Les développeurs de Google Brain ont prouvé que les images "conflictuelles" peuvent contenir à la fois une personne et un ordinateur; et les conséquences possibles sont effrayantes.
Dans l'image ci-dessus - à gauche, il y a sans aucun doute un chat. Mais pouvez-vous dire avec certitude si le chat est à droite, ou juste un chien qui lui ressemble? La différence entre les deux est que le bon est fait en utilisant un algorithme spécial qui ne donne pas de modèles informatiques appelés "réseaux neuronaux convolutionnels" (CNN, réseau neuronal convolutionnel, ci-après dénommé SNA) pour conclure sans ambiguïté que dans l'image. Dans ce cas, le SNS pense qu'il s'agit plus d'un chien que d'un chat, mais le plus intéressant - la plupart des gens pensent de la même manière.
Il s'agit d'un exemple de ce que l'on appelle une «image contradictoire» (ci-après dénommée le KARP): elle est spécialement modifiée afin de tromper le SCN et d'éviter que le contenu ne soit correctement identifié. Les chercheurs de Google Brain ont voulu comprendre s'il était possible de provoquer un dysfonctionnement des réseaux neuronaux biologiques dans nos têtes de la même manière et, par conséquent, ont créé des options qui affectent également les voitures et les personnes, leur faisant penser qu'ils regardent quelque chose qui pas vraiment.
Quelles sont les images contradictoires?
Presque partout, pour la reconnaissance dans le SCN, des algorithmes de classification visuelle sont utilisés. En «montrant» au programme un grand nombre d'illustrations différentes avec des pandas, vous pouvez l'entraîner à reconnaître les pandas, car il apprend par comparaison afin de distinguer une caractéristique commune à l'ensemble. Dès que le SCN (également appelé
«classificateurs» ) recueille un éventail suffisant de «signes de panda» sur les données de formation, il sera capable de reconnaître le panda dans toutes les nouvelles images qu'il fournira.
On reconnaît les pandas par leurs caractéristiques abstraites: petites oreilles noires, grosses têtes blanches, yeux noirs, fourrure et tout ce jazz. Le SCN fait le contraire, ce qui n'est pas surprenant, car la quantité d'informations sur l'environnement que les gens interprètent chaque minute est beaucoup plus importante. Par conséquent, en tenant compte des spécificités des modèles, il est possible d'influencer les images de manière à les rendre «incohérentes» en les mélangeant à des données soigneusement calculées, après quoi le résultat pour une personne ressemblera presque à l'original, mais complètement différent pour le
classificateur , qui commencera à faire des erreurs en essayant de déterminer contenu.
Voici un exemple de panda:
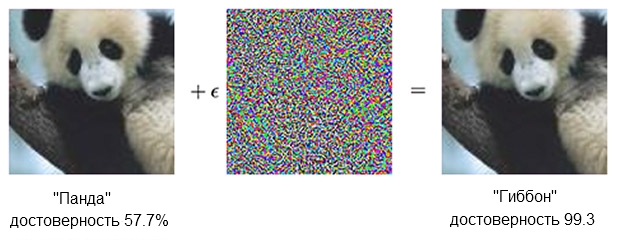 L'image d'un panda, combinée à l'indignation, peut convaincre le classificateur qu'il s'agit en fait d'un gibbon.Source: OpenAILe classificateur
L'image d'un panda, combinée à l'indignation, peut convaincre le classificateur qu'il s'agit en fait d'un gibbon.Source: OpenAILe classificateur basé sur le SCN est sûr que le panda à gauche est d'environ 60%. Mais si vous complétez légèrement ("créez l'indignation") la source en ajoutant ce qui ressemble à du bruit chaotique, le même classificateur sera sûr à 99,3% qu'il regarde maintenant le gibbon. De petits changements qui ne sont même pas clairement visibles donnent lieu à une attaque très réussie, mais cela ne fonctionnera que sur un modèle informatique spécifique et ne réalisera pas ceux qui pourraient être "appris" sur autre chose.
