Exemple de fonctionnement AttnGAN. Dans la rangée supérieure se trouvent plusieurs images de différentes résolutions générées par un réseau neuronal. Les deuxième et troisième lignes montrent le traitement des cinq mots les plus appropriés par deux modèles de l'attention du réseau neuronal pour dessiner les sections les plus pertinentesLa création automatique d'images à partir de descriptions de texte dans un langage naturel est un problème fondamental pour de nombreuses applications, telles que la génération d'art et la conception informatique. Ce problème stimule également les progrès dans le domaine de la formation à l'IA multimodale avec une relation entre la vision et le langage.
Des recherches récentes menées par des chercheurs dans ce domaine sont basées sur des réseaux contradictoires génératifs (GAN). L'approche générale consiste à traduire la description textuelle entière dans le vecteur de phrase global. Cette approche démontre un certain nombre de résultats impressionnants, mais elle présente les principaux inconvénients: le manque de détails clairs au niveau des mots et l'impossibilité de générer des images haute résolution. Une équipe de développeurs de Lichai University, Rutgers University, Duke University (all - USA) et Microsoft ont proposé leur solution au problème: le nouveau réseau de neurones
Attentionn Generative Adversarial Network (AttnGAN) est une amélioration de l'approche traditionnelle et permet un changement en plusieurs étapes de l'image générée, en changeant des mots individuels dans le texte description.
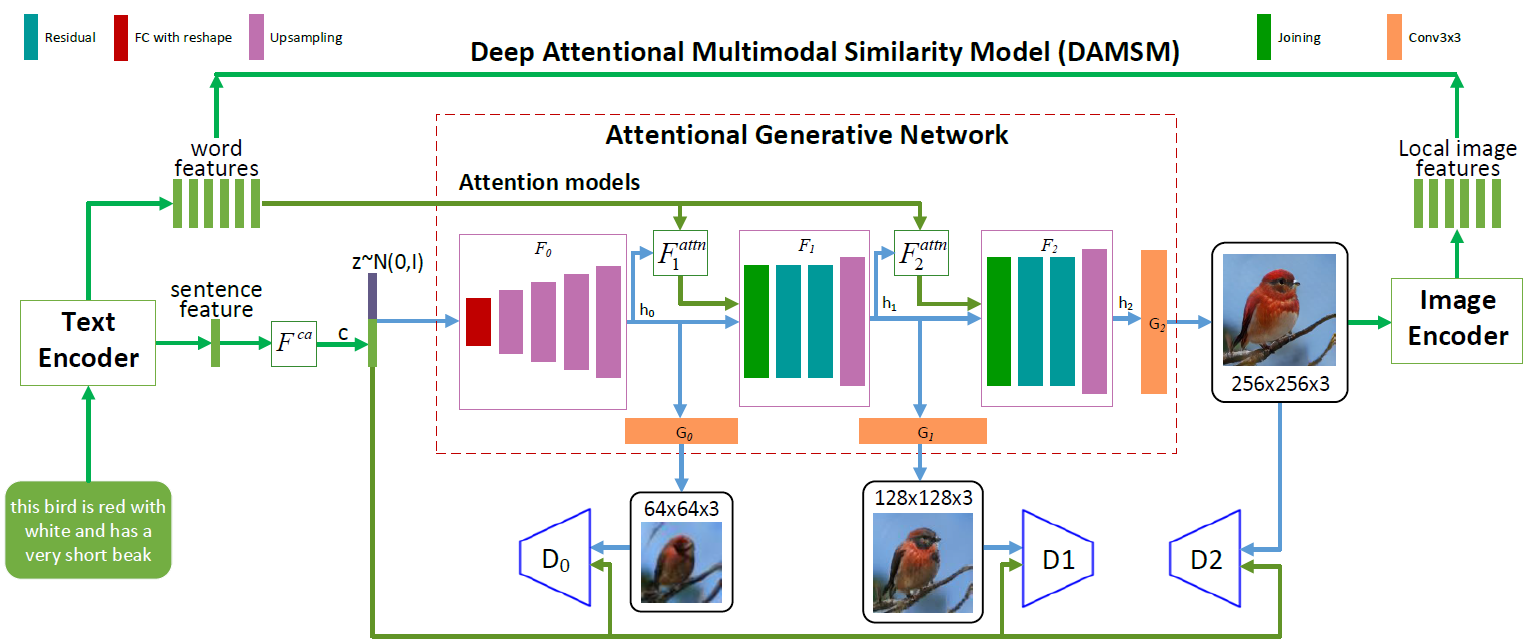 Architecture du réseau neuronal AttnGAN. Chaque modèle d'attention reçoit automatiquement des conditions (c'est-à-dire des vecteurs de vocabulaire correspondants) pour générer différentes zones de l'image. Le module DAMSM offre une granularité supplémentaire pour la fonction de perte de conformité dans la traduction de l'image au texte dans le réseau génératif
Architecture du réseau neuronal AttnGAN. Chaque modèle d'attention reçoit automatiquement des conditions (c'est-à-dire des vecteurs de vocabulaire correspondants) pour générer différentes zones de l'image. Le module DAMSM offre une granularité supplémentaire pour la fonction de perte de conformité dans la traduction de l'image au texte dans le réseau génératifComme vous pouvez le voir dans l'illustration décrivant l'architecture du réseau neuronal, le modèle AttnGAN présente deux innovations par rapport aux approches traditionnelles.
