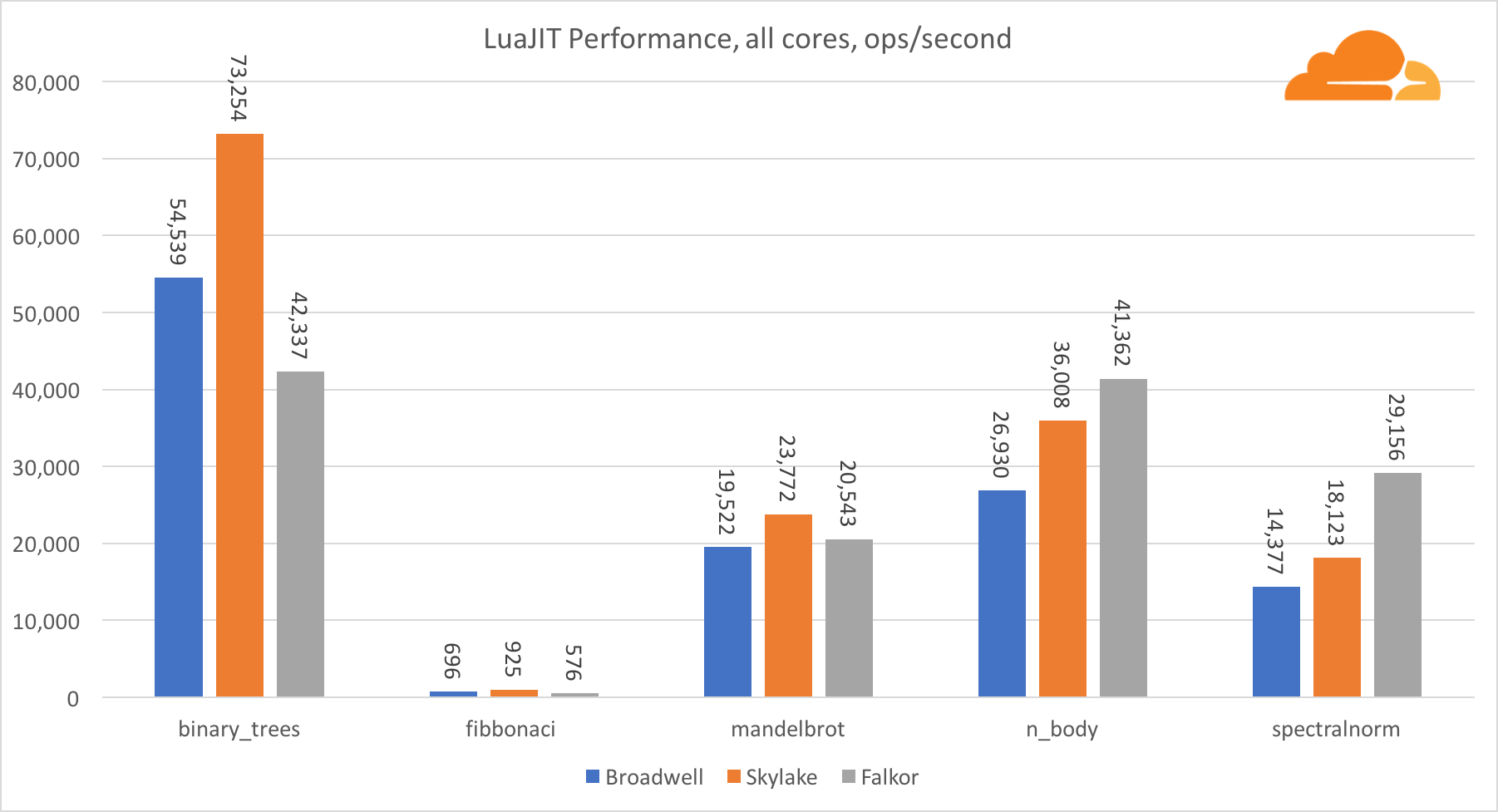
À l'exception du test binary_trees, les performances de LuaJIT sur ARM sont très compétitives. Il remporte deux tests et le troisième se met nez à nez avec ses concurrents.
