
Aujourd'hui, le CERN est l'un des plus grands utilisateurs de Kubernetes au monde. Selon des statistiques récentes, 210 clusters européens K8 ont été lancés dans cette organisation européenne derrière le Grand collisionneur de hadrons (LHC) et un certain nombre d'autres projets de recherche bien connus, servant des centaines de milliers de tâches simultanément. Cette réussite est à leur sujet.
Conteneurs du CERN: début
Pour ceux qui connaissent au moins superficiellement les activités du CERN, ce n'est pas un secret que beaucoup d'attention est accordée dans cette organisation aux technologies de l'information pertinentes: rappelez-vous simplement que c'est le berceau du World Wide Web, et parmi les mérites les plus récents, vous pouvez vous souvenir des systèmes de grille (y compris le
LHC Computing Grid ), un
circuit intégré spécialisé,
la distribution Scientific Linux et même
sa propre licence matérielle ouverte. En règle générale, ces projets, qu'ils soient logiciels ou matériels, sont liés à la principale idée originale du CERN-LHC. Cela vaut également pour l'infrastructure informatique du CERN, qui répond largement à ses propres besoins.
 Au centre de données du CERN à Genève
Au centre de données du CERN à GenèveLes premières informations accessibles au public sur l'utilisation pratique des conteneurs dans l'infrastructure de l'organisation, qui ont été trouvées, remontent à avril 2016. Dans le cadre d'un rapport «interne» de
Containers and Orchestration dans le cloud du CERN , les employés du CERN ont expliqué comment ils utilisent OpenStack Magnum
(un composant OpenStack pour travailler avec des moteurs d'orchestration de conteneurs) afin de prendre en charge les conteneurs dans leur cloud (CERN Cloud) et leur orchestration. Mentionnant déjà Kubernetes, les ingénieurs visaient à être indépendants de l'instrument d'orchestration choisi, prenant en charge d'autres options: Docker Swarm et Mesos.
Remarque : Le cloud OpenStack lui-même a été introduit dans l'infrastructure de production du CERN plusieurs années auparavant, en 2013. En février 2017, 188 000 cœurs, 440 To de RAM étaient disponibles dans ce cloud, 4 millions de machines virtuelles ont été créées (dont 22 000 étaient actives).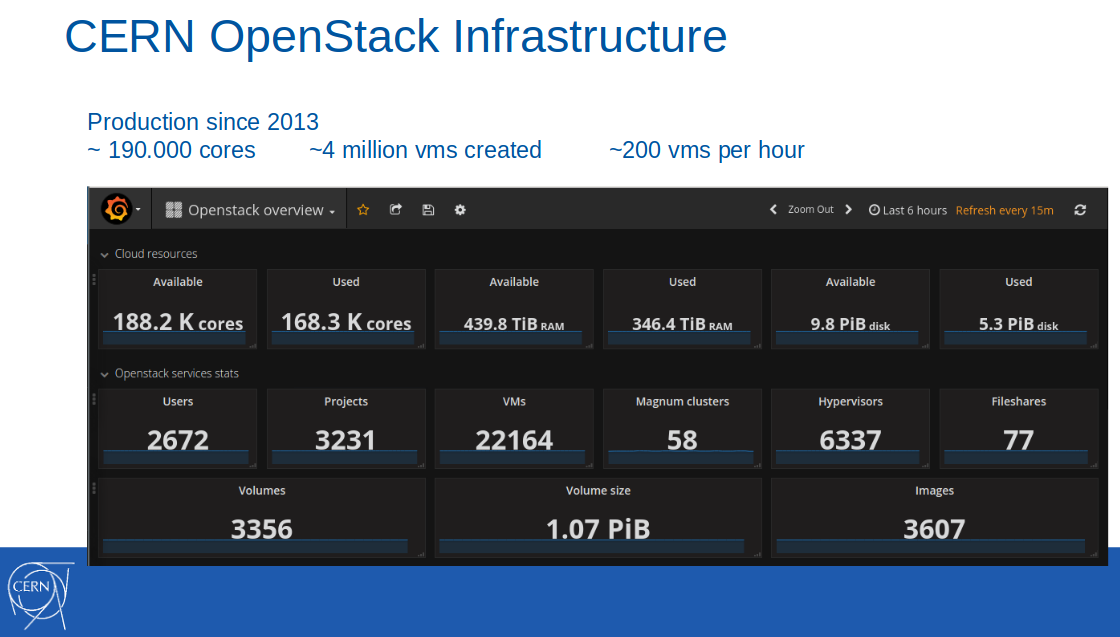
À cette époque, le support de conteneurs au format Containers-as-a-Service était positionné comme un service pilote et était utilisé dans dix projets informatiques de l'organisation. Parmi les scénarios d'application, une intégration continue avec GitLab CI était nécessaire pour créer et déployer des applications dans des conteneurs Docker.
