L'idée de fusionner l'informatique quantique et l'apprentissage automatique est à son apogée. Peut-elle répondre à des attentes élevées?

Au début des années 1990, Elizabeth Behrman, professeur de physique à
l'Université de Wichita, a commencé à travailler sur la fusion de la physique quantique avec l'intelligence artificielle - en particulier dans la technologie de réseau neuronal alors impopulaire. La plupart des gens pensaient qu'elle essayait de mélanger l'huile et l'eau. «C'était vraiment difficile pour moi de publier», se souvient-elle. - Les magazines sur les réseaux de neurones ont dit: "De quel type de mécanique quantique s'agit-il?", Et les magazines de physique ont dit "De quel type de réseau de neurones s'agit-il?"
Aujourd'hui, un mélange de ces deux concepts semble la chose la plus naturelle au monde. Les réseaux de neurones et autres systèmes d'apprentissage automatique sont devenus la technologie la plus soudaine du 21e siècle. Ils réussissent mieux dans les occupations humaines que chez les humains, et ils nous dépassent non seulement dans les tâches dans lesquelles la plupart d'entre nous n'ont pas brillé de toute façon - par exemple, dans les échecs ou l'analyse approfondie des données, mais aussi dans les tâches pour lesquelles le cerveau a évolué - par exemple, reconnaissance faciale, traduction linguistique et détermination de l'emprise à une intersection à quatre voies. Ces systèmes sont devenus possibles en raison de l'énorme puissance informatique, il n'est donc pas surprenant que les entreprises technologiques aient commencé à rechercher des ordinateurs non seulement plus grands, mais appartenant à une toute nouvelle classe.
Après des décennies de recherche, les ordinateurs quantiques sont presque prêts à effectuer des calculs avant tout autre ordinateur sur Terre. Leur principal avantage est généralement la factorisation de grands nombres - une opération qui est la clé des systèmes de cryptage modernes. Certes, à ce stade, il reste encore au moins dix ans. Mais les processeurs quantiques rudimentaires d'aujourd'hui sont également mystérieusement parfaits pour les besoins d'apprentissage automatique. Ils manipulent d'énormes quantités de données en une seule passe, recherchent des modèles insaisissables qui sont invisibles pour les ordinateurs classiques et ne sortent pas avant les données incomplètes ou non définies. «Il existe une symbiose naturelle entre la nature essentiellement statistique de l'informatique quantique et de l'apprentissage automatique», explique Johann Otterbach, physicien à Rigetti Computing, une société d'informatique quantique à Berkeley, en Californie.
D'ailleurs, le pendule a déjà basculé à un autre maximum. Google, Microsoft, IBM et d'autres géants de la technologie investissent de l'argent dans l'apprentissage automatique quantique (KMO) et dans un incubateur de startup dédié à ce sujet, situé à l'Université de Toronto. «L'apprentissage automatique» devient un mot à la mode », explique
Jacob Biamont , spécialiste de physique quantique à l'
Institut des sciences et technologies de Skolkovo . "Et en le mélangeant avec le concept de" quantique ", vous apprendrez un mot mégamode."
Mais le concept de «quantum» ne signifie jamais exactement ce qu'on attend de lui. Bien que vous puissiez décider que le système KMO doit être puissant, il souffre du syndrome «enfermé». Il fonctionne avec des états quantiques, et non avec
des données
lisibles par
l'homme , et la traduction entre ces deux mondes peut égaliser tous ses avantages évidents. C'est comme si l'iPhone X, qui a toutes ses fonctionnalités impressionnantes, n'est pas plus rapide que l'ancien téléphone, car le réseau local est dégoûtant. Dans certains cas particuliers, les physiciens peuvent surmonter ce goulot d'étranglement d'E / S, mais il n'est toujours pas clair si de tels cas apparaîtront lors de la résolution de problèmes pratiques avec MO. «Nous n'avons pas encore de réponses claires», explique
Scott Aaronson , un spécialiste informatique à l'Université du Texas à Austin, essayant toujours de vraiment regarder les choses dans le domaine de l'informatique quantique. "Les gens sont assez prudents quant à la question de savoir si ces algorithmes donneront une sorte d'avantage de vitesse."
