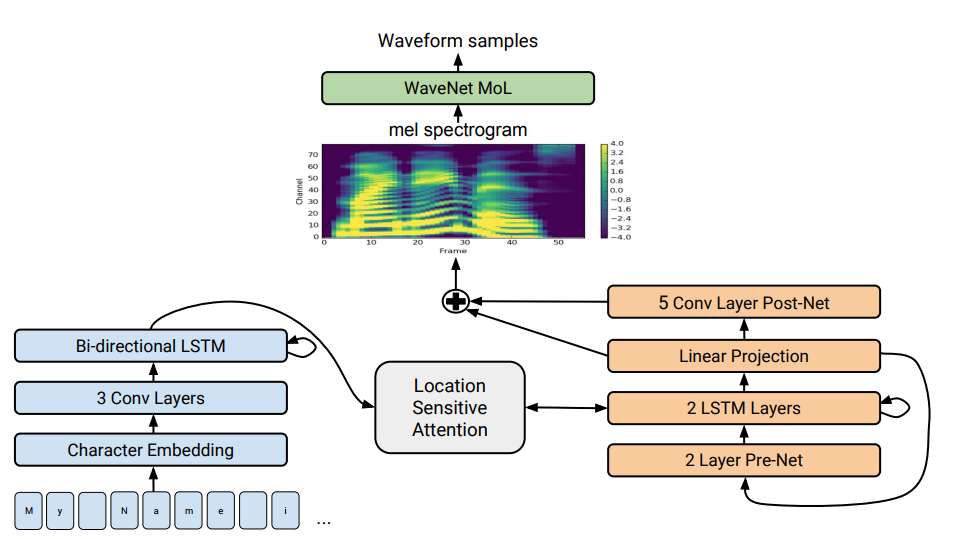
 Architecture Tacotron 2. Au bas de l'illustration, des modèles offre à offre sont traduits qui traduisent une séquence de lettres en une séquence d'attributs dans un espace à 80 dimensions. Pour une description technique, voir un article scientifique.
Architecture Tacotron 2. Au bas de l'illustration, des modèles offre à offre sont traduits qui traduisent une séquence de lettres en une séquence d'attributs dans un espace à 80 dimensions. Pour une description technique, voir un article scientifique.La synthèse vocale - la reproduction artificielle de la parole humaine à partir d'un texte - est traditionnellement considérée comme l'une des composantes de l'intelligence artificielle. Auparavant, de tels systèmes ne pouvaient être vus que dans les films de science-fiction, mais maintenant ils fonctionnent littéralement dans tous les smartphones: ce sont Siri, Alice, etc. Mais ils ne prononcent pas de phrases très réalistes: voix inanimée, les mots sont séparés les uns des autres.
Google a
développé un synthétiseur vocal avancé de nouvelle génération. Il s'appelle Tacotron 2 et est basé sur un réseau neuronal. Pour démontrer ses capacités, l'entreprise a publié des
exemples de synthèse . Au bas de la page avec des exemples, vous pouvez faire un test et essayer de déterminer où le texte est délivré par le synthétiseur vocal et où se trouve la personne. Déterminer la différence est presque impossible.
Malgré des décennies de recherche, la synthèse vocale reste une tâche urgente pour la communauté scientifique. Au cours des dernières années, différentes techniques ont prévalu dans ce domaine: récemment, la synthèse concaténative avec le choix des fragments a été considérée comme la plus avancée - le processus de combinaison de petits fragments sonores préenregistrés, ainsi que la synthèse vocale paramétrique statistique, dans laquelle le vocodeur a synthétisé des voies de prononciation lisses. La deuxième méthode a résolu de nombreux problèmes de synthèse concaténative avec des artefacts aux frontières entre les fragments. Cependant, dans les deux cas, le son synthétisé semblait brouillé et contre nature par rapport à la parole humaine.
Puis est venu le moteur sonore WaveNet (un modèle génératif de formes d'onde dans le domaine temporel), qui a pour la première fois pu montrer une qualité sonore comparable à celle de l'homme. Il est maintenant utilisé dans le système de synthèse
vocale Deep Voice 3 .
Plus tôt en 2017, Google a présenté l'
architecture offre à offre
Tacotron . Il génère des spectrogrammes d'amplitudes à partir d'une séquence de caractères. Tacotron simplifie le convoyeur de moteur audio traditionnel. Ici, les caractéristiques linguistiques et acoustiques sont générées par un seul réseau neuronal formé uniquement sur les données. L'expression "phrase à phrase" signifie que le réseau neuronal établit une correspondance entre une séquence de lettres et une séquence d'attributs pour coder le son. Les signes sont générés dans un spectrogramme audio à 80 dimensions avec des trames de 12,5 millisecondes.
Le réseau neuronal apprend non seulement la prononciation des mots, mais également des caractéristiques vocales spécifiques, telles que le volume, la vitesse et l'intonation.
Ensuite, les ondes sonores sont directement générées en utilisant l'algorithme Griffin-Lim (pour l'estimation de phase) et la transformée de Fourier à court terme inverse. Comme l'ont noté les auteurs, il s'agissait d'une solution temporaire pour démontrer les capacités du réseau neuronal. En fait, le moteur WaveNet et similaires créent un meilleur son que l'algorithme Griffin-Lim, et sans artefacts.
Dans le système Tacotron 2 modifié, les spécialistes de Google connectaient toujours le vocodeur WaveNet au réseau neuronal. Ainsi, le réseau neuronal crée des spectrogrammes, puis une version modifiée de WaveNet génère un son à 24 kHz.
Le réseau de neurones apprend de manière indépendante (de bout en bout) au son d'une voix humaine, qui est accompagnée de texte. Un réseau neuronal bien formé lit ensuite les textes de telle manière qu'il est presque impossible de les distinguer du son de la parole humaine, comme on peut le voir sur
des exemples réels .
Les chercheurs notent que le système Deep Voice 3 utilise une approche similaire, mais la qualité de sa synthèse ne peut toujours pas être comparée à la parole humaine. Mais le Tacotron 2 peut, voir les résultats du test du score d'opinion moyen (MOS) dans le tableau.
Il existe un autre synthétiseur vocal qui fonctionne également sur un réseau de neurones - c'est
Char2Wav , mais il a une architecture complètement différente.
Les scientifiques disent qu'en général, le réseau neuronal fonctionne bien, mais a encore du mal à prononcer certains mots complexes (tels que
décorum ou
merlot ). Et parfois, il produit au hasard des bruits étranges - les raisons de cela sont maintenant clarifiées. De plus, le système ne peut pas fonctionner en temps réel et les auteurs n'ont pas encore pu prendre le contrôle du moteur, c'est-à-dire lui donner l'intonation souhaitée, par exemple une voix joyeuse ou triste. Chacun de ces problèmes est intéressant en soi, écrivent-ils.
L'article scientifique a été
publié le 16 décembre 2017 sur le site de préimpression arXiv.org (arXiv: 1712.05884v1).