Il convient de noter que le test binary_trees est extrêmement important, car il implique de nombreux cycles d'allocation de mémoire et de récupération de place. Cela nécessite une réflexion plus approfondie à l'avenir.
Nginx
En tant que charge de travail NGINX, j'ai décidé d'en créer un qui ressemblerait au serveur réel.
J'ai configuré un serveur qui sert le fichier HTML utilisé dans le test gzip sur https en utilisant la suite de chiffrement ECDHE-ECDSA-AES128-GCM-SHA256.
Il utilise également LuaJIT pour rediriger la demande entrante, supprimer tous les sauts de ligne et les espaces supplémentaires du fichier HTML lors de l'ajout d'un horodatage. Le HTML est ensuite compressé à l'aide de brotli 5.
Chaque serveur a été configuré pour fonctionner avec autant d'utilisateurs que de processeurs virtuels. 40 pour Broadwell, 48 pour Skylake et 46 pour Falkor.
En tant que client pour ce test, j'ai utilisé le programme hey fonctionnant sur 3 serveurs Broadwell.
En même temps que le test, nous avons pris des relevés de puissance des blocs BMC correspondants de chaque serveur.
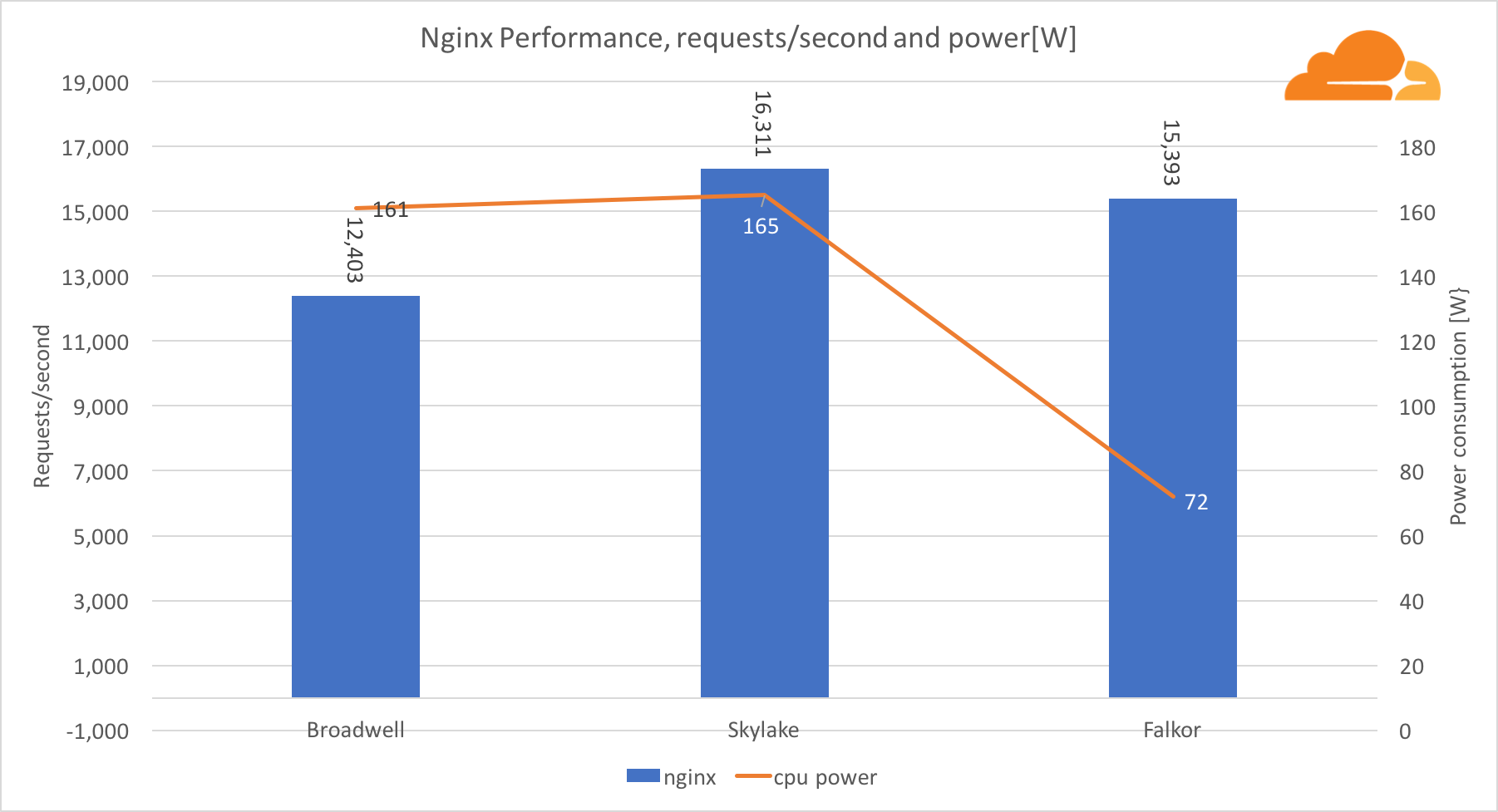
Avec la charge de travail, NGINX Falkor a traité presque le même nombre de demandes que le serveur Skylake, et les deux étaient nettement en avance sur Broadwell. Les relevés de puissance tirés du BMC montrent que cela s'est produit lorsque l'énergie était consommée moitié moins que les autres processeurs. Cela signifie que Falkor a réussi à obtenir 214 demandes / W, Skylake - 99 demandes / W et Broadwell - 77 demandes / W.
J'ai été surpris que Skylake et Broadwell consomment environ la même quantité d'énergie, étant donné qu'ils sont produits de la même manière, et Skylake a plus de cœurs.
La faible consommation d'énergie de Falkor n'est pas surprenante, car les processeurs Qualcomm sont connus pour leur haute efficacité énergétique, ce qui leur a permis d'occuper une position dominante sur le marché des processeurs pour appareils mobiles.
Conclusion
