Bonjour, Habr! Enfin, nous avons attendu une autre partie de la série de documents du diplômé de nos programmes de
Big Data Specialist et
Deep Learning , Cyril Danilyuk, sur l'utilisation de Mask R-CNN, les réseaux de neurones actuellement populaires, dans le cadre d'un système de classification des images, à savoir évaluer la qualité d'un plat préparé à l'aide d'un ensemble de données provenant de capteurs.
Après avoir examiné l'ensemble de données sur les jouets consistant en des images de panneaux de signalisation dans l'
article précédent , nous pouvons maintenant résoudre le problème que j'ai rencontré dans la vie réelle:
«Est-il possible de mettre en œuvre l'algorithme d'apprentissage profond, qui pourrait distinguer les plats de haute qualité des mauvais plats un par un des photos? " . En bref, l'entreprise voulait cela:
Ce qu'une entreprise représente lorsqu'elle pense au machine learning:Ceci est un exemple d'un problème mal posé: dans ce cas, il est impossible de déterminer si une solution existe, si elle est unique et stable. De plus, l'énoncé du problème lui-même est très vague, sans parler de la mise en œuvre de sa solution. Bien sûr, cet article n'est pas consacré à l'efficacité de la communication ou de la gestion de projet, mais il est important de le noter:
ne jamais prendre en charge des projets dont le résultat final n'est pas défini et enregistré dans les TdR. L'un des moyens les plus fiables pour faire face à une telle incertitude est de construire d'abord un prototype, puis, en utilisant de nouvelles connaissances, de structurer le reste de la tâche. C'est ce que nous avons fait.
Énoncé du problème
Dans mon prototype, je me suis concentré sur un plat du menu - une omelette - et j'ai construit un pipeline évolutif, qui détermine la "qualité" de l'omelette à la sortie. Cela peut être décrit plus en détail comme suit:
- Type de problème: classification multiclasse avec 6 classes de qualité discrètes: bonne (bonne), jaune cassé (avec jaune d'œuf étalé), grillé (trop cuit), deux œufs (deux œufs), quatre œufs (quatre œufs), morceaux mal placés (avec des morceaux dispersés sur une plaque) .
- Ensemble de données: 351 photographies collectées manuellement de diverses omelettes. Echantillons de formation / validation / test: 139/32/180 photos mixtes.
- Labels de classe: chaque photo correspond à un label de classe correspondant à une évaluation subjective de la qualité de l'omelette.
- Métrique: entropie croisée catégorique.
- Connaissance minimale du domaine: une omelette de «qualité» devrait ressembler à ceci: elle se compose de trois œufs, d'une petite quantité de bacon, d'une feuille de persil au centre, n'a pas de jaunes étalés et de morceaux trop cuits. De plus, la composition globale doit «bien paraître», c'est-à-dire que les pièces ne doivent pas être dispersées sur toute la plaque.
- Critère d'achèvement: la meilleure valeur de l'entropie croisée dans l'échantillon test parmi tous les possibles après deux semaines de développement du prototype.
- La méthode de visualisation finale: t-SNE sur l'espace de données d'une plus petite dimension.
 Images d'entrée
Images d'entréeLe principal objectif du pipeline est d'apprendre à combiner plusieurs types de signaux (par exemple, des images sous différents angles, une carte thermique, etc.), après avoir reçu une représentation précompressée de chacun d'eux et passer ces caractéristiques à travers le classificateur de réseau neuronal pour la prédiction finale. Ainsi, nous pouvons réaliser notre prototype et le rendre pratiquement applicable dans d'autres travaux. Voici quelques-uns des signaux utilisés dans le prototype:
- Masques d'ingrédients clés (masque R-CNN): signal n ° 1 .
- Le nombre d'ingrédients clés sur le cadre., Numéro de signal 2 .
- Recadrage RVB de plaques avec omelette sans fond. Pour plus de simplicité, j'ai décidé de ne pas les ajouter au modèle pour le moment, bien qu'ils soient le signal le plus évident: à l'avenir, vous pouvez entraîner le réseau neuronal convolutionnel pour la classification en utilisant une fonction de perte de triplet adéquate, calculer les plongements d'images et couper la distance L2 du courant Des images à perfectionner. Malheureusement, je n'ai pas eu l'occasion de tester cette hypothèse, car l'échantillon de test ne comprenait que 139 objets.
Vue générale du pipeline
Je note que je devrai ignorer quelques étapes importantes, telles que l'analyse exploratoire des données, la construction d'un classificateur de base et l'étiquetage actif (mon terme proposé, qui signifie annotation semi-automatique d'objets, inspiré de la
vidéo de démonstration Polygon-RNN ) pour le masque R-CNN (en savoir plus sur ceci dans les prochains articles).
Jetez un œil à l'ensemble du pipeline en général:
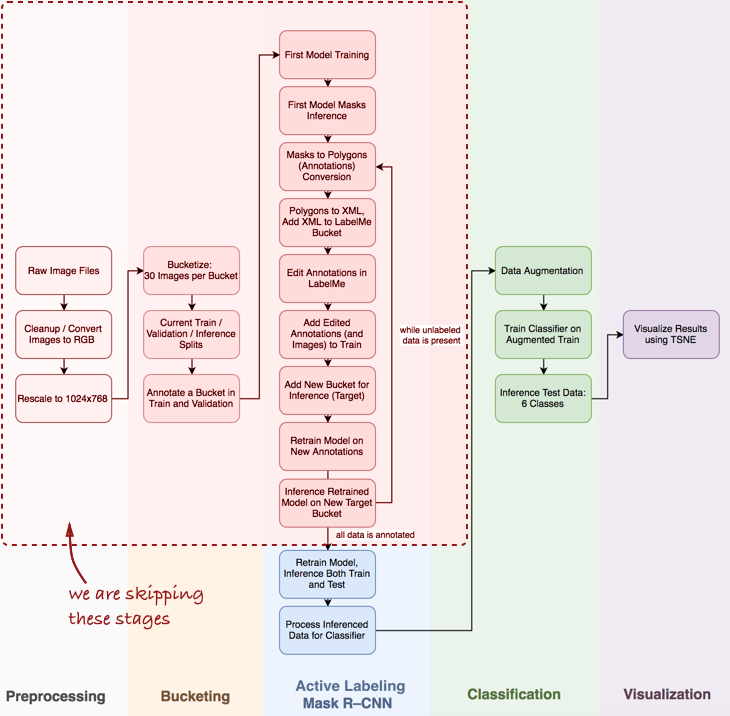 Dans cet article, nous nous intéressons aux étapes de Mask R-CNN et au classement au sein du pipeline.
Dans cet article, nous nous intéressons aux étapes de Mask R-CNN et au classement au sein du pipeline.Ensuite, nous considérerons trois étapes: 1) utiliser le masque R-CNN pour construire des masques d'ingrédients d'omelette; 2) classificateur ConvNet basé sur Keras; 3) visualisation des résultats en utilisant t-SNE.
Étape 1: Masque R-CNN et masques de construction
Le masque R-CNN (MRCNN) a récemment connu un pic de popularité. À partir de l'
article Facebook original et se terminant par le
Data Science Bowl 2018 à Kaggle, Mask R-CNN s'est imposé comme une architecture puissante pour la segmentation par exemple (c'est-à-dire non seulement la segmentation d'image pixel par pixel, mais aussi la séparation de plusieurs objets appartenant à la même classe ) De plus, c'est un plaisir de travailler avec la
mise en œuvre du MRCNN à partir de Matterport dans le Keras. Le code est bien structuré, a une bonne documentation et fonctionne dès la sortie de la boîte, bien que plus lentement que prévu.
En pratique, en particulier lors du développement d'un prototype, il est essentiel d'avoir un réseau neuronal convolutionnel pré-formé. Dans la plupart des cas, l'ensemble de données étiquetées du data scientist est très limité ou pas du tout, tandis que ConvNet nécessite beaucoup de données étiquetées pour atteindre la convergence (par exemple, l'ensemble de données ImageNet contient 1,2 million d'images étiquetées). Ici, l'
apprentissage par transfert vient à la rescousse: nous pouvons fixer le poids des couches convolutives et recycler uniquement le classificateur. La fixation des couches convolutives est importante pour les petits ensembles de données, car cette technique empêche le recyclage.
Voici ce que j'ai obtenu après la première ère de recyclage:
 Résultat de la segmentation des objets: tous les ingrédients clés reconnus
Résultat de la segmentation des objets: tous les ingrédients clés reconnusÀ l'étape suivante du pipeline (
Process Inferenced Data for Classifier ), il est nécessaire de découper la partie de l'image qui contient la plaque et d'extraire le masque binaire bidimensionnel pour chaque ingrédient de cette plaque:
 Image recadrée avec des ingrédients clés sous forme de masques binaires.
Image recadrée avec des ingrédients clés sous forme de masques binaires.Ces masques binaires sont ensuite combinés en une image à 8 canaux (puisque j'ai défini 8 classes de masques pour MRCNN), et nous obtenons le
signal n ° 1 :
 Signal n ° 1 : image à 8 canaux composée de masques binaires. En couleur pour une meilleure visualisation.
Signal n ° 1 : image à 8 canaux composée de masques binaires. En couleur pour une meilleure visualisation.Pour obtenir le
signal n ° 2 , j'ai compté le nombre de fois que chaque ingrédient est trouvé sur la récolte de la plaque et j'ai obtenu un ensemble de vecteurs de caractéristiques, chacun correspondant à sa récolte.
