... et apprenez à travailler avec les outils de développement Ethereum à l'aide d'un exemple concret.
Partie zéro: l'objet est apparu
Je viens de terminer mes conférences sur le cours complet de développement d'applications décentralisées basées sur Ethereum dans Solidity en chinois. Je l'ai donné dans mon temps libre afin d'augmenter le niveau de connaissances sur la blockchain et les contrats intelligents parmi la communauté chinoise des développeurs. Pendant mon travail, je me suis lié d'amitié avec quelques étudiants.
Et juste à la fin du cours, nous nous sommes soudain retrouvés entourés de ces créatures:
 Image de cryptokitties.co
Image de cryptokitties.coComme la plupart des gens qui ont rencontré ce phénomène, nous n'avons pas pu, eux non plus, résister à ces cryptocréations mignonnes et nous sommes rapidement devenus accro au jeu. Nous aimions sortir de nouveaux chats et nous avons même remplacé
la méthode du caneton par la méthode du chat crypto . Je crois que la dépendance aux jeux est mauvaise, mais pas dans ce cas, car la passion pour l'élevage de chatons nous a rapidement conduit à la question:
Comment certains chats crypto obtiennent-ils leur ensemble de gènes?
Nous avons décidé de consacrer samedi soir à y trouver la réponse, et nous pensons avoir réussi à faire quelques progrès dans le développement de logiciels qui nous permettent de déterminer la mutation génétique des chatons cryptés nouveau-nés avant leur naissance. En d'autres termes, ce programme peut vous aider à vérifier et à déterminer le moment approprié pour la fécondation de la mère chat, et ainsi obtenir la plus intéressante des mutations possibles.
Nous publions ce matériel dans l'espoir qu'il servira à tout le monde comme article d'introduction pour se familiariser avec les outils de développement Ethereum très utiles, tout comme les crypto-chatons eux-mêmes ont permis à de nombreuses personnes peu familiarisées avec la blockchain de rejoindre les rangs des utilisateurs de crypto-monnaie.
Première partie: la logique de haut niveau de la génération de petits chatons
Pour commencer, nous nous sommes demandé: comment se passe la naissance des crypto chatons?
Pour répondre à cette question, nous avons utilisé l'excellent conducteur Etherscan blockchain, qui nous permet de faire bien plus que simplement «étudier les paramètres et le contenu des blocs». Nous avons donc découvert le code source du contrat CryptoKittiesCore:
 https://etherscan.io/address/0x06012c8cf97bead5deae237070f9587f8e7a266d#code
https://etherscan.io/address/0x06012c8cf97bead5deae237070f9587f8e7a266d#codeVeuillez noter que le contrat étendu est en fait légèrement différent de celui utilisé dans le programme de primes. Selon ce code, un bébé chaton est formé en deux étapes: 1) la mère chat est fécondée par le chat; 2) un peu plus tard, lorsque la période de maturation du fœtus prend fin, la fonction giveBirth est appelée. Cette fonction est généralement appelée par un certain démon de processus, mais, comme vous le verrez plus tard, pour obtenir des mutations intéressantes, vous devrez sélectionner correctement le bloc dans lequel votre chaton est né.
function giveBirth(uint256 _matronId) external whenNotPaused returns(uint256) { Kitty storage matron = kitties[_matronId];
Dans le code ci-dessus, vous pouvez clairement voir que les gènes d'un chaton nouveau-né sont déterminés dès la naissance en appelant la fonction mixGenes à partir du contrat intelligent externe de geneScience. Cette fonction prend trois paramètres: le gène mère, le gène père et le numéro de bloc dans lequel le chat sera prêt à accoucher.
Vous aurez probablement une question logique, pourquoi les gènes ne sont pas déterminés au moment de la conception, comme c'est le cas dans le monde réel? Comme vous le verrez au cours du récit suivant, cela vous permet de vous défendre assez élégamment contre les tentatives de prédire et de déchiffrer les gènes. Cette approche élimine la possibilité d'une prédiction précise à 100% des gènes de chaton avant que le fait de la grossesse chat-mère ne soit enregistré dans la blockchain. Et même si vous pouviez trouver le code exact responsable du mélange des gènes, cela ne vous donnerait aucun avantage.
Quoi qu'il en soit, au début, nous ne le savions pas encore, alors continuons. Maintenant, nous devons trouver l'adresse du contrat geneScience. Pour ce faire, utilisez MyEtherWallet:
 Adresse du contrat GeneScience
Adresse du contrat GeneScienceVoici à quoi ressemble le bytecode du contrat:
0x60606040526004361061006c5763ffffffff7c01000000000000000000000000000000000000000000000000000000006000350416630d9f5aed81146100715780631597ee441461009f57806354c15b82146100ee57806361a769001461011557806377a74a201461017e575b600080fd5b341561007c57600080fd5b61008d6004356024356044356101cd565b604051908152602001604051809........
Par son apparence, on ne peut pas dire qu'en conséquence, quelque chose d'aussi mignon qu'un chaton apparaît sur tout, mais nous sommes très chanceux que ce soit une adresse publique, et nous n'avons pas besoin de la chercher dans le référentiel). En fait, nous pensons qu'il ne devrait pas être rendu aussi facilement accessible. Si les développeurs voulaient vraiment s'assurer que l'adresse du contrat était correcte, ils devraient utiliser la fonction checkScienceAddress, mais cela ne nous dérangera pas.
Deuxième partie: l'effondrement d'une hypothèse simple
Alors, que voulons-nous réaliser à la fin? Il faut comprendre que nous ne nous fixons pas pour objectif de compiler entièrement le bytecode, en le transformant en un code de solidité lisible par l'homme. Nous avons besoin d'une méthode bon marché (sans avoir à payer pour les transactions dans la blockchain de combat) pour déterminer les gènes des chaton, à condition que nous sachions qui sont ses parents. Voilà ce que nous allons faire.
Pour commencer, utilisons l'
outil d'opcode Etherscan pour une analyse rapide. Cela ressemble à ceci:
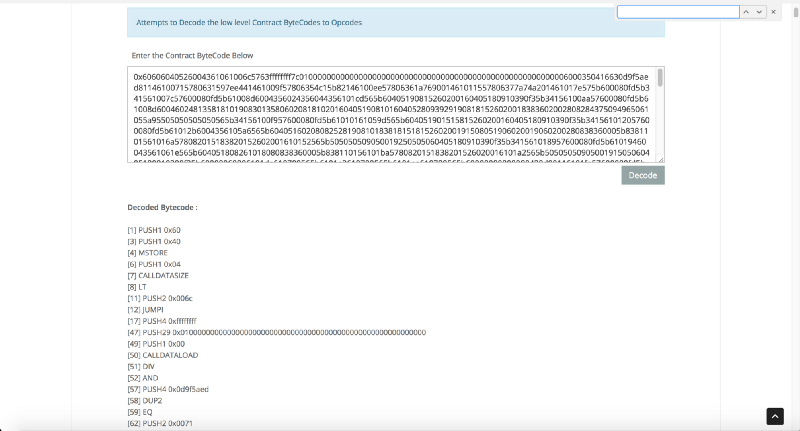 Beaucoup plus clair
Beaucoup plus clairNous suivons la règle d'or du décodage du code assembleur: nous partons d'une hypothèse simple et audacieuse sur le comportement du programme et, au lieu d'essayer de comprendre son travail dans son ensemble, nous nous concentrons sur la confirmation de l'hypothèse formulée. Nous allons parcourir le bytecode pour répondre à quelques questions:
- Utilise-t-il des horodatages? Non, car l'opcode TIMESTAMP est manquant. S'il y a un simple accident, sa source est certainement un autre opcode.
- Un hachage de bloc est-il utilisé? Oui, BLOCKHASH se produit deux fois. Par conséquent, le hasard, le cas échéant, peut provenir de leurs opcodes, mais nous n'en sommes pas encore sûrs.
- Des hachages sont-ils utilisés? Oui, il y a SHA3. Il n'est pas clair, cependant, ce qu'il fait.
- Est-ce que msg.sender est utilisé? Non, car l'opcode CALLER est manquant. Par conséquent, aucun contrôle d'accès n'est appliqué au contrat.
- Un contrat externe est-il utilisé? Non, il n'y a pas d'opcode CALL.
- COINBASE est-il utilisé? Non, et donc nous excluons une autre source possible de hasard.
Ayant reçu la réponse à ces questions, nous avons avancé et entendons tester une hypothèse simple: le résultat de mixGene est déterminé par trois et seulement trois paramètres d'entrée de cette fonction. Si c'est le cas, nous pourrions simplement déployer ce contrat localement, continuer à appeler cette fonction avec les paramètres qui nous intéressent, puis, peut-être, nous pourrions obtenir un kit de gènes de chaton avant même que la mère-chat ne soit fécondée.
Pour vérifier cette hypothèse, nous appelons la fonction mixGene sur le réseau principal avec trois paramètres aléatoires: 1111115, 80, 40 et obtenons un résultat X. Ensuite, déployez ce bytecode en utilisant
truffle et testrpc . Notre paresse a donc conduit à une manière quelque peu non standard d'utiliser la truffe.
contract GeneScienceSkeleton { function mixGenes(uint256 genes1, uint256 genes2, uint256 targetBlock) public returns (uint256) {} }
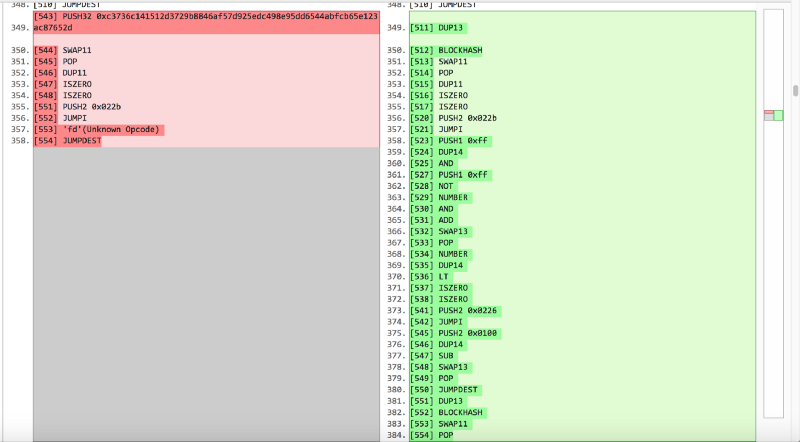
Nous commençons par le squelette du contrat, le mettons dans la structure de dossiers du framework truffle et exécutons la compilation de truffes. Cependant, au lieu de migrer directement ce contrat vide vers testrpc, nous remplaçons le bytecode du contrat dans le dossier de construction par le bytecode étendu réel et le bytecode du contrat geneScience. C'est un moyen atypique mais rapide si vous souhaitez déployer un contrat avec uniquement du bytecode et une interface ouverte limitée pour les tests locaux. Après cela, nous appelons directement Mixgenes avec les paramètres 1111115, 80, 40, et malheureusement nous obtenons une erreur avec la réponse revenir en réponse. Ok, regardez plus profondément. Comme nous le savons, la signature des fonctions mixGene est 0x0d9f5aed, nous prenons donc un stylo et du papier et suivons l'exécution du bytecode, à partir du point d'entrée de cette fonction pour tenir compte des changements dans la pile et le stockage. Après quelques sauts, on se retrouve ici:
[497] DUP1 [498] NUMBER [499] DUP14 [500] SWAP1 [501] GT [504] PUSH2 0x01fe [505] JUMPI [507] PUSH1 0x00 [508] DUP1 [509] 'fd'(Unknown Opcode)
A en juger par le contenu de ces lignes, si le numéro du bloc courant est inférieur au troisième paramètre, revert () est appelé. Eh bien, c'est un comportement tout à fait raisonnable: appeler une fonction réelle dans un jeu avec un numéro de bloc du futur est impossible et c'est logique.
Cette vérification d'entrée est facile à contourner: nous extrayons juste quelques blocs sur testrpc et appelons à nouveau la fonction. Cette fois, la fonction renvoie avec succès Y.
Mais malheureusement X! = Y
Dommage. Cela signifie que le résultat de l'exécution de la fonction dépend non seulement des paramètres d'entrée, mais également de l'état de la blockchain du réseau principal, qui, bien sûr, diffère de l'état de la fausse blockchain testrpc.
Troisième partie: retrousser nos manches et creuser dans la pile
D'accord. Il est donc temps de retrousser vos manches. Le papier n'est plus adapté au suivi de l'état de la pile. Donc, pour un travail plus sérieux, nous allons lancer un désassembleur EVM très utile appelé
evmdis .
Comparé au papier et au stylo, il s'agit d'une avancée tangible. Continuons avec ce à quoi nous nous sommes arrêtés dans le dernier chapitre. Ce qui suit est une conclusion encourageante avec evmdis:
............. :label22 # Stack: [@0x70E @0x70E @0x70E 0x0 0x0 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x1EB PUSH(0x0) 0x1ED DUP1 0x1EE DUP1 0x1EF DUP1 0x1F0 DUP1 0x1F1 DUP1 0x1F3 DUP13 0x1F9 JUMPI(:label23, NUMBER() > POP()) # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 0x0 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x1FA PUSH(0x0) 0x1FC DUP1 0x1FD REVERT() :label23 # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 0x0 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x1FF DUP13 0x200 PUSH(BLOCKHASH(POP())) 0x201 SWAP11 0x202 POP() 0x203 DUP11 0x209 JUMPI(:label25, !!POP()) # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 @0x200 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x20C DUP13 0x213 PUSH((NUMBER() & ~0xFF) + (POP() & 0xFF)) 0x214 SWAP13 0x215 POP() 0x217 DUP13 0x21E JUMPI(:label24, !!(POP() < NUMBER())) # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 @0x200 0x0 @0x213 @0x85 @0x82 :label3 @0x34] 0x222 DUP13 0x223 PUSH(POP() - 0x100) 0x224 SWAP13 0x225 POP() :label24 # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 @0x200 0x0 [@0x223 | @0x213] @0x85 @0x82 :label3 @0x34] 0x227 DUP13 0x228 PUSH(BLOCKHASH(POP())) 0x229 SWAP11 0x22A POP() :label25 # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 [@0x200 | @0x228] 0x0 [@0x88 | @0x223 | @0x213] @0x85 @0x82 :label3 @0x34] 0x22C DUP11 0x22D DUP16 0x22E DUP16 ...........
Ce que evmdis est vraiment bon, c'est son utilité pour analyser JUMPDEST dans les bonnes étiquettes, qui ne peuvent pas être surestimées.
Donc, après avoir passé l'exigence initiale, nous nous retrouvons sur l'étiquette 23. Nous voyons DUP13 et rappelons du chapitre précédent que le nombre 13 sur la pile est notre troisième paramètre. Nous essayons donc d'obtenir le BLOCKHASH de notre troisième paramètre. Cependant, l'action de BLOCKHASH est limitée à 256 blocs. C'est pourquoi il est suivi de JUMPI (il s'agit d'une construction if). Si nous traduisons la logique des opcodes dans le langage du pseudo-code, nous obtenons quelque chose comme ceci:
func blockhash(p) { if (currentBlockNumber - p < 256) return hash(p); return 0; } var bhash = blockhash(thrid); if (bhash == 0) { thirdProjection = (currentBlockNumber & ~0xff) + (thridParam & 0xff); if (thirdProjection > currentBlockNumber) { thirdProjection -= 256; } thirdParam = thirdProjection; bhash = blockhash(thirdProjection); } label 25 and beyond ..... some more stuff related to thirdParam and bhash
un peu plus de trucs liés à thirdParam et bhash - autre code lié à thirdParam et block hash
Nous pensons maintenant que nous avons trouvé une raison pour laquelle nos résultats diffèrent de ceux que nous observons dans le réseau principal. Plus important encore, nous avons apparemment réussi à découvrir la source du hasard. A savoir: le hachage de bloc est calculé en fonction du troisième paramètre ou de la
prévision du troisième paramètre. Il est important de noter que dans la pile, le troisième paramètre est également remplacé par ce numéro de bloc prévu.
Évidemment, lors d'une exécution locale en dehors du réseau principal, nous n'avons pas d'option simple pour imposer un retour BLOCKHASH qui correspond aux valeurs du réseau principal. Quoi qu'il en soit, puisque nous connaissons les trois paramètres, nous pouvons facilement surveiller le réseau principal et obtenir le hachage du bloc H pour le troisième paramètre, ainsi que le hachage du bloc prévu.
Ensuite, nous pouvons insérer ce hachage directement dans le code d'octet dans notre environnement de test local, et si tout se passe comme prévu, nous obtiendrons enfin le bon ensemble de gènes.
Mais il y a un hic: DUP13 et BLOCKHASH ne sont que 2 octets dans le code, et si nous les remplaçons simplement par 33 octets PUSH32 0x * hash *, le compteur de programme changera complètement et nous devrons corriger chaque JUMP et JUMPI. Ou nous devrons faire JUMP à la fin du code et remplacer les instructions pour le code déployé, et ainsi de suite.
Eh bien, puisque nous sommes arrivés si loin, nous allons renifler un peu plus. Puisque nous poussons le hachage non nul de 32 octets dans la branche if, la condition sera toujours vraie et par conséquent, tout ce qui est écrit dans la partie else peut être simplement jeté pour faire de la place pour notre hachage de 32 octets. Eh bien, en général, c'est ce que nous avons fait:
Le point clé est que puisque nous avons abandonné la partie restante de la condition, nous devons remplacer le troisième paramètre d'entrée de la fonction mixGene par la prévision du troisième paramètre avant de l'appeler.
C'est au point que si vous essayez d'obtenir le résultat d'une opération
mixGene (X, Y, Z), où currentBlockNumber est Z <256, il vous suffit de remplacer le hachage PUSH32 par le hachage du bloc Z.
Cependant, si vous avez l’intention de faire ce qui suit
mixGene (X, Y, Z), où currentBlockNumber est Z ≥ 256, vous devrez remplacer le hachage PUSH32 par le hachage du bloc proj_Z, où proj_Z est défini comme suit:
proj_Z = (currentBlockNumber & ~0xff) + (Z & 0xff); if (proj_Z > currentBlockNumber) { proj_Z -= 256; } <b> Z proj_Z , mixGene(X, Y, proj_Z).</b>
Notez que proj_Z restera inchangé dans une certaine plage de blocs. Par exemple, si Z & 0xff = 128, alors proj_Z change uniquement sur chaque bloc zéro et 128e.
Pour confirmer cette hypothèse et vérifier s'il y a des pièges à venir, nous avons changé le bytecode et utilisé un autre utilitaire cool appelé
hevm .
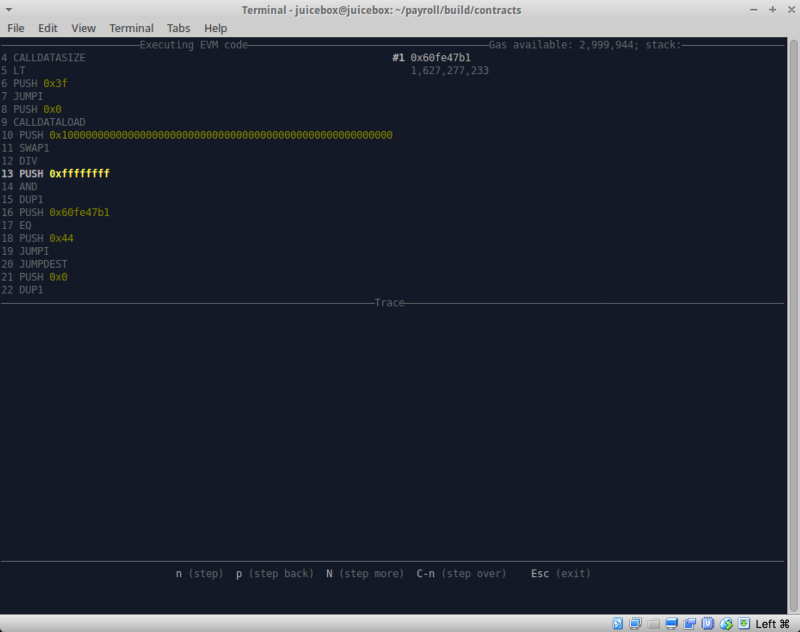
Si vous n'avez jamais utilisé hevm, je vous recommande de l'essayer. L'outil est disponible avec son propre framework, mais surtout dans son ensemble, il convient de noter une chose indispensable comme un débogueur de pile interactif.
Usage: hevm exec --code TEXT [--calldata TEXT] [--address ADDR] [--caller ADDR] [--origin ADDR] [--coinbase ADDR] [--value W256] [--gas W256] [--number W256] [--timestamp W256] [--gaslimit W256] [--gasprice W256] [--difficulty W256] [--debug] [--state STRING] Available options: -h,--help
Ci-dessus, les options de lancement. L'utilitaire vous permet de spécifier une variété de paramètres. Parmi eux, --debug, qui vous donne la possibilité de déboguer de manière interactive.
Nous avons donc ici passé plusieurs appels au contrat geneScience déployé sur la blockchain du réseau principal et enregistré les résultats. Ensuite, nous avons utilisé hevm pour exécuter notre bytecode cassé avec des données préparées en tenant compte des règles décrites ci-dessus et ...
Les résultats sont les mêmes!
Le dernier chapitre: conclusion et poursuite des travaux (?)
Alors, qu'avons-nous pu réaliser?
En utilisant notre logiciel de piratage, vous pouvez 100% de chances de prédire un gène 256 bits pour un chaton nouveau-né s'il est né dans la plage de blocs [coolDownEndBlock (lorsque le bébé est prêt à apparaître), le bloc actuel est + 256 (environ)]. Vous pouvez raisonner de cette façon: lorsque le bébé est dans l'utérus de la mère chat, ses gènes mutent au fil du temps, en raison de la source d'entropie sous la forme d'un hachage du bloc coolDownEndBlock prévu, qui change également avec le temps. Par conséquent, vous pouvez utiliser ce programme pour vérifier à quoi ressemblera le gène du bébé s'il est né maintenant. Et si vous n'aimez pas ce gène, vous pouvez attendre environ 256 blocs supplémentaires (en moyenne) et vérifier le nouveau gène.
Quelqu'un peut dire que cela ne suffit pas, car seule une précision de prédiction de 100% peut être considérée comme un piratage idéal avant même la grossesse d'une mère-chat. Cependant, cela n'est pas possible, car le gène du chaton est déterminé non seulement par les gènes de ses parents, mais aussi par le hachage prédit du bloc comme facteur de mutation, qui ne peut tout simplement pas être connu avant la fécondation.
Qu'est-ce qui peut être amélioré et quelles sont les nuances ici?
Nous avons rapidement passé en revue les changements qui se produisent sur la pile dans la vraie partie logique du contrat intelligent (étiquette 25 et tout ce qui suit) et nous pensons que cette partie prévisible du code mixGene est assez soumise à l'analyse et à l'étude. Nous espérons que le hachage de bloc en tant que facteur de mutation a également une certaine signification physique, aidant, par exemple, à déterminer quel gène doit être muté. Si nous parvenons à comprendre cela, nous obtiendrons le gène d'origine, sans mutations. C'est utile car si vous n'avez pas un bon gène source, alors même la meilleure mutation peut ne pas suffire.
Nous n'avons pas non plus mesuré la corrélation entre le gène 256 bits et les traits de chaton (couleur des yeux, type de queue, etc.), mais nous pensons que cela est tout à fait possible à l'aide d'un bot hautes performances et d'un simple classificateur.
Et en général, nous comprenons parfaitement l'intention de l'équipe de développement de CryptoKitties de stabiliser la mutation sur une courte période de temps. Mais le revers de cette approche est la possibilité d'effectuer une analyse comme nous l'avons fait.
Nous tenons également à remercier la merveilleuse communauté ethereum pour le développement d'outils tels que Etherscan, hevm, evmdis, truffle, testrpc, myetherwallet et Solidity. C'est une communauté très cool et nous sommes heureux d'en faire partie.
Et enfin, le code modifié
https://github.com/modong/GeneScienceCracked/N'oubliez pas de remplacer $ CONSTBLOCKHASH $ par le hachage du bloc prédit.
