
Au cours de la dernière décennie, les réseaux neuronaux profonds (DNN) sont devenus un excellent outil pour un certain nombre de tâches d'IA comme la classification d'images, la reconnaissance vocale et même la participation à des jeux. Alors que les développeurs tentaient de montrer ce qui a causé le succès de DNN dans le domaine de la classification des images et ont créé des outils de visualisation (par exemple, Deep Dream, Filtres) qui aident à comprendre «ce qui» étudie exactement le modèle DNN, une nouvelle application intéressante est née : extraire le «style» d'une image et l'appliquer à une autre, contenu différent. Cela a été appelé le "transfert de style d'image".
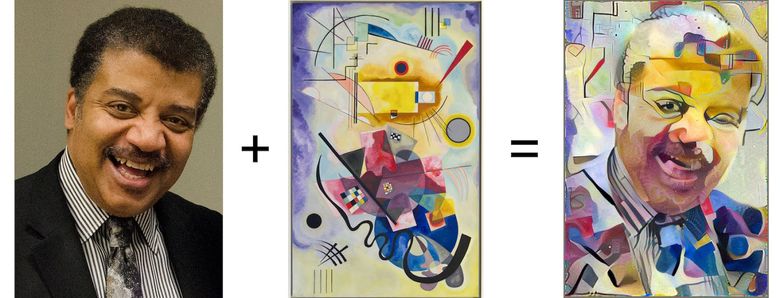
Gauche: image avec contenu utile, au centre: image avec style, droite: contenu + style (source: Google Research Blog )
Cela a non seulement suscité l'intérêt de nombreux autres chercheurs (par exemple, 1 et 2 ), mais a également conduit à l'émergence de plusieurs applications mobiles réussies. Au cours des deux dernières années, ces méthodes de transfert de style visuel se sont considérablement améliorées.

Habillage de style Adobe (source: Engadget )

Exemple tiré du site Web de Prisma
Une brève introduction à ces algorithmes:
Cependant, malgré les progrès de l'utilisation des images, l'application de ces techniques dans d'autres domaines, par exemple pour le traitement de la musique, était très limitée (voir 3 et 4 ), et les résultats ne sont pas du tout aussi impressionnants que dans le cas des images. Cela suggère qu'il est beaucoup plus difficile de transférer le style dans la musique. Dans cet article, nous examinerons le problème plus en détail et discuterons de certaines approches possibles.
Pourquoi est-il si difficile de transférer du style en musique?
Répondons d'abord à la question: qu'est-ce que le «transfert de style» en musique ? La réponse n'est pas si évidente. En images, les concepts de «contenu» et de «style» sont intuitifs. Le «contenu d'image» décrit les objets représentés, par exemple les chiens, les maisons, les visages, etc., et le «style d'image» fait référence aux couleurs, à l'éclairage, aux coups de pinceau et à la texture.
Cependant, la musique est sémantiquement abstraite et multidimensionnelle . Le «contenu musical» peut signifier différentes choses dans différents contextes. Souvent, le contenu de la musique est associé à une mélodie et le style à un arrangement ou une harmonisation. Cependant, le contenu peut être les paroles et les différentes mélodies utilisées pour chanter peuvent être interprétées comme des styles différents. En musique classique, le contenu peut être considéré comme la partition (qui inclut l'harmonisation), tandis que le style est l'interprétation des notes par l'interprète, qui apporte sa propre expression (variant et ajoutant des sons de lui-même). Pour mieux comprendre l'essence du transfert de style dans la musique, regardez quelques-unes de ces vidéos:
Dans la deuxième vidéo, différentes techniques d' apprentissage automatique sont utilisées.
Ainsi, le transfert de style en musique est, par définition, difficile à formaliser. Il existe d'autres facteurs clés qui compliquent la tâche:
- Les machines BAD comprennent la musique (pour l'instant): le succès du transfert de style dans les images découle du succès de DNN dans les tâches liées à la compréhension des images, telles que la reconnaissance d'objets. Étant donné que les DNN peuvent apprendre des propriétés qui varient d'un objet à l'autre, des techniques de rétropropagation peuvent être utilisées pour modifier l'image cible pour qu'elle corresponde aux propriétés du contenu. Bien que nous ayons fait des progrès significatifs dans la création de modèles basés sur DNN capables de comprendre des tâches musicales (par exemple, transcrire des mélodies, définir un genre, etc.), nous sommes encore loin des sommets atteints dans le traitement d'images. C'est un sérieux obstacle au transfert de style en musique. Les modèles existants ne peuvent tout simplement pas apprendre les «excellentes» propriétés qui permettent de classer la musique, ce qui signifie que l'application directe des algorithmes de transfert de style utilisés pour travailler avec des images ne donne pas le même résultat.
- La musique est éphémère : ce sont des données représentant des séries dynamiques, c'est-à-dire qu'un fragment musical change avec le temps. Cela complique l'apprentissage. Bien que les réseaux de neurones récurrents et LSTM (Long Short-Term Memory) vous permettent d'en apprendre davantage à partir de données transitoires, nous devons encore créer des modèles fiables qui peuvent apprendre à reproduire la structure à long terme de la musique (remarque: il s'agit d'un domaine de recherche réel, et des scientifiques de l'équipe Google Magenta a obtenu un certain succès dans ce domaine ).
- La musique est discrète (au moins au niveau symbolique): la musique symbolique ou enregistrée sur papier est de nature discrète. Dans le tempérament uniforme , le système d'accord d'instruments de musique le plus populaire aujourd'hui, les tonalités sonores occupent des positions discrètes sur une échelle de fréquence continue. Dans le même temps, la durée des tons se situe également dans un espace discret (généralement des quarts de ton, des tons pleins, etc.). Par conséquent, il est très difficile d'adapter les méthodes de propagation de pixel back (utilisées pour travailler avec des images) dans le domaine de la musique symbolique.
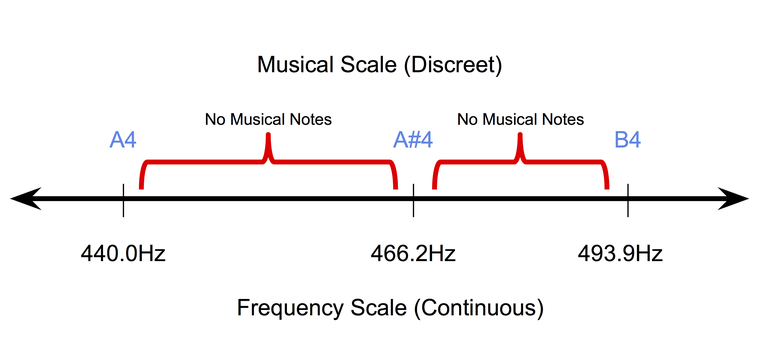
La nature discrète des notes de musique dans un tempérament uniforme.
Par conséquent, les techniques utilisées pour transférer le style dans les images ne sont pas directement applicables à la musique. Pour ce faire, ils doivent être traités en mettant l'accent sur les concepts et les idées musicales.
À quoi sert le transfert de style en musique?
Pourquoi avez-vous besoin de résoudre ce problème? Comme pour les images, les utilisations potentielles du transfert de style en musique sont assez intéressantes. Par exemple, développer un outil pour aider les compositeurs . Par exemple, un instrument automatique capable de transformer une mélodie en utilisant des arrangements de différents genres sera extrêmement utile pour les compositeurs qui ont besoin d'essayer rapidement différentes idées. Les DJ seront également intéressés par ces instruments.
Un résultat indirect de ces recherches sera une amélioration significative des systèmes informatiques musicaux. Comme expliqué ci-dessus, pour que le transfert de style fonctionne en musique, les modèles que nous créons doivent apprendre à mieux "comprendre" les différents aspects.
Simplifiez la tâche de transfert de style dans la musique
Commençons par une tâche très simple d'analyse de mélodies monophoniques dans différents genres. Les mélodies monophoniques sont des séquences de notes, chacune étant déterminée par le ton et la durée. La progression de la hauteur dépend en grande partie de l'échelle de la mélodie et la progression de la durée dépend du rythme. Donc, tout d'abord, nous séparons clairement le « contenu de hauteur» et le «style rythmique» en deux entités avec lesquelles vous pouvez reformuler la tâche de transfert de style. De plus, lorsque vous travaillez avec des mélodies monophoniques, nous évitons désormais les tâches associées à l'arrangement et au texte.
En l'absence de modèles pré-entraînés capables de distinguer avec succès les progressions de tons et les rythmes des mélodies monophoniques, nous avons d'abord recours à une approche très simple du transfert de style. Au lieu d'essayer de changer le contenu de la tonalité appris sur la mélodie cible avec le style rythmique appris sur le rythme cible, nous allons essayer d'enseigner individuellement les modèles de tonalités et les durées de différents genres, puis essayer de les combiner. Schéma approximatif de l'approche:
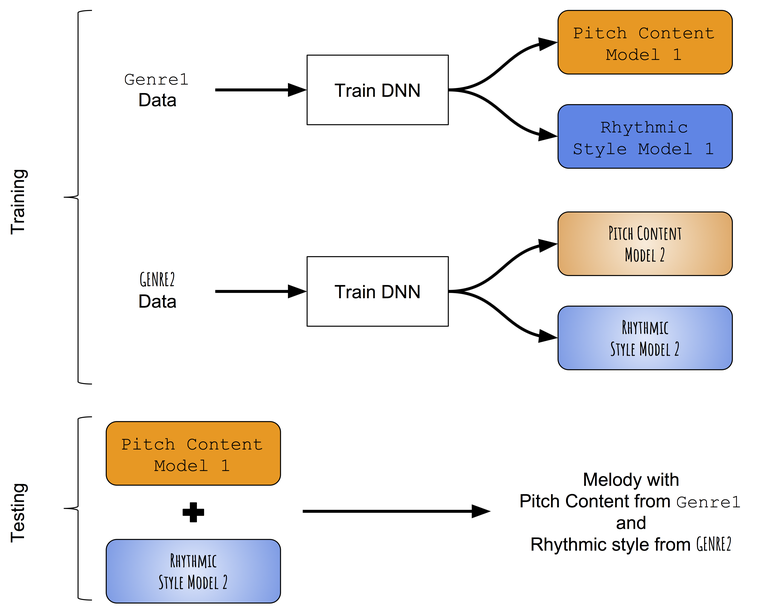
Schéma de la méthode de transfert de style intergenre.
Nous enseignons séparément les progressions de ton et de rythme
Présentation des données
Nous présenterons les mélodies monophoniques comme une séquence de notes musicales, chacune ayant un index de tonalité et une séquence. Afin que notre clé de présentation soit indépendante, nous utiliserons la présentation en fonction d'intervalles: le ton de la note suivante sera présenté comme un écart (± demi-ton) par rapport au ton de la note précédente. Créons deux dictionnaires pour les tons et les durées dans lesquels chaque état discret (pour le ton: +1, -1, +2, -2, etc.); pour les durées: une noire, une note complète, un quart avec un point, etc.) se voit attribuer un index dictionnaire.
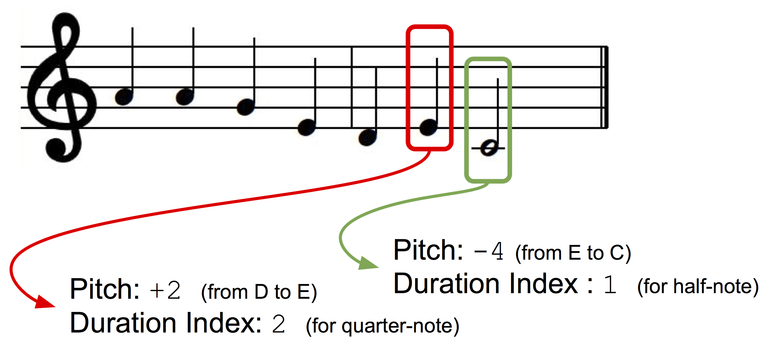
Présentation des données.