Tout d'abord, il s'agit d'un réseau accusatoire, qui fait référence à l'attention comme facteur d'apprentissage (Attentional Generative Adversarial Network). Autrement dit, il met en œuvre le mécanisme d'attention, qui détermine les mots les plus appropriés pour générer les parties correspondantes de l'image. En d'autres termes, en plus de coder l'intégralité de la description textuelle dans l'espace vectoriel global des phrases, chaque mot individuel est également codé en tant que vecteur textuel. À la première étape, le réseau neuronal génératif utilise l'espace vectoriel global des phrases pour rendre une image à basse résolution. Dans les étapes suivantes, elle utilise le vecteur d'image dans chaque région pour interroger les vecteurs de dictionnaire, en utilisant la couche d'attention pour former le vecteur de contexte de mot. Ensuite, le vecteur d'image régional est combiné avec le vecteur de contexte de mot correspondant pour former un vecteur de contexte multimodal, sur la base duquel le modèle génère de nouvelles caractéristiques d'image dans les régions respectives. Cela vous permet d'augmenter efficacement la résolution de l'image entière dans son ensemble, car à chaque étape, il y a de plus en plus de détails.
La deuxième innovation de Microsoft en matière de réseau neuronal est le module DAMSM (Deep Attentional Multimodal Similarity Model). À l'aide du mécanisme d'attention, ce module calcule le degré de similitude entre l'image générée et la phrase de texte, en utilisant à la fois des informations du niveau de l'espace vectoriel des phrases et un niveau bien détaillé de vecteurs de dictionnaire. Ainsi, DAMSM fournit une granularité supplémentaire pour la perte de la fonction d'ajustement lors de la traduction de l'image au texte lors de la formation du générateur.
Grâce à ces deux innovations, le réseau de neurones AttnGAN affiche des résultats nettement meilleurs que le meilleur des systèmes GAN traditionnels, écrivent les développeurs. En particulier, le score de démarrage maximum connu pour les réseaux de neurones existants a été amélioré de 14,14% (de 3,82 à 4,36) sur l'ensemble de données CUB et amélioré jusqu'à 170,25% (de 9,58 à 25,89) sur l'ensemble de données COCO plus sophistiqué.
L'importance de cette évolution est difficile à surestimer. Le réseau de neurones AttnGAN a montré pour la première fois qu'un réseau génératif-accusatoire multicouche, qui se réfère à l'attention comme facteur d'apprentissage, est capable de déterminer automatiquement les conditions au niveau du mot pour générer des parties individuelles d'une image.
L'article scientifique a été
publié le 28 novembre 2017 sur le site de préimpression arXiv.org (arXiv: 1711.10485v1).