Neurones quantiques
La tâche principale d'un réseau neuronal, qu'il soit classique ou quantique, est de reconnaître les modèles. Il est créé à l'image du cerveau humain et est un réseau d'unités informatiques de base - les «neurones». Chacun d'eux ne peut être plus difficile à allumer / éteindre. Un neurone surveille la sortie de nombreux autres neurones, comme s'il votait sur certaines questions, et passe en position de marche si suffisamment de neurones ont voté pour. En règle générale, les neurones sont disposés en couches. Le premier calque accepte une entrée (par exemple, des pixels d'image), les calques du milieu créent diverses combinaisons d'entrée (représentant des structures telles que des visages et des formes géométriques) et le dernier calque produit une sortie (une description de haut niveau de ce qui est dans l'image).
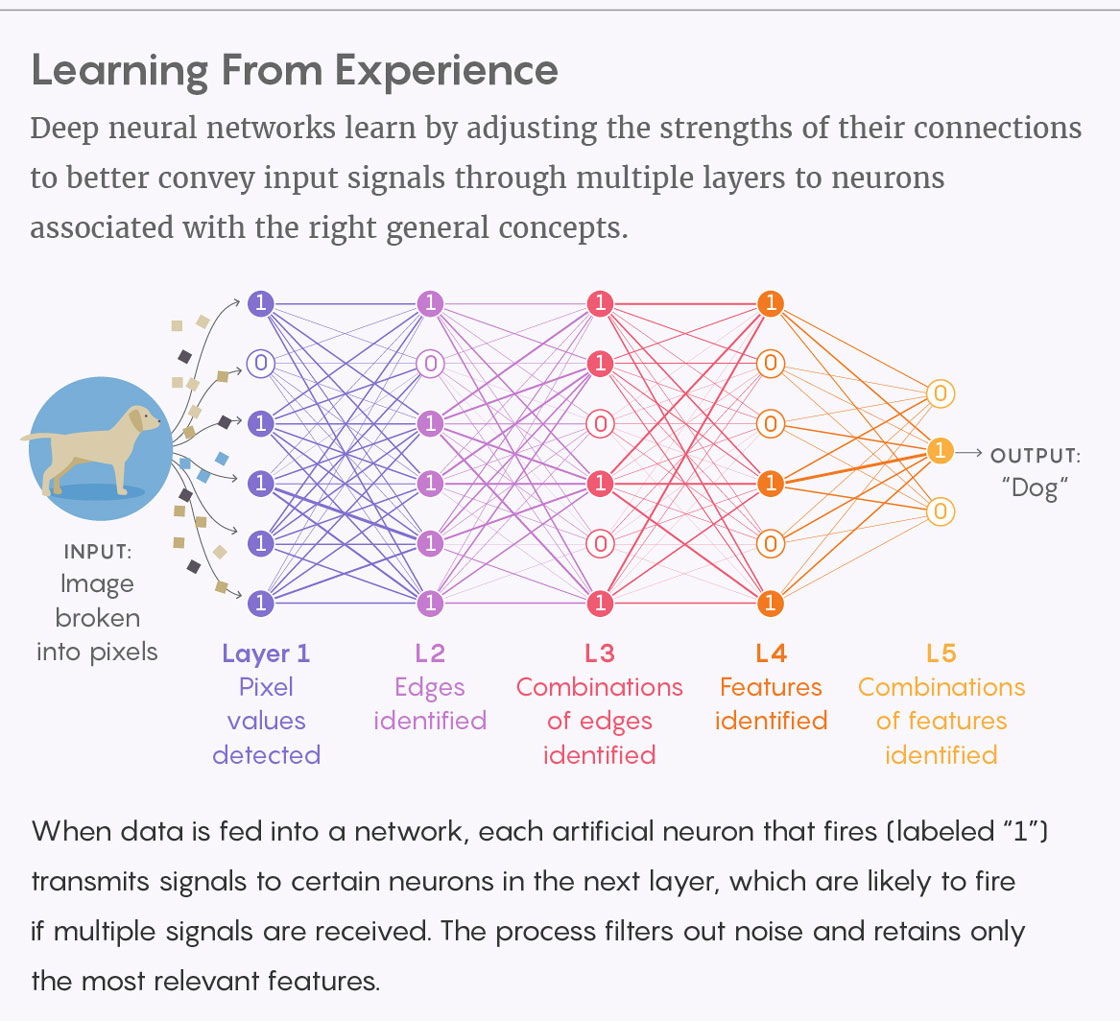 Les réseaux de neurones profonds sont formés en ajustant le poids de leurs connexions de la meilleure façon pour transmettre des signaux à travers plusieurs couches aux neurones associés aux concepts généralisés nécessaires
Les réseaux de neurones profonds sont formés en ajustant le poids de leurs connexions de la meilleure façon pour transmettre des signaux à travers plusieurs couches aux neurones associés aux concepts généralisés nécessairesCe qui est important, tout ce schéma n'est pas élaboré à l'avance, mais est adapté dans le processus d'apprentissage par essais et erreurs. Par exemple, nous pouvons alimenter des réseaux d'images étiquetés «chaton» ou «chiot». Il attribue une étiquette à chaque image, vérifie si elle a réussi et sinon, il corrige les connexions neuronales. Au début, cela fonctionne presque par accident, mais améliore ensuite les résultats; après, disons, 10 000 exemples, elle commence à comprendre les animaux de compagnie. Il peut y avoir un milliard de connexions internes dans un réseau neuronal sérieux, et toutes doivent être ajustées.