L'échantillon Falkor que nous avons obtenu m'a vraiment impressionné. Il s'agit d'une énorme amélioration par rapport aux tentatives précédentes de serveurs basés sur ARM. Bien sûr, en comparant le cœur avec le cœur, Intel Skylake est bien meilleur, mais si nous regardons au niveau du système, les performances deviennent très attrayantes.
La version de production du Centriq SoC contiendra 48 cœurs Falkor fonctionnant à des fréquences allant jusqu'à 2,6 GHz, ce qui donne une augmentation potentielle des performances de 8%.
Évidemment, le Skylake que nous testons n'est pas un produit phare comme Platinum avec ses 28 cœurs, mais ces 28 cœurs coûtent cher et consomment 200 W, tandis que nous essayons d'optimiser nos coûts et d'augmenter les performances de 1 watt.
Pour le moment, je suis très préoccupé par les mauvaises performances du langage Go, mais cela changera dès que les serveurs basés sur ARM occuperont leur niche sur le marché.
Les performances C et LuaJIT sont très compétitives, et dans de nombreux cas supérieures à Skylake. Dans presque tous les tests, Falkor s'est avéré être un digne remplaçant de Broadwell.
Le plus gros avantage de Falkor pour le moment est sa faible consommation d'énergie. Bien que le TDP soit de 120W, lors de mes tests ce chiffre n'a jamais dépassé 89W (pour les tests go). A titre de comparaison, Skylake et Broadwell ont dépassé 160W, tandis que leur TDP est de 170W.
Comme une publicité. Ce ne sont pas que des serveurs virtuels! Ce sont des VPS (KVM) avec des disques dédiés, ce qui ne peut pas être pire que des serveurs dédiés, et dans la plupart des cas - mieux!
Nous avons créé VPS (KVM) avec des disques dédiés aux Pays-Bas et aux États-Unis (configurations VPS (KVM) - E5-2650v4 (6 cœurs) / 10 Go DDR4 / 240 Go SSD ou 4 To HDD / 1 Gbit / s 10 To disponibles à un prix unique - à partir de 29 $ / mois , des options avec RAID1 et RAID10 sont disponibles) , ne manquez pas la chance de passer une commande pour un nouveau type de serveur virtuel, où toutes les ressources vous appartiennent, comme sur un serveur dédié, et le prix est beaucoup plus bas, avec un matériel beaucoup plus productif!
Comment construire l'infrastructure du bâtiment. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou? Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis!