
Notre journée commence par la phrase "Bonjour!". Pendant la journée, nous discutons avec des collègues, des parents, des amis et même des étrangers qui demandent des indications pour le métro le plus proche. Nous parlons même quand il n'y a personne autour de nous pour mieux percevoir notre propre raisonnement. Tout cela est notre discours - un cadeau qui est vraiment incomparable avec de nombreuses autres possibilités du corps humain. La parole nous permet d'établir des liens sociaux, d'exprimer des pensées et des émotions, de nous exprimer, par exemple, dans des chansons.
Et donc, les voitures intelligentes sont apparues dans la vie des gens. Une personne, soit par curiosité, soit par soif de nouvelles réalisations, essaie d'apprendre à parler à la machine. Mais pour parler, il faut entendre et écouter. De nos jours, il est difficile de surprendre avec un programme (par exemple Siri) qui peut reconnaître la parole, trouver un restaurant sur la carte, appeler maman, même raconter une blague. Elle comprend beaucoup, pas tous, bien sûr, mais beaucoup. Mais il n'en a pas toujours été ainsi, naturellement. Il y a des décennies, c'était pour le bonheur, quand une machine pouvait comprendre au moins une douzaine de mots.
Aujourd'hui, nous allons plonger dans l'histoire de la façon dont l'humanité a pu parler avec la machine, qui, au fil des siècles, a fait des percées dans ce domaine et a donné l'impulsion au développement de la technologie de reconnaissance vocale. Nous examinons également comment les appareils modernes perçoivent et traitent nos voix. Allons-y.
Les origines de la reconnaissance vocale
Qu'est-ce que la parole? En gros, c'est du son. Donc, pour reconnaître la parole, vous devez d'abord reconnaître le son et l'enregistrer.
Nous avons maintenant des iPod, des lecteurs MP3, avant les magnétophones, même les gramophones et les gramophones antérieurs. Ce sont tous des appareils pour jouer des sons. Mais qui était l'ancêtre de tous?
 Thomas Edison avec son invention. 1878 année
Thomas Edison avec son invention. 1878 annéeC'était un phonographe. Le 29 novembre 1877, le grand inventeur Thomas Edison présente sa nouvelle création, capable d'enregistrer et de reproduire des sons. C'est une percée qui a suscité le plus vif intérêt de la société.
Le principe du phonographe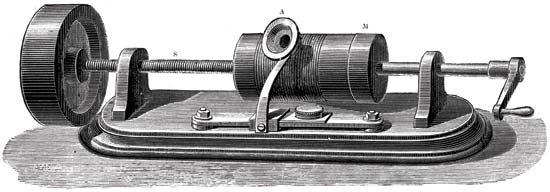
Les parties principales du mécanisme d'enregistrement sonore étaient un cylindre recouvert d'une feuille et une aiguille coupante. L'aiguille se déplaçait le long d'un cylindre qui tournait. Et les vibrations mécaniques ont été capturées à l'aide d'une membrane de microphone. En conséquence, l'aiguille a laissé des marques sur la feuille. En conséquence, nous avons reçu un cylindre avec un record. Pour le reproduire, le même cylindre a été initialement utilisé comme lors de l'enregistrement. Mais le foil était trop fragile et s'usait rapidement, car les disques étaient de courte durée. Ensuite, ils ont commencé à appliquer de la cire, qui recouvrait le cylindre. Afin de prolonger l'existence des enregistrements, ils ont commencé à copier à l'aide de la galvanoplastie. Grâce à l'utilisation de matériaux plus durs, les copies ont duré beaucoup plus longtemps.
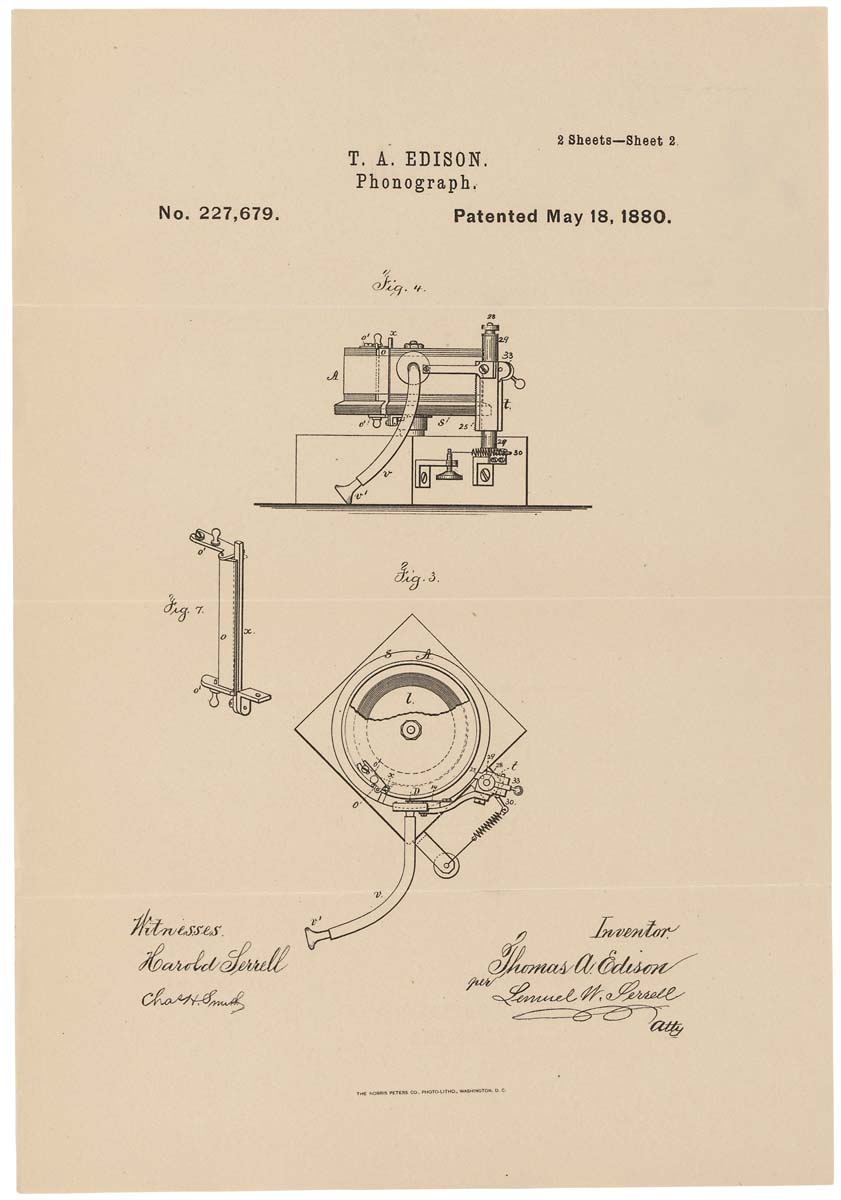 Illustration schématique d'un phonographe sur un brevet. 1880, 18 mai
Illustration schématique d'un phonographe sur un brevet. 1880, 18 maiCompte tenu des inconvénients ci-dessus, le phonographe, bien que ce soit une machine intéressante, mais il n'a pas été balayé des étagères. Ce n'est qu'avec l'avènement du phonographe à disque - mieux connu sous le nom de gramophone - que la reconnaissance publique est venue. La nouveauté a permis de faire des enregistrements plus longs (le premier phonographe ne pouvait enregistrer que quelques minutes), ce qui a duré longtemps. Et le gramophone lui-même était équipé d'un haut-parleur qui augmentait le volume de lecture.
Thomas Edison a initialement conçu le phonographe comme un appareil pour enregistrer des conversations téléphoniques, comme les enregistreurs vocaux modernes. Cependant, sa création a gagné une grande popularité dans la reproduction d'œuvres musicales. Ayant servi de début à la formation de l'industrie du disque.
Discours "orgue"
Bell Labs est célèbre pour ses inventions dans le domaine des télécommunications. Une telle invention était Voder.
En 1928, Homer Dudley a commencé à travailler sur un vocodeur, un appareil capable de synthétiser la parole. Nous parlerons de lui plus tard. Maintenant, nous allons considérer sa partie - le vador.
 Illustration schématique d'un vador
Illustration schématique d'un vadorLe principe de base du vador était de décomposer la parole humaine en composants acoustiques. La machine était extrêmement complexe et seul un opérateur qualifié pouvait la faire fonctionner.
Vader a imité les effets du tractus vocal humain. Il y avait 2 sons principaux que l'opérateur pouvait choisir avec son poignet. Des pédales ont été utilisées pour contrôler le générateur d'oscillations discontinues (bourdonnement), qui ont créé des voyelles voisées et des sons nasaux. Un tube à décharge gazeuse (sifflement) créait des sifflantes (consonnes fricatives). Tous ces sons sont passés à travers l'un des 10 filtres, qui a été sélectionné avec les touches. Il y avait aussi des touches spéciales pour les sons tels que "p" ou "d", et pour les affricats "j" dans le mot "mâchoire" et "ch" dans le mot "fromage".
Ce petit extrait de la présentation du vador démontre clairement le principe de son fonctionnement et des actions de l'opérateurUn opérateur ne pouvait produire un discours valablement reconnaissable qu'après plusieurs mois de pratique et d'entraînement intensifs.
Pour la première fois, le transporteur a été présenté lors d'une exposition à New York en 1939.
Économiser grâce à la synthèse vocale
Considérons maintenant un vocodeur, dont une partie était le pilote susmentionné.
 L'un des modèles de vocodeur: HY-2 (1961)
L'un des modèles de vocodeur: HY-2 (1961)Le vocodeur était à l'origine destiné à économiser les ressources de fréquence des liaisons radio lors de la transmission des messages vocaux. Au lieu de la voix elle-même, les valeurs de ses paramètres spécifiques ont été transmises, qui ont été traitées par le synthétiseur vocal à la sortie.
La base du vocodeur était constituée de trois propriétés principales:
- générateur de bruit (sons consonantiques);
- générateur de tonalité (voyelles);
- filtres formels (recréant les caractéristiques individuelles du locuteur).
Malgré son sérieux, le vocodeur a attiré l'attention des musiciens électroniques. La conversion du signal source et sa lecture sur un autre appareil ont permis d'obtenir une variété d'effets, tels que l'effet d'un instrument de musique chantant à «voix humaine».
Machine de comptage
En 1952, les technologies n'étaient pas aussi avancées qu'aujourd'hui. Mais cela n'a pas empêché les scientifiques enthousiastes de se fixer des tâches impossibles, selon beaucoup. Alors messieurs Stephen Balashek (S. Balashek), Ralon Biddulf (R. Biddulph) et K.Kh. Davis (KH Davis) a décidé d'enseigner à la machine à comprendre leur discours. Suite à l'idée, la voiture d'Audrey a vu le jour. Ses capacités étaient très limitées - elle ne pouvait reconnaître que les nombres de 0 à 9. Mais c'était déjà suffisant pour déclarer en toute sécurité une percée dans la technologie informatique.
 Audrey avec l'un de ses créateurs (selon Internet, corrigez-moi si ce n'est pas le cas)
Audrey avec l'un de ses créateurs (selon Internet, corrigez-moi si ce n'est pas le cas)Malgré ses petites capacités, Audrey ne pouvait pas se vanter d'avoir les mêmes dimensions. C'était une «fille» assez grande - l'armoire de relais mesurait près de 2 mètres de haut et tous les éléments occupaient une petite pièce. Ce qui n'est pas surprenant pour les ordinateurs de l'époque.
La procédure d'interaction entre l'opérateur et Audrey avait également certaines conditions. L'opératrice a prononcé les mots (chiffres, dans ce cas) dans le combiné d'un téléphone ordinaire, assurez-vous de résister à une pause de 350 millisecondes entre chaque mot. Audrey a accepté l'information, l'a traduite en format électronique et a allumé une ampoule spécifique correspondant à un chiffre particulier. Sans parler du fait que tous les opérateurs ne pouvaient pas obtenir une réponse exacte. Pour atteindre une précision de 97%, l'opérateur devait être une personne qui pratiquait le «bavardage» avec Audrey depuis longtemps. En d'autres termes, Audrey ne comprenait que ses créateurs.
Même en tenant compte de toutes les lacunes d'Audrey, qui ne sont pas associées à des erreurs de conception, mais aux limites de la technologie de l'époque, elle est devenue la première star à l'horizon des machines qui comprennent la voix humaine.
L'avenir dans la boîte à chaussures
En 1961, au IBM Advanced Systems Development Laboratory, un nouveau dispositif miracle a été développé - le Shoebox, qui peut reconnaître 16 mots (en anglais exclusivement) et des nombres de 0 à 9. L'auteur de cet ordinateur était William C. Dersch.
 Shoebox d'IBM
Shoebox d'IBMLe nom inhabituel correspondait à l'apparence de la machine, c'était la taille et la forme comme une boîte à chaussures. La seule chose qui a attiré mon attention était le microphone, qui était connecté aux trois filtres audio nécessaires pour reconnaître les sons aigus, moyens et faibles. Les filtres étaient connectés à un décodeur logique (circuit logique diode-transistor) et à un mécanisme interrupteur d'éclairage.
L'opératrice a porté le microphone à sa bouche et a prononcé un mot (par exemple, le numéro 7). La machine a converti les données acoustiques en signaux électroniques. Le résultat de l'entente a été l'inclusion d'une ampoule avec la signature "7". En plus de comprendre des mots individuels, Shoebox pourrait comprendre des problèmes arithmétiques simples (comme 5 + 6 ou 7-3) et donner la bonne réponse.
Shoebox a été présenté par son créateur en 1962 à l'Exposition universelle de Seattle.
Conversation téléphonique avec la voiture
En 1971, IBM, connue pour son amour des inventions et des technologies innovantes, a décidé de mettre en pratique la reconnaissance vocale. Le système d'identification automatique des appels a permis à un ingénieur situé partout aux États-Unis d'appeler un ordinateur à Raleigh, en Caroline du Nord. L'appelant peut poser une question et recevoir une réponse vocale. L'unicité de ce système résidait dans la compréhension des nombreuses voix, étant donné leur tonalité, leur accentuation, leur volume de discours, etc.
Harpie monte en flèche
Le bureau des projets de recherche avancée du ministère de la Défense (DARPA pour faire court) a annoncé le lancement d'un programme de développement et de recherche en reconnaissance vocale en 1971 qui vise à créer une machine capable de reconnaître 1000 mots. Un projet audacieux, compte tenu des succès de son prédécesseur, en quelques dizaines de mots. Mais il n'y a pas de limite à l'ingéniosité humaine. Et en 1976, l'Université Carnegie Mellon démontre Harpy, capable de reconnaître 1011 mots.
Démonstration vidéo de harpieL'université a déjà développé des systèmes de reconnaissance vocale - Hearsay-1 et Dragon. Ils ont servi de base à la mise en œuvre de Harpy.
Dans Hearsay-1, la connaissance (c'est-à-dire un dictionnaire machine) est représentée sous la forme de procédures, et dans Dragon - sous la forme d'un réseau de Markov avec une transition probabiliste a priori. Chez Harpy, il a été décidé d'utiliser le dernier modèle, mais sans cette transition.
Dans cette vidéo, le principe de fonctionnement est décrit plus en détail.
En termes simples, vous pouvez représenter un réseau - une séquence de mots et leurs combinaisons, ainsi que des sons avec un seul mot, pour que la machine comprenne la prononciation différente du même mot.
Harpy comprenait 5 opérateurs, dont trois hommes et deux femmes. Cela parlait des plus grandes capacités informatiques de cette machine. La précision de la reconnaissance vocale était d'environ 95%.
Tangora par IBM
Au début des années 80, IBM a décidé de développer un système capable de reconnaître plus de 20 000 mots au milieu de la décennie. Ainsi Tangora est né, dans le travail duquel des modèles Markov cachés ont été utilisés. Malgré un vocabulaire assez impressionnant, le système n'a pas nécessité plus de 20 minutes de collaboration avec le nouvel opérateur (la personne qui parle) pour apprendre à reconnaître son discours.
Poupée vivante
En 1987, la société de jouets Worlds of Wonder a sorti une nouveauté révolutionnaire - une poupée parlante nommée Julie. La caractéristique la plus impressionnante du jouet danois était la capacité de l'entraîner à reconnaître le discours du propriétaire. Julie pouvait assez bien parler. De plus, la poupée était équipée de nombreux capteurs, grâce auxquels elle réagissait lorsqu'elle était ramassée, chatouillée ou transférée d'une pièce sombre à une pièce lumineuse.
La publicité commerciale de Worlds of Wonder Julie présente ses caractéristiquesSes yeux et ses lèvres étaient mobiles, ce qui créait une image encore plus vivante. En plus de la poupée elle-même, il était possible d'acheter un livre dans lequel des images et des mots étaient faits sous forme d'autocollants spéciaux. Si vous tenez les poupées avec vos doigts, elles exprimeront ce qu'elles «ressentent» au toucher. Doll Julie a été le premier appareil doté d'une fonction de reconnaissance vocale, accessible à tous.
Le premier logiciel de dictée

En 1990, Dragon Systems a lancé le premier logiciel d'ordinateur personnel basé sur la reconnaissance vocale - DragonDictate. Le programme fonctionnait exclusivement sur Windows. L'utilisateur devait faire de petites pauses entre chaque mot pour que le programme puisse les analyser. À l'avenir, une version plus parfaite est apparue qui vous permet de parler en continu - Dragon NaturallySpeaking (c'est elle qui est disponible maintenant, tandis que le DragonDictate original a cessé de se mettre à jour depuis Windows 98). Malgré sa «lenteur», DragonDictate a gagné une grande popularité parmi les utilisateurs de PC, en particulier chez les personnes handicapées.
Sphinx non égyptien
L'Université Carnegie Mellon, qui s'est déjà «éclairée» plus tôt, est devenue le berceau d'un autre système de reconnaissance vocale historiquement important - Sphinx 2.
 Créateur de Sphinx Xuedong Huang
Créateur de Sphinx Xuedong HuangL'auteur direct du système était Xuedong Huang. Le Sphinx 2 se distingue de son prédécesseur par sa vitesse. Le système était axé sur la reconnaissance vocale en temps réel pour les programmes utilisant la langue parlée (de tous les jours). Parmi les caractéristiques de Sphinx 2 figuraient: la formation d'hypothèses, la commutation dynamique entre les modèles de langage, la détection d'équivalents, etc.
Le code Sphinx 2 a été utilisé dans de nombreux produits commerciaux. Et en 2000, sur le site Web de SourceForge, Kevin Lenzo a publié le code source du système pour une visualisation générale. Ceux qui souhaitent étudier le code source de Sphinx 2 et ses autres variantes peuvent suivre le
lien .
Dictée médicale
En 1996, IBM a lancé MedSpeak, le premier produit commercial avec reconnaissance vocale. Il était censé utiliser ce programme chez les médecins pour établir des dossiers médicaux. Par exemple, un radiologue, examinant les photos du patient, a exprimé ses commentaires, que le système MedSpeak a traduits en texte.
Avant de passer aux représentants les plus célèbres des programmes de reconnaissance vocale, examinons rapidement et brièvement quelques événements historiques liés à cette technologie.
Blitz historique
- 2002 - Microsoft intègre la reconnaissance vocale dans tous ses produits Office;
- 2006 - La US National Security Agency commence à utiliser des programmes de reconnaissance vocale pour identifier les mots-clés limites dans les enregistrements de conversation;
- 2007 (30 janvier) - Microsoft lance Windows Vista - le premier système d'exploitation avec reconnaissance vocale;
- 2007 - Google présente GOOG-411 - un système de transfert téléphonique (une personne appelle un numéro, indique de quelle organisation ou de quelle personne elle a besoin et le système les relie). Le système a fonctionné aux États-Unis et au Canada;
- 2008 (14 novembre) - Google lance la recherche vocale sur les appareils mobiles iPhone. Ce fut la première utilisation de la technologie de reconnaissance vocale dans les téléphones mobiles;
Et maintenant, nous arrivons à la période où beaucoup de gens ont découvert la technologie de reconnaissance vocale.
Les dames ne se querellent pas
Le 4 octobre 2011, Apple a annoncé Siri, dont le décodage du nom parle de lui-même - l'interface d'interprétation et de reconnaissance vocale (c'est-à-dire l'interface d'interprétation et de reconnaissance vocale).