Sur un ordinateur classique, ces connexions sont représentées par une fabuleuse matrice de nombres, et le fonctionnement du réseau signifie effectuer des calculs matriciels. En règle générale, ces opérations avec la matrice sont données pour le traitement sur une puce spéciale - par exemple, un
GPU . Mais personne ne peut faire des opérations matricielles mieux qu'un ordinateur quantique. «Le traitement de grandes matrices et vecteurs sur un ordinateur quantique est exponentiellement plus rapide», explique Seth Lloyd, physicien au Massachusetts Institute of Technology et pionnier de l'informatique quantique.
Pour résoudre ce problème, les ordinateurs quantiques sont en mesure de tirer parti de la nature exponentielle d'un système quantique. La plupart de la capacité d'information d'un système quantique n'est pas contenue dans ses unités de données individuelles - qubits, analogues quantiques de bits d'un ordinateur classique - mais dans les propriétés conjointes de ces qubits. Deux qubits ont ensemble quatre états: à la fois on, off, on / off et off / on. Chacun a un certain poids, ou «amplitude», qui peut jouer le rôle d'un neurone. Si vous ajoutez un troisième qubit, vous pouvez imaginer huit neurones; le quatrième - 16. La capacité de la machine augmente de façon exponentielle. En fait, les neurones sont enduits dans tout le système. Lorsque vous changez l'état de quatre qubits, vous traitez 16 neurones en un seul coup, et un ordinateur classique devrait traiter ces nombres un à la fois.
Lloyd estime que 60 qubits suffisent pour encoder la quantité de données que l'humanité produit en un an, et 300 peuvent contenir le contenu classique de l'Univers entier. Le plus grand ordinateur quantique disponible aujourd'hui, construit par IBM, Intel et Google, compte environ 50 qubits. Et ce n'est que si nous supposons que chaque amplitude représente un bit classique. En fait, les amplitudes sont des valeurs continues (et représentent des nombres complexes), et avec une précision adaptée à la résolution de problèmes pratiques, chacune d'elles peut stocker jusqu'à 15 bits, explique Aaronson.