Afin de créer un contenu qui provoque une mauvaise réaction parmi un nombre important et diversifié d'analystes artificiels, il faut agir plus grossièrement - de minuscules corrections n'affecteront pas. Ce qui fonctionne de manière fiable ne pourrait pas être fait avec de «petits moyens». En d'autres termes, si vous voulez que le contenu fonctionne sous tous les angles et à toutes les distances, vous devez intervenir de manière plus significative, ou, comme dirait une personne, plus évident.
Dans la vue - un homme
Voici deux exemples de carpes grossières, où une personne peut facilement détecter des interférences.
 Source: Open AI à gauche, Google Brain à droite
Source: Open AI à gauche, Google Brain à droiteL'image du chat sur la gauche, que le SNS est défini comme un ordinateur, a été réalisée en "géométrie brisée". Si vous regardez de plus près (ou même pas trop près), vous verrez qu'il existe plusieurs structures angulaires et en forme de boîte qui peuvent ressembler à la forme d'une unité centrale. Et l'image de la banane à droite, qui est reconnue comme un grille-pain, donne régulièrement un faux positif à tout point de vue. Les gens trouveront actuellement une banane ici, cependant, un étrange engin à côté a quelques signes d'un grille-pain - et cela fait un imbécile de technologie.
Lorsque vous créez une image «contradictoire» appropriée et garantie dont vous avez besoin pour battre toute une entreprise de modèles de reconnaissance, cela conduit très souvent à l'apparition d'un «facteur humain». En d'autres termes, ce qui confond un seul réseau de neurones peut ne pas du tout être perçu comme un problème, et lorsque vous essayez d'obtenir un rébus qui est définitivement adapté pour tromper cinq ou dix à la fois, il s'avère que cela fonctionne sur la base de mécanismes qui, si les gens sont complètement inutiles.
En conséquence, il n'est absolument pas nécessaire d'essayer de forcer une personne à croire qu'un chat angulaire est un boîtier d'ordinateur, et la somme d'une banane et d'un étrange torchis ressemble à un grille-pain. Il est beaucoup mieux, lorsque vous créez des CARP conçus pour vous et moi, de vous concentrer immédiatement sur l'utilisation de modèles qui perçoivent le monde comme les gens.
Tromper l'œil (et le cerveau)
Le SNA avec une formation approfondie et une vision humaine sont quelque peu similaires, mais fondamentalement, le réseau neuronal «regarde» les choses «de manière informatique». Par exemple, lorsqu'elle reçoit une image, elle «voit» une grille statique de pixels rectangulaires en même temps. L'œil fonctionne différemment, une personne perçoit des détails élevés dans un secteur d'environ cinq degrés de chaque côté de la ligne de visée, mais en dehors de cette zone, l'attention au détail diminue linéairement.
Ainsi, contrairement à une machine, par exemple, le flou des bords d'une image ne fonctionnera pas avec une personne et passera simplement inaperçu. Les chercheurs ont pu modéliser cette fonctionnalité en ajoutant une «couche de rétine» qui a changé les données fournies par le SNA pour ressembler à l'œil, afin de limiter le réseau neuronal au même cadre que la vision normale.
Il convient de noter qu'une personne fait face à ses déficiences de perception par le fait que le regard n'est pas dirigé vers un point, mais se déplace constamment, examinant l'image entière, mais il a également été possible de compenser les conditions de l'expérience, en nivelant les différences entre le SCN et les personnes.
Remarque à partir du travail lui-même:
Chaque expérience a commencé avec un réticule d'installation, qui est apparu au centre de l'écran pendant 500 à 1000 millisecondes, et chaque sujet a été invité à fixer son regard sur le réticule.L'utilisation de la «couche rétinienne» était la dernière étape qui devait être prise dans le cadre d'un «ajustement mince» de l'apprentissage automatique pour les «caractéristiques humaines». Au cours de la génération des échantillons, ils ont été conduits à travers dix modèles différents, dont chacun aurait dû clairement appeler, disons, un chat, par exemple, un chien. Si le résultat était «10 sur 10 se sont trompés», alors le matériel a été soumis à des tests chez l'homme.
Est-ce que cela fonctionne?