L'histoire du développement de Siri est très longue (en fait, elle a 40 ans de travail) et intéressante. Le fait même de son existence et de ses fonctionnalités étendues est le travail conjoint de nombreuses entreprises et universités. Cependant, nous ne nous concentrerons pas sur ce produit, car l'article ne concerne pas Siri, mais la reconnaissance vocale en général.
Microsoft n'a pas voulu effleurer le dos, car en 2014 (2 avril) ils ont annoncé leur assistant numérique virtuel Cortana.

La fonctionnalité de Cortana est similaire à celle de son concurrent Siri, à l'exception d'un système plus flexible pour configurer l'accès à l'information.
Débat sur Cortana ou Siri. Qui est le meilleur? " menées depuis leur apparition sur le marché. Comme, en général, et la lutte entre les utilisateurs d'iOS et d'Android. Mais c'est bien. Les produits concurrents, dans le but de paraître meilleurs que leurs concurrents, offriront de plus en plus de nouvelles opportunités, développeront et utiliseront des technologies et des techniques plus avancées dans le même domaine de la reconnaissance vocale. N'ayant qu'un seul représentant dans n'importe quel domaine de la technologie grand public, il n'est pas nécessaire de parler de son développement rapide.
Une petite vidéo amusante de la conversation entre Siri et Cortana (évidemment construite, mais non moins drôle). Attention!: Dans cette vidéo il y a du blasphème.
Conversation avec des voitures. Comment nous comprennent-ils?
Comme je l'ai mentionné plus tôt, en gros, la parole est saine. Et quel est le son de la voiture? Ce sont des changements (fluctuations) de la pression atmosphérique, c.-à-d. ondes sonores. Pour que l'appareil (ordinateur ou téléphone) puisse reconnaître la parole, vous devez d'abord tenir compte de ces fluctuations. La fréquence de mesure doit être d'au moins 8 000 fois par seconde (encore mieux - 44 100 fois par seconde). Si les mesures sont effectuées avec des interruptions de temps importantes, nous obtiendrons un son inexact, ce qui signifie une parole illisible. Le processus décrit ci-dessus est appelé numérisation à 8 kHz ou 44,1 kHz.
Lorsque des données sur les vibrations des ondes sonores sont collectées, elles doivent être triées. Étant donné que dans le tas général, nous avons à la fois des sons de parole et des sons secondaires (bruit de machine, bruissement de papier, bruit d'un ordinateur qui fonctionne, etc.). La conduite d'opérations mathématiques nous permet d'éliminer précisément notre discours, qui a besoin de reconnaissance.
Vient ensuite l'analyse de l'onde sonore sélectionnée - la parole. Puisqu'il se compose de nombreux composants distincts qui forment certains sons (par exemple, "ah" ou "ee"). La mise en évidence de ces fonctionnalités et leur conversion en équivalents numériques vous permet de définir des mots spécifiques.
, , 40 (44, , 100), .. . , , . . , , «» , ( , , , ..), . , «t» «sTar» «t» «ciTy» -.
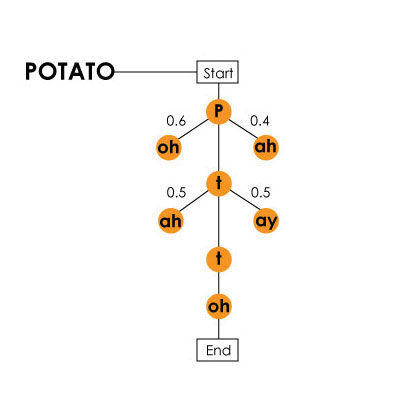 «potato» () / Harpy
«potato» () / Harpy, , . , «hang ten», — «hey, ngten», «ngten».
, , . , (), , №2 №1. «What do cats like for breakfast?» «water gaslight four brick vast?». , . . , , , . .
, . , , .
, . . - , ( , ), . . , , , . , -, , .
. 25% 3 6 !
! VPS (KVM) , , — !
VPS (KVM) c ( VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD 4TB HDD / 1Gbps 10TB — $29 / , RAID1 RAID10) , , , , , «»!
. c Dell R730xd 5-2650 v4 9000 ? Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 !