Mais la capacité d'un ordinateur quantique à stocker des informations sous forme compressée ne les rend pas plus rapides. Il faut pouvoir utiliser ces qubits. En 2008, Lloyd, le physicien
Aram Harrow du MIT et
Avinatan Hassidim , informaticien à l'Université Bar-Ilan en Israël,
ont montré comment une importante opération d'inversion de matrice algébrique pouvait être réalisée. Ils l'ont divisé en une séquence d'opérations logiques qui peuvent être effectuées sur un ordinateur quantique. Leur algorithme fonctionne pour un grand nombre de technologies MO. Et il n'a pas besoin d'autant d'étapes que, disons, en factorisant un grand nombre. Un ordinateur peut effectuer rapidement une tâche de classification avant que le bruit - un facteur limitant majeur de la technologie moderne - ne puisse tout gâcher. "Avant d'avoir un ordinateur quantique entièrement polyvalent et résistant aux erreurs, vous pouvez simplement avoir un avantage quantique", a déclaré Kristan Temm du Centre de recherche. Thomas Watson d'IBM.
Laissez la nature résoudre le problème
Jusqu'à présent, l'apprentissage automatique basé sur l'informatique à matrice quantique n'a été démontré que sur des ordinateurs à quatre qubits. La plupart des succès expérimentaux de l'apprentissage automatique quantique utilisent une approche différente dans laquelle un système quantique ne simule pas seulement un réseau, mais est un réseau. Chaque qubit est responsable d'un neurone. Et bien qu'il ne soit pas nécessaire de parler de croissance exponentielle, un tel appareil peut tirer parti d'autres propriétés de la physique quantique.
Le plus grand de ces appareils, contenant environ 2 000 qubits, a été fabriqué par D-Wave Systems, près de Vancouver. Et ce n'est pas exactement ce que les gens imaginent en pensant à l'ordinateur. Au lieu d'obtenir une entrée, d'effectuer une séquence de calculs et d'afficher la sortie, cela fonctionne en trouvant une cohérence interne. Chacun des qubits est une boucle électrique supraconductrice, fonctionnant comme un minuscule électro-aimant, orienté vers le haut, vers le bas ou les deux vers le haut et vers le bas - c'est-à-dire étant en superposition. Ensemble, les qubits se lient en raison de l'interaction magnétique.

Pour démarrer ce système, vous devez d'abord appliquer un champ magnétique orienté horizontalement qui initialise les qubits avec la même superposition de haut en bas - l'équivalent d'une feuille vierge. Il existe plusieurs façons d'entrer des données. Dans certains cas, vous pouvez fixer la couche qubit aux valeurs initiales requises; plus souvent, les entrées sont incluses en raison des interactions. Ensuite, vous autorisez les qubits à interagir les uns avec les autres. Certains essaient de s'aligner de la même manière, certains dans la direction opposée, et sous l'influence d'un champ magnétique horizontal, ils basculent vers l'orientation préférée. Dans ce processus, ils peuvent forcer d'autres qubits à changer. Au début, cela se produit assez souvent, car tant de qubits sont mal localisés. Au fil du temps, ils se calment, après quoi vous pouvez désactiver le champ horizontal et les fixer dans cette position. À ce moment, les qubits se sont alignés dans une séquence de positions haut et bas, ce qui est une conclusion basée sur l'entrée.
Il n'est pas toujours évident de savoir quel sera l'arrangement final des qubits, mais c'est le point. Le système, se comportant simplement naturellement, résout un problème sur lequel un ordinateur classique se battrait pendant longtemps. «Nous n'avons pas besoin d'un algorithme», explique
Hidetoshi Nishimori , physicien au Tokyo Institute of Technology qui a développé les principes de fonctionnement des machines D-Wave. - Il s'agit d'une approche complètement différente de la programmation conventionnelle. Le problème est résolu par la nature. »
La commutation des qubits est due à la tunnelisation quantique, la tendance naturelle des systèmes quantiques à la configuration optimale, la meilleure possible. On pourrait construire un réseau classique fonctionnant sur des principes analogiques en utilisant une gigue aléatoire au lieu d'un tunnelage pour commuter les bits, et dans certains cas, cela fonctionnerait mieux. Mais, fait intéressant, pour les problèmes qui se posent dans le domaine de l'apprentissage automatique, le réseau quantique semble atteindre son optimum plus rapidement.