Architecture du modèle
Nous utiliserons la même architecture que Colombo et ses collègues ont utilisée - ils ont simultanément enseigné deux réseaux de neurones LSTM au même genre musical: a) le réseau de sons appris à prédire le ton suivant en fonction de la note précédente et de la durée précédente, b) le réseau de durée appris à prédire la durée suivante en fonction de la note suivante et durée précédente. De plus, avant les réseaux LSTM, nous ajouterons des couches d'intégration pour comparer les indices de tonalité d'entrée et les durées dans les espaces d'intégration mémorisés. L'architecture du réseau neuronal est illustrée dans l'image:
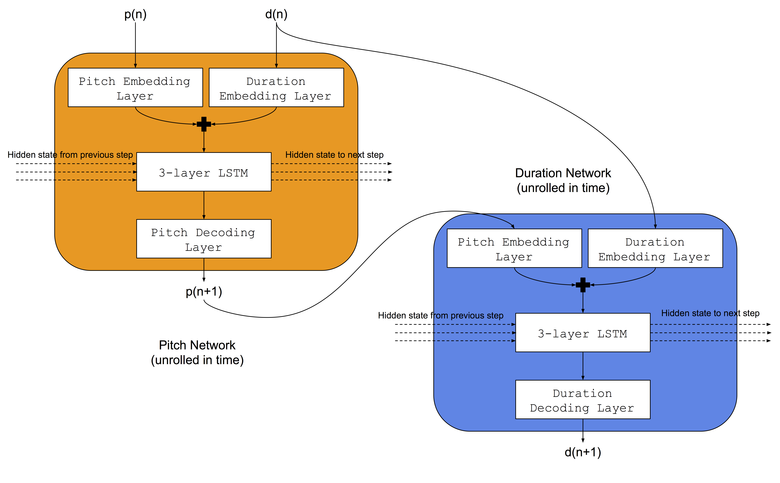
Procédure de formation
Pour chaque genre, les réseaux responsables des tonalités et des durées sont formés en même temps. Nous utiliserons deux ensembles de données: a) un ensemble de données folkloriques de Norbeck , couvrant environ 2 000 mélodies folk irlandaises et suédoises, b) un ensemble de données de jazz (non accessible au public), couvrant environ 500 morceaux de jazz.
Fusion de modèles formés
Pendant le test, la mélodie est d'abord générée en utilisant le réseau de sons et le réseau de durée formés dans le premier genre (par exemple, folk). Ensuite, la séquence de sons de la mélodie générée est utilisée en entrée pour un réseau de séquences entraînées dans un autre genre (par exemple, le jazz), et le résultat est une nouvelle séquence de durées. Par conséquent, une mélodie créée en utilisant une combinaison de deux réseaux de neurones a une séquence de tons correspondant au premier genre (folk) et une séquence de durées correspondant au deuxième genre (jazz).
Résultats préliminaires
De courts extraits de quelques-uns des morceaux obtenus:
Tonalités folkloriques et durées folkloriques

Extrait de la notation musicale.
Tonalités folkloriques et durées jazz

Extrait de la notation musicale.
Sons de jazz et séquences de jazz

Extrait de la notation musicale .
Sons de jazz et séquences folkloriques

Extrait de la notation musicale.
Conclusion
Bien que l'algorithme actuel ne soit pas mauvais au départ, il présente un certain nombre d'inconvénients critiques:
- Il est impossible de «transférer le style» en fonction d'une mélodie cible spécifique . Les modèles apprennent des modèles de tons et de durées dans un genre, ce qui signifie que toutes les transformations sont déterminées par le genre. Il serait idéal de modifier un morceau de musique dans le style d'une chanson ou d'un morceau cible spécifique.
- Il n'est pas possible de contrôler le degré de changement de style. Il serait très intéressant d'obtenir une «poignée» régissant cet aspect.
- Lors de la fusion des genres, il est impossible de conserver la structure musicale dans une mélodie transformée. Une structure à long terme est importante pour l'évaluation musicale en général, et pour que les mélodies générées soient musicalement esthétiques, la structure doit être préservée.
Dans les articles suivants, nous examinerons les moyens de contourner ces lacunes.