Étape 2: ConvNet Classifier dans Keras
Le classificateur CNN a été implémenté à partir de zéro à l'aide de Keras. Je voulais combiner plusieurs signaux (
signal n ° 1 et
signal n ° 2 , ainsi que l'ajout éventuel de données à l'avenir) et laisser les réseaux de neurones les utiliser pour faire des prévisions concernant la qualité de la parabole. L'architecture présentée ci-dessous est d'essai et loin d'être idéale:

Quelques mots sur l'architecture du classifieur:
- Module convolutionnel à plusieurs échelles : J'ai d'abord choisi un filtre 5x5 pour les couches convolutionnelles, mais cela n'a conduit qu'à un résultat satisfaisant. Des améliorations ont été obtenues en appliquant AveragePooling2D à plusieurs couches avec différents filtres: 3x3, 5x5, 7x7, 11x11. Une couche convolutionnelle 1x1 supplémentaire a été ajoutée devant chacune des couches pour réduire la dimension. Ce composant est un peu comme un module Inception , même si je n'avais pas prévu de construire un réseau trop profond.
- Filtres plus grands : j'ai utilisé des filtres plus grands, car ils aident à extraire facilement des signes plus grands de l'image d'entrée (qui est elle-même essentiellement une couche d'activation avec 8 filtres - le masque de chaque ingrédient peut être considéré comme un filtre séparé).
- Combinaison de signaux : dans mon implémentation naïve, une seule couche a été utilisée pour connecter deux ensembles d'attributs: les masques binaires traités ( signal n ° 1 ) et les ingrédients comptés ( signal n ° 2 ). Cependant, malgré sa simplicité, l'ajout du signal n ° 2 a permis de réduire la métrique d'entropie croisée de 0,8 à [0,7, 0,72] .
- Logits : en termes de TensorFlow, logit est une couche sur laquelle tf.nn.softmax_cross_entropy_with_logits est appliqué pour calculer la perte de lot .
Étape 3: visualisation des résultats à l'aide de t-SNE
Pour visualiser les résultats du classificateur sur les données de test, j'ai utilisé t-SNE - un algorithme qui vous permet de transférer les données source vers un espace de dimension inférieure (pour comprendre le principe de l'algorithme, je recommande de lire
l'article original , il est extrêmement informatif et bien écrit).
Avant la visualisation, j'ai pris des images de test, extrait la couche logite du classificateur et appliqué l'algorithme t-SNE à cet ensemble de données. Bien que je n'ai pas essayé différentes valeurs du paramètre de perplexité, le résultat semble toujours assez bon:
 Le résultat du t-SNE sur les données de test avec les prédictions du classificateur
Le résultat du t-SNE sur les données de test avec les prédictions du classificateurBien sûr, cette approche est imparfaite, mais elle fonctionne. Il peut y avoir plusieurs améliorations possibles:
- Plus de données. Les réseaux de convolution nécessitent beaucoup de données et je n'avais que 139 images pour la formation. Des techniques telles que l'augmentation des données fonctionnent bien (j'ai utilisé D4 ou une augmentation symétrique des dièdres , ce qui donne plus de 2 000 images), mais il est toujours extrêmement important d'avoir plus de données réelles.
- Fonction de perte plus appropriée. Pour plus de simplicité, j'ai utilisé une entropie croisée catégorique, ce qui est bien car cela fonctionne dès la sortie de la boîte. La meilleure option serait d'utiliser la fonction de perte, qui prend en compte la variation au sein des classes, par exemple, la fonction de perte de triplet (voir l' article FaceNet ).
- Amélioration de l'architecture du classificateur. Le classificateur actuel est essentiellement un prototype, dont le seul but est de construire des masques binaires et de combiner plusieurs ensembles de fonctionnalités pour former un seul pipeline.
- Amélioration de la disposition des images. J'étais très bâclé lors du balisage manuel des images: le classificateur a fait ce travail mieux que moi sur une dizaine d'images de test.
Conclusion Il faut enfin reconnaître que l'entreprise n'a ni données, ni explications, ni même une tâche plus clairement définie à résoudre. Et c'est bien (sinon, pourquoi ont-ils besoin de vous?), Car votre travail consiste à utiliser divers outils, des processeurs multicœurs, des modèles pré-formés et un mélange d'expertise technique et commerciale pour créer de la valeur ajoutée dans l'entreprise.
Commencez petit: un prototype fonctionnel peut être créé à partir de plusieurs blocs de code jouets, et il augmentera considérablement la productivité des conversations ultérieures avec la direction de l'entreprise. C'est le travail d'un scientifique des données - pour offrir aux entreprises de nouvelles approches et idées.
Le 20 septembre 2018, le
«Big Data Specialist 9.0» commence, où, entre autres, vous apprendrez à visualiser les données et à comprendre la logique métier derrière telle ou telle tâche, ce qui vous aidera à présenter plus efficacement les résultats de votre travail à vos collègues et à la direction.