Trois groupes d'images ont été impliqués dans l'expérience: «animaux de compagnie» (chats et chiens), «légumes» (courgettes et brocolis) et «menaces» (araignées et serpents, bien qu'en tant que propriétaire du serpent, je suggère un terme différent pour l'évaluation). Pour chaque groupe, le succès était compté si la personne testée choisissait la mauvaise chose - appelait le chien un chat, et vice versa. Les participants se sont assis devant un moniteur qui a affiché une image pendant environ 60 ou 70 millisecondes, et ils ont dû appuyer sur l'un des deux boutons pour indiquer l'objet. Puisque l'image a été montrée pendant un temps très court, cela a atténué la différence entre la façon dont les gens et les réseaux de neurones perçoivent le monde; l'illustration dans le titre, par ailleurs, est frappante par sa persistance de l'erreur.
Ce que les sujets ont montré pourrait être une image non modifiée (image), un CarP «ordinaire» (adv), un CarP «inversé» (flip), sur lequel le bruit était inversé avant l'application, ou un «faux» CarP, sur lequel une couche avec du bruit a été appliqué à une image n'appartenant à aucun des types du groupe (faux). Les deux dernières options ont été utilisées pour contrôler la nature de la perturbation (la structure du bruit affectera-t-elle autrement à l'envers, ou simplement «manger-non»?), De plus, elles ont permis de comprendre si l'interférence trompe complètement les gens ou réduit légèrement la précision.
Remarque à partir du travail lui-même:
Faux: une condition a été ajoutée pour forcer le sujet à commettre une erreur. Nous l'avons ajouté, car si les changements initiaux réduisent la précision de l'observateur, cela peut être dû à une diminution de la qualité d'image directe. Afin de montrer que les CARP fonctionnent réellement dans chaque classe, nous avons introduit des options où aucun choix ne pouvait être correct et leur précision était de 0, et nous avons observé exactement quelle était la «bonne» réponse dans ce cas. Nous avons démontré des images arbitraires d'ImageNet, qui étaient affectées par l'une ou l'autre classe du groupe, mais qui ne correspondaient à aucune d'entre elles. Le participant à l'expérience devait déterminer ce qui se trouvait devant lui. Par exemple, nous pourrions montrer une image d'un avion déformée en appliquant un bruit de «chien», bien que pendant l'expérience, le sujet n'ait reconnu qu'un chat ou un chien.Voici un exemple montrant un pourcentage du nombre de personnes qui ont pu identifier clairement une image en tant que chien, selon la façon dont le bruit a été utilisé. Permettez-moi de vous rappeler qu'il ne fallait que 60 à 70 millisecondes pour jeter un coup d'œil et prendre une décision.
 Source: Google Brain
Source: Google Brain
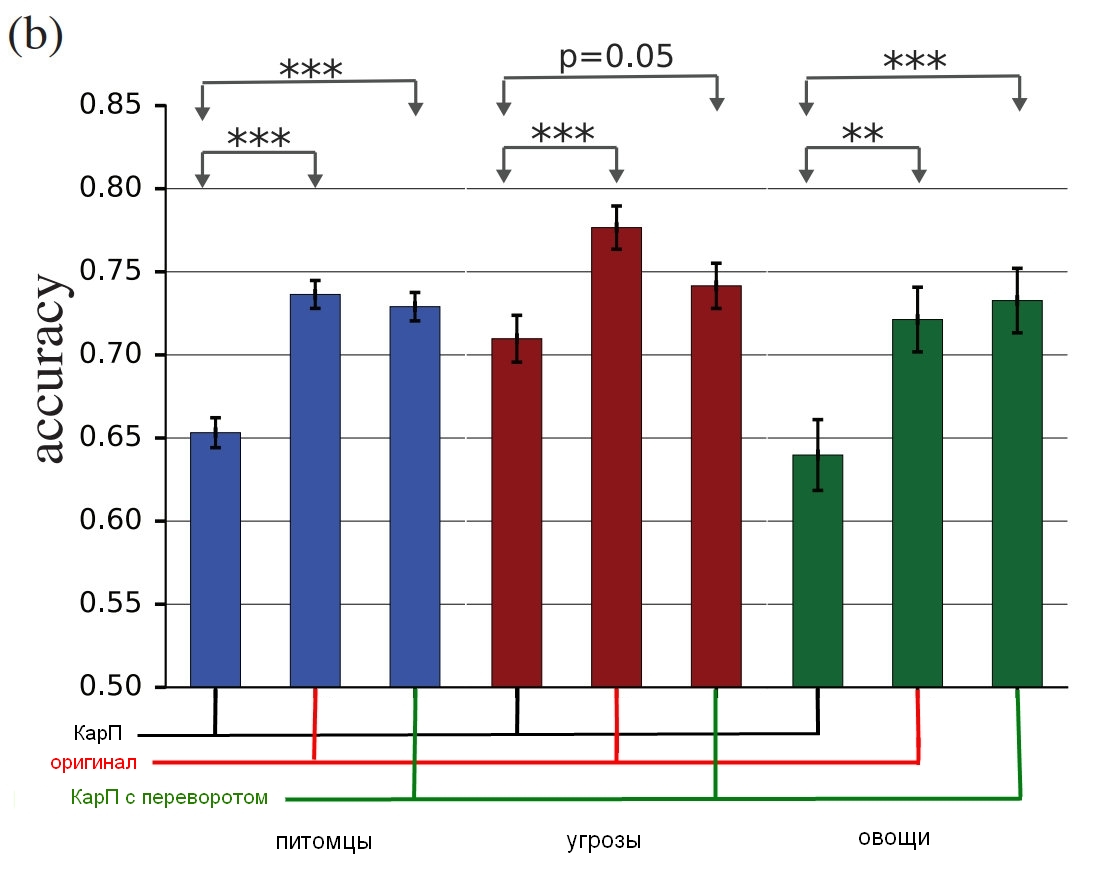