 De la présentation au rapport du CERN du 8 avril 2016
De la présentation au rapport du CERN du 8 avril 2016Le lancement de ce service en production était attendu pour le troisième trimestre 2016.
Remarque : Il convient de noter séparément que les employés du CERN mettent invariablement leurs meilleures pratiques en amont des projets Open Source utilisés, y compris et de nombreux composants OpenStack, qui dans ce cas étaient Magnum, marionnette-magnum, Rally, etc.Des millions de requêtes par seconde avec Kubernetes
En juin de la même année (2016), le service au CERN
avait toujours le statut de pré-production:
«Nous nous dirigeons progressivement vers un mode de production à part entière pour inclure les conteneurs en tant que service dans l'ensemble standard de services informatiques disponibles au CERN.»
Et puis, inspirés par la
publication sur le blog de Kubernetes sur le traitement de 1 million de requêtes HTTP par seconde sans interruption pendant la mise à jour du service dans K8s, les ingénieurs de l'organisation scientifique ont décidé de répéter ce succès dans leur cluster sur OpenStack Magnum, Kubernetes 1.2 et une base matérielle de 800 cœurs de CPU.
De plus, ils ont décidé de ne pas se limiter à une simple répétition de l'expérience et ont réussi à augmenter le nombre de requêtes à 2 millions par seconde, préparant simultanément plusieurs correctifs pour le même OpenStack Magnum et effectuant des tests avec différents nombres de nœuds dans le cluster (300, 500 et 1000).
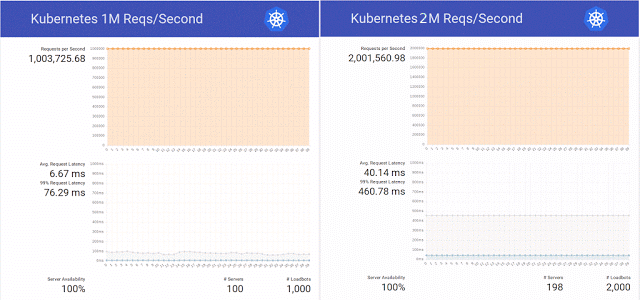
Résumant les résultats de ces tests, les ingénieurs ont de nouveau noté qu '"il y a aussi Swarm et Mesos, et nous prévoyons de les tester bientôt". Si la question a atteint ces tests, Internet n'est pas connu, mais à la fin de cette année, l'expérience avec Kubernetes
s'est poursuivie - avec 10 millions de requêtes par seconde. Le résultat a été assez positif, mais s'est limité à une marque réussie d'un peu plus de 7 millions - en raison d'un problème de réseau non lié à OpenStack.
Les ingénieurs spécialisés dans OpenStack Heat et Magnum ont également mesuré qu'il a fallu 23 minutes pour faire évoluer le cluster de 1 à 1000 nœuds, l'évaluant comme un bon résultat
(voir également la présentation Toward 10,000 Containers on OpenStack au OpenStack Summit Barcelona 2016) .
Conteneurs au CERN: transition vers la production
En février de l'année suivante (2017), les conteneurs du CERN étaient déjà largement utilisés pour résoudre des problèmes dans différents domaines: traitement par lots, apprentissage automatique, gestion des infrastructures, déploiement continu ... Cela était annoncé dans le rapport «
OpenStack Magnum au CERN. Mise à l'échelle des clusters de conteneurs sur des milliers de nœuds "(
vidéo ) au FOSDEM 2017:

Il a également indiqué que l'utilisation de Magnum au CERN était entrée dans la phase de production en octobre 2016, et a de nouveau souligné le soutien de trois instruments d'orchestration: Kubernetes, Docker Swarm et Mesos. Pourquoi c'était si important, a
expliqué lors d'un de ses discours (OpenStack Summit à Boston, mai 2017) Ricardo Rocha du département informatique du CERN:
«Magnum nous permet également de choisir un moteur de conteneur, qui nous a été très précieux. Des groupes de personnes qui préconisaient Kubernetes travaillaient dans l'organisation, mais il y avait aussi ceux qui utilisaient déjà Mesos, et certains ont même travaillé avec le Docker habituel, voulant continuer à s'appuyer sur l'API Docker, et Swarm a un grand potentiel ici. Nous voulions atteindre la facilité d'utilisation, ne pas obliger les gens à comprendre des modèles complexes pour configurer leurs clusters. »
À cette époque, le CERN utilisait environ 40 clusters avec Kubernetes, 20 avec Docker Swarm et 5 avec Mesosphere DC / OS.
Un an plus tard, en mai 2018, la situation a considérablement changé. À partir de la
présentation du
CERN Experiences with Multi-Cloud Federated Kubernetes (
vidéo ) par Ricardo et son collègue (Clenimar Filemon) à KubeCon Europe 2018, de nouveaux détails sur l'utilisation de Kubernetes sont devenus connus. Désormais, ce n'est plus seulement l'un des outils d'orchestration de conteneurs mis à la disposition des utilisateurs d'une organisation scientifique, mais aussi une technologie importante pour l'ensemble de l'infrastructure, qui permet, grâce à la fédération, d'étendre considérablement le cloud computing en ajoutant des ressources tierces (GKE, AKS, Amazon, Oracle ...) à ses propres capacités.
Remarque : La fédération dans Kubernetes est un mécanisme spécial qui simplifie la gestion de plusieurs clusters en synchronisant les ressources qui s'y trouvent et en détectant automatiquement les services dans tous les clusters. Le cas réel de son application est de travailler avec une variété de clusters Kubernetes répartis sur différents fournisseurs (leurs centres de données, des services cloud tiers).Comme vous pouvez le voir sur cette diapositive, qui montre certaines caractéristiques quantitatives du centre de données du CERN à Genève ...

... l'infrastructure interne de l'organisation s'est considérablement développée. Par exemple, le nombre de cœurs disponibles pour l'année a presque doublé - déjà à 320 mille. Les ingénieurs sont allés plus loin et ont combiné plusieurs de leurs centres de données, ayant atteint la disponibilité de 700 000 cœurs dans le nuage du CERN, qui sont engagés dans l'exécution parallèle de 400 000 tâches (pour la reconstruction d'événements, l'étalonnage de détecteurs, les simulations, l'analyse de données, etc.) ...
Mais dans le cadre de cet article, le fait qu'il existe déjà 210 clusters Kubernetes, dont les tailles varient considérablement (de 10 à 1000 nœuds), est d'un plus grand intérêt.
Fédération avec Kubernetes
Cependant, les capacités internes du CERN n'étaient pas toujours suffisantes - par exemple, pour des périodes de fortes charges: avant les grandes conférences internationales de physique et dans le cas de grandes campagnes de reconstruction d'expériences. Un cas d’utilisation notable nécessitant des ressources importantes est le service batch du CERN, qui représente environ 80% des ressources informatiques de l’organisation.
Au cœur de ce système se trouve le framework open source
HTCondor , conçu pour résoudre les problèmes de la catégorie HTC (calcul à haut débit). Le démon StartD est responsable des calculs qu'il contient, qui démarre sur chaque nœud et est responsable du démarrage de la charge de travail sur celui-ci. C'est lui qui a été conteneurisé au CERN dans le but de se lancer sur Kubernetes et plus loin la fédération.
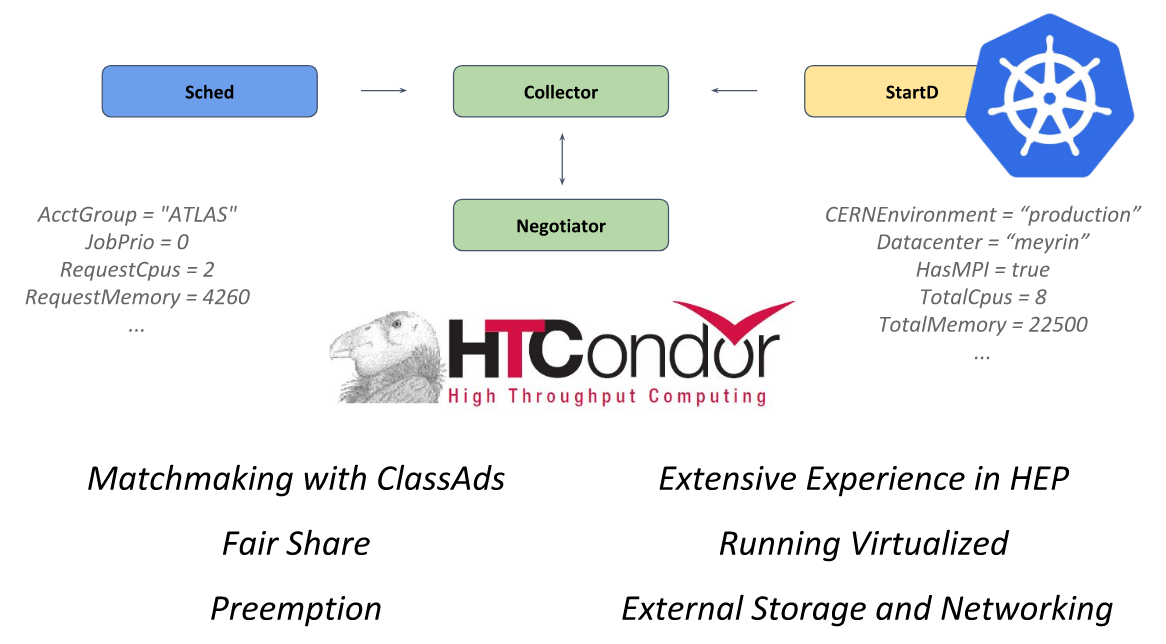 HTCondor de la présentation du CERN à KubeCon Europe 2018
HTCondor de la présentation du CERN à KubeCon Europe 2018En suivant ce chemin, les ingénieurs du CERN ont pu décrire une seule ressource (
DaemonSet avec un conteneur où StartD est lancé depuis HTCondor) et la déployer sur les nœuds de tous les clusters Kubernetes fédérés: d'abord dans le cadre de son centre de données, puis en connectant des fournisseurs externes (cloud public de T-Systems et d'autres sociétés):
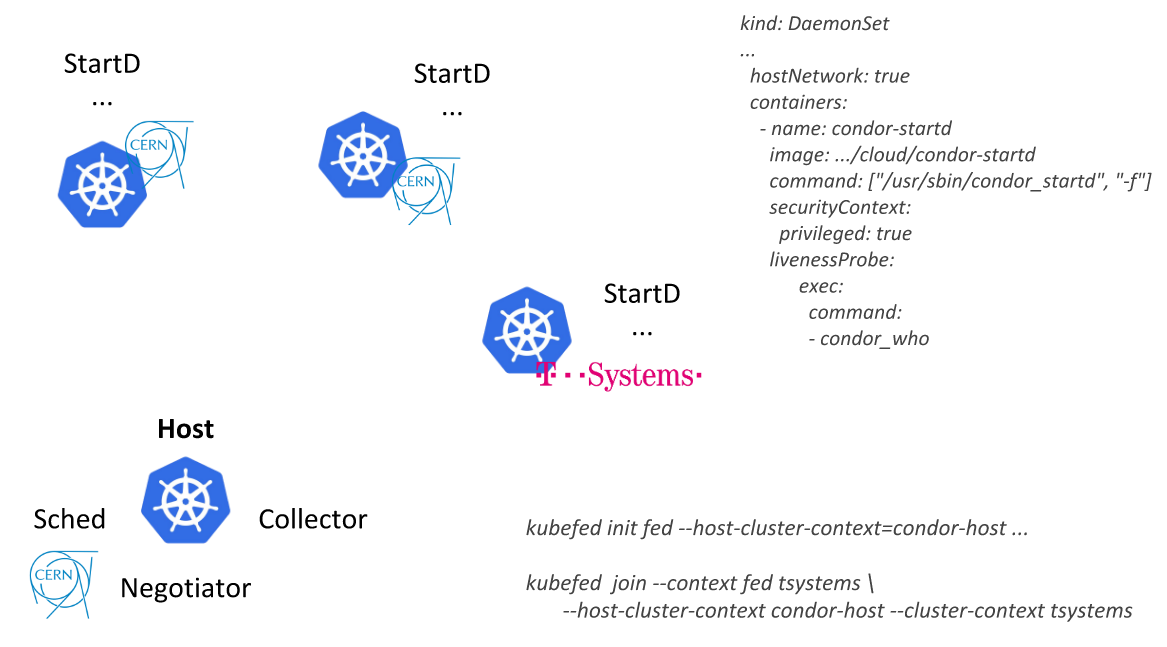
Une autre application est une plate-forme analytique basée sur
REANA ,
RECAST et
Yadage . Contrairement au CERN Batch Service, qui est un logiciel «établi» dans l'organisation, il s'agit d'un nouveau développement, qui a immédiatement pris en compte les spécificités de l'application avec Kubernetes. Les workflows de ce système sont implémentés de manière à ce que chaque étape soit convertie en
Job pour Kubernetes.
Si initialement toutes ces tâches étaient exécutées sur un seul cluster, puis au fil du temps, les demandes ont augmenté et "aujourd'hui est notre meilleure fédération de cas d'utilisation dans Kubernetes". Regardez une courte vidéo avec sa démonstration dans
ce fragment du discours de Ricardo Rocha.
PS
Des informations supplémentaires sur l'étendue actuelle de l'utilisation des technologies de l'information au CERN sont disponibles sur
le site Web de l'organisation .
Autres articles du cycle