La machine de D-Wave a ses inconvénients. Il est extrêmement sensible au bruit et, dans la version actuelle, il peut effectuer peu de variétés d'opérations. Mais les algorithmes d'apprentissage automatique sont par nature tolérants au bruit. Ils sont utiles précisément parce qu'ils peuvent reconnaître le sens dans une réalité désordonnée, séparant les chatons des chiots, malgré des moments distrayants. "Les réseaux de neurones sont connus pour leur résistance au bruit", a déclaré Berman.
En 2009, une équipe dirigée par
Hartmouth Niven , un spécialiste informatique chez Google, un pionnier de la réalité augmentée (il était co-fondateur du projet Google Glass), qui est entré dans le domaine du traitement de l'information quantique, a montré comment le premier prototype de la machine de D-Wave est capable d'effectuer une tâche très réelle apprentissage automatique. Ils ont utilisé la machine comme un réseau neuronal monocouche, triant les images en deux classes: «voiture» et «pas voiture» dans une bibliothèque de 20 000 photographies prises dans la rue. La machine n'avait que 52 qubits de travail, pas assez pour entrer complètement l'image. Par conséquent, l'équipe Niven a combiné une voiture avec un ordinateur classique qui a analysé divers paramètres statistiques des images et calculé la sensibilité de ces valeurs à la présence sur la photo de la voiture - elles n'étaient généralement pas particulièrement sensibles, mais au moins différaient des valeurs aléatoires. Une combinaison de ces valeurs pourrait déterminer de manière fiable la présence d'une voiture, il n'était tout simplement pas évident de savoir quelle combinaison. Et le réseau neuronal était engagé dans la détermination de la combinaison souhaitée.
Une équipe a un qubit associé à chaque valeur. Si le qubit a été défini sur une valeur de 1, il a marqué la valeur correspondante comme utile; 0 signifiait qu'elle n'était pas nécessaire. Les interactions magnétiques des qubits codaient les exigences de ce problème - par exemple, la nécessité de ne prendre en compte que les quantités les plus très différentes pour que le choix final soit le plus compact. Le système résultant a pu reconnaître la voiture.
L'année dernière, une équipe dirigée par Maria Spiropoulou, spécialiste de la physique des particules au California Institute of Technology, et Daniel Lidara, physicien à l'Université de Californie du Sud, a appliqué un algorithme pour résoudre un problème de physique pratique: classer les collisions de protons dans les catégories Higgs boson et non boson. Higgs. " En limitant les estimations uniquement aux collisions qui ont généré des photons, ils ont utilisé la théorie de base des particules pour prédire quelles propriétés d'un photon devraient indiquer l'apparence à court terme d'une particule de Higgs - par exemple, dépasser une certaine valeur seuil de l'élan. Ils ont examiné huit de ces propriétés et 28 combinaisons d'entre elles, qui au total ont produit 36 signaux candidats et permis à la puce D-Wave de trouver l'échantillon optimal. Il a identifié 16 variables comme utiles et trois comme les meilleures. "Compte tenu de la petite taille de l'ensemble de formation, l'approche quantique a donné un avantage en termes de précision par rapport aux méthodes traditionnelles utilisées dans la communauté des experts en physique des hautes énergies", a déclaré Lidar.
 Maria Spiropoulou, physicienne au California Institute of Technology, a utilisé l'apprentissage automatique pour rechercher des bosons de Higgs
Maria Spiropoulou, physicienne au California Institute of Technology, a utilisé l'apprentissage automatique pour rechercher des bosons de HiggsEn décembre, Rigetti a démontré un moyen de regrouper automatiquement des objets à l'aide d'un ordinateur quantique à usage général de 19 qubits. Les chercheurs ont fourni à la voiture une liste des villes et les distances entre elles et lui ont demandé de trier les villes en deux régions géographiques. La difficulté de cette tâche est que la distribution d'une ville dépend de la distribution de toutes les autres, vous devez donc rechercher une solution pour l'ensemble du système à la fois.
En fait, l'équipe de la société a attribué un qubit à chaque ville et a noté à quel groupe il était affecté. Grâce à l'interaction des qubits (dans le système Rigetti, ce n'est pas magnétique, mais électrique), chaque paire de qubits a cherché à prendre des valeurs opposées, car dans ce cas leur énergie était minimisée. De toute évidence, dans tout système contenant plus de deux qubits, certaines paires devront appartenir au même groupe. Les villes plus proches étaient plus susceptibles d'être d'accord, car pour elles le coût énergétique de l'appartenance au même groupe était plus faible que dans le cas des villes éloignées.
Pour amener le système à la moindre énergie, l'équipe Rigetti a choisi une approche quelque peu similaire à l'approche D-Wave. Ils ont initialisé des qubits avec une superposition de toutes les distributions de groupe possibles. Ils ont permis aux qubits d'interagir brièvement les uns avec les autres, ce qui les a amenés à accepter certaines valeurs. Ensuite, ils ont utilisé un analogue du champ magnétique horizontal, ce qui a permis aux qubits d'inverser l'orientation, s'ils avaient une telle tendance qui poussait légèrement le système vers l'état énergétique avec une énergie minimale. Ensuite, ils ont répété ce processus en deux étapes - interaction et révolution - jusqu'à ce que le système minimise l'énergie en répartissant les villes dans deux régions différentes.
Des tâches de classification similaires, bien qu'utiles, sont assez simples. De véritables percées MO sont attendues dans les modèles génératifs qui non seulement reconnaissent les chiots et les chatons, mais sont également capables de créer de nouveaux archétypes - des animaux qui n'ont jamais existé, mais sont aussi mignons que de vrais. Ils sont même capables de dériver indépendamment des catégories telles que «chatons» ou «chiots», ou de reconstruire une image qui n'a ni patte ni queue. "Ces technologies sont capables de beaucoup et très utiles dans la région de Moscou, mais elles sont très difficiles à mettre en œuvre", a déclaré
Mohammed Amin , scientifique en chef chez D-Wave. L'aide des ordinateurs quantiques serait utile ici.
D-Wave et d'autres équipes de recherche ont accepté ce défi.
Former un tel modèle signifie ajuster les interactions magnétiques ou électriques des qubits afin que le réseau puisse reproduire certaines données de test. Pour ce faire, vous devez combiner le réseau avec un ordinateur conventionnel. Le réseau est engagé dans des tâches complexes - il détermine ce que signifie cet ensemble d'interactions en termes de configuration finale du réseau - et l'ordinateur partenaire utilise ces informations pour affiner les interactions. Lors d'une démonstration l'année dernière, Alejandro Perdomo-Ortiz , chercheur au Laboratoire d'intelligence artificielle de la NASA, avec une équipe, a donné à D-Wave un système d'imagerie composé de chiffres manuscrits. Elle a déterminé qu'il y avait dix catégories en tout, faisait correspondre les nombres de 0 à 9 et a créé son propre gribouillage sous forme de nombres.Goulots d'étranglement du tunnel
Ce sont toutes de bonnes nouvelles. Et la mauvaise nouvelle est que, quel que soit le niveau de refroidissement de votre processeur, si vous ne pouvez pas lui fournir des données avec lesquelles travailler. Dans les algorithmes d'algèbre matricielle, une seule opération peut traiter une matrice de 16 nombres, mais elle nécessite toujours 16 opérations pour charger la matrice. "Le problème de la préparation de l'État - placer les données classiques dans un état quantique - est évité, et je pense que c'est l'une des parties les plus importantes", a déclaré Maria Schuld, chercheuse à Xanadu, une startup informatique quantique, et l'une des premières scientifiques à avoir obtenu son diplôme dans le domaine de l'OCM. Les systèmes MO distribués physiquement font face à des difficultés parallèles - comment introduire une tâche dans un réseau de qubits et faire interagir les qubits selon les besoins.Une fois que vous avez été en mesure d'entrer les données, vous devez les stocker de telle manière que le système quantique puisse interagir avec elles sans interrompre les calculs actuels. Lloyd et ses collègues ont proposé la RAM quantique utilisant des photons, mais personne n'a de dispositif analogique pour les qubits supraconducteurs ou les ions piégés - technologies utilisées dans les principaux ordinateurs quantiques. "Il s'agit d'un autre problème technique énorme en plus du problème de la construction de l'ordinateur quantique lui-même", a déclaré Aaronson. - En communiquant avec les expérimentateurs, j'ai l'impression qu'ils ont peur. Ils ne savent pas comment aborder la création de ce système. »Et enfin, comment afficher les données? Cela signifie mesurer l'état quantique de la machine, mais la mesure ne renvoie pas seulement un nombre à la fois, choisi au hasard, elle détruit également l'état entier de l'ordinateur, effaçant le reste des données avant que vous n'ayez la possibilité de le réclamer. Vous devez exécuter l'algorithme encore et encore pour supprimer toutes les informations.Mais tout n'est pas perdu. Pour certains types de tâches, des interférences quantiques peuvent être utilisées. Il est possible de contrôler le déroulement des opérations afin que les réponses incorrectes s'annulent et que les bonnes se renforcent; Ainsi, lorsque vous mesurez l'état quantique, vous recevrez non seulement une valeur aléatoire, mais la réponse souhaitée. Mais seuls quelques algorithmes, par exemple, la recherche avec une recherche exhaustive, peuvent tirer parti de l'interférence, et l'accélération s'avère généralement faible.Dans certains cas, les chercheurs ont trouvé des solutions pour l'entrée et la sortie des données. En 2015, Lloyd, Silvano Garnerone de l'Université de Waterloo au Canada et Paolo Zanardi de l'Université de Californie du Sud ont montré que dans certains types d'analyses statistiques, il n'est pas nécessaire d'entrer ou de stocker l'ensemble de données. De même, il n'est pas nécessaire de lire toutes les données lorsque plusieurs valeurs clés sont suffisantes. Par exemple, les entreprises technologiques utilisent la région de Moscou pour émettre des recommandations sur des programmes télévisés à regarder ou des biens à acheter sur la base d'une énorme matrice d'habitudes humaines. «Si vous créez un tel système pour Netflix ou Amazon, vous n'avez pas besoin de la matrice enregistrée quelque part, mais de recommandations pour les utilisateurs», explique Aaronson.Tout cela soulève la question: si une machine quantique démontre ses capacités dans des cas particuliers, peut-être que la machine classique peut aussi bien se montrer dans ces cas? Il s'agit d'un problème majeur non résolu dans ce domaine. Après tout, les ordinateurs ordinaires peuvent aussi faire beaucoup. La méthode de sélection habituelle pour le traitement de grands ensembles de données - l'échantillonnage aléatoire - est en fait très similaire dans l'esprit à un ordinateur quantique qui, quoi qu'il arrive à l'intérieur, produit finalement un résultat aléatoire. Schuld note: «J'ai implémenté de nombreux algorithmes auxquels j'ai réagi comme:« C'est tellement cool, c'est une telle accélération », puis, juste pour le plaisir, j'ai écrit une technologie d'échantillonnage pour un ordinateur classique, et j'ai réalisé que la même chose pouvait être réalisée avec aider à l'échantillonnage. "Aucun des succès obtenus à ce jour par KMO n'est complet sans un piège. Prenez la voiture D-Wave. Lors de la classification des images de voitures et de particules de Higgs, cela n'a pas fonctionné plus rapidement qu'un ordinateur classique. "L'un des sujets non abordés dans notre travail est l'accélération quantique", a déclaré Alex Mott, un spécialiste informatique du projet DeepMind de Google, qui a travaillé sur l'équipe de recherche sur la particule de Higgs. Les approches d'algèbre matricielle, comme l'algorithme Harrow-Hassidimi-Lloyd, ne montrent une accélération que dans le cas de matrices clairsemées - presque entièrement remplies de zéros. "Mais personne ne pose la question - les données éparses sont-elles généralement intéressantes pour l'apprentissage automatique?" - dit Schuld.Intelligence quantique
D'un autre côté, même de rares améliorations des technologies existantes pourraient plaire aux entreprises technologiques. «Les améliorations qui en résultent sont modestes, pas exponentielles, mais au moins quadratiques», explique Nathan Vayeb , chercheur en informatique quantique chez Microsoft Research. "Si vous prenez un ordinateur quantique suffisamment grand et rapide, nous pourrions révolutionner de nombreuses régions de la région de Moscou." Et dans le processus d'utilisation de ces systèmes, les informaticiens peuvent peut-être résoudre une énigme théorique - sont-ils réellement par définition plus rapides et dans quoi exactement.Schuld estime également qu'il y a de la place pour l'innovation du côté logiciel. MO n'est pas seulement un tas de calculs. Il s'agit d'un ensemble de tâches avec sa propre structure particulière définie. "Les algorithmes créés par les gens sont séparés des choses qui rendent MO intéressant et beau", a-t-elle déclaré. - Par conséquent, j'ai commencé à travailler de l'autre côté et j'ai pensé: Si j'ai déjà un ordinateur quantique - à petite échelle - quel modèle de MO peut être implémenté dessus? Peut-être que ce modèle n'a pas encore été inventé. " Si les physiciens veulent impressionner les experts en MO, ils devront faire plus que simplement créer des versions quantiques de modèles existants.Tout comme de nombreux neuroscientifiques sont arrivés à la conclusion que la structure des pensées humaines reflète le besoin du corps, les systèmes MO se matérialisent également. Les images, le langage et la plupart des données qui les traversent proviennent du monde réel et reflètent ses propriétés. L'OCM se matérialise également - mais dans un monde plus riche que le nôtre. Un domaine où il brillera sans aucun doute est le traitement des données quantiques. Si ces données ne sont pas une image mais le résultat d'une expérience physique ou chimique, une machine quantique deviendra l'un de ses éléments. Le problème d'entrée disparaît et les ordinateurs classiques sont loin derrière.Comme dans un cercle vicieux, les premiers KMO peuvent aider à développer leurs successeurs. "L'une des façons dont nous voulons vraiment utiliser ces systèmes est de créer les ordinateurs quantiques eux-mêmes", a déclaré Weibe. "Pour certaines procédures de correction d'erreurs, c'est la seule approche que nous avons." Peut-être qu'ils peuvent même réparer les erreurs en nous. Sans aborder la question de savoir si le cerveau humain est un ordinateur quantique - et c'est une question très controversée - il se comporte encore parfois de cette façon. Le comportement humain est extrêmement contextuel; nos préférences se forment à travers les choix qui nous sont fournis et n'obéissent pas à la logique. En cela, nous sommes similaires aux particules quantiques. "Comment vous posez des questions et dans quel ordre compte, et cela est typique des ensembles de données quantiques", a déclaré Perdomo-Ortiz.Par conséquent, le système KMO peut s'avérer être une méthode naturelle pour étudier les distorsions cognitives de la pensée humaine.Les réseaux de neurones et les processeurs quantiques ont quelque chose en commun: il est surprenant qu'ils fonctionnent même. La capacité de former un réseau neuronal n'a jamais été évidente, et pendant des décennies, la plupart des gens ont douté que ce serait possible. De même, il n'est pas évident que les ordinateurs quantiques seront un jour adaptés à l'informatique, car les caractéristiques distinctives de la physique quantique sont si bien cachées pour nous tous. Pourtant, les deux fonctionnent - pas toujours, mais plus souvent que nous ne le pensons. Et compte tenu de cela, il semble probable que leur unification trouvera sa place sous le soleil.