Image originale avec un chien; Carpe avec un chien, acceptée à la fois par un homme et un ordinateur comme un chat; contrôler l'image avec une couche de bruit à l'envers.Et voici les résultats finaux:
 Source: Google Brain
Source: Google Brain
Les résultats de l'étude, comment les vraies personnes identifient ces images par rapport à celles déformées.Le graphique montre la précision du match. Si vous choisissez un chat et que c'est vraiment un chat, la précision augmente. Si vous choisissez un chat, mais c'est en fait un chien, transformé par le bruit en une sorte de chat, la précision est réduite.
Comme vous pouvez le voir, les gens sont beaucoup plus corrects dans la sélection d'images non corrigées ou avec des couches de bruit inversées que dans la sélection d'images "incohérentes". Cela prouve que le principe d'attaque de la perception peut nous être transféré des ordinateurs.
Non seulement les impacts sont indéniablement efficaces, ils sont également plus minces que prévu - pas de boxcats ou de pseudo-grille-pain, ou quelque chose comme ça. Comme nous avons vu les deux couches avec du bruit et des images avant et après le traitement, nous devons comprendre ce qui nous confond exactement. Bien que les chercheurs soient prudents, déclarant que "nos exemples sont spécialement conçus pour faire un fou de la tête, vous devez donc être prudent en utilisant des personnes expérimentales pour étudier l'effet."
L'équipe tentera à l'avenir de dériver quelques règles générales pour certaines catégories de modifications, y compris "la
destruction des bords d'un objet , en particulier par des impacts moyens, perpendiculaires à la ligne de bord; la
correction des zones limitrophes en augmentant le contraste tout en texturant la bordure; en
changeant la texture ; en
utilisant des parties sombres "des images dans lesquelles le niveau d'impact sur la perception est élevé malgré de minuscules perturbations." Voici des exemples de zones entourées de rouge dans lesquelles les méthodes décrites sont mieux vues.
 Source: Google Brain
Source: Google Brain
Exemples d'images avec différents principes de distorsionQuel est le résultat?
L'essentiel est que c'est plus, bien plus qu'un simple truc intelligent. Les gars de Google Brain ont confirmé qu'ils peuvent créer une technique efficace de tromperie, mais ils ne comprennent pas entièrement pourquoi cela fonctionne, compte tenu du niveau d'abstraction, et il est possible que ce soit littéralement un niveau de réalité de base:
Notre projet soulève des questions fondamentales sur le fonctionnement des CARP, le fonctionnement des réseaux de neurones et du cerveau. Avez-vous réussi à transférer des attaques du SCN vers le cerveau parce que les représentations sémantiques des informations qu'elles contiennent sont similaires? Ou parce que ces deux représentations correspondent à un certain modèle sémantique général, qui existe naturellement dans le monde environnant?
En conclusion, si vous voulez vraiment devenir un peu paranoïaque, alors les chercheurs sont heureux de vous rendre service, soulignant que «la reconnaissance visuelle des objets ... il est difficile de donner une appréciation objective. La «Fig. 1» est-elle objectivement un chien, ou est-ce un chat objectif qui peut faire croire que c'est un chien? » En d'autres termes, l'image se transforme-t-elle vraiment en objet ou vous fait-elle simplement penser différemment?
C'est effrayant ici (et je dis sérieusement "effrayant") qu'au final, vous pouvez trouver des moyens d'influencer n'importe quel fait, car la distance entre la manipulation du SCN et la manipulation d'une personne n'est évidemment pas trop grande. En conséquence, les technologies d'apprentissage automatique peuvent potentiellement être utilisées pour déformer les images ou les vidéos de la bonne manière, ce qui remplacera notre perception (et la réaction correspondante), et nous ne comprendrons même pas ce qui s'est passé. Extrait du rapport:
Par exemple, un groupe de modèles avec une formation approfondie peut être formé sur les évaluations des personnes du niveau de confiance dans certains types de personnes, caractéristiques, expressions. Il deviendra possible de générer des indignations «conflictuelles» qui augmenteront ou diminueront le sentiment de «crédibilité», et de tels matériaux «peaufinés» peuvent être utilisés dans des clips d'actualité ou de la publicité politique.
À l'avenir, les risques théoriques incluent la possibilité de créer des stimulations sensorielles qui pénètrent dans le cerveau de différentes manières et avec une très grande efficacité. Comme vous le savez, de nombreux animaux sont considérés comme vulnérables aux stimulations dépassant le seuil. Disons que les coucous peuvent simultanément faire semblant d'être impuissants et faire un appel plaintif, ce qui, en combinaison, oblige les oiseaux d'autres races à nourrir les poussins de coucou avant leur propre progéniture. Les échantillons «conflictuels» peuvent être considérés comme une forme particulière de stimulation à seuil supérieur pour les réseaux de neurones. Et le fait que des stimuli excessifs, qui sont en théorie beaucoup plus susceptibles d'affecter une personne que de simplement lui faire accrocher une étiquette "un chat" sur la photo d'un chien, cause une préoccupation considérable, peut être créé à l'aide d'une machine puis transféré à des personnes.
Bien sûr, de telles méthodes peuvent être utilisées «pour le bien», et un certain nombre d'options ont déjà été proposées, telles que «affiner les traits caractéristiques des images afin d'augmenter le niveau de concentration, par exemple, lors du contrôle de la situation de l'air ou de l'analyse d'images radiographiques, car ce travail est monotone et les conséquences la négligence peut être terrible. " De plus, «les concepteurs d'interfaces utilisateur peuvent utiliser des perturbations pour développer des interfaces plus intuitives». Hmmm. C'est certainement génial, mais je suis en quelque sorte plus préoccupé par le fait de pirater mon cerveau et d'établir le niveau de confiance dans les gens, vous savez?
Certaines des questions posées feront l'objet de recherches futures - il est possible de découvrir ce qui rend exactement des images spécifiques plus appropriées pour transmettre une erreur à une personne, et cela peut fournir de nouveaux indices pour comprendre les principes du cerveau. Et cela, à son tour, aidera à créer des réseaux de neurones plus avancés qui apprendront plus rapidement et mieux. Mais nous devons être prudents et nous rappeler que, comme les ordinateurs, il n’est parfois pas si difficile de nous tromper.
Le projet
" Adversarial Examples that Fool both Human and Computer Vision , par Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow, and Jascha Sohl-Dickstein, from Google Brain" , peut être téléchargé à partir d'
arXiv . Et si vous avez besoin d'images plus controversées qui travaillent sur les gens, alors le matériel d'